ElasticSearch学习笔记(超详细)
文章目录
- 初识ElasticSearch
- 什么是ElasticSearch
- ElasticSearch特点
- ElasticSearch用途
- ElasticSearch底层实现
- ElasticSearch和Solr的区别
- Solr是什么
- 不同场景时两个的对比
- 总结
- ElasticSearch体系结构
- 倒排索引
- 什么是Term Dictionary
- 什么是Term Index
- 为什么 Elasticsearch/Lucene 检索可以比 MySQL快
- 什么是ELK
- 安装ElasticSearch
- 安装ik分词器
- 测试ik分词器
- IK分词器的两种分词模式
- ik分词器添加自定义词库
- 安装ElasticSearch-head
- 安装Kibana
- REST风格说明
- 什么是REST风格
- 基本REST命令说明
- PUT命令
- 创建类型
- 插入数据
- 更新数据
- POST命令
- 更新数据(推荐使用)
- DELETE命令
- GET命令
- 查询数据(重点)
- 精确查询
- 查询字符串搜索
- 查询所有结果
- 条件查询
- 布尔查询
- 按排序查询
- 分页查询
- 指定查询结果的字段
- 高亮查询
- 拓展
初识ElasticSearch
什么是ElasticSearch
Elasticsearch 是一个分布式的开源搜索和分析引擎,适用于所有类型的数据,包括文本、数字、地理空间、结构化和非结构化数据。它可以帮助你用前所未有的速度去处理大规模数据。ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
ElasticSearch特点
- 可以作为一个大型分布式集群(数百台服务器)技术,处理PB级数据,服务大公司;也可以运行在单机上,服务小公司
- 对用户而言,是开箱即用的,非常简单,作为中小型的应用,直接3分钟部署一下ES
- Elasticsearch作为传统数据库的一个补充,比如全文检索,同义词处理,相关度排名,复杂数据分析,海量数据的近实时处理
- Elasticsearch不是什么新技术,主要是将全文检索、数据分析以及分布式技术,合并在了一起,才形成了独一无二的ES;lucene(全文检索),商用的数据分析软件(也是有的),分布式数据库(mycat)
ElasticSearch用途
Elasticsearch 在速度和可扩展性方面都表现出色,而且还能够索引多种类型的内容,这意味着其可用于多种用例:
- 应用程序搜索
- 网站搜索
- 企业搜索
- 日志处理和分析
- 基础设施指标和容器监测
- 应用程序性能监测
- 地理空间数据分析和可视化
- 安全分析
- 业务分析
维基百科使用Elasticsearch提供全文搜索并高亮关键字,以及输入实时搜索(search-asyou-type)和搜索纠错(did-you-mean)等搜索建议功能。
英国卫报使用Elasticsearch结合用户日志和社交网络数据提供给他们的编辑以实时的反馈,以便及时了解公众对新发表的文章的回应。
Github使用Elasticsearch检索1300亿行的代码。
ElasticSearch底层实现
ElasticSearch是基于对 Lucene 进行封装,将搜索引擎的操作封装成了RESTful API,通过http请求就可以调用,目的是为了隐藏Lucene的复杂性,从而让全文搜索变得简单。
ElasticSearch和Solr的区别
Solr是什么
Solr 是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器。Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化。
Solr可以独立运行,运行在Jetty、Tomcat等这些Servlet容器中,Solr 索引的实现方法很简单,用 POST 方法向 Solr 服务器发送一个描述 Field 及其内容的 XML 文档,Solr根据xml文档添加、删除、更新索引 。Solr 搜索只需要发送 HTTP GET 请求,然后对 Solr 返回Xml、json等格式的查询结果进行解析,组织页面布局。Solr不提供构建UI的功能,Solr提供了一个管理界面,通过管理界面可以查询Solr的配置和运行情况。
Solr是基于lucene开发企业级搜索服务器,实际上就是封装了lucene。
Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的文件,生成索引;也可以通过提出查找请求,并得到返回结果。
不同场景时两个的对比

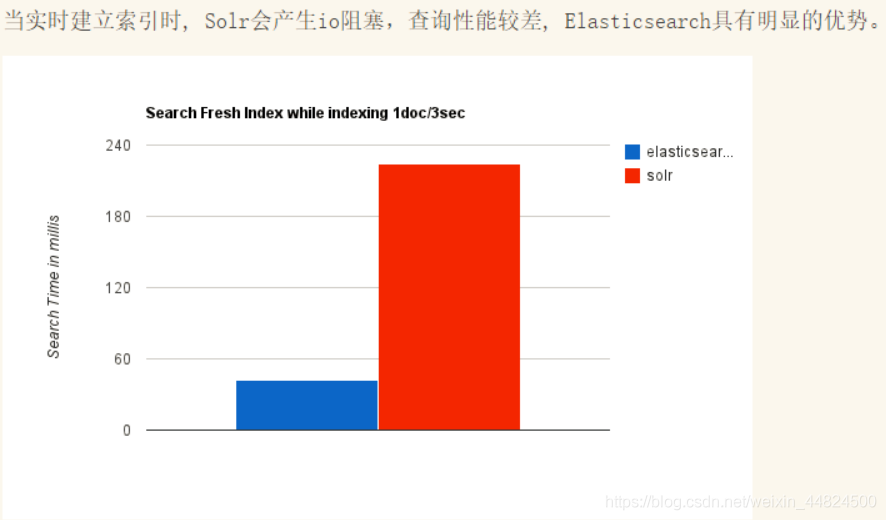
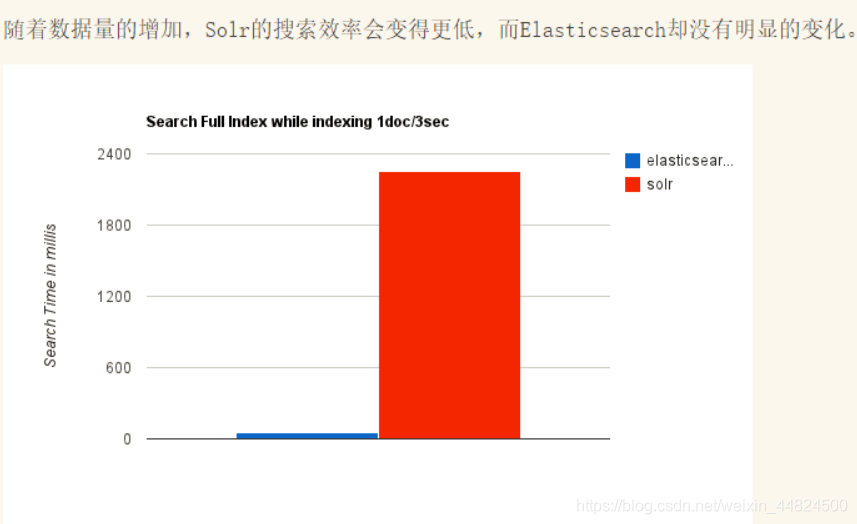
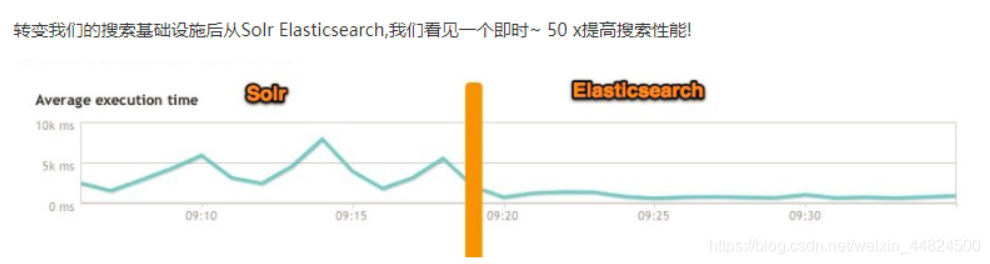
总结
(1)es基本是开箱即用,非常简单。Solr安装略微复杂一点。
(2)Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能。
(3)Solr 支持更多格式的数据,比如JSON、XML、CSV,而 Elasticsearch 仅支持json文件格式。
(4)Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高级功能多有第三方插件提供,例如图形化界面需要kibana支撑
(5)Solr 查询快,但更新索引时慢(即插入删除慢),用于电商等查询多的应用;ES建立索引快(即查询慢),即实时性查询快,用于FaceBook、百度等搜索。Solr 是传统搜索应用的有力解决方案,但 Elasticsearch 更适用于新兴的实时搜索应用。
(6)Solr比较成熟,有一个更大,更成熟的用户、开发和贡献者社区,而 Elasticsearch相对开发维护者较少,更新太快,学习使用成本较高。
ElasticSearch体系结构
初学者建议将 ElasticSearch当为一个数据库进行学习。
下图是Elasticsearch与关系型数据库逻辑结构概念的对比: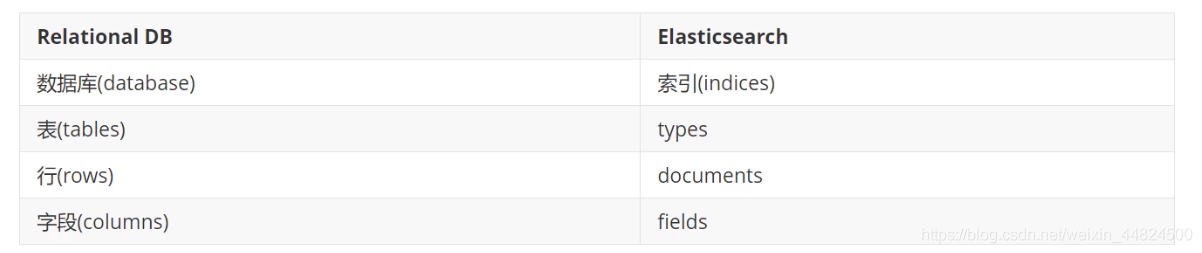
倒排索引
倒排索引(Inverted Index)也叫反向索引,有反向索引必有正向索引。通俗地来讲,正向索引是通过key找value,反向索引则是通过value找key。
正向索引:
MYSQL数据库所用的索引就是正向索引,适合根据文档中的ID来查询对应的内容。但是在查询一个keyword在哪些文档里包含的时候需对所有的文档进行扫描以确保没有遗漏,这样就使得检索时间大大延长,检索效率低下。
正向索引构建的结果如下图: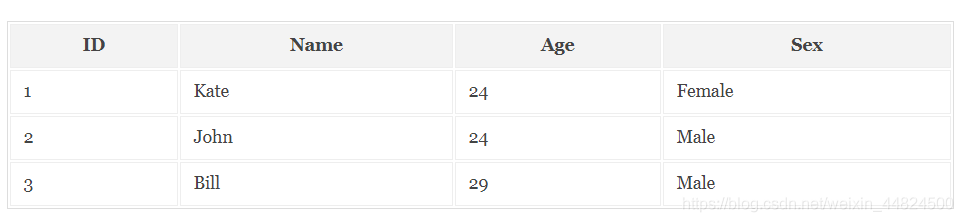
倒排索引:
与正序索引相反。在搜索引擎中每个文件都对应一个文件ID,文件内容被表示为一系列关键词的集合,记录每个关键字在文档中出现的频率和出现的位置。
按照上面的文档内容构建的倒排索引结果会如下图: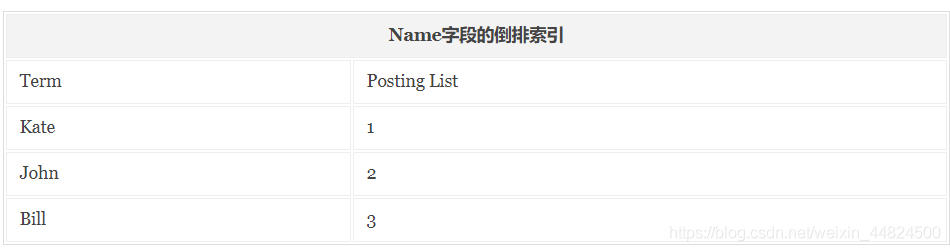
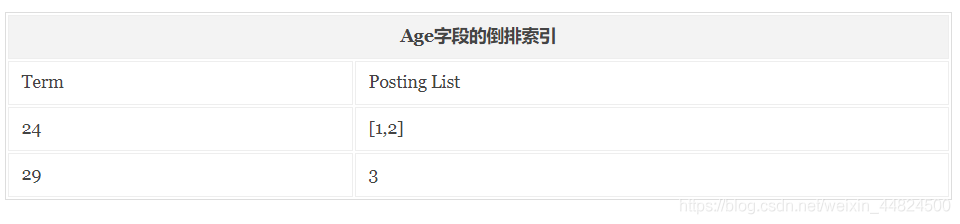

如果我们要通过倒排索引查找‘Male’这个关键词在哪些文档中出现过,首先我们通过倒排索引可以查询到该关键词出现的文档位置是在2和3中;然后再通过正排索引查询到文档2和3的内容并返回结果。
什么是Term Dictionary
Elasticsearch为了能快速找到某个Term,将所有的Term排个序,二分法查找Term,这就是Term Dictionary。
什么是Term Index
如果Term太多,Term Dictionary也会很大,全部放在内存不现实,只能部分存储到磁盘上。这是又出现了新的问题,磁盘寻道次数太多也会严重影响查找效率,为了减少磁盘寻道次数来提高查询性能,于是有了Term Index,就像字典里的索引页一样,A开头的有哪些Term,分别在哪页,可以理解Term Index是一颗树: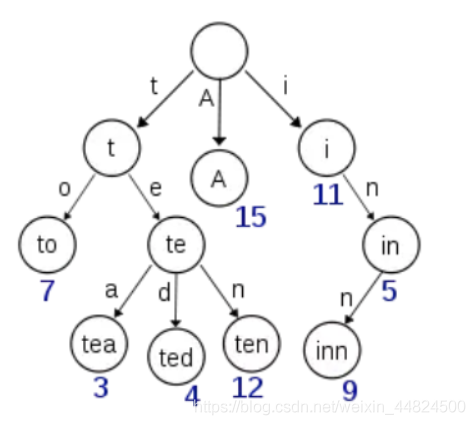
Term Index不需要存下所有的Term,而仅仅是它们的一些前缀与Term Dictionary的Block之间的映射关系,再结合相关的压缩技术,可以使Term Index缓存到内存中。从Term Index查到对应的Term Dictionary的Block位置之后,再去磁盘上找Term,大大减少了磁盘随机读的次数。
为什么 Elasticsearch/Lucene 检索可以比 MySQL快
MySQL 只有 Term Dictionary 这一层,是以 B+Tree 排序的方式存储在磁盘上的。检索一个 Term 需要若干次的 Random Access 的磁盘操作。
Lucene 在 Term Dictionary 的基础上添加了 Term Index 来加速检索,Term Index 以树的形式缓存在内存中。从 Term Index 查到对应的 Term Dictionary 的 Block 位置之后,再去磁盘上找 Term,大大减少了磁盘的 Random Access 次数。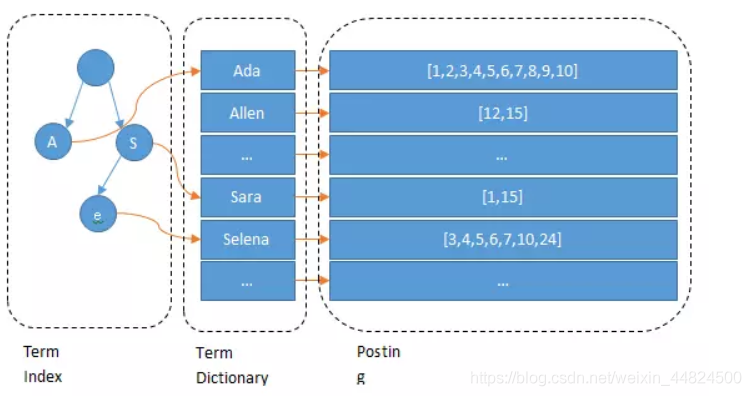
值得一提的两点是:
Term Index 在内存中是以 FST(finite state transducers)的形式保存的,其特点是非常节省内存。
Term Dictionary 在磁盘上是以分 Block 的方式保存的,一个 Block 内部利用公共前缀压缩,比如都是 Ab 开头的单词就可以把 Ab 省去。这样 Term Dictionary 可以比 B-Tree 更节约磁盘空间。
什么是ELK
ELK 是elastic公司提供的一套完整的日志收集以及展示的解决方案,分别表示:ElasticSearch , Logstash, Kibana。
ElasticSearch是个开源分布式搜索引擎,提供搜集、分析、存储数据三大功能。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
Logstash 主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。一般工作方式为c/s架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去。
Kibana 也是一个开源和免费的工具,Kibana可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。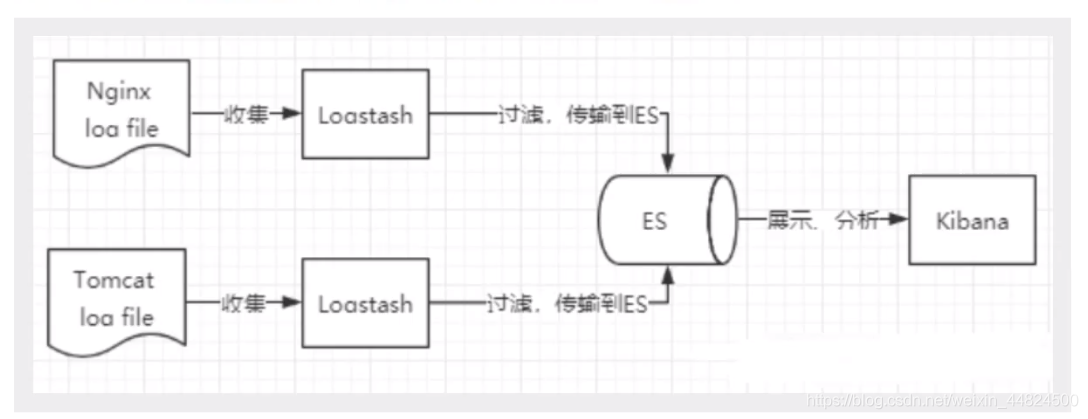
安装ElasticSearch
由于官网下载较慢,下方链接为华为云的镜像。
ElasticSearch:
https://mirrors.huaweicloud.com/elasticsearch/?C=N&O=D
选好自己的版本,下载压缩包。
我选择的是7.6.2的Windows版本,需要清晰知道自己下载的版本,后面下载kibana等都必须版本一致。
下载完成后解压。
重点关注一下config文件夹中的 jvm.options
很多同学一启动马上闪退,就是因为这里的内存设置过大,按照自己电脑配置进行设置,1g闪退就设置512M,以此类推。
接着我们打开bin目录中的elasticsearch.bat
出现下面图片,在浏览器输入红框地址。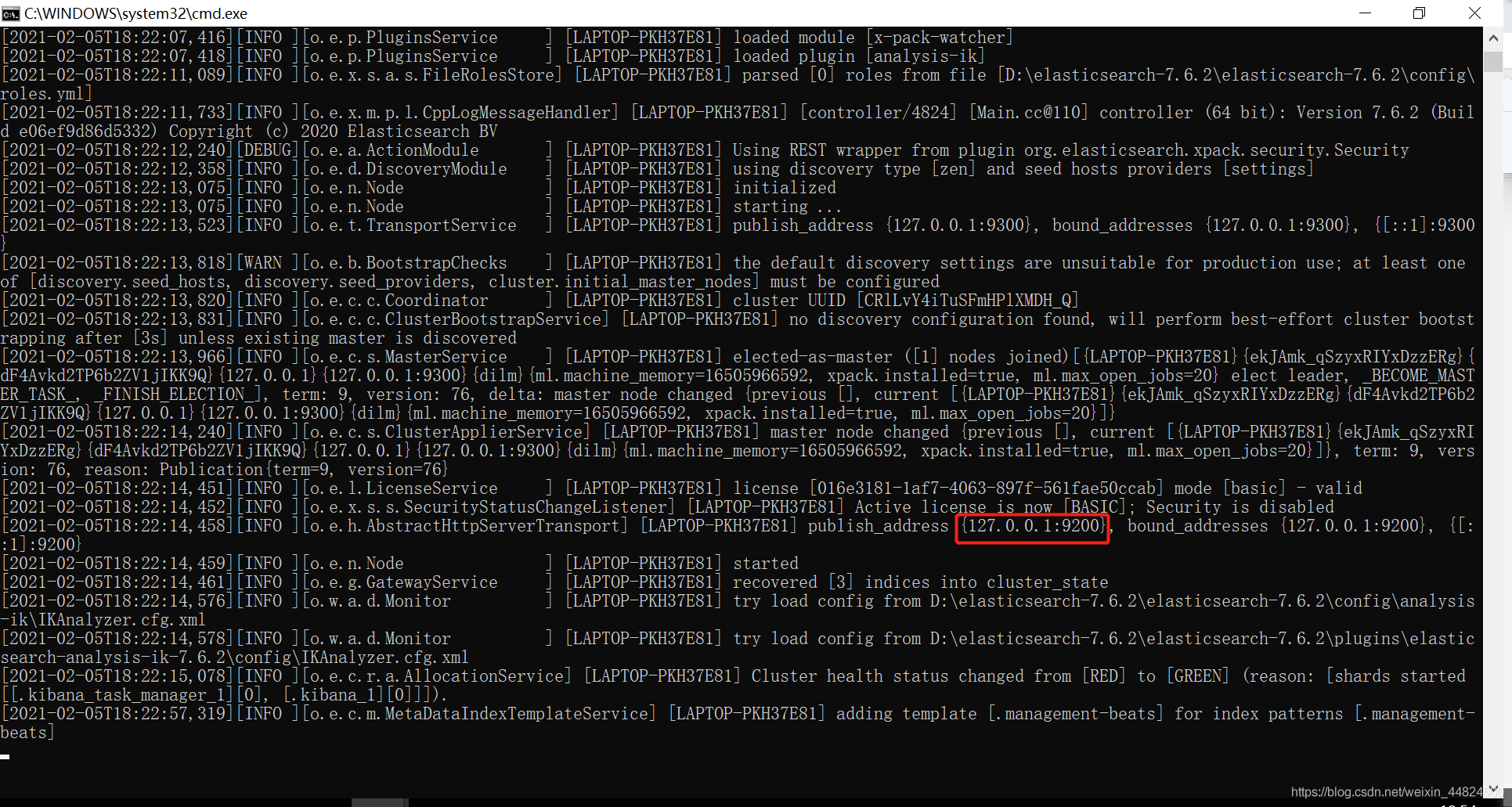
出现下方 json格式则安装成功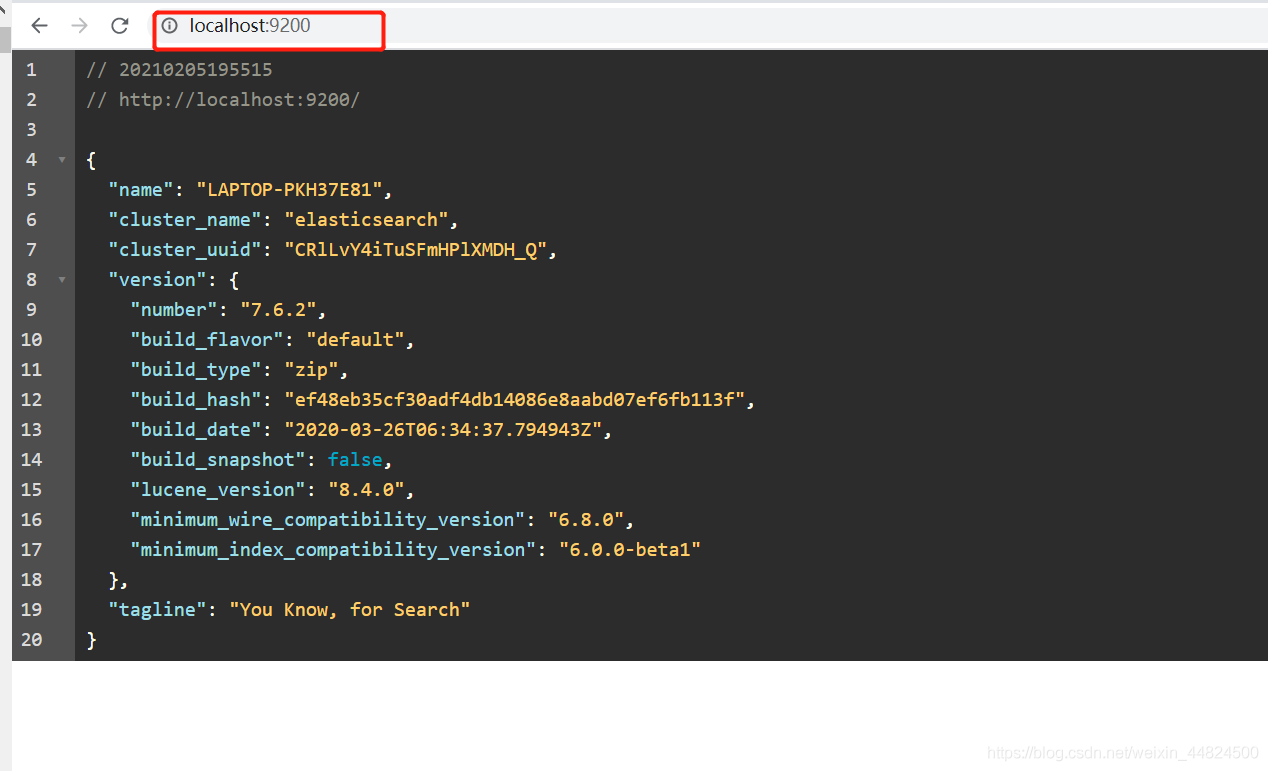
安装ik分词器
打开下方网址,找到和自己elasticsearch一样版本的下载。
https://github.com/medcl/elasticsearch-analysis-ik/releases
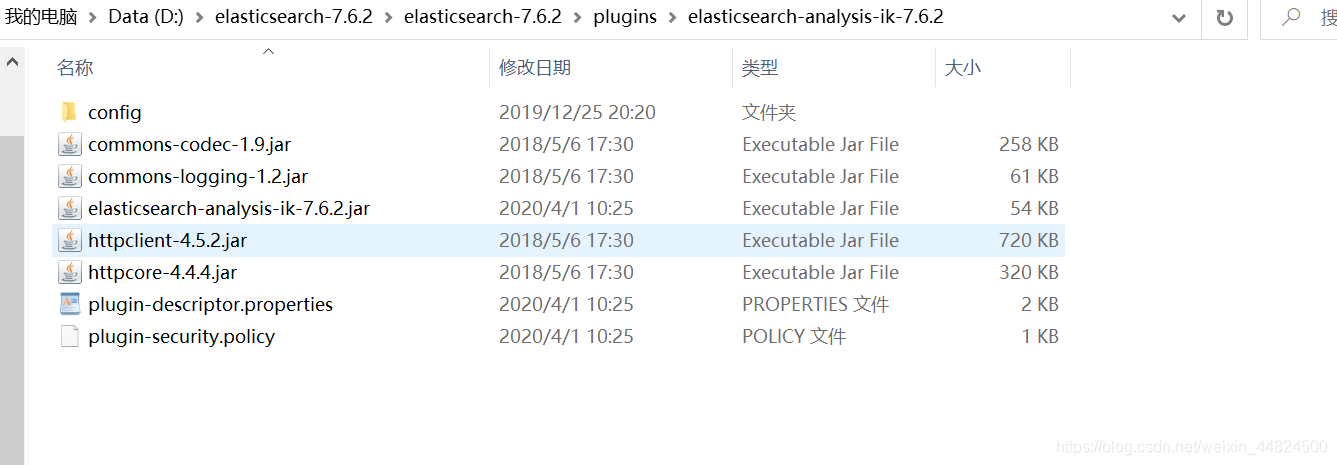
下载完成后,将其解压到elasticsearch文件夹中的plugins,由于ik分词器是elasticsearch的一个插件,elasticsearch的插件都是放在plugins中的。
重启elasticsearch,观察其启动界面的命令行是否出现下图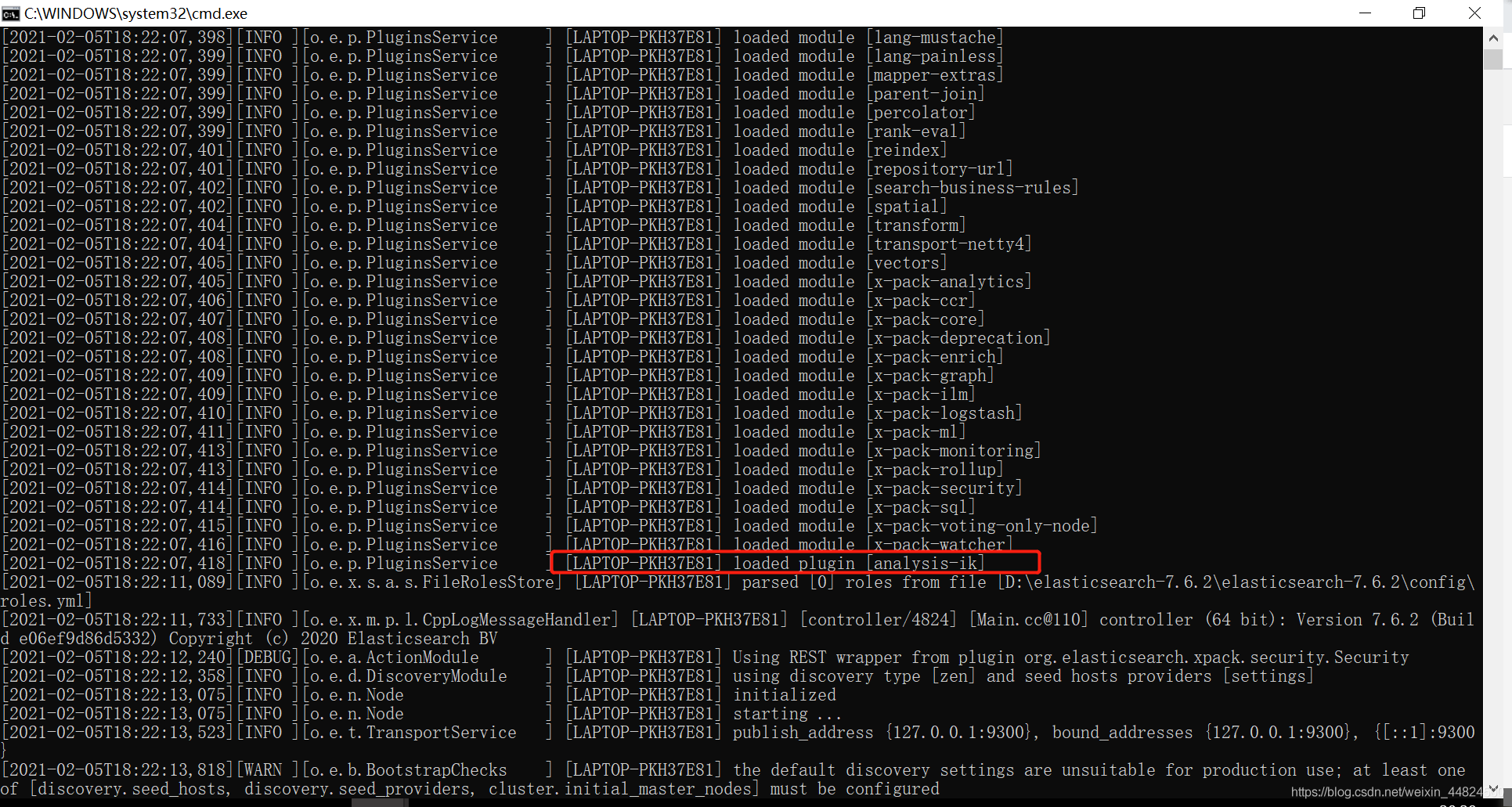
出现了即安装ik插件成功。
测试ik分词器
安装成功后我们打开Kibana可以尝试一下ik分词器如何使用。
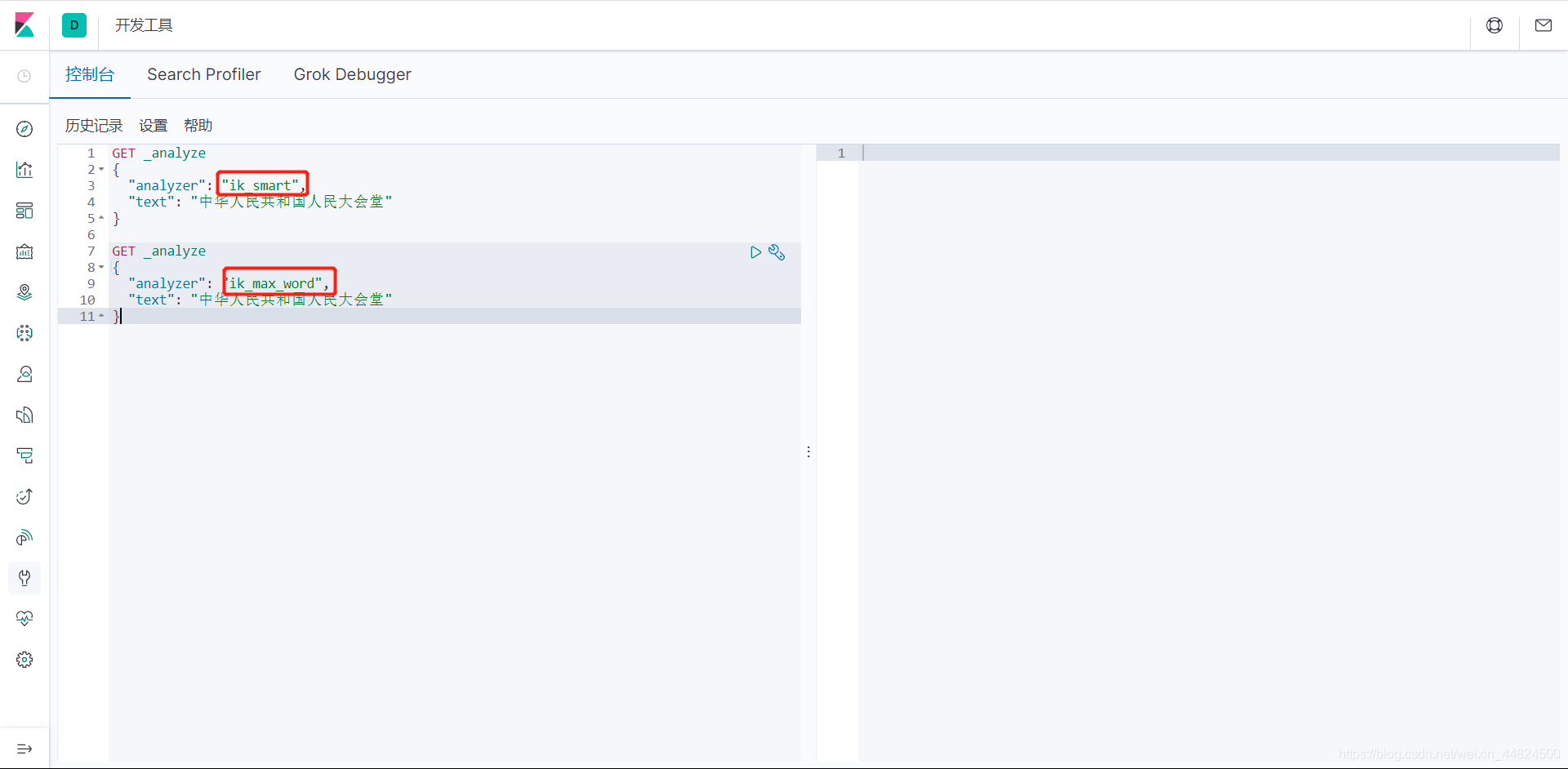
IK分词器的两种分词模式
IK分词器有两种分词模式:ik_max_word和ik_smart模式。
ik_max_word
会将文本做最细粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为“中华人民共和国、中华人民、中华、华人、人民共和国、人民、共和国、大会堂、大会、会堂等词语。ik_smart
会做最粗粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为中华人民共和国、人民大会堂。
点击小三角形对该阴影区域的json的text进行分词
ik_smart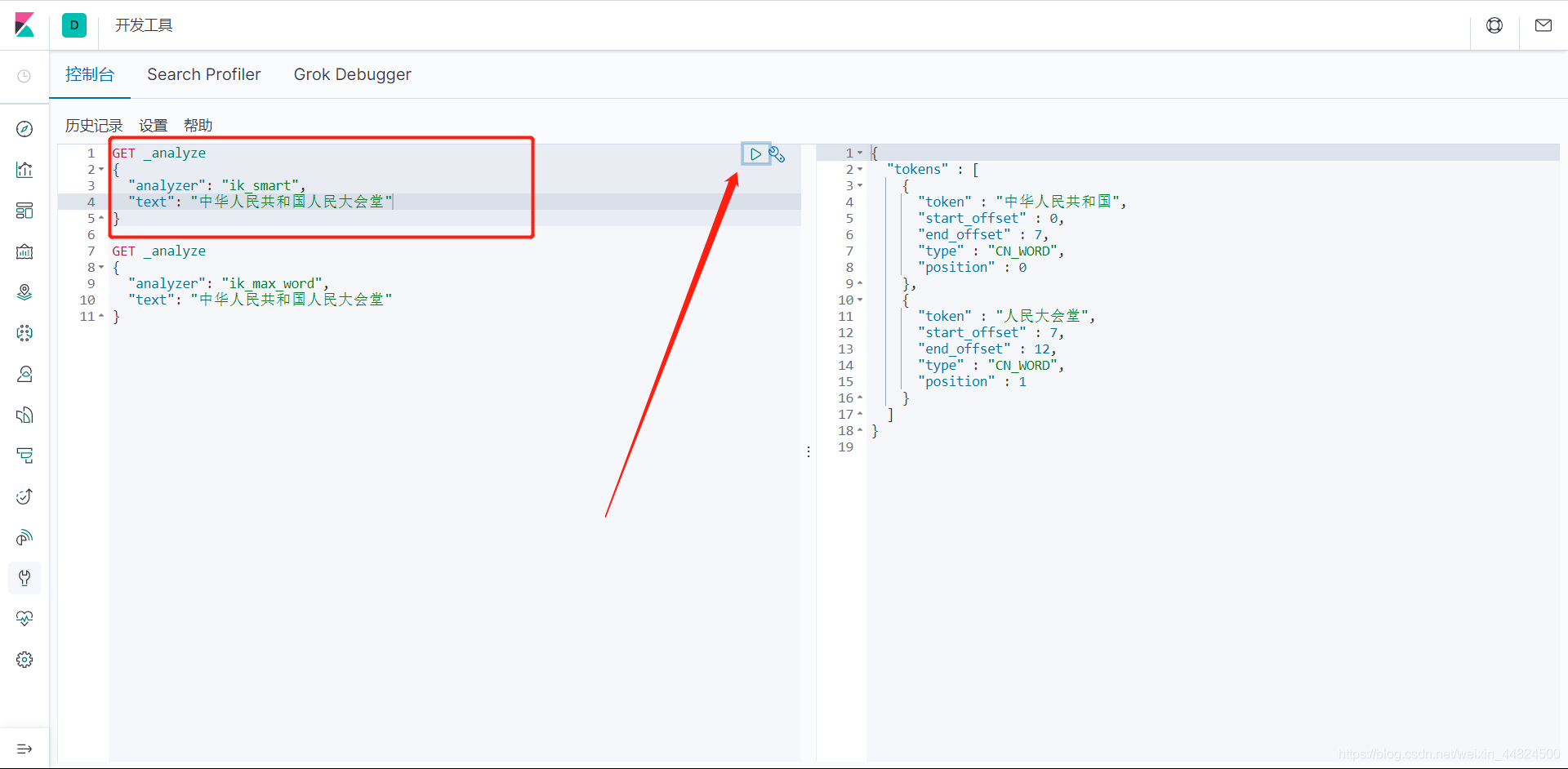
ik_max_word
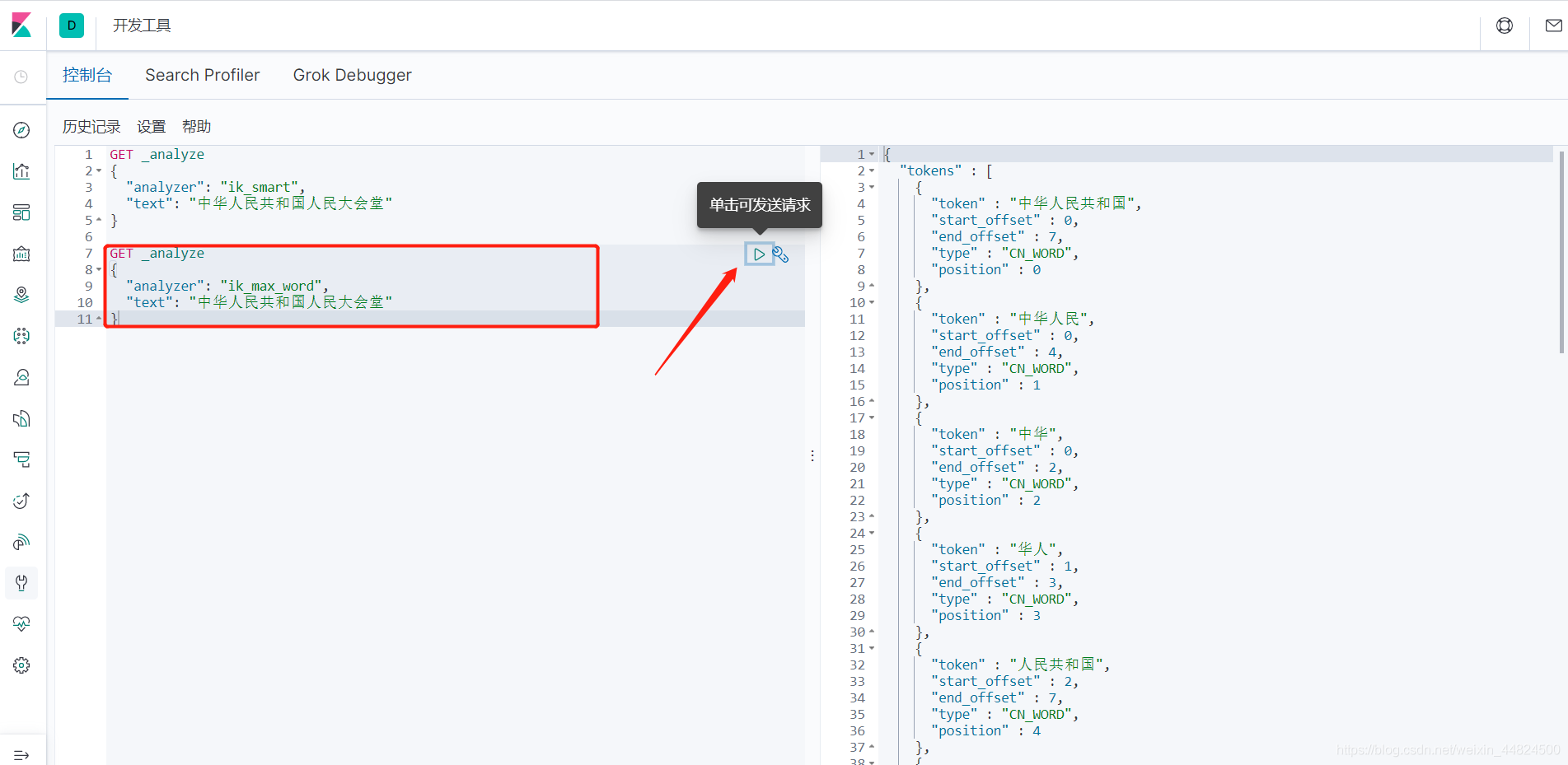
{
"tokens" : [
{
"token" : "中华人民共和国",
"start_offset" : 0,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "中华人民",
"start_offset" : 0,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "中华",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "华人",
"start_offset" : 1,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "人民共和国",
"start_offset" : 2,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "人民",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 5
},
{
"token" : "共和国",
"start_offset" : 4,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 6
},
{
"token" : "共和",
"start_offset" : 4,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 7
},
{
"token" : "国人",
"start_offset" : 6,
"end_offset" : 8,
"type" : "CN_WORD",
"position" : 8
},
{
"token" : "人民大会堂",
"start_offset" : 7,
"end_offset" : 12,
"type" : "CN_WORD",
"position" : 9
},
{
"token" : "人民大会",
"start_offset" : 7,
"end_offset" : 11,
"type" : "CN_WORD",
"position" : 10
},
{
"token" : "人民",
"start_offset" : 7,
"end_offset" : 9,
"type" : "CN_WORD",
"position" : 11
},
{
"token" : "大会堂",
"start_offset" : 9,
"end_offset" : 12,
"type" : "CN_WORD",
"position" : 12
},
{
"token" : "大会",
"start_offset" : 9,
"end_offset" : 11,
"type" : "CN_WORD",
"position" : 13
},
{
"token" : "会堂",
"start_offset" : 10,
"end_offset" : 12,
"type" : "CN_WORD",
"position" : 14
}
]
}
ik分词器添加自定义词库
当有一些自造词需要ik分词器进行分词时,可以打开在ik分词器的解压文件夹中的config
新建一个文档将自造词放进去即可,记得要把文档后缀改为dic,编码为UTF-8
保存后,打开IKAnalyzer.cfg.xml
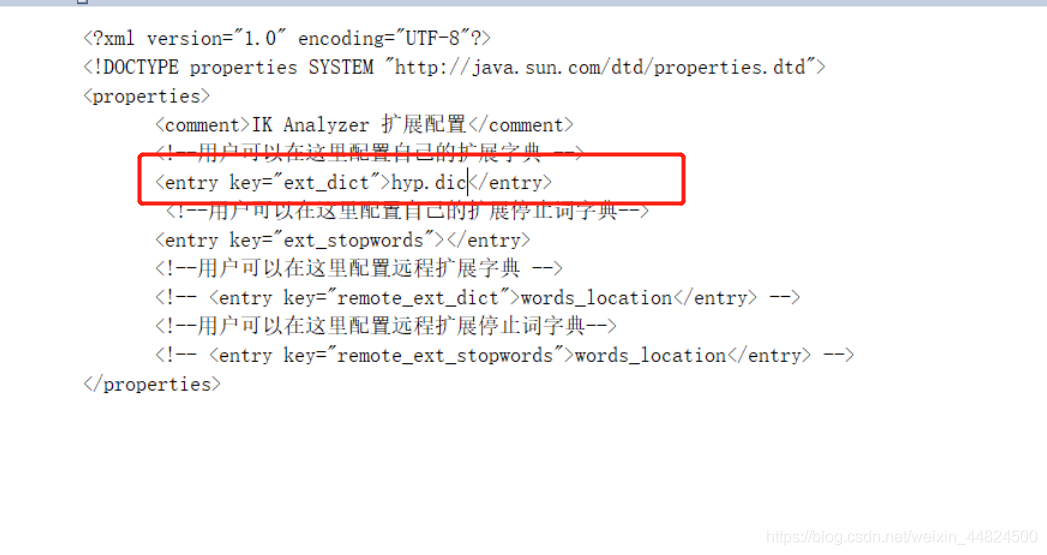
将自己词典的文件名填写进去,保存,添加成功,重启es。
安装ElasticSearch-head
elasticsearch-head将是一款专门针对于elasticsearch的客户端工具,包括数据可视化,增删改查工具,es语句的可视化等等。
下载地址:
https://github.com/mobz/elasticsearch-head
和elasticsearch安装一样,将解压包解压,进入elasticsearch-head的文件夹
进入解压路径的命令行
执行 npm install
执行 npm run start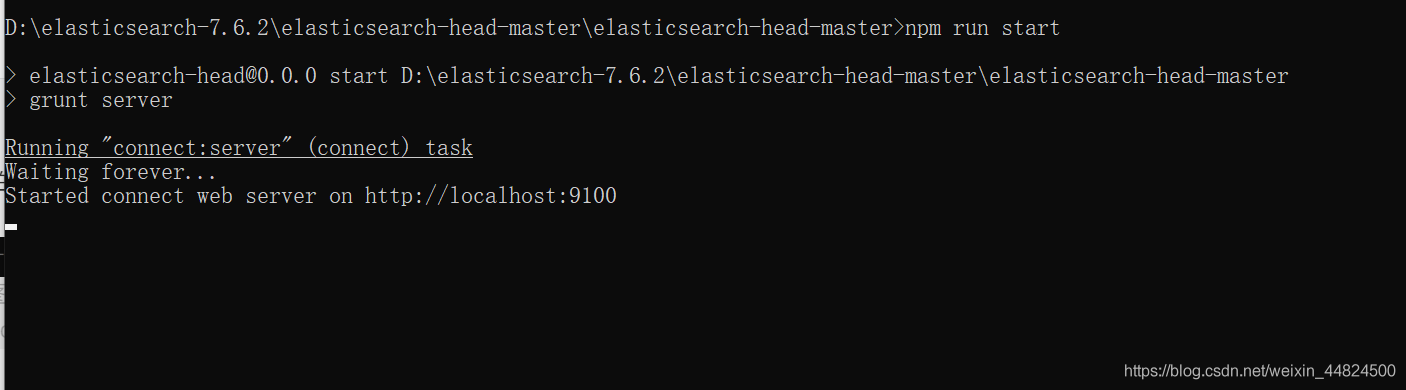
在浏览器访问http://localhost:9100,可看到如下界面,表示启动成功: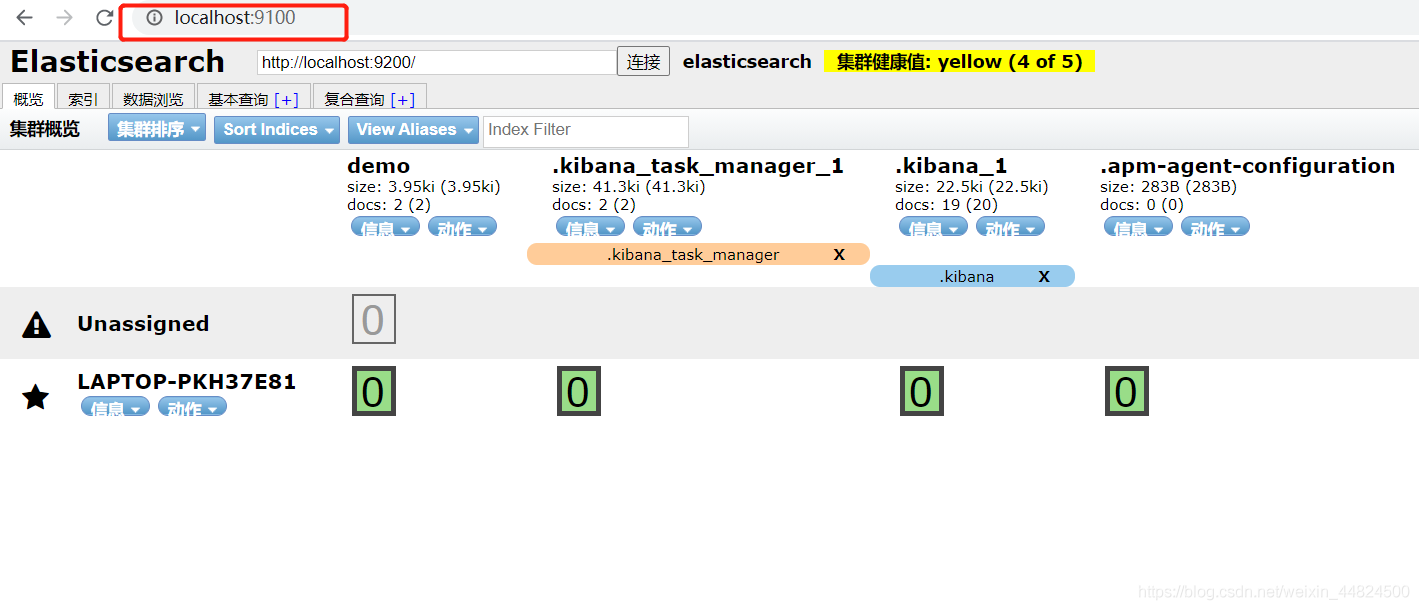
安装Kibana
依旧是华为云的镜像
Kibana
https://mirrors.huaweicloud.com/kibana/?C=N&O=D
选择和你的ElasticSearch一样的版本下载,和es一样解压即可用。
由于Kibana默认是英文,我们需要进入config文件夹中的kibana.yml
在末尾加入i18n.locale: "zh-CN",更改保存,让国际化变成中文。
接着进入bin目录打开kibana.bat,出现下方界面。
在浏览器打开http://localhost:5601,进入下方页面即安装成功。
REST风格说明
什么是REST风格
REST是一种软件架构风格,或者说是一种规范,其强调HTTP应当以资源为中心,并且规范了URI的风格;规范了HTTP请求动作(GET/PUT/POST/DELETE/HEAD/OPTIONS)的使用,具有对应的语义。
基本REST命令说明
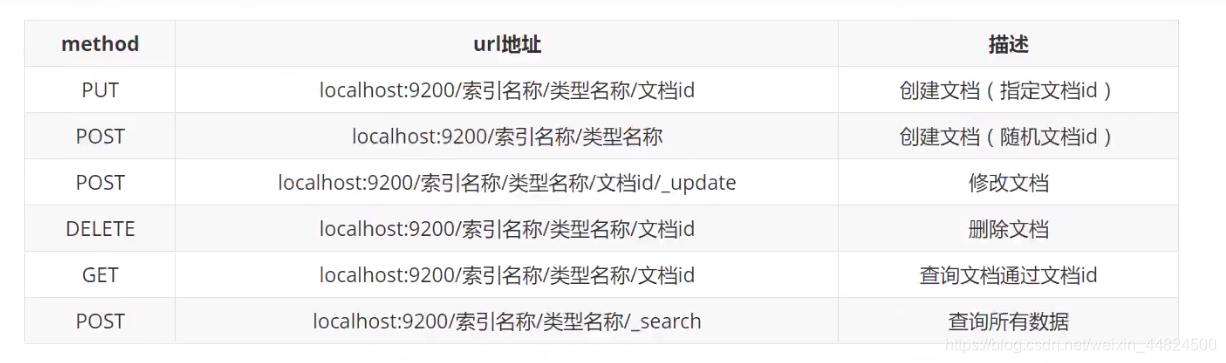
PUT命令
创建一个demo索引的 type类型下保存1号数据为 “name”: “小黄”, “age”:21
PUT demo/type/1
{
"name": "小黄",
"age":21
}
创建成功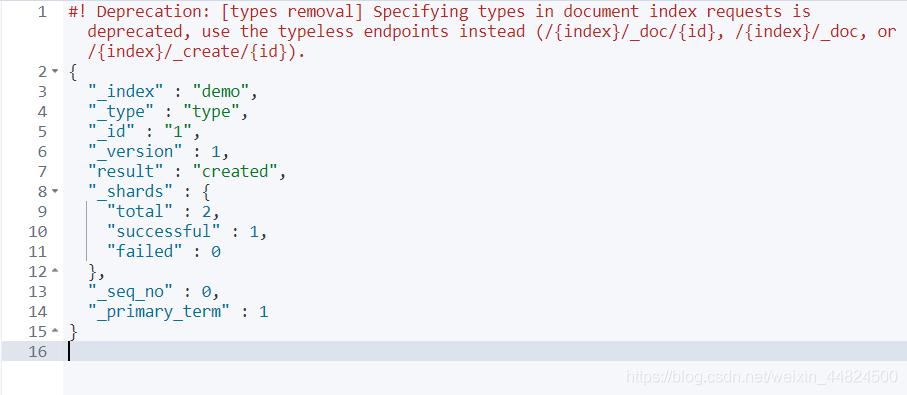
对照着和关系型数据库的联系理解
创建类型
不填写时,默认为_.doc类型,在未来8.多的版本具体类型可能会被抛弃。
指定某个字段使用指定类型,常见类型有下图:
我们在下方创建了一个test2的索引里面的字段和对应的类型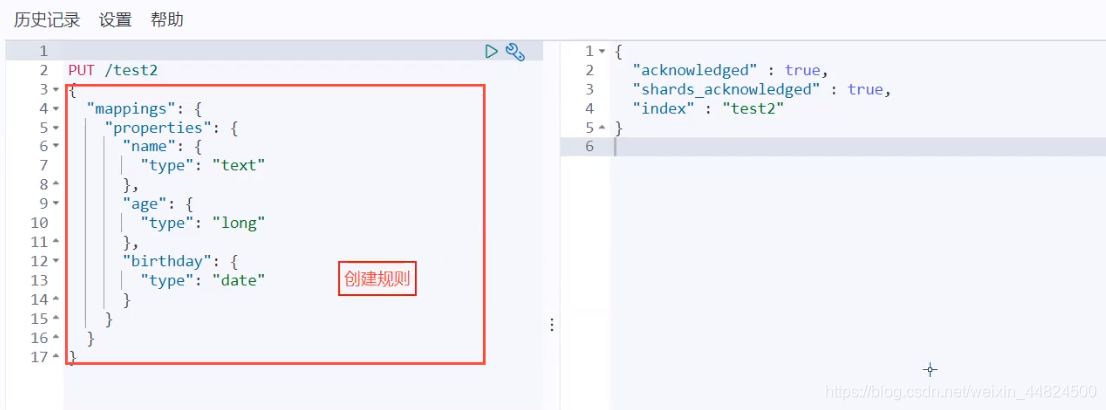
插入数据
这里在demo索引下的插入了4个记录
PUT demo/type/1
{
"name": "小黄1.0",
"age":21
}
PUT demo/type/2
{
"name": "小黄2.0",
"age":21
}
PUT demo/type/3
{
"name": "小黄3.0",
"age":21
}
PUT demo/type/4
{
"name": "小黄4.0",
"age":21
}
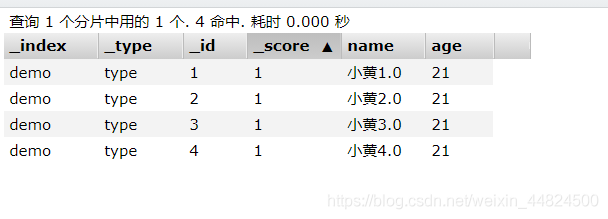
更新数据
假设我需要更新name为小黄2.0,直接在对应的字段更改成对应数据即可,需要将不修改字段的数据也写上去,否则将会被空白覆盖。
PUT demo/type/1 # 更新id为1的数据
{
"name": "小黄2.0",
"age":21 #即使21不用修改还是需要写
}
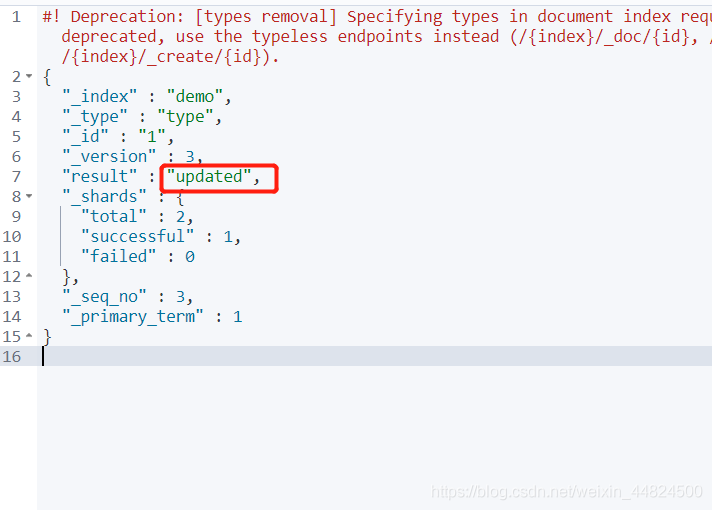
修改后 _version增加
POST命令
POST可以不带ID发送,ES会自动生成一个ID,如果再次请求也会再次新增一个ID
POST demo/type
{
"name": "小黄",
"age":21
}
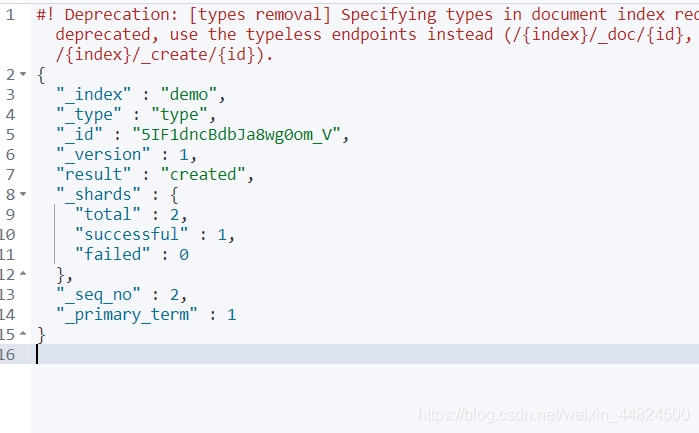
可以看到自动生成一个ID为 5IF1dncBdbJa8wg0om_V
更新数据(推荐使用)
POST一样可以更新数据,只需要在最后加上需要修改的ID号和/_update,加上 “doc”:{}包围需要修改的数据字段即可,不需要将不修改的数据写上去。
POST demo/type/1/_update
{
"doc":{
"name": "小黄3.0"
}
}

DELETE命令
DELETE demo #删除demo索引
DELETE demo/type/1 #删除demo索引下的1号文档
根据请求判断删除索引还是文档记录
GET命令
查询数据(重点)
GET demo #获取索引信息

GET demo/type/1 #获取demo索引的 type类型下保存1号数据
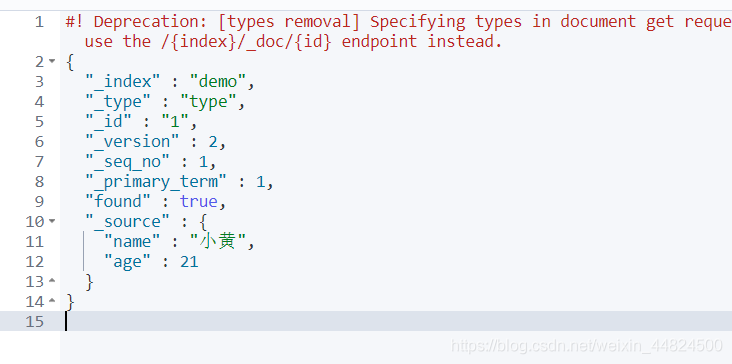
_index:表示在哪个索引下
_type:类型
_id:添加时的id
_version:版本号
_seq_no:并发控制字段,序列号,每次更新+1 (乐观锁操作使用)
_primary_term:分片,作用同上,重启会变化
_source:真正的内容
精确查询
term查询是直接通过倒排索引指定的词条进行精确查找的
GET demo/type/_search
{
"query": {
"term": {
"age": "21"
}
}
}
而match会使用分词器解析(先分析文档,在通过分析的文档进行查询)
keyword类型数据不能被分词器解析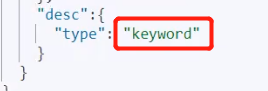
而其他类型可以被分词器解析
查询字符串搜索
将具有"黄"的数据全部搜索出来
GET demo/type/_search?q=name:黄
#! Deprecation: [types removal] Specifying types in search requests is deprecated.
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 4,
"relation" : "eq"
},
"max_score" : 0.10536051,
"hits" : [
{
"_index" : "demo",
"_type" : "type",
"_id" : "1",
"_score" : 0.10536051,
"_source" : {
"name" : "小黄1.0",
"age" : 21
}
},
{
"_index" : "demo",
"_type" : "type",
"_id" : "2",
"_score" : 0.10536051,
"_source" : {
"name" : "小黄2.0",
"age" : 21
}
},
{
"_index" : "demo",
"_type" : "type",
"_id" : "3",
"_score" : 0.10536051,
"_source" : {
"name" : "小黄3.0",
"age" : 21
}
},
{
"_index" : "demo",
"_type" : "type",
"_id" : "4",
"_score" : 0.10536051,
"_source" : {
"name" : "小黄4.0",
"age" : 21
}
}
]
}
}
hits:显示索引和文档信息,查询总结果数,权重, 具体文档,数据中的东西都可以遍历出来
_score:表示权重,越高表示该数据和搜索字段越匹配。由于我上面的数据格式一样,都只具有一个"黄"所以权重一样,都是0.10536051。
查询所有结果
GET demo/type/_search
{
"query":{"match_all":{}}
}
条件查询
GET demo/type/_search
{
"query":{
"match":{
"name":"黄"
}
}
}
布尔查询
使用 "bool":{} 声明使用布尔查询
must等同于MySQL中的 and
GET demo/type/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "huang"
}
},
{
"match": {
"age": 21
}
}
]
}
}
}
should等同于MySQL中的 or
filter条件过滤查询,过滤条件的范围用range表示gt表示大于、lt表示小于、gte表示大于等于、lte表示小于等于)
GET demo/type/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "黄"
}
}
],
"filter": {
"range": {
"age": {
"gte": 10,
"lt": 27
}
}
}
}
}
}
按排序查询
GET demo/type/_search
{
"query":{
"match":{
"name":"黄"
}
},
"sort":[
{
"age":"desc" #降序
}
]
}
分页查询
GET demo/type/_search
{
"query":{"match_all":{}},
"from":0,
"size":2 #从零开始查询所有记录,每页只显示2条记录
}
指定查询结果的字段
GET demo/type/_search
{
"query":{"match_all":{}},
"_source":["name","age"]
}
高亮查询
搜索出name为小黄1.0的数据,并将其name字段高亮显示
GET demo/type/_search
{
"query":{
"match_phrase":{
"name":"小黄1.0"
}
} ,
"highlight":{
"fields":{
"name":{}
}
}
}
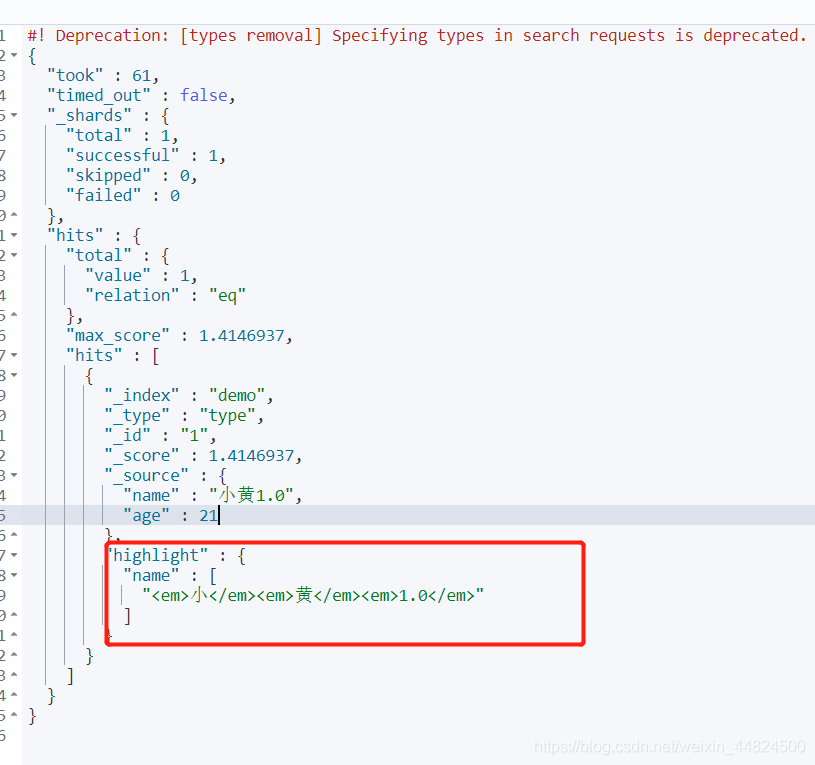
自定义搜索高亮字段格式前后缀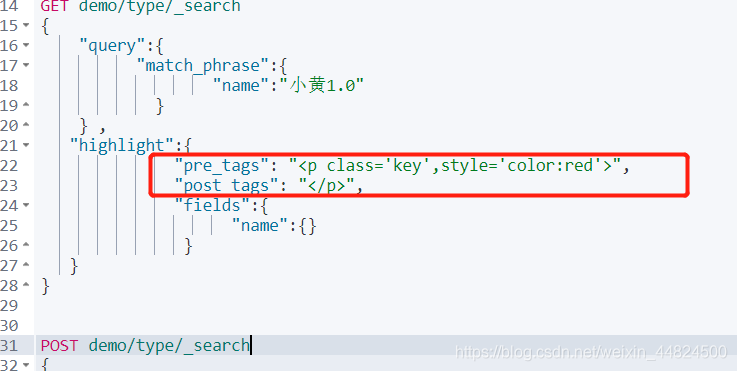

拓展
GET _cat/nodes #查看所有节点

GET _cat/health #查看es健康状况

GET _cat/master #查看主节点

GET _cat/indices #查看所有索引 == MySQL中的show databases

参考:
https://www.bilibili.com/video/BV17a4y1x7zq
http://www.mybatis.cn/archives/1112.html
https://www.jianshu.com/p/c96576fcbcd9
转:
ElasticSearch学习笔记
ElasticSearch学习笔记(超详细)的更多相关文章
- maven学习笔记(超详细总结)
目录 项目管理利器--maven 第1章 maven概述 1-1 项目管理利器-maven简介 1.1.1 什么是maven 1.1.2 什么是依赖管理 1.1.3 传统项目的依赖管理 1.1.4 m ...
- ElasticSearch学习笔记(详细)
目录 ElasticSearch概述 ElasticSearch入门 安装 基本操作 查看es相关信息 索引操作 文档操作 bulk批量API 进阶检索 Search API Query DSL 分词 ...
- python多线程学习笔记(超详细)
python threading 多线程 一. Threading简介 首先看下面的没有用Threading的程序 ): s += i time.sleep( ): s += i time. ...
- Elasticsearch学习笔记一
Elasticsearch Elasticsearch(以下简称ES)是一款Java语言开发的基于Lucene的高效全文搜索引擎.它提供了一个分布式多用户能力的基于RESTful web接口的全文搜索 ...
- elasticsearch学习笔记——相关插件和使用场景
logstash-input-jdbc学习 ES(elasticsearch缩写)的一大优点就是开源,插件众多.所以扩展起来非常的方便,这也造成了它的生态系统越来越强大.这种开源分享的思想真是与天朝格 ...
- Java多线程学习(吐血超详细总结)
Java多线程学习(吐血超详细总结) 林炳文Evankaka原创作品.转载请注明出处http://blog.csdn.net/evankaka 写在前面的话:此文只能说是java多线程的一个入门,其实 ...
- redis学习笔记(详细)——高级篇
redis学习笔记(详细)--初级篇 redis学习笔记(详细)--高级篇 redis配置文件介绍 linux环境下配置大于编程 redis 的配置文件位于 Redis 安装目录下,文件名为 redi ...
- JUC.Condition学习笔记[附详细源码解析]
目录 Condition的概念 大体实现流程 I.初始化状态 II.await()操作 III.signal()操作 3个主要方法 Condition的数据结构 线程何时阻塞和释放 await()方法 ...
- JUC.Lock(锁机制)学习笔记[附详细源码解析]
锁机制学习笔记 目录: CAS的意义 锁的一些基本原理 ReentrantLock的相关代码结构 两个重要的状态 I.AQS的state(int类型,32位) II.Node的waitStatus 获 ...
随机推荐
- HDOJ 1848(SG函数)
对于SG函数来说,sg[y]=x的意义为,x与y的输赢状态是相同的 sg[y]=mex(y)的定义与n.p点的定义是相同的 #include<iostream>#include<cs ...
- 2020-2021 ICPC, NERC, Southern and Volga Russian Regional Contest (Online Mirror, ICPC Rules) C. Berpizza (STL)
题意:酒吧里有两个服务员,每个人每次都只能服务一名客人,服务员2按照客人进酒吧的顺序服务,服务员3按照客人的钱来服务,询问\(q\),\(1\)表示有客人进入酒吧,带着\(m\)块钱,\(2\)表示询 ...
- [POJ 2585] Window Pains 拓朴排序
题意:你现在有9个2*2的窗口在4*4的屏幕上面,由于这9这小窗口叠放顺序不固定,所以在4*4屏幕上有些窗口只会露出来一部分. 如果电脑坏了的话,那么那个屏幕上的各小窗口叠放会出现错误.你的任务就是判 ...
- OpenStack Train版-5.安装nova计算服务(控制节点)
nova计算服务需要在 控制节点 和 计算节点 都安装 控制节点主要安装 nova-api(nova主服务) nova-scheduler(nova调度服务) nova-conductor(n ...
- linux无需root挂载iso镜像文件
引言 起初,我在针对deepin制作一款appimage安装工具,想要其实现的功能就是自动获取图标,只需要输入软件名称和分类即可,当然以后也会寻找方案省去手动输入的麻烦. 后来我发现一个有趣的问题 o ...
- Eazfuscator.NET(.net混淆工具)
软件功能 调试支持: 在你的程序集被Eazfuscator.NET混淆后,它不会成为不可调试混乱的砖块.你总是可以得到一个行号,出现未处理的异常,查看可读的堆栈跟踪,甚至附加调试器来遍历你的模糊代码. ...
- WOJ1022 Competition of Programming 贪心 WOJ1023 Division dp
title: WOJ1022 Competition of Programming 贪心 date: 2020-03-19 13:43:00 categories: acm tags: [acm,wo ...
- pthread_create函数
函数简介 pthread_create是UNIX环境创建线程函数 头文件 #include<pthread.h> 函数声明 int pthread_create(pthread_t *re ...
- 开源软件ffmpeg使用中的问题
error while decoding MB 20 10, bytestream -13 经过调试,发现这部是 int ret = avcodec_decode_video2(pCodecConte ...
- 力扣1689. 十-二进制数的最少数目-C语言实现-中等难度题
题目 传送门 如果一个十进制数字不含任何前导零,且每一位上的数字不是 0 就是 1 ,那么该数字就是一个 十-二进制数 .例如,101 和 1100 都是 十-二进制数,而 112 和 3001 不是 ...