mySQL入门之多表操作
外键
初识外键
外键:引用另一个表中的一列或多列,被引用的列应该具有主键约束或唯一性约束。(外键用于建立和加强两个表数据之间的连接,保证数据的完整和统一性)
主表:被引用的表
从表:引用外键的表
--例:
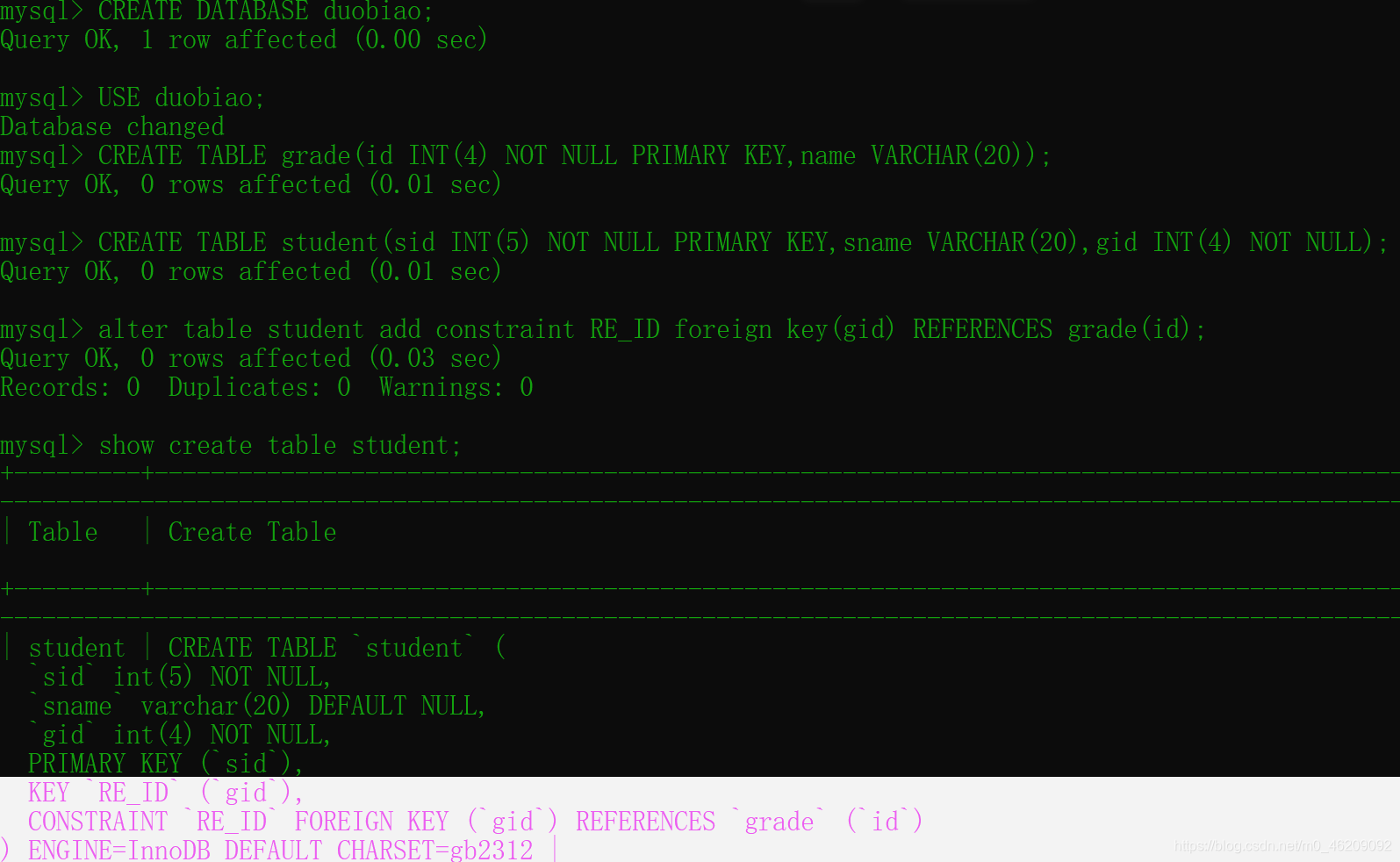
CREATE DATABASE duobiao;
USE duobiao;
CREATE TABLE grade(
id INT(4) NOT NULL PRIMARY KEY,
name VARCHAR(20));
CREATE TABLE student(
sid INT(5) NOT NULL PRIMARY KEY,
sname VARCHAR(20),
gid INT(4) NOT NULL,
foreign key(gid)references grade(id)
);
--student表中的gid是引用了grade表中主键(id),即:gid可以作为student表的外键,student表可以用gid连接grade表中的信息,从而建立两个表数据之间的连接。
--此两个表的主从关系为:grade为主表,student为从表
为表添加外键约束
语法: alter table 表名 add constraint 外键名 foreign key(外键字段名) REFERENCES 主表表名(主键字段名);
--例:
alter table student add constraint RE_ID foreign key(gid) REFERENCES grade(id);
--查看结果:show create table student;
删除外键约束
alter table 表名 drop foreign key 外键名;
--例:
alter table student drop foreign key RE_ID;
--查看结果:show create table student;
外键的注意事项:
1.建立外键的表必须是InnoDB型,不能是临时表。因为mySQL中只有InnoDB类型的表才支持外键。
2.定义外键名时,不能加引号,如:constraint 'NN-ID’或constraint "NN-ID"都是错误的。
3.外键约束的参数:
(1)cascade:从主表删除或者更新且自动删除或更新从表中匹配的行
(2)set null:从主表删除或更新行,并设置从表中的外键行为null,如果使用该选项,必须保证子表列没有指定not null
(3)restrict:拒绝对主表的删除或更新操作。
(4)no action:标准SQL的关键字,在mysql中于restrict相同(默认值)xf
操作关联表
关联关系
在实际开发中,需要根据实体的内容设计数据表,实体间会有各种关联关系。所以根据实体设计的数据表之间也存在着各种关联关系,mySQL中数据表的关联关系有三种:多对一,多对多,一对一。
(1)多对一
例如:一个班级有多个学生,不能说一个学生属于多个班级。
两表间建立外键:在多对一的表关系中,应该将外键建在多的一方(如:学生),否则会造成数据的冗余
(2)多对多
例如:订单与商品,一个订单中可以有多个商品,一个商品可以放到多个订单中。
两表间建立外键:通常情况下,为了实现这种关系需要定义一张中间表(称为连接表),该表存在两个外键(分别参照商品表与订单表)。
(3)一对一
例如:身份证与人,一个人只能有一张身份证,一张身份证只能匹配到一个人。
两表间建立外键:首先,分清主从关系,从表需要主表的存在才有意义(身份证需要人存在才有意义),因此,人为主表,身份证为从表(在身份证表中建立外键)。
应用方面:
1.分割具有很多列的表
2.由于安全原因而隔离表的一部分
3.保存临时的数据,并且可以毫不费力地通过删除这些数据
添加数据
因为外键列只能插入参照列存在的值,所以如果要为两个表添加数据,就需要先为主表添加数据
--建立student表与grade表外键联系
alter table student add constraint RE_ID foreign key(gid) REFERENCES grade(id);
--查看结果
show create table student;
--为主表添加数据
INSERT INTO grade(id,name)VARCHAR(1,'一年级');
INSERT INTO grade(id,name)VARCHAR(2,'二年级');
--为从表添加数据
INSERT INTO student(sid,sname,gid)VALUES(1,'李四',1),(2,'张三',1),(3,'王五',2);
--查看结果
SELECT sname FROM student WHERE name='一年级';
删除数据
先删除从表中参照列的数据(改为NULL)或删除从表数据,然后删除主表数据
--在student表中,将一年级的学生全部删除
delete from student where sname='李四';
delete from student where sname='张三';
--在grade表中,将一年级删除
delete from grade where id=1;
--查看结果
select*from grade;
连接查询
在关系型数据库管理系统中,建立表时各个数据之间的关系不必确定,通常将每个实体的所有信息存放在一个表中,当查询数据时,通过连接操作查询多个表中的实体信息,当两个或多个表中存在相同的意义的字段时,便可以通过这些字段对不同的表进行连接查询,连接查询包括:交叉查询,内连接查询,外连接查询
交叉连接(少见)
交叉连接返回的结果是被连接的两个表中所有数据行的笛卡儿积即:返回第一个表中符合查询条件的数据行数乘以第二个表符合查询条件的数据行数
语法:SELECT*FROM 表1 CROSS JOIN 表2;
CROSS JOIN用于连接两个要查询的表,该语句可以查询两个表中所有的数据组合。
--例:
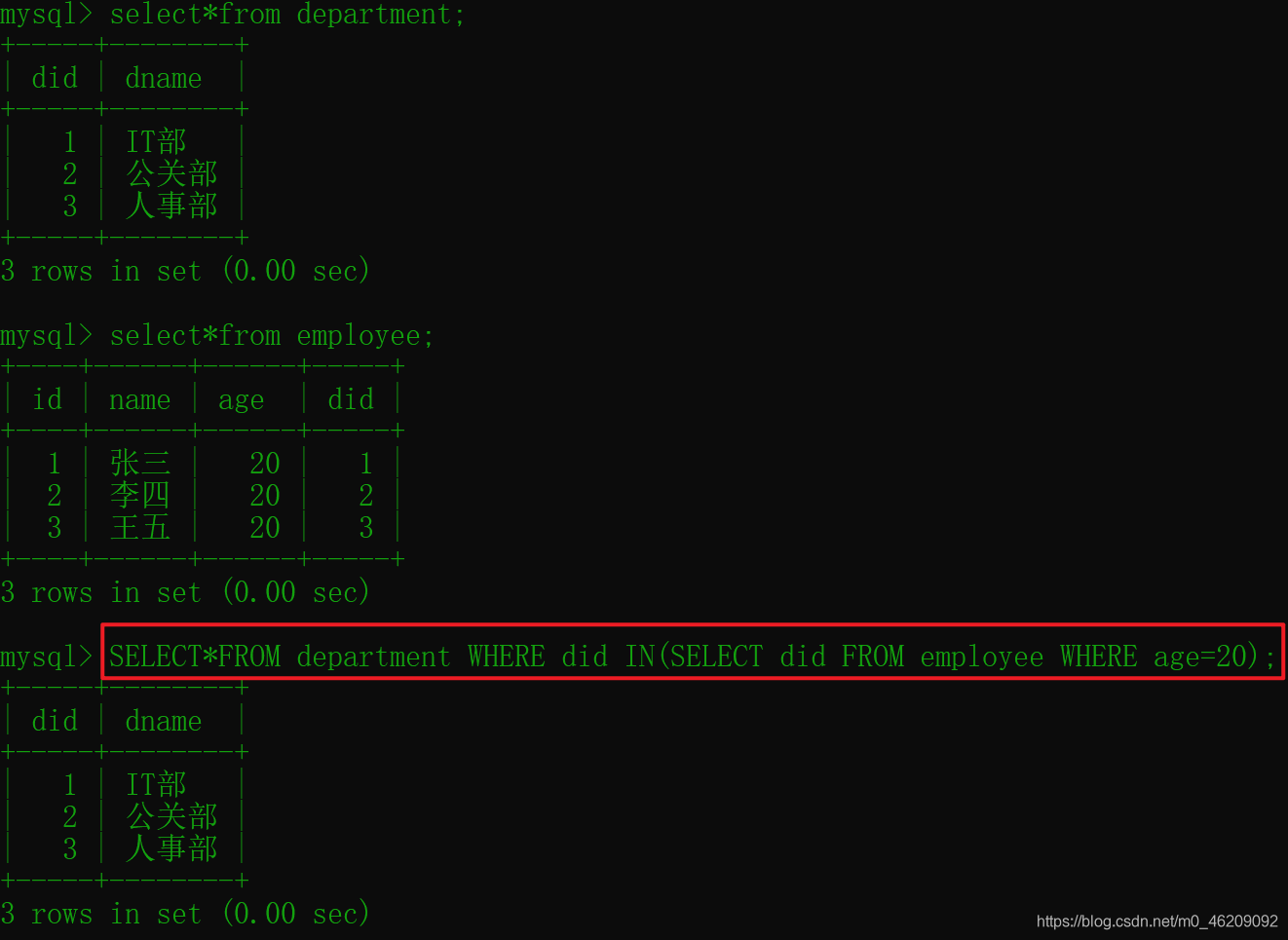
--生成表
USE db2020
CREATE TABLE department(
did INT(4) NOT NULL PRIMARY KEY,
dname VARCHAR(36));
CREATE TABLE employee(
id INT(4) NOT NULL PRIMARY KEY,
name VARCHAR(36),
age INT(2),
did INT(4) NOT NULL);
--插入数据
INSERT INTO department(did,dname)VALUES(1,'IT部'),(2,'公关部'),(3,'人事部');
INSERT INTO employee VALUES(1,'张三',20,1),(2,'李四',20,2),(3,'王五',20,3);
--使用交叉连接查询
SELECT*FROM department CROSS JOIN employee;

内连接(简单连接或自然连接)
内连接使用比较运算符对两个表中的数据进行比较,并列出与连接条件匹配的数据行,结合成新的记录。
语法:SELECT 查询字段 FROM 表1 [INNER] JOIN 表2 ON 表1.关系字段=表2.关系字段;
INNER JOIN 用于连接两个表,ON来指定连接条件,其中INNER可以省略。
--例1:
SELECT employee.name,department.dname FROM department JOIN employee ON department.did=employee.did;

--例2:
--使用where条件语句来实现同样的功能
SELECT employee.name,department.dname FROM department,employee WHERE department.did=employee.did;

自连接查询(特殊的内连接):在一个连接查询中,涉及的两个表是同一个表。 例如:查询李四所在部门有哪些员工,就可以使用自连接查询
SELECT p1.* FROM employee p1 JOIN employee p2 ON p1.did=p2.did WHERE p2.name='李四';

外连接
返回查询结果不仅包含符合条件的数据,而且还包括左表(左连接),右表(右连接)或两个表(全外连接)中的所有数据,此时就需要使用外连接查询。
语法:SELECT 所查字段 FROM 表1 LEFT|RIGHT[OUTER] JOIN 表2 ON 表1.关系字段=表2.关系字段 WHERE 条件;
(1)LEFT JOIN(左连接)
返回查询结果:符合条件的数据和LEFT JOIN子句中指定的左表中所有记录,如果左表的某条记录在右表中不存在,则在右表中显示为空。
--例:
SELECT department.did,department.dname,employee.name FROM department LEFT JOIN employee ON department.did=employee.did;

(2)RIGHT JOIN(右连接)
返回查询结果:符合条件的数据和RIGHT JOIN子句中指定的右表中所有记录,如果右表的某条记录在左表中不存在,则在左表中显示为空。
SELECT department.did,department.dname,employee.name FROM department RIGHT JOIN employee ON department.did=employee.did;

复合条件连接查询
复合条件连接查询即:在连接查询的过程中,通过添加过滤条件来限制查询结果,使查询结果更加精确。
子查询
子查询:一个查询语句嵌套在另一个查询语句内部的查询。
它可以嵌套在一个SELECT,SELECT…INTO,INSERT…INTO等语句中。
执行过程:先执行子查询中的语句,然后将返回的结果作为外层查询的过滤条件。
在子查询中通常可以使用IN,EXISTS,ANY,ALL操作符。
带IN关键字的子查询
内层查询语句只返回一个数据列,这个数据列中的值将供外层语句进行比较操作。
--例:
SELECT*FROM department WHERE did IN(SELECT did FROM employee WHERE age=20);
带EXISTS关键字的子查询
EXISTS关键字后面的参数可以是任意一个子查询,这个子查询的作用相当于测试,它不产生任何数据,只返回TRUE或FALSE,当返回值为TRUE时,外层语句才会执行。
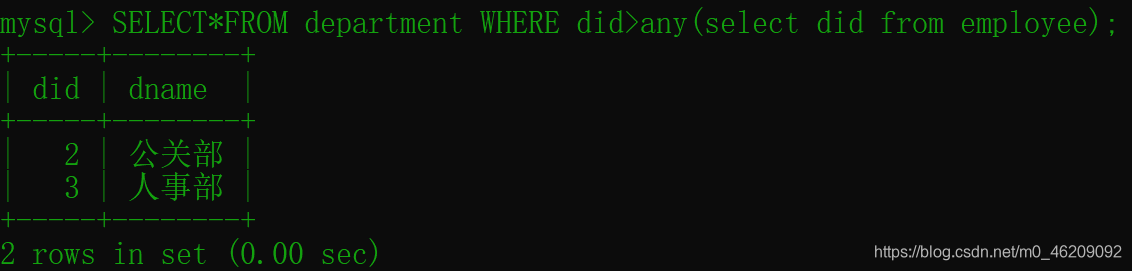
带ANY的关键字的子查询
ANY关键字允许创建一个表达式对子查询的返回值进行比较,只要满足内层子查询中任意一个比较条件,就返回一个结果作为外层查询条件。
--例:
SELECT*FROM department WHERE did>any(select did from employee);
带ALL关键字的子查询
ALL关键字与ANY有点类似,只不过带ALL关键字的子查询返回的结果需同时满足所有内层查询条件。
--例:
SELECT*FROM department WHERE did>all(select did from employee);

带比较运算符的子查询
前面的ANY和ALL关键字的子查询中都使用了比较运算符,常见的有:>,<,>=,!=等
mySQL入门之多表操作的更多相关文章
- Python/MySQL(二、表操作以及连接)
Python/MySQL(二.表操作以及连接) mysql表操作: 主键:一个表只能有一个主键.主键可以由多列组成. 外键 :可以进行联合外键,操作. mysql> create table y ...
- MySQL之库、表操作
一.库操作 创建库 create database 库名(charset utf8 对库的编码进行设置,不写就用默认值) 库名可以由字母.数字.下划线.特殊字符,要区分大小写,唯一性,不能使用关键字, ...
- MySQL(分组、连表操作、备份数据库)
day58 分组 参考:https://www.cnblogs.com/xp796/p/5262187.html select dept, max(salary) from department gr ...
- MySql基础学习-库表操作
1.创建数据 CREATE DATABASE mysql_study; 2.连接数据库 USE mysql_study 3.创建数据表 CREATE TABLE person( id int auto ...
- MYSQL基础笔记(三)-表操作基础
数据表的操作 表与字段是密不可分的. 新增数据表 Create table [if not exists] 表名( 字段名 数据类型, 字段名 数据类型, 字段n 数据类型 --最后一行不需要加逗号 ...
- django连接mysql数据库以及建表操作
django连接mysql数据库需要在project同名的目录下面的__init__.py里面加入下面的东西 import pymysql pymysql.install_as_MySQLdb() 找 ...
- MySQL入门第二天——记录操作与连接查询
常见SQL语法,请参见w3school:http://www.w3school.com.cn/sql/sql_distinct.asp 易百教程:http://www.yiibai.com/sql/f ...
- mysql,数据类型与表操作
一.mysql基本认知 创建用户 create host aa identified with mysql_native_password by ''; 修改用户权限 alter user root@ ...
- MyBatis实现Mysql数据库分库分表操作和总结
前言 作为一个数据库,作为数据库中的一张表,随着用户的增多随着时间的推移,总有一天,数据量会大到一个难以处理的地步.这时仅仅一张表的数据就已经超过了千万,无论是查询还是修改,对于它的操作都会很耗时,这 ...
随机推荐
- 851. Loud and Rich —— weekly contest 87
851. Loud and Rich 题目链接:https://leetcode.com/problems/loud-and-rich/description/ 思路:有向图DFS,记录最小的quie ...
- Servlet学习笔记(三)
目录 Servlet学习笔记(三) 一.HTTP协议 1.请求:客户端发送欸服务器端的数据 2.响应:服务器端发送给客户端的数据 3.响应状态码 二.Response对象 1.Response设置响应 ...
- EntityFramework Core上下文实例池原理分析
前言 无论是在我个人博客还是著作中,对于上下文实例池都只是通过大量文字描述来讲解其基本原理,而且也是浅尝辄止,导致我们对其认识仍是一知半解,本文我们摆源码,从源头开始分析.希望通过本文从源码的分析,我 ...
- CF1320C World of Darkraft: Battle for Azathoth
线段树 又是熟悉的感觉,又是E题写完了,没调完,不过还好上了紫 CF1295E 可以发现可以打败怪兽的关系类似二维偏序 那么首先考虑第一维(武器)以攻击值($a_{i}$)进行排序 把所有的怪兽以防御 ...
- VUE自定义(有限)库存日历插件
开发过程中遇到一个令人发指的,一个element-ui无法满足的日历需求, 改造其日历插件的代价太大,于是索性自己手写一个,需求如下: 1. 根据开始.结束时间计算时间覆盖的月份,渲染有限的可选择日期 ...
- php之4个坐标点判断是否为矩形和正方形
代码 <?php $a=[0,0]; $b=[0,1]; $c=[1,1]; $d=[1,0]; $ar=array($a,$b,$c,$d); $a1=[]; // 0 1 2 3 forea ...
- 企业网络拓扑VRRP主备功能实例(一)
组网图形 VRRP主备备份简介 通常,同一网段内的所有主机上都存在一条相同的.以网关为下一跳的缺省路由.主机发往其他网段的报文将通过缺省路由发往网关,再由网关进行转发,从而实现主机与外部网络的通信. ...
- cgroup实践-资源控制
1.Cgroup安装 安装Cgroups需要libcap-devel和libcgroup两个相关的包 yum install gcc libcap-devel 2.Cgroup挂载配置 Cgroup对 ...
- readonly和disabled的区别!
Readonly只针对input(text / password)和textarea有效 Disabled对于所有的表单元素都有效 readonly接受值更改可以回传,disable接受改但不回传数据 ...
- 没找到Wkhtmltopdf,报表会被显示为html
windows10 odoo 打印报表时提示 没找到Wkhtmltopdf,报表会被显示为html 现象 原因 没有安装Wkhtmltopdf,没有配置环境变量,odoo在电脑系统中找不到Wkhtml ...