python+selenium+chromedriver抓取shodan搜索结果
作用:免积分抓取shodan的搜索结果,并把IP保存为txt
前提:
①shodan会员(ps:黑色星期五打折)
②安装有python27
③谷歌浏览器(ps:版本一定要跟chromedriver匹配)
④windows系统
开始:
一.安装好必要的包
①win+R 调用cmd
②cd C:\Python27\Scripts(ps:以你自己实际安装目录来)
③pip install selenium
④pip install pyquery
二.下载核心组件和脚本
①shodan_project.zip 并且把解压到C:\Python27\
②chromedriver 解压进C:\Python27\shodan_project (ps:版本要跟谷歌浏览器对应,不然会导致抓取失败)
使用教程:
①修改shodan账号密码,和你要搜索的关键字

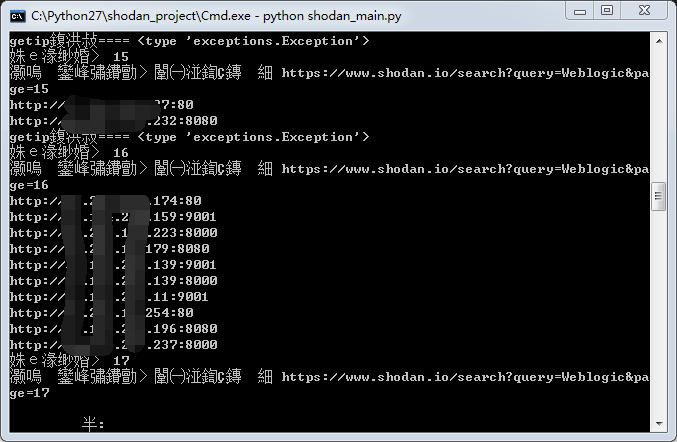
②python shodan_main.py 出现以下画面说明成功运行
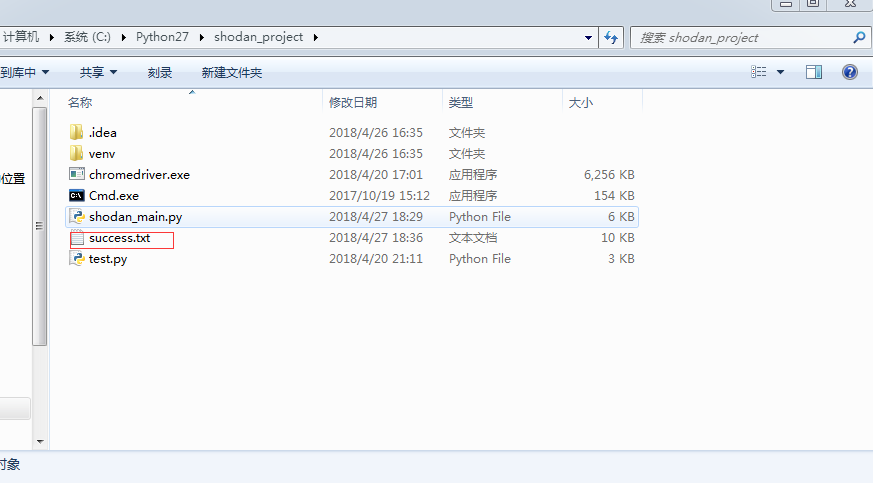
③结果保存在success.txt
缺点:
①由于原作者是写死只抓取<a href="http://.*">格式的ip,会导致很多结果无法抓取出现getipfail<type'exceptions,Exception>的情况。
②然而shodan搜到的ip会有https,/host/,http等多种情况。你可以根据自己的情况修改源码。或者等我学习爬虫后出个升级版
临时解决办法:
①打开shodan_main.py,改为下面的语法
ip_item = re.findall(r'<a href=".*">', contents) 三个格式都抓取
②然而这样会导致下面的情况,把http://,/host/也给搞了进来
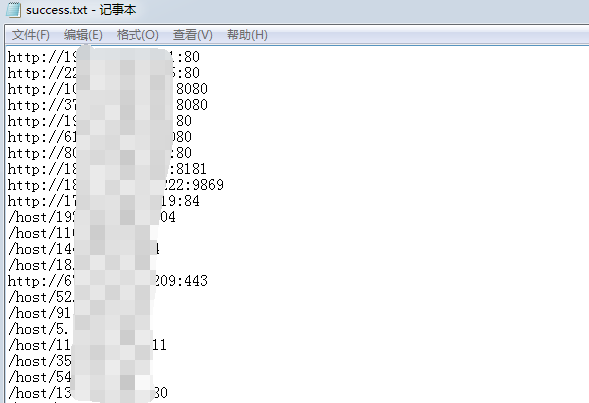
③我们可以利用记事本的替换功能,点击全部替换。
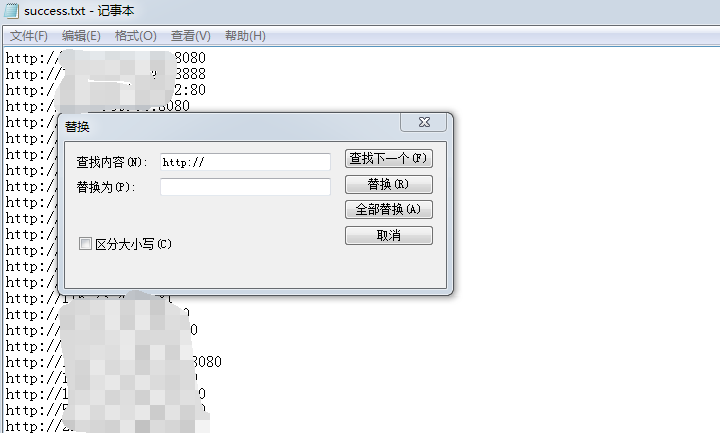
改进:
①bat指定Notepad++打开shodan_main.py
start /d "C:\Program Files (x86)\Notepad++" notepad++.exe "C:\Python27\shodan_project\shodan_main.py"
②bat一键启动shodan_main.py
@echo off
cd C:\Python27\shodan_project start python shodan_main.py exit
③bat打开结果目录
start explorer "C:\Python27\shodan_project"
2018/4/28更新:
①把keyword=的""改为',这样才能搜字符串
shodan_seach(keywords='6379 country:"US"') #关键字
②修改re.sub替换函数
ip = re.sub('/host/|http://|https://|">', "", ip) # |是或的意思,这样就不用手动替换了
2018/4/29更新:
①项目添加clean.py,过滤success.txt里的个别乱码
#!/usr/bin/env python
#_*_coding:utf-8 _*_
__author__ = 'gaogd'
import re with open('success.txt','r') as f:
for line in f.readlines():
result2 = re.findall('[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}', line)
if not result2 == []:
print result2[0]
result = result2[0] + '\n'
with open('arr_ip.txt', 'a+') as w:
w.write(result)
②修改打开结果的bat
@echo off
cd C:\Python27\shodan_project start python clean.py '打开结果前运行该脚本 start explorer "C:\Python27\shodan_project" exit 'arr_ip.txt就是过滤后干净的ip
感谢:
参考:
②如何用python的re.sub( )方法进行“多处”替换
python+selenium+chromedriver抓取shodan搜索结果的更多相关文章
- 关于python抓取google搜索结果的若干问题
关于python抓取google搜索结果的若干问题 前一段时间一直在研究如何用python抓取搜索引擎结果,在实现的过程中遇到了很多的问题,我把我遇到的问题都记录下来,希望以后遇到同样问题的童 ...
- [Python爬虫] 之九:Selenium +phantomjs抓取活动行中会议活动(单线程抓取)
思路是这样的,给一系列关键字:互联网电视:智能电视:数字:影音:家庭娱乐:节目:视听:版权:数据等.在活动行网站搜索页(http://www.huodongxing.com/search?city=% ...
- selenium+PhantomJS 抓取淘宝搜索商品
最近项目有些需求,抓取淘宝的搜索商品,抓取的品类还多.直接用selenium+PhantomJS 抓取淘宝搜索商品,快速完成. #-*- coding:utf-8 -*-__author__ =''i ...
- selenium+chrome抓取数据,运行js
某些特殊的网站需要用selenium来抓取数据,比如用js加密的,破解难度大的 selenium支持linux和win,前提是必须安装python3,环境配置好 抓取代码: #!/usr/bin/en ...
- C#使用Selenium+PhantomJS抓取数据
本文主要介绍了C#使用Selenium+PhantomJS抓取数据的方法步骤,具有很好的参考价值,下面跟着小编一起来看下吧 手头项目需要抓取一个用js渲染出来的网站中的数据.使用常用的httpclie ...
- selenium-java web自动化测试工具抓取百度搜索结果实例
selenium-java web自动化测试工具抓取百度搜索结果实例 这种方式抓百度的搜索关键字结果非常容易抓长尾关键词,根据热门关键词去抓更多内容可以用抓google,百度的这种内容容易给屏蔽,用这 ...
- scrapy和selenium结合抓取动态网页
1.安装python (我用的是2.7版本的) 2.安装scrapy: 详情请参考 http://blog.csdn.net/wukaibo1986/article/details/8167590 ...
- 测试开发Python培训:抓取新浪微博抓取数据-技术篇
测试开发Python培训:抓取新浪微博抓取数据-技术篇 poptest是国内唯一一家培养测试开发工程师的培训机构,以学员能胜任自动化测试,性能测试,测试工具开发等工作为目标.在poptest的se ...
- 利用Python网络爬虫抓取微信好友的签名及其可视化展示
前几天给大家分享了如何利用Python词云和wordart可视化工具对朋友圈数据进行可视化,利用Python网络爬虫抓取微信好友数量以及微信好友的男女比例,以及利用Python网络爬虫抓取微信好友的所 ...
随机推荐
- C# indexof和indexofany区别(转)
定位子串是指在一个字符串中寻找其中包含的子串或者某个字符.在String类中,常用的定位子串和字符的方法包括IndexOf/LastIndexOf及IndexOfAny/LastIndexOfAny, ...
- MySQL安装版本介绍
MySQL安装 源码安装 二进制格式的程序包 程序包管理器安装 yum dnf MySQL在CentOS上的情况 6上只有mySQL 7上只有mariadb 8上既有mysql也有mariadb Ce ...
- Java 等待/通知机制
等待/通知的目的是确保等待线程从wait()方法返回时能够感知到通知线程对变量所做出的的修改: 等待方遵循如下原则: 1.获取对象的锁 2.如果条件不满足,那么调用对象的wait()方法,被通知后任要 ...
- ElasticSearch详细笔记
ElasticSearch详细笔记 什么是ElasticSearch Elasticsearch(简称ES)是一个基于Apache Lucene(TM)的开源搜索引擎,无论在开源还是专有领域,Luce ...
- Chrome FeHelper 插件下载地址
方便大家下载 下载可用,本人亲自测试 下载地址: 地址链接
- 完美解决CentOS8 yum安装AppStream报错,更新yum后无法makecache的问题
问题 CentOS 8 yum安装软件时,提示无法从AppStream下载 [root@C8-3 ~]# yum -y install httpd mariadb-server mariadb php ...
- Java Web中解决乱码的方式
Java Web中解决乱码的方式 方式一:添加编码过滤器 package com.itmacy.dev.filter; import javax.servlet.*; import javax.ser ...
- 对于RBAC与shiro的一些思考
一.什么是RBAC模型 RBAC模型是一个解决用户权限问题的设计思维. 在最简单的RBAC模型中,将用户表设计为如下几个表 1.用户 2.角色 3.权限 以及这三张表衍生出来的两张中间表 4.用户_角 ...
- visual c++6.0使用VA注意事项
visual c++6.0使用VA时配置: (1)因为VA安装时会自动检索MSDEV.exe:如果V6安装在XP或者win7系统上,直接安装,添加addin即可: (2)但是如果安装在win8上,V6 ...
- php 导出excel 10万数据
php导出excel 10万数据(此代码主要测试用) 在工作当中要对一些基本信息和其他信息导出 起初信息比较小无所谓.... 但当信息超出65535的时候 发现点问题了 超出了 而且 反应速度很慢 实 ...