准备数据集用于flink学习
欢迎访问我的GitHub
https://github.com/zq2599/blog_demos
内容:所有原创文章分类汇总及配套源码,涉及Java、Docker、Kubernetes、DevOPS等;
在学习和开发flink的过程中,经常需要准备数据集用来验证我们的程序,阿里云天池公开数据集中有一份淘宝用户行为数据集,稍作处理后即可用于flink学习;
下载
下载地址:
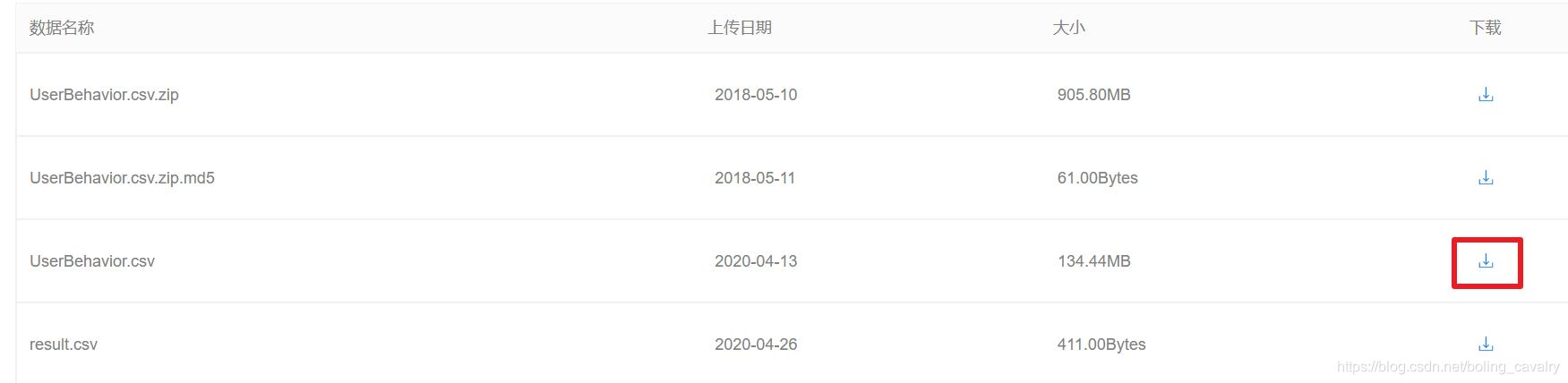
https://tianchi.aliyun.com/dataset/dataDetail?spm=a2c4e.11153940.0.0.671a1345nJ9dRR&dataId=649如下图所示,点击红框中的图标下载(名为UserBehavior.csv.zip的文件太大无法在excel打开,因此下载体积小一些的UserBehavior.csv):
该CSV文件的内容,一共有五列,每列的含义如下表:
| 列名称 | 说明 |
|---|---|
| 用户ID | 整数类型,序列化后的用户ID |
| 商品ID | 整数类型,序列化后的商品ID |
| 商品类目ID | 整数类型,序列化后的商品所属类目ID |
| 行为类型 | 字符串,枚举类型,包括('pv', 'buy', 'cart', 'fav') |
| 时间戳 | 行为发生的时间戳 |
| 时间字符串 | 根据时间戳字段生成的时间字符串 |
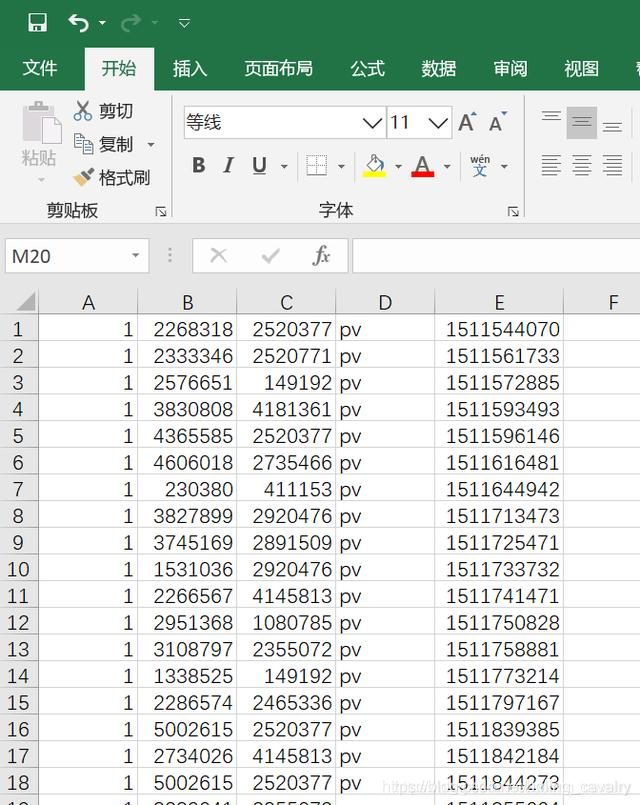
- 下载完毕后用excel打开,如下图所示:
增加一个字段
为了便于检查数据,接下来在时间戳字段之后新增一个字段,内容是将该行的时间戳转成时间字符串
- 如下图,在F列的第一行位置输入表达式,将E1的时间戳转成字符串:
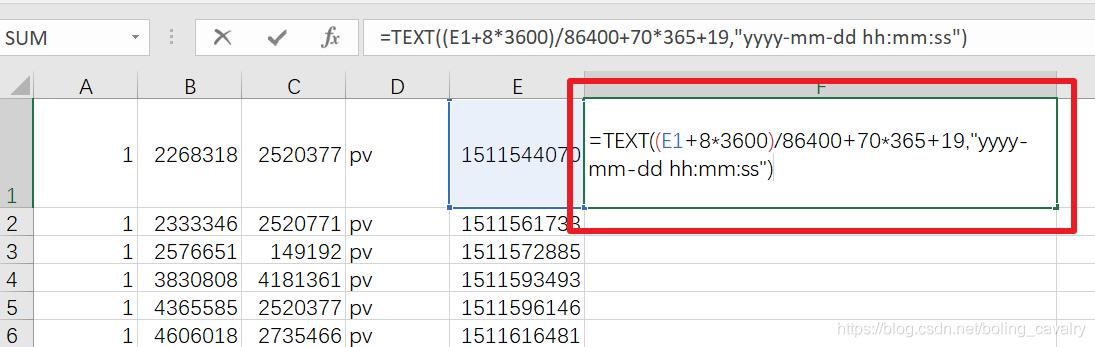
- 上图红框中的表达式内容如下:
=TEXT((E1+8*3600)/86400+70*365+19,"yyyy-mm-dd hh:mm:ss")
- !!!有个问题要格外注意!!!:上述表达式中,由于8*3600的作用,得到的时间字符串实际上是东八区时区的时间,在flink sql中,如果用DATE_FORMAT函数计算timestamp也能得到时间字符串,但是这个字符串是格林尼治时区,此时两个时间字符串的值就不同了,例如从F列看2017/11/12和2017/11/13各一条记录,但是DATE_FORMAT函数计算timestamp得到的却是2017/11/12有两条记录,解决这个问题的办法就是将表达式中的8*3600去掉,大家都用格林尼治时区;
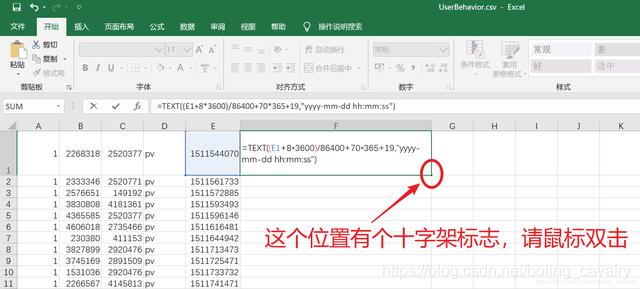
- 表达式生效后,F1的内容就是E1的时间字符串,接下来F列的所有记录都作转换,鼠标放在下图红框位置时,会出现十字架标志,在此标志上双击鼠标:
5. 完成后如下图,F列的时间信息更利于我们开发过程中核对数据:
修复乱序
- 此时的CSV文件中的数据并不是按时间字段排序的,如下图:
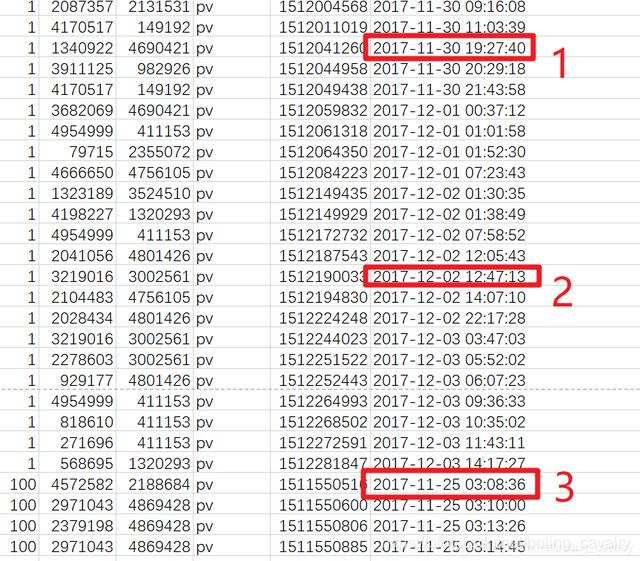
- flink在处理上述数据时,由于乱序问题可能会导致计算结果不准,以上图为例,在处理红框2中的数据时,红框3所对应的窗口早就完成计算了,虽然flink的watermark可以容忍一定程度的乱序,但是必须将容忍时间调整为7天才能将红框3的窗口保留下来不触发,这样的watermark调整会导致大量数据无法计算,因此,需要将此CSV的数据按照时间排序再拿来使用;
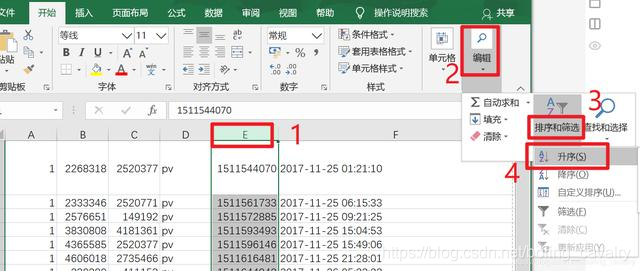
- 如下图操作即可完成排序:
4. 完成排序后如下图所示:
至此,一份淘宝用户行为数据集就准备完毕了,接下来的文章将会用此数据进行flink相关的实战;
直接下载准备好的数据
- 为了便于您快速使用,上述调整过的CSV文件我已经上传到CSDN,地址:
https://download.csdn.net/download/boling_cavalry/12381698 - 也可以在我的Github下载,地址:
https://raw.githubusercontent.com/zq2599/blog_demos/master/files/UserBehavior.7z
欢迎关注公众号:程序员欣宸
微信搜索「程序员欣宸」,我是欣宸,期待与您一同畅游Java世界...
https://github.com/zq2599/blog_demos
准备数据集用于flink学习的更多相关文章
- 入门大数据---Flink学习总括
第一节 初识 Flink 在数据激增的时代,催生出了一批计算框架.最早期比较流行的有MapReduce,然后有Spark,直到现在越来越多的公司采用Flink处理.Flink相对前两个框架真正做到了高 ...
- 利用Mono.Cecil动态修改程序集来破解商业组件(仅用于研究学习)
原文 利用Mono.Cecil动态修改程序集来破解商业组件(仅用于研究学习) Mono.Cecil是一个强大的MSIL的注入工具,利用它可以实现动态创建程序集,也可以实现拦截器横向切入动态方法,甚至还 ...
- StarSpace是用于高效学习实体向量的通用神经模型
StarSpace是用于高效学习实体向量的通用神经模型,用于解决各种各样的问题: 学习单词,句子或文档级嵌入. 文本分类或任何其他标签任务. 信息检索:实体/文件或对象集合的排序,例如 排名网络文件. ...
- Apache Flink学习笔记
Apache Flink学习笔记 简介 大数据的计算引擎分为4代 第一代:Hadoop承载的MapReduce.它将计算分为两个阶段,分别为Map和Reduce.对于上层应用来说,就要想办法去拆分算法 ...
- ref:一系列用于Fuzzing学习的资源汇总
ref:http://www.freebuf.com/articles/rookie/169413.html 一系列用于Fuzzing学习的资源汇总 secist2018-04-30共185833人围 ...
- flink学习笔记-各种Time
说明:本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKh ...
- Flink学习笔记:Flink API 通用基本概念
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- flink学习笔记:DataSream API
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
- Flink学习笔记:Operators之Process Function
本文为<Flink大数据项目实战>学习笔记,想通过视频系统学习Flink这个最火爆的大数据计算框架的同学,推荐学习课程: Flink大数据项目实战:http://t.cn/EJtKhaz ...
随机推荐
- roles学习笔记(模拟安装httpd服务)
这是目录(app 是模拟的角色) [root@test ansible]# tree.├── app_role.retry├── app_role.yml├── httpd_role.yml├── n ...
- 手工实现docker的vxlan
前几天了解了一下docker overlay的原理,然后一直想验证一下自己的理解是否正确,今天模仿docker手工搭建了一个overlay网络.先上拓扑图,其实和上次画的基本一样.我下面提到的另一台机 ...
- 多测师讲解自动化测试 _RF分配id_高级讲师肖sir
1.Assign Id To Element.
- linux centos 04
1.python的虚拟环境 1.将当前机器上的解释器作为一个 本地,复制出的很多歌 虚拟解释器 物理机上的 本体解释器 ,什么事也不做 分身1: 解释器1:虚拟环境1 运行django 1 ...
- 并查集算法Union-Find的思想、实现以及应用
并查集算法,也叫Union-Find算法,主要用于解决图论中的动态连通性问题. Union-Find算法类 这里直接给出并查集算法类UnionFind.class,如下: /** * Union-Fi ...
- Python之format字符串格式化
1.字符串连接 >>> a = 'My name is ' + 'Suen' >>> a 'My name is Suen' >>> a = 'M ...
- Linux的安全模型
3A 资源分派: Authentication:认证,验证用户身份 Authorization:授权,不同的用户设置不同权限 Accouting|Audition:审计 当用户登录成功时,系统会自动分 ...
- centos之间如何实现免密ssh登陆
在公司产品中,管理平台和下面的主机很多时候都要求免密,免密的逻辑到底是怎么样的呢?今天就简单看看! 首先创建两台虚机,正常情况下ssh登陆对方是需要密码的 先通过ssh-keygen生成一对秘钥 [r ...
- ssm整合之applicationContext.xml
<?xml version="1.0" encoding="UTF-8"?><beans xmlns="http://www.spr ...
- centos7安装oracle版本的jdk
Hadoop机器上的JDK,最好是Oracle的Java JDK,不然会有一些问题,比如可能没有JPS命令. 如果安装了其他版本的JDK,卸载掉!!! 1,查看是否已经安装了jdk java -ver ...