Phoneix(三)HBase集成Phoenix创建二级索引
一、Hbase集成Phoneix
1、下载
在官网http://www.apache.org/dyn/closer.lua/phoenix/中选择提供的镜像站点中下载与安装的HBase版本对应的版本。本地使用的1.2.5,故下载的apache-phoenix-4.13.1-HBase-1.2-bin.tar.gz包。
2、上传并解压
tar -zxvf apache-phoenix-4.13.1-HBase-1.2-bin.tar.gz
mv apache-phoenix-4.13.1-HBase-1.2-bin.tar.gz phoenix
3、将phoenix-core-4.13.1-HBase-1.2.jar、phoenix-4.13.1-HBase-1.2-server.jar发送到hregionserver所在的hbase的lib目录下:
cp phoenix-core-4.13.1-HBase-1.2.jar /mnt/hbase/lib/
scp phoenix-core-4.13.1-HBase-1.2.jar slave01:/mnt/hbase/lib/
scp phoenix-core-4.13.1-HBase-1.2.jar slave02:/mnt/hbase/lib/
cp phoenix-4.13.1-HBase-1.2-server.jar /mnt/hbase/lib/
scp phoenix-4.13.1-HBase-1.2-server.jar slave02:/mnt/hbase/lib/
scp phoenix-4.13.1-HBase-1.2-server.jar slave01:/mnt/hbase/lib/
4、重启Hbase
start-hbase.sh
5、启动phoneix
# 进入phoenix下的bin目录
cd phoenix/bin
# 启动
./sqlline.py master:2181
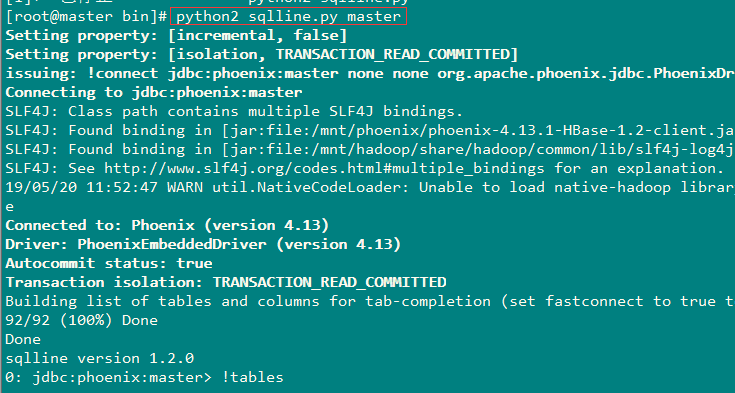
6、创建一张简单的 表测试
0: jdbc:phoenix:master> create table user(id varchar primary key,name varchar,age varchar,phone varchar,email varchar);
No rows affected (1.47 seconds)
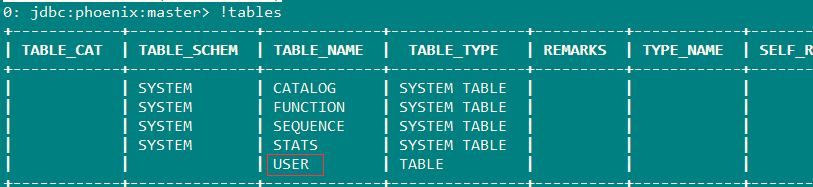
7、插入数据
upsert into user values('1001','caocao','26','13800000000','caocao@163.com');
upsert into user values('1002','liubei','24','13800000001','liubei@163.com');
upsert into user values('1003','guanyu','23','13800000002','guanyu@163.com');
upsert into user values('1004','zhangfei','22','13800000003','zhangfei@163.com');
upsert into user values('1005','sunquan','20','13800000004','sunquan@163.com');
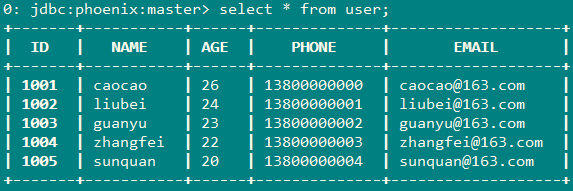
8、通过hbase shell查看


因此配置完成了。。。
二、Phoneix集成Hbase创建二级索引
索引最常用的三个类型:覆盖索引、全局索引、本地索引
1、配置(如果使用的phoneix版本在4.8之后则不需要如下配置,我这里使用的是4.13因此不需要配置)
在每一个RegionServer的hbase-site.xml中加入如下的属性
<property>
<name>hbase.regionserver.wal.codec</name>
<value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value>
</property>
<property>
<name>hbase.region.server.rpc.scheduler.factory.class</name>
<value>org.apache.hadoop.hbase.ipc.PhoenixRpcSchedulerFactory</value>
<description>Factory to create the Phoenix RPC Scheduler that uses separate queues for index and metadata updates</description>
</property>
<property>
<name>hbase.rpc.controllerfactory.class</name>
<value>org.apache.hadoop.hbase.ipc.controller.ServerRpcControllerFactory</value>
<description>Factory to create the Phoenix RPC Scheduler that uses separate queues for index and metadata updates</description>
</property>
<property>
<name>hbase.coprocessor.regionserver.classes</name>
<value>org.apache.hadoop.hbase.regionserver.LocalIndexMerger</value>
</property>
在每一个Master的hbase-site.xml中加入如下的属性(phoneix版本在4.8之后不用添加):
<property>
<name>hbase.master.loadbalancer.class</name>
<value>org.apache.phoenix.hbase.index.balancer.IndexLoadBalancer</value>
</property>
<property>
<name>hbase.coprocessor.master.classes</name>
<value>org.apache.phoenix.hbase.index.master.IndexMasterObserver</value>
</property
2、使用phoneix创建表、导入数据(数据量10W条)
https://www.cnblogs.com/yfb918/p/10895754.html
3、覆盖索引(Covered Indexes)
说明:只需要通过索引就能返回所要查询的数据,所以索引的列必须包含所需查询的列(select 的列和where的列)
3.1不带索引的查询,查询ip='139.204.122.144'(普通查询)
由于数据量不大,经过多次查询,查询时间在0.13s-0.150s左右
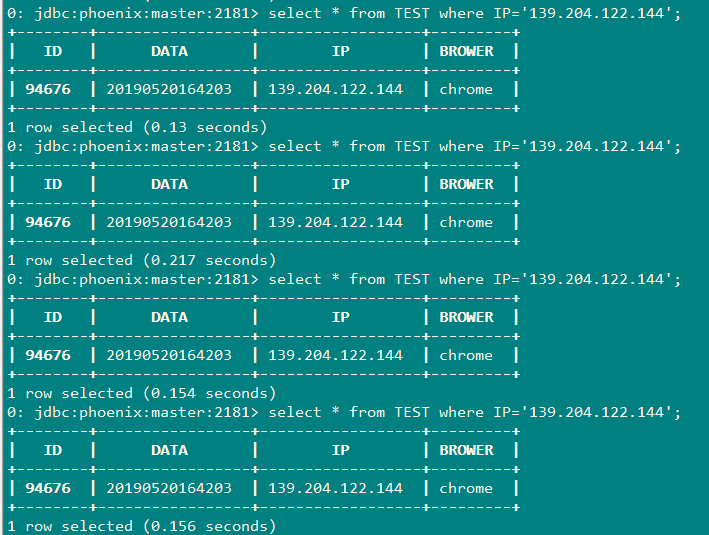
3.1.1查询计划
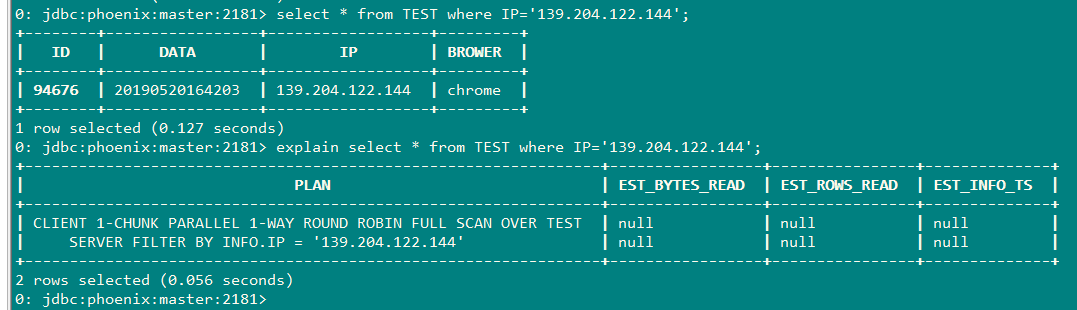
由图看出该执行过程线进行了full scan(全表扫描)再通过Filter(过滤器)进行筛选数据。
3.2创建基于ID的覆盖索引并绑定IP列上的数据
CREATE INDEX COVERINDEX ON TEST(ID) INCLUDE(IP)
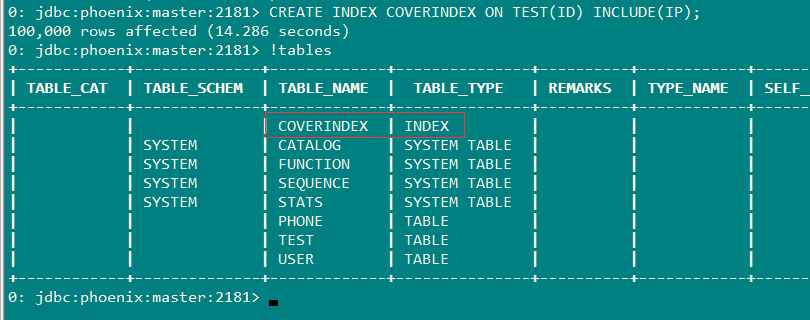
当我要通过ID来查询IP时就直接可以从索引上取回数据而无需先得到索引再去数据表中查询数据
查询语句:
说明:这里ID=''94676"正是上面IP=‘139.204.122.144’的该条数据
SElECT IP FROM TEST WHERE ID='94676';
经过多次查询:耗时在:0.016s-0.02s左右

3.2.1查询计划

3.3测试后删除索引

4、全局索引(Global Indexes)
全局索引适用于多读少写的场景,在写操作上会给性能带来极大的开销,因为所有的更新和写操作都会引起索引的更新,在读取数据时,Phoneix将通过索引表达式来快速查询结果。
在使用全局索引之前需要在每个RegionServer上的hbase-site.xml添加如下属性:
<property>
<name>hbase.regionserver.wal.codec</name>
<value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value>
</property>
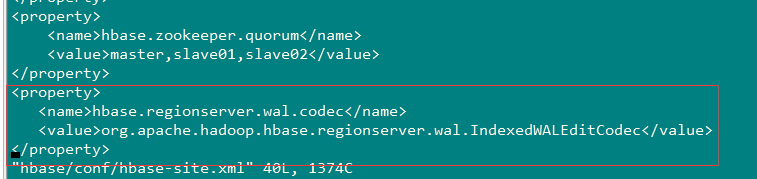
4.1这里在IP字段上创建索引
CREATE INDEX IPINDEX ON TEST(IP);

以下查询才会使用到索引
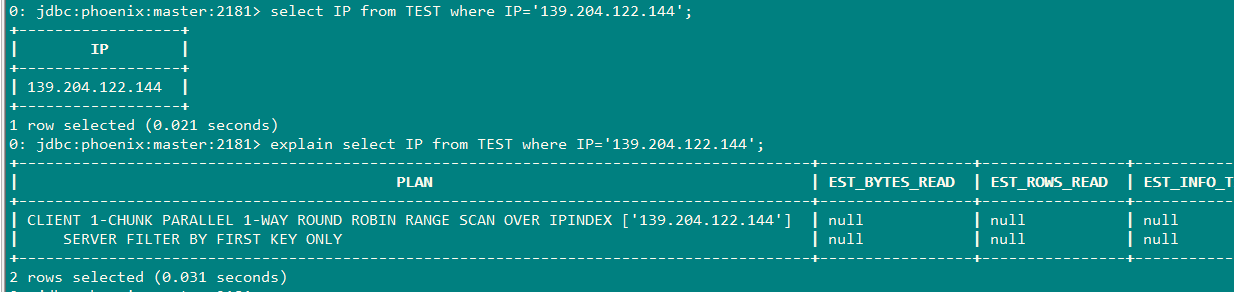
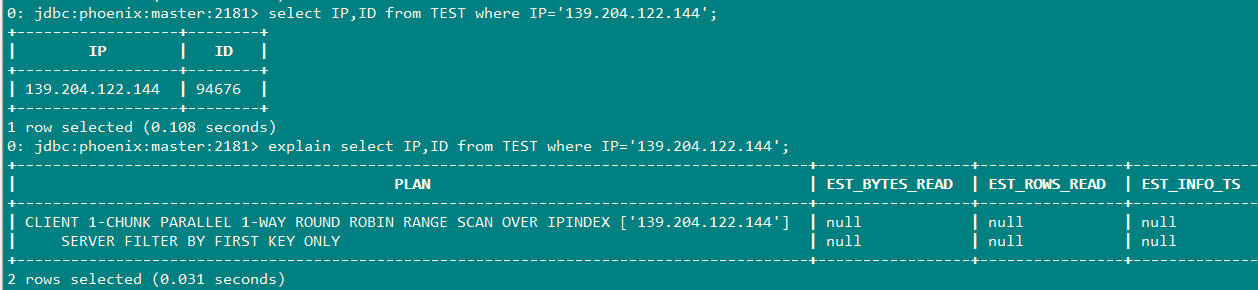

下面这个是采用强制索引的方式:
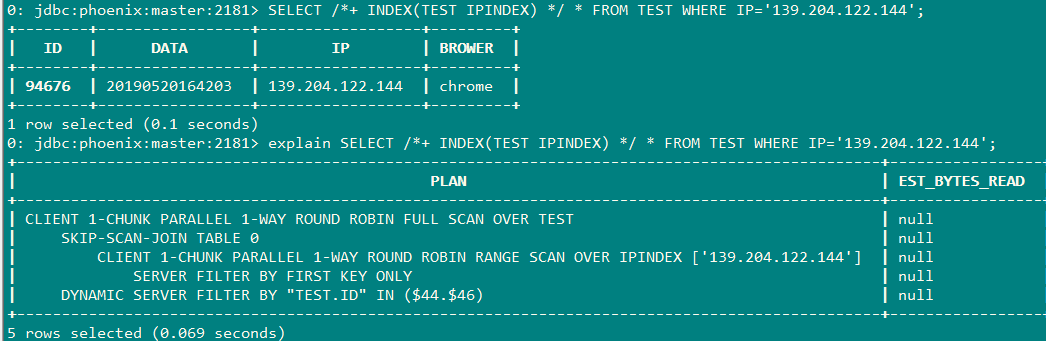
以下查询不会使用到索引
语句一:
select IP,BROWER from TEST where IP='139.204.122.144';
虽然IP是索引字段,但是BROWER不是索引字段,所以不会使用到索引
语句二:
select BROWER from TEST where IP='139.204.122.144';
BROWER不是索引字段,其他同理
但是使用以下几种方式,执行查询语句二时也将使用到索引
a、创建包含字段BROWER的覆盖索引
CREATE INDEX BROWERINDEX ON TEST(IP) INCLUDE(BROWER);
b、强制使用索引
SELECT /*+ INDEX(INDEXIP,IPINDEX) */ IP FROM TEST WHERE IP='139.204.122.144';
如果IP是索引字段,那么就会直接从索引表中查询
c、使用本地索引
CREATE LOCAL INDEX BROWERINDEX ON CSVTABLES(BROWER);
5、本地索引(Local indexes)
本地索引适用于写多读少,空间有限的场景,和全局索引一样,Phoneix在查询时会自动选择是否使用本地索引,使用本地索引,为避免进行写操作所带来的网络开销,索引数据和表数据都存放在相同的服务器中,当查询的字段不完全是索引字段时本地索引也会被使用,与全局索引不同的是,所有的本地索引都单独存储在同一张共享表中,由于无法预先确定Region的位置,所以在读取数据时会检查每个Region上的数据因而带来一定性能开销。
在使用本地索引之前需要在hbase master的hbase-site.xml上添加一下配置:
<property>
<name>hbase.master.loadbalancer.class</name>
<value>org.apache.phoenix.hbase.index.balancer.IndexLoadBalancer</value>
</property>
<property>
<name>hbase.coprocessor.master.classes</name>
<value>org.apache.phoenix.hbase.index.master.IndexMasterObserver</value>
</property>
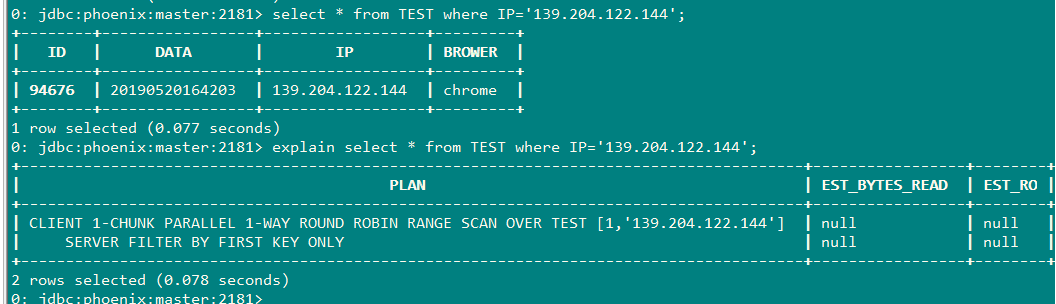
创建本地索引
CREATE LOCAL INDEX IPINDEX ON TEST(IP);
查询
Phoneix(三)HBase集成Phoenix创建二级索引的更多相关文章
- phoenix连接hbase数据库,创建二级索引报错:Error: org.apache.phoenix.exception.PhoenixIOException: Failed after attempts=36, exceptions: Tue Mar 06 10:32:02 CST 2018, null, java.net.SocketTimeoutException: callTimeou
v\:* {behavior:url(#default#VML);} o\:* {behavior:url(#default#VML);} w\:* {behavior:url(#default#VM ...
- phoenix创建二级索引
create table user (id varchar primary key, firstname varchar, lastname varchar); create index user_i ...
- 通过phoenix在hbase上创建二级索引,Secondary Indexing
环境描述: 操作系统版本:CentOS release 6.5 (Final) 内核版本:2.6.32-431.el6.x86_64 phoenix版本:phoenix-4.10.0 hbase版本: ...
- 利用Phoenix为HBase创建二级索引
为什么需要Secondary Index 对于Hbase而言,如果想精确地定位到某行记录,唯一的办法是通过rowkey来查询.如果不通过rowkey来查找数据,就必须逐行地比较每一列的值,即全表扫瞄. ...
- hbase基于solr配置二级索引
一.概述 Hbase适用于大表的存储,通过单一的RowKey查询虽然能快速查询,但是对于复杂查询,尤其分页.查询总数等,实现方案浪费计算资源,所以可以针对hbase数据创建二级索引(Hbase Sec ...
- Phoneix(二)HBase集成Phoenix安装
一.软件下载 1.访问:http://phoenix.apache.org/ 2.点击: 3.进入以下内容:点击 4.跳转到 5.跳转到 6.点击安装包,进入 点击进行下载: 二.安装 phoneni ...
- phoenix中添加二级索引
Phoenix创建Hbase二级索引 官方文档 1. 配置Hbase支持Phoenix创建二级索引 1. 添加如下配置到Hbase的Hregionserver节点的hbase-site.xml ...
- 「从零单排HBase 12」HBase二级索引Phoenix使用与最佳实践
Phoenix是构建在HBase上的一个SQL层,能让我们用标准的JDBC APIs对HBase数据进行增删改查,构建二级索引.当然,开源产品嘛,自然需要注意“避坑”啦,阿丸会把使用方式和最佳实践都告 ...
- HBase学习(四) 二级索引 rowkey设计
HBase学习(四) 一.HBase的读写流程 画出架构 1.1 HBase读流程 Hbase读取数据的流程:1)是由客户端发起读取数据的请求,首先会与zookeeper建立连接2)从zookeepe ...
随机推荐
- Python使用import导入模块时执行了模块的文件但报ModuleNotFoundError错误的愚蠢问题
老猿在学习import导入自定义模块时,搜索路径中sys.path中已经添加对应路径,发现会报ModuleNotFoundError,但对应的模块代码被执行了,代码myfib.py如下: def fi ...
- 解析php sprintf函数漏洞
php sprintf函数漏洞 0x01 了解sprintf()函数 1,sprintf(),函数是php中的函数 2,作用是将格式化字符串写入变量中 3,函数形式为sprintf(format,ar ...
- pytorch知识(torch.sum,以及维度问题)
参考(推荐): https://mathpretty.com/12065.html
- 【APIO2019】桥梁(询问分块)
Description 给定一张 \(n\) 个点,\(m\) 条边的无向图,边 \(i\) 的权值为 \(d_i\).现有 \(q\) 次操作,第 \(j\) 个操作有两种模式: \(1\ b_j\ ...
- Robot Framework+adb框架自动化测试Android设备案例⑸——L1层测试用例
一.L1层测试用例 1.初始化.robot *** Settings *** Resource ../L2层关键字.robot *** Test Cases *** 切换EMMC模式 [Tags] A ...
- Java为什么称为动态编译?
Java在程序运行时产生Java类并编译成.class文件.
- react项目中对dom元素样式修改的另一种方法以及将组件插入到node节点中
在项目中,以前如果遇到对dom元素的操作都是直接获取dom元素,比如说: 但是如果修改的样式比较多的话,不如直接"切换"dom元素,如下例子: 这样会节省一些性能.因为操作dom的 ...
- Java IO流字符流简介及基本使用
Java IO流字符流简介及常用字符流的基本使用 字符流分为输入字符流(Writer)和输出字符流(Reader),这两种字符流及其子类字符流都有自己专门的功能.在编码中我们常用的输出字符流有File ...
- ECharts的下载和安装(图文详解)
首先搜索找到ECharts官网,点击进入. 找到下载 进入就看到第三步,就点击在线制作 点击进入之后就自己可以选择里面的形状图,就在线制作.最后生成echarts.min.js 点击下载后就会生成js ...
- phpStudy后门分析及复现
参考文章:https://blog.csdn.net/qq_38484285/article/details/101381883 感谢大佬分享!! SSRF漏洞学习终于告一段落,很早就知道phpstu ...