架构设计 | 基于Seata中间件,微服务模式下事务管理
源码地址:GitHub·点这里 || GitEE·点这里
一、Seata简介
1、Seata组件
Seata是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务。Seata将为用户提供了AT、TCC、SAGA、XA事务模式,为用户打造一站式的分布式解决方案。
2、支持模式
AT 模式
- 基于支持本地 ACID 事务的关系型数据库。
- Java应用,通过 JDBC 访问数据库。
一阶段:业务数据和回滚日志记录在同一个本地事务中提交,释放本地锁和连接资源。
二阶段:提交异步化,非常快速地完成。回滚通过一阶段的回滚日志进行反向补偿。
TCC模式
一个分布式的全局事务,整体是两阶段提交的模型,全局事务是由若干分支事务组成的,分支事务要满足两阶段提交的模型要求,即需要每个分支事务都具备自己的:
一阶段 prepare 行为
二阶段 commit 或 rollback 行为
Saga模式
Saga模式是SEATA提供的长事务解决方案,在Saga模式中,业务流程中每个参与者都提交本地事务,当出现某一个参与者失败则补偿前面已经成功的参与者,一阶段正向服务和二阶段补偿服务都由业务开发实现。
XA模式
XA是一个分布式事务协议,对业务无侵入的分布式事务解决方案,XA提交协议需要事务参与者的数据库支持,XA事务具有强一致性,在两阶段提交的整个过程中,一直会持有资源的锁,性能不理想的缺点很明显。
二、服务端部署
1、下载组件包
1.2版本:seata-server-1.2.0.zip
解压目录
- bin:存放服务端运行启动脚本;
- lib:存放服务端依赖的资源jar包;
- conf:配置文件目录。
2、修改配置
file.conf配置
mode:db 即使用数据库存储事务信息,这里还可以选择file存储方式。
file模式为单机模式,全局事务会话信息内存中读写并持久化本地文件root.data,性能较高;
db模式为高可用模式,全局事务会话信息通过db共享,相应性能差些;
redis模式Seata-Server 1.3及以上版本支持,性能较高,存在事务信息丢失风险,请提前配置合适当前场景的redis持久化配置.
store {
## store mode: file、db
mode = "db"
db {
datasource = "druid"
dbType = "mysql"
driverClassName = "com.mysql.jdbc.Driver"
url = "jdbc:mysql://127.0.0.1:3306/seata_server"
user = "root"
password = "123456"
minConn = 5
maxConn = 30
globalTable = "global_table"
branchTable = "branch_table"
lockTable = "lock_table"
queryLimit = 100
maxWait = 5000
}
}
registry.conf配置
这里选择eureka作为注册中心,seata-server也要作为一个服务添加到注册中心,不使用配置中心所以config配置默认即可。
registry {
# file 、nacos 、eureka、redis、zk、consul、etcd3、sofa
type = "eureka"
eureka {
serviceUrl = "http://localhost:8761/eureka"
application = "default"
weight = "1"
}
}
3、事务管理表
需要在seata-server即上述配置的MySQL库中建立3张事务管理表:
- 全局事务:global_table
- 分支事务:branch_table
- 全局锁:lock_table
- 事务回滚:undo_log
- SQL脚本:mysql-script目录
4、启动命令
Linux环境:sh seata-server.sh
三、业务服务搭建
1、代码结构
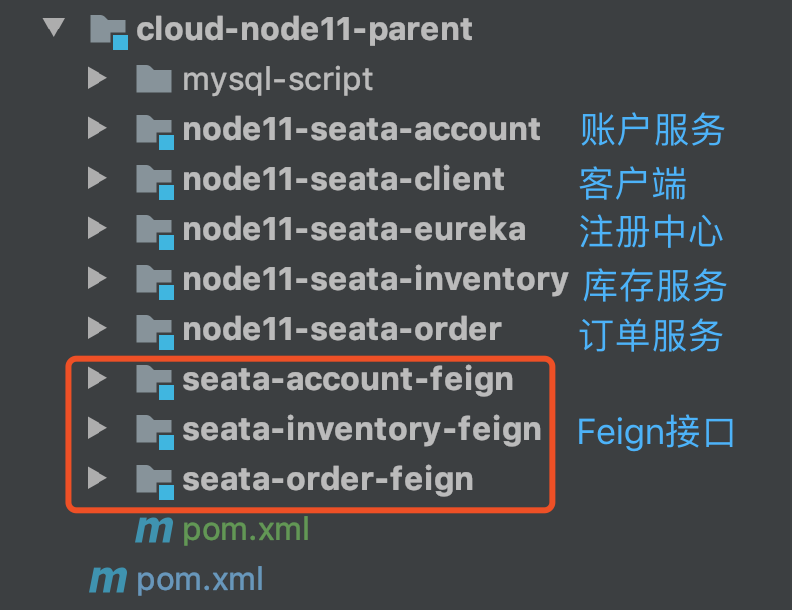
- seata-eureka:注册中心
- seata-order:订单服务
- seata-account:账户服务
- seata-inventor:库存服务
- seata-client:客户端服务
- account-feign:账户Feign接口
- inventory-feign:库存Feign接口
- order-feign:订单Feign接口
请求链路:客户端->订单->账户+库存,测试整个流程的分布式事务问题。
2、数据库结构

- seata_server:seata组件服务端依赖库
- seata_account:模拟账户数据库
- seata_inventor:模拟库存数据库
- seata_order:模拟订单数据库
各个库脚本位置:mysql-script/data-biz.sql
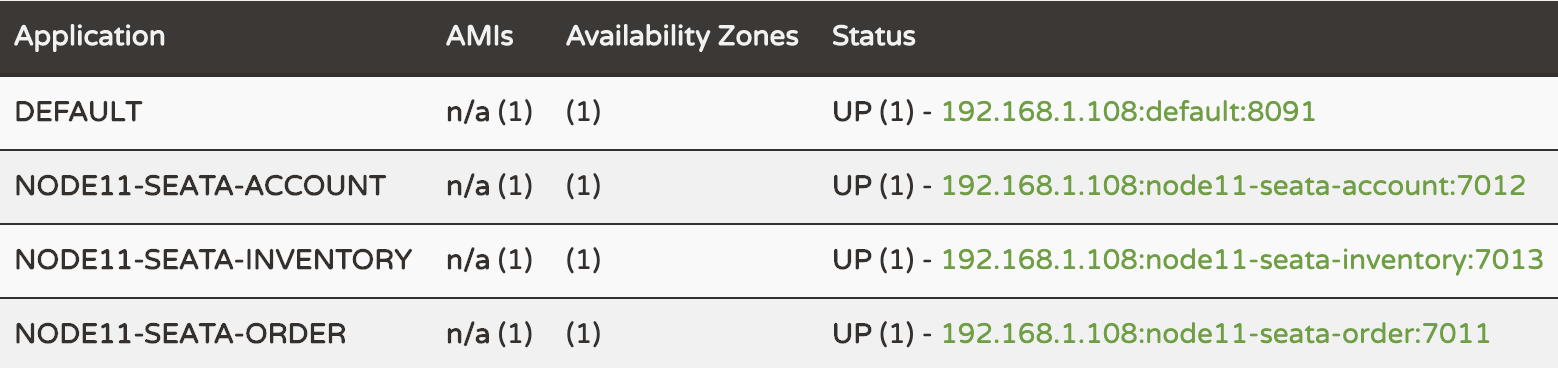
3、启动服务
依次启动:注册中心,库存服务,账户服务,订单服务,客户端服务;
Eureka服务列表如下:
四、Seata用法详解
1、Seata基础配置
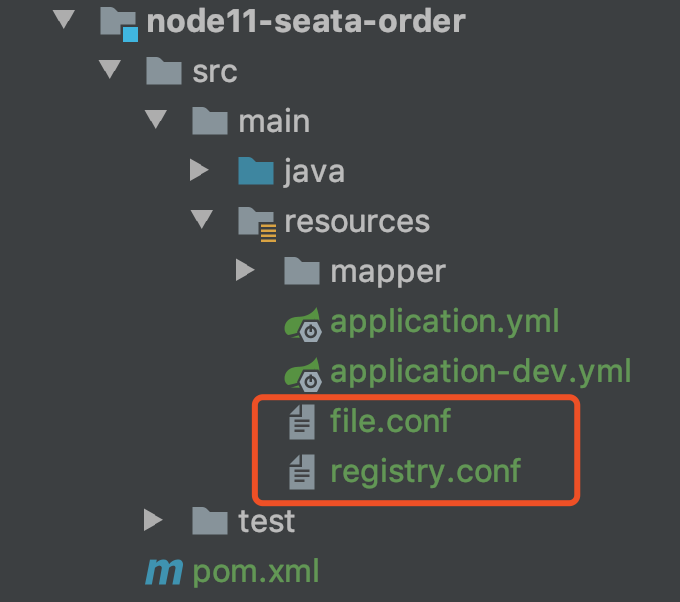
几个基础服务的配置方式一样。
conf配置
file.conf重点关注下面内容,事务组的名称,需要在yml文件中使用。
my_test_tx_group = "default"
registry.conf:是注册中心的选择。
2、数据库配置
注意这里的事务组名称配置。
spring:
# 事务组的名称
cloud:
alibaba:
seata:
tx-service-group: my_test_tx_group
# 数据源配置
datasource:
type: com.alibaba.druid.pool.DruidDataSource
druid:
driverClassName: com.mysql.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/seata_account
username: root
password: 123456
将数据库整体由Seata进行代理管理,核心API:DataSourceProxy。
@Configuration
public class SeataAccountConfig {
@Value("${spring.application.name}")
private String applicationName;
@Bean
public GlobalTransactionScanner globalTransactionScanner() {
return new GlobalTransactionScanner(applicationName, "test-tx-group");
}
@Bean
@ConfigurationProperties(prefix = "spring.datasource.druid")
public DruidDataSource druidDataSource() {
return new DruidDataSource() ;
}
@Primary
@Bean("dataSource")
public DataSourceProxy dataSourceProxy(DataSource druidDataSource) {
return new DataSourceProxy(druidDataSource);
}
@Bean
public SqlSessionFactory sqlSessionFactory(DataSourceProxy dataSourceProxy)throws Exception{
SqlSessionFactoryBean sqlSessionFactoryBean = new SqlSessionFactoryBean();
sqlSessionFactoryBean.setDataSource(dataSourceProxy);
sqlSessionFactoryBean.setMapperLocations(new PathMatchingResourcePatternResolver()
.getResources("classpath*:/mapper/*.xml"));
sqlSessionFactoryBean.setTransactionFactory(new SpringManagedTransactionFactory());
return sqlSessionFactoryBean.getObject();
}
}
3、业务代码
核心注解:GlobalTransactional,管理整体的分布式事务。
@Service
public class OrderServiceImpl implements OrderService {
private final Logger LOGGER = LoggerFactory.getLogger(OrderServiceImpl.class);
@Resource
private OrderMapper orderMapper ;
@Resource
private AccountFeign accountFeign ;
@Resource
private InventoryFeign inventoryFeign ;
@GlobalTransactional
@Override
public Integer createOrder(String orderNo) {
LOGGER.info("Order 生成中 "+orderNo);
// 本服务下订单库
Integer insertFlag = orderMapper.insert(orderNo) ;
// 基于feign接口处理账户和库存
accountFeign.updateAccount(10L) ;
inventoryFeign.updateInventory(10) ;
return insertFlag ;
}
}
测试流程:在任意服务下抛出异常,观察整体的事务状态,观察是否有整体的事务控制效果。
五、源代码地址
GitHub地址:知了一笑
https://github.com/cicadasmile/spring-cloud-base
GitEE地址:知了一笑
https://gitee.com/cicadasmile/spring-cloud-base
推荐阅读:架构设计系列
架构设计 | 基于Seata中间件,微服务模式下事务管理的更多相关文章
- 2流高手速成记(之八):基于Sentinel实现微服务体系下的限流与熔断
我们接上回 上一篇中,我们进行了简要的微服务实现,也体会到了SpringCloudAlibaba的强大和神奇之处 我们仅改动了两个注释,其他全篇代码不变,原来的独立服务就被我们分为了provider和 ...
- 24 | 紧跟时代步伐:微服务模式下API测试要怎么做?
- 使用 Loki 微服务模式部署生产集群
转载自:https://mp.weixin.qq.com/s?__biz=MzU4MjQ0MTU4Ng==&mid=2247500523&idx=1&sn=0994af2b50 ...
- Java开发架构篇:领域驱动设计架构基于SpringCloud搭建微服务
作者:小傅哥 博客:https://bugstack.cn 沉淀.分享.成长,让自己和他人都能有所收获! 一.前言介绍 微服务不是泥球小单体,而是具备更加清晰职责边界的完整一体的业务功能服务.领域驱动 ...
- 基于 Docker 的微服务架构实践
本文来自作者 未闻 在 GitChat 分享的{基于 Docker 的微服务架构实践} 前言 基于 Docker 的容器技术是在2015年的时候开始接触的,两年多的时间,作为一名 Docker 的 D ...
- 通过Dapr实现一个简单的基于.net的微服务电商系统(十九)——分布式事务之Saga模式
在之前的系列文章中聊过分布式事务的一种实现方案,即通过在集群中暴露actor服务来实现分布式事务的本地原子化.但是actor服务本身有其特殊性,场景上并不通用.所以今天来讲讲分布式事务实现方案之sag ...
- iUAP云运维平台v3.0全面支持基于K8s的微服务架构
什么是微服务架构? 微服务(MicroServices)架构是当前互联网业界的一个技术热点,业内各公司也都纷纷开展微服务化体系建设.微服务架构的本质,是用一些功能比较明确.业务比较精练的服务去解决更大 ...
- 用友iuap云运维平台支持基于K8s的微服务架构
什么是微服务架构? 微服务(MicroServices)架构是当前互联网业界的一个技术热点,业内各公司也都纷纷开展微服务化体系建设.微服务架构的本质,是用一些功能比较明确.业务比较精练的服务去解决更大 ...
- (转)微服务架构 互联网保险O2O平台微服务架构设计
http://www.cnblogs.com/Leo_wl/p/5049722.html 微服务架构 互联网保险O2O平台微服务架构设计 关于架构,笔者认为并不是越复杂越好,而是相反,简单就是硬道理也 ...
随机推荐
- 关于Dapper实现读写分离的个人思考
概念相关 为了确保多线上环境数据库的稳定性和可用性,大部分情况下都使用了双机热备的技术.一般是一个主库+一个从库或者多个从库的结构,从库的数据来自于主库的同步.在此基础上我们可以通过数据库反向 ...
- 【面经】超硬核面经,已拿蚂蚁金服Offer!!
写在前面 很多小伙伴都反馈说,现在的工作不好找呀,也不敢跳槽,在原来的岗位上也是战战兢兢!其实,究其根本原因,还是自己技术不过关,如果你技术真的很硬核,怕啥?想去哪去哪呗!这不,我的一个读者去面试了蚂 ...
- go语言gRPC系列(二) - 为gRPC添加证书
1. 前言 2. 生成自签证书 2.1 MAC生成自签证书的教程链接: 2.2 Windows生成自签证书的教程 3. 改造服务端使用自签证书 3.1 复制证书至代码下 3.2 改造代码添加证书认证 ...
- 《Java从入门到失业》第二章:Java环境(一):Java SE安装
从这一章开始,终于我们可以开始正式进入Java世界了.前面我们提到过,Java分三个版本,我们这里只讨论Java SE. 2.1Java SE安装 所谓工欲善其事,必先利其器.第一步,我们当然是要下载 ...
- pyttsx3 的使用教程
import pyttsx3 def use_pyttsx3(): # 创建对象 engine = pyttsx3.init() # 获取当前语音速率 rate = engine.getPropert ...
- JAVA HTML 以压缩包下载多文件
Html: 利用form表单来发送下载请求 <form id ="submitForm" method="post"> </form> ...
- ElasticSearch实战系列八: Filebeat快速入门和使用---图文详解
前言 本文主要介绍的是ELK日志系统中的Filebeat快速入门教程. ELK介绍 ELK是三个开源软件的缩写,分别表示:Elasticsearch , Logstash, Kibana , 它们都是 ...
- linux驱动之内核多线程(一)
本文摘自http://www.cnblogs.com/zhuyp1015/archive/2012/06/11/2545624.html Linux内核可以看作一个服务进程(管理软硬件资源,响应用户进 ...
- You are using pip version 10.0.1, however version 20.2.2 is available.
在安装第三方库时,出现如下提示: You are using pip version 10.0.1, however version 20.2.2 is available.You should co ...
- A Review on Generative Adversarial Networks: Algorithms, Theory, and Applications
1 Introduction GANs由两个模型组成:生成器和鉴别器.生成器试图捕获真实示例的分布,以便生成新的数据样本.鉴别器通常是一个二值分类器,尽可能准确地将生成样本与真实样本区分开来.GANs ...