python+selenium+chromedriver抓取shodan搜索结果
作用:免积分抓取shodan的搜索结果,并把IP保存为txt
前提:
①shodan会员(ps:黑色星期五打折)
②安装有python27
③谷歌浏览器(ps:版本一定要跟chromedriver匹配)
④windows系统
开始:
一.安装好必要的包
①win+R 调用cmd
②cd C:\Python27\Scripts(ps:以你自己实际安装目录来)
③pip install selenium
④pip install pyquery
二.下载核心组件和脚本
①shodan_project.zip 并且把解压到C:\Python27\
②chromedriver 解压进C:\Python27\shodan_project (ps:版本要跟谷歌浏览器对应,不然会导致抓取失败)
使用教程:
①修改shodan账号密码,和你要搜索的关键字

②python shodan_main.py 出现以下画面说明成功运行
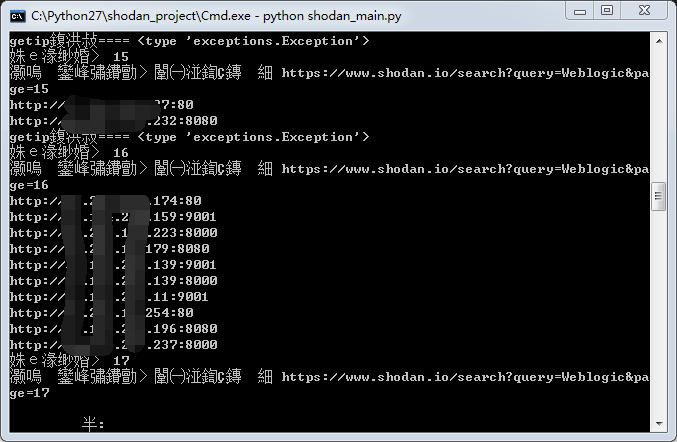
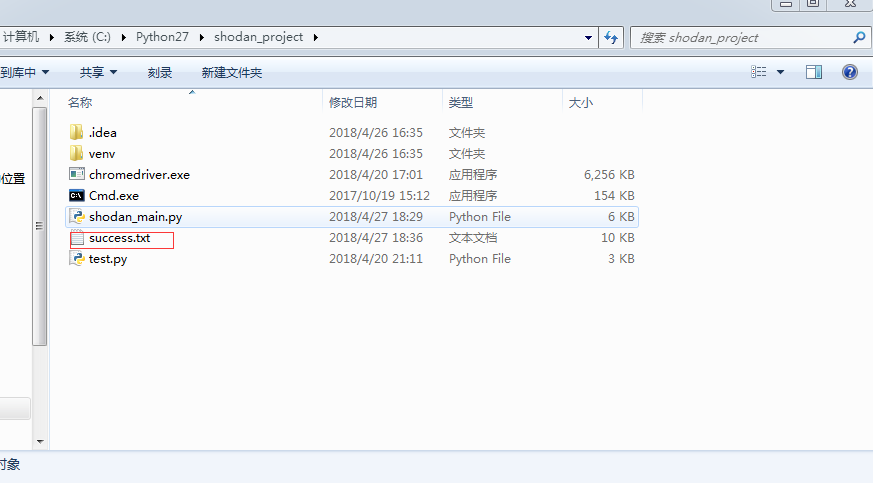
③结果保存在success.txt
缺点:
①由于原作者是写死只抓取<a href="http://.*">格式的ip,会导致很多结果无法抓取出现getipfail<type'exceptions,Exception>的情况。
②然而shodan搜到的ip会有https,/host/,http等多种情况。你可以根据自己的情况修改源码。或者等我学习爬虫后出个升级版
临时解决办法:
①打开shodan_main.py,改为下面的语法
ip_item = re.findall(r'<a href=".*">', contents) 三个格式都抓取
②然而这样会导致下面的情况,把http://,/host/也给搞了进来
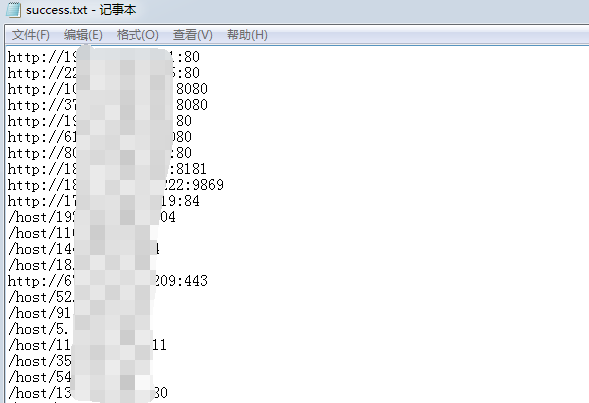
③我们可以利用记事本的替换功能,点击全部替换。
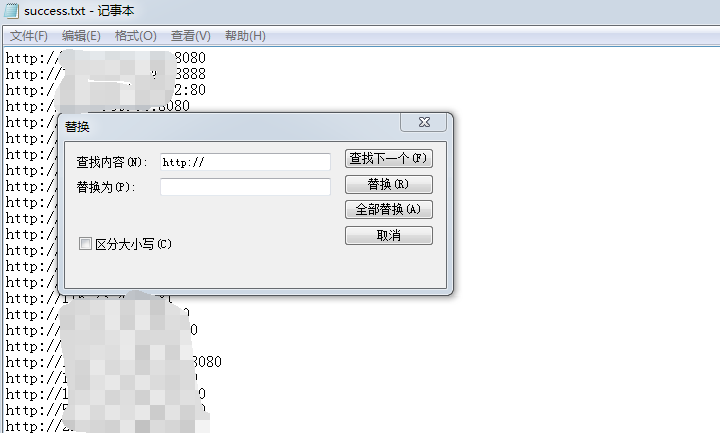
改进:
①bat指定Notepad++打开shodan_main.py
start /d "C:\Program Files (x86)\Notepad++" notepad++.exe "C:\Python27\shodan_project\shodan_main.py"
②bat一键启动shodan_main.py
@echo off
cd C:\Python27\shodan_project start python shodan_main.py exit
③bat打开结果目录
start explorer "C:\Python27\shodan_project"
2018/4/28更新:
①把keyword=的""改为',这样才能搜字符串
shodan_seach(keywords='6379 country:"US"') #关键字
②修改re.sub替换函数
ip = re.sub('/host/|http://|https://|">', "", ip) # |是或的意思,这样就不用手动替换了
2018/4/29更新:
①项目添加clean.py,过滤success.txt里的个别乱码
#!/usr/bin/env python
#_*_coding:utf-8 _*_
__author__ = 'gaogd'
import re with open('success.txt','r') as f:
for line in f.readlines():
result2 = re.findall('[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}', line)
if not result2 == []:
print result2[0]
result = result2[0] + '\n'
with open('arr_ip.txt', 'a+') as w:
w.write(result)
②修改打开结果的bat
@echo off
cd C:\Python27\shodan_project start python clean.py '打开结果前运行该脚本 start explorer "C:\Python27\shodan_project" exit 'arr_ip.txt就是过滤后干净的ip
感谢:
参考:
②如何用python的re.sub( )方法进行“多处”替换
python+selenium+chromedriver抓取shodan搜索结果的更多相关文章
- 关于python抓取google搜索结果的若干问题
关于python抓取google搜索结果的若干问题 前一段时间一直在研究如何用python抓取搜索引擎结果,在实现的过程中遇到了很多的问题,我把我遇到的问题都记录下来,希望以后遇到同样问题的童 ...
- [Python爬虫] 之九:Selenium +phantomjs抓取活动行中会议活动(单线程抓取)
思路是这样的,给一系列关键字:互联网电视:智能电视:数字:影音:家庭娱乐:节目:视听:版权:数据等.在活动行网站搜索页(http://www.huodongxing.com/search?city=% ...
- selenium+PhantomJS 抓取淘宝搜索商品
最近项目有些需求,抓取淘宝的搜索商品,抓取的品类还多.直接用selenium+PhantomJS 抓取淘宝搜索商品,快速完成. #-*- coding:utf-8 -*-__author__ =''i ...
- selenium+chrome抓取数据,运行js
某些特殊的网站需要用selenium来抓取数据,比如用js加密的,破解难度大的 selenium支持linux和win,前提是必须安装python3,环境配置好 抓取代码: #!/usr/bin/en ...
- C#使用Selenium+PhantomJS抓取数据
本文主要介绍了C#使用Selenium+PhantomJS抓取数据的方法步骤,具有很好的参考价值,下面跟着小编一起来看下吧 手头项目需要抓取一个用js渲染出来的网站中的数据.使用常用的httpclie ...
- selenium-java web自动化测试工具抓取百度搜索结果实例
selenium-java web自动化测试工具抓取百度搜索结果实例 这种方式抓百度的搜索关键字结果非常容易抓长尾关键词,根据热门关键词去抓更多内容可以用抓google,百度的这种内容容易给屏蔽,用这 ...
- scrapy和selenium结合抓取动态网页
1.安装python (我用的是2.7版本的) 2.安装scrapy: 详情请参考 http://blog.csdn.net/wukaibo1986/article/details/8167590 ...
- 测试开发Python培训:抓取新浪微博抓取数据-技术篇
测试开发Python培训:抓取新浪微博抓取数据-技术篇 poptest是国内唯一一家培养测试开发工程师的培训机构,以学员能胜任自动化测试,性能测试,测试工具开发等工作为目标.在poptest的se ...
- 利用Python网络爬虫抓取微信好友的签名及其可视化展示
前几天给大家分享了如何利用Python词云和wordart可视化工具对朋友圈数据进行可视化,利用Python网络爬虫抓取微信好友数量以及微信好友的男女比例,以及利用Python网络爬虫抓取微信好友的所 ...
随机推荐
- js后台提交成功后 关闭当前页 并刷新父窗体
后台提交成功后 关闭当前页 并刷新父窗体 this.ClientScript.RegisterStartupScript(this.GetType(), "message", &q ...
- docker部署nginx服务器
1,下载nginx镜像 docker pull nginx 2,启动 docker run --name runoob-nginx-test -p 8081:80 -d nginx 3,创建本地目录 ...
- etc/river.toml
# MySQL address, user and password # user must have replication privilege in MySQL. my_addr = " ...
- 刷题不应该刷leecode 应该刷oj
因为leecode有很多题目 表述不清 意义不明 最关键的是 leecode压根不规定输入输出的格式 这个完全不是竞赛的风格 这样会养成很多坏习惯
- String字符串性能优化的探究
一.背景 String 对象是我们使用最频繁的一个对象类型,但它的性能问题却是最容易被忽略的.String 对象作为 Java 语言中重要的数据类型,是内存中占用空间最大的一个对象,高效地使用字符串, ...
- java关键字之abstract
Java 允许类,借口或成员方法具有抽象属性. abstract 修饰的类叫做抽象类,该类不能被实例化. abstract 修饰的方法叫抽象方法,抽象方法只有声明部分,没有具体的方法体. 接口总是 ...
- 浅谈分布式共识算法raft
前言:在分布式的系统中,存在很多的节点,节点之间如何进行协作运行.高效流转.主节点挂了怎么办.如何选主.各节点之间如何保持一致,这都是不可不面对的问题,此时raft算法应运而生,专门 用来解决上述问题 ...
- Java学习的第三十八天
例3.4. package bgio; public class cjava { public static void main(String[]args) { int i=1; int sum=0; ...
- Python实现微信支付(三种方式)
Python实现微信支付(三种方式) 关注公众号"轻松学编程"了解更多. 如果需要python SDk源码,可以加我微信[1257309054] 在文末有二维码. 一.准备环境 1 ...
- java常用类——包装类
八种基本数据类型对应八种包装类和它们的继承关系 基本数据类型 对应的包装类 boolean Boolean byte Byte short Short int Integer long Long ch ...