使用Python从PDF文件中提取数据
前言
数据是数据科学中任何分析的关键,大多数分析中最常用的数据集类型是存储在逗号分隔值(csv)表中的干净数据。然而,由于可移植文档格式(pdf)文件是最常用的文件格式之一,因此每个数据科学家都应该了解如何从pdf文件中提取数据,并将数据转换为诸
很多人学习python,不知道从何学起。
很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手。
很多已经做案例的人,却不知道如何去学习更加高深的知识。
那么针对这三类人,我给大家提供一个好的学习平台,免费领取视频教程,电子书籍,以及课程的源代码!
QQ群:1097524789
如“csv”之类的格式,以便用于分析或构建模型。
在本文中,我们将重点讨论如何从pdf文件中提取数据表。类似的分析可以用于从pdf文件中提取其他类型的数据,如文本或图像。我们将说明如何从pdf文件中提取数据表,然后将其转换为适合于进一步分析和构建模型的格式。我们将给出一个实例。
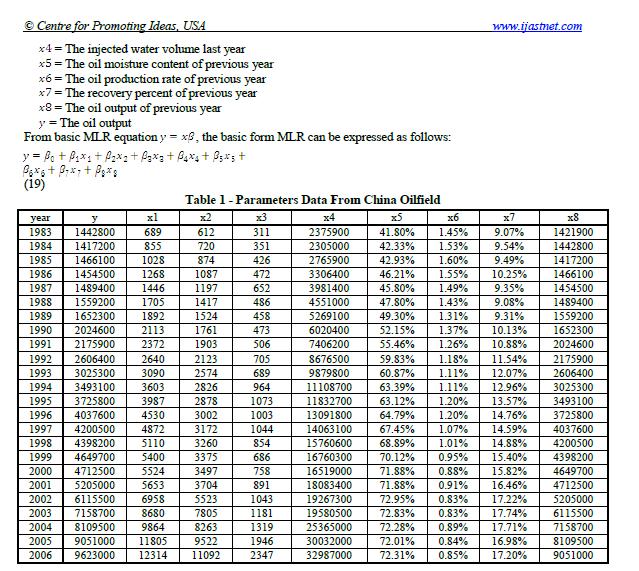
示例:使用Python从PDF文件中提取一个表格
a) 将表复制到Excel并保存为table_1_raw.csv
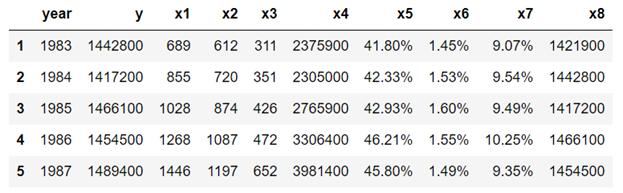
数据以一维格式存储,必须进行重塑、清理和转换。
b) 导入必要的库
- import pandas as pd
- import numpy as np
c) 导入原始数据,重新定义数据
- df=pd.read_csv("table_1_raw.csv", header=None)
- df.values.shape
- df2=pd.DataFrame(df.values.reshape(25,10))
- column_names=df2[0:1].values[0]
- df3=df2[1:]
- df3.columns = df2[0:1].values[0]
- df3.head()
d) 使用字符串处理工具进行数据纠缠
我们从上面的表格中注意到,x5、x6和x7列是用百分比表示的,所以我们需要去掉percent(%)符号:
- df4['x5']=list(map(lambda x: x[:-1], df4['x5'].values))
- df4['x6']=list(map(lambda x: x[:-1], df4['x6'].values))
- df4['x7']=list(map(lambda x: x[:-1], df4['x7'].values))
e) 将数据转换为数字形式
我们注意到列x5、x6和x7的列值数据类型为string,因此我们需要将它们转换为数值数据,如下所示:
- df4['x5']=[float(x) for x in df4['x5'].values]
- df4['x6']=[float(x) for x in df4['x6'].values]
- df4['x7']=[float(x) for x in df4['x7'].values]
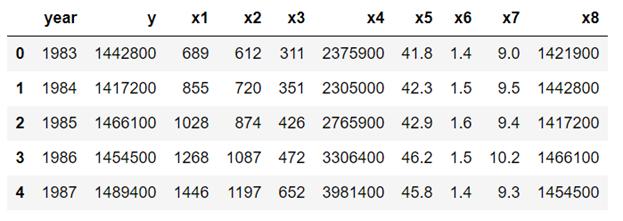
f) 查看转换数据的最终形式
- df4.head(n=5)
g) 导出最终数据到一个csv文件
- df4.to_csv('table_1_final.csv',index=False)
使用Python从PDF文件中提取数据的更多相关文章
- [数据科学] 从csv, xls文件中提取数据
在python语言中,用丰富的函数库来从文件中提取数据,这篇博客讲解怎么从csv, xls文件中得到想要的数据. 点击下载数据文件http://seanlahman.com/files/databas ...
- 【Python】从文件中读取数据
从文件中读取数据 1.1 读取整个文件 要读取文件,需要一个包含几行文本的文件(文件PI_DESC.txt与file_reader.py在同一目录下) PI_DESC.txt 3.1415926535 ...
- 如何使用JMeter从文件中提取数据
在性能测试方面,重用响应数据至关重要.几乎(如果不是全部!)负载测试场景假设您: 从先前的响应中提取有趣的方面,并在下一个请求中重用它们(也称为相关) 确保实际响应符合预期(又称断言) 因此,如果您是 ...
- [Python]将Excel文件中的数据导入MySQL
Github Link 需求 现有2000+文件夹,每个文件夹下有若干excel文件,现在要将这些excel文件中的数据导入mysql. 每个excel文件的第一行是无效数据. 除了excel文件中已 ...
- 如何从PDF文件中提取矢量图
很多时候我们需要PDF文档中的插图,直接用pdf中的复制或者截屏软件只能提取位图格式的图片,放大缩小难免失真. 本文教大家一种一种从pdf中提取矢量图的方法. 工具软件: 1 adobe acroba ...
- matlab从fig文件中提取数据
如果你的fig文件中图像是由多条曲线绘制而成,比如说plot命令生成的,通过以下方式输出横坐标,纵坐标的取值 open('figname.fig'); lh = findall(gca, 'type' ...
- python : 将txt文件中的数据读为numpy数组或列表
很多时候,我们将数据存在txt或者csv格式的文件里,最后再用python读取出来,存到数组或者列表里,再做相应计算.本文首先介绍写入txt的方法,再根据不同的需求(存为数组还是list),介绍从tx ...
- [数据科学] 从text, json文件中提取数据
文本文件是基本的文件类型,不管是csv, xls, json, 还是xml等等都可以按照文本文件的形式读取. #-*- coding: utf-8 -*- fpath = "data/tex ...
- python在json文件中提取IP和域名
# qianxiao996精心制作 #博客地址:https://blog.csdn.net/qq_36374896 import re def openjson(path): f = open(pat ...
随机推荐
- A Mountaineer 最详细的解题报告
题目来源:A Mountaineer (不知道该链接是否可以直接访问,所以将题目复制下来了) 题目如下: D - A Mountaineer Time limit : 2sec / Stack lim ...
- 【C#】WebService接受跨域请求及返回json数据
问题概述 通过Web Service发布服务供客户端调用是一种非常简单.方便.快速的手段,并且服务发布后会有一个服务说明页面,直观明了,如图: 一般情况下,在web页面中的JavaScript中调用W ...
- java实现判断时间是否为合法时间
最近遇到一个需求,输入字符串,判断为日期的话再进行后面的比较大小之类的操作,但是合法日期的格式也是比较多的,利用正则表达式又太长了.所以后面利用的方法就是,先把输入的字符串转成一种固定的时间格式,然后 ...
- Oracle RMAN 异机恢复一例
背景介绍:本例需求是将NBU备份的oracle数据库恢复到另一主机上. NBU环境配置.异机上的Oracle软件安装配置忽略,下面只介绍OracleDB恢复的过程. ----------------- ...
- CentOS8.0 Docker Repository
一.硬件软件准备 1.2台服务器或者电脑(使用云服务器1.阿里云 2.百度云各一台) ,系统均为CentOS 8.0 2.分别安装Docker 3.测试镜像准备(准备的是 ...
- LGTB 与 序列
题目描述 LGTB 有一个长度为 N 的序列 A ,现在他想构造一个新的长度为 N 的序列 B ,使得 B 中的任意两个数都互质.并且他要使 \sum_{1\le i\le N}|A_i-B_i| 最 ...
- static关键字和final关键字
static关键字和final关键字 static(静态) 作用 用来修饰属性.方法.代码块.内部类 static修饰属性 表示静态变量(类变量) 按是否使用static修饰,属性的分类 静态属性 当 ...
- ThinkPHP5.0、5.1和6.0教程文档合集(免费下载)
我们都知道ThinkPHP是一个免费开源的,快速.简单的面向对象的轻量级PHP开发框架. ThinkPHP6主要更新了什么呢? 1. 支持PHP最新的强类型 2. PSR开发规范得了更广泛的应用 3. ...
- APP自动化 -- TouchAction(触屏)
- 给Django Admin添加验证码和多次登录尝试限制
Django自带的Admin很好用,但是放到生产环境总还差了点什么= = 看看admin的介绍: Django奉行Python的内置电池哲学.它自带了一系列在Web开发中用于解决常见问题或需求的额外的 ...