mysql聚簇索引和非聚簇索引
聚簇索引
InnoDB使用的是聚簇索引
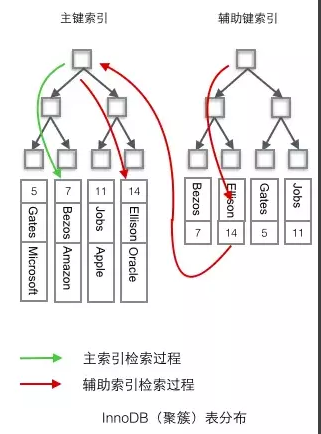
- 将数据与主键索引放在了一起,索引的叶子节点保存了行数据,找到了主键索引,即找到了行数据。
- 辅助索引记录了主键的位置,所以查询where name= xxx 时,先找辅助索引树,找到主键位置,然后找数据树,找到数据行
- 聚簇索引的数据的物理存放顺序与索引顺序是一致的,即:只要索引时相邻的,那么对应的数据一定也是相邻地存放在磁盘上的。聚簇索引要比非聚簇索引查询效率高很多。
- 聚簇索引这种主+辅索引的好处是,当发生数据行移动或者页分裂时,辅助索引树不需要更新,因为辅助索引树存储的是主索引的主键关键字,而不是具体的物理地址。
非聚簇索引
MyISAM是非聚簇索引
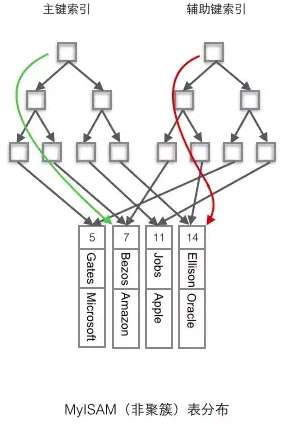
- B+Tree的叶子节点上的data,并不是数据本身,而是数据存放的地址。主索引和辅助索引没啥区别,只是主索引中的key一定得是唯一的.
聚簇索引的优点
- 聚簇索引这种主+辅索引的好处是,当发生数据行移动或者页分裂时,辅助索引树不需要更新,因为辅助索引树存储的是主索引的主键关键字,而不是具体的物理地址。
- 当你需要取出一定范围内的数据时,用聚簇索引也比用非聚簇索引好。
- 当一条查询语句符合覆盖索引条件时,只需要通过索引就可以返回查询所需要的数据,这样避免了查到索引后再返回表操作,减少I/O提高效率
聚簇索引的缺点
- 插入速度严重依赖于插入顺序,按照主键的顺序插入是最快的方式,否则将会出现页分裂,严重影响性能。因此,对于InnoDB表,我们一般都会定义一个自增的ID列为主键。
- 更新主键的代价很高,因为将会导致被更新的行移动。因此,对于InnoDB表,我们一般定义主键为不可更新。
- 使用辅助索引查询时需要查两次
- 采用聚簇索引插入新值比采用非聚簇索引插入新值的速度要慢很多,因为插入要保证主键不能重复,判断主键不能重复,采用的方式在不同的索引下面会有很大的性能差距,聚簇索引遍历所有的叶子节点,非聚簇索引也判断所有的叶子节点,但是聚簇索引的叶子节点除了带有主键还有记录值,记录的大小往往比主键要大的多。这样就会导致聚簇索引在判定新记录携带的主键是否重复时进行昂贵的I/O代价。
磁盘分块和内存分页
mysql聚簇索引和非聚簇索引的更多相关文章
- MYSQL性能调优: 对聚簇索引和非聚簇索引的认识
聚簇索引是对磁盘上实际数据重新组织以按指定的一个或多个列的值排序的算法.特点是存储数据的顺序和索引顺序一致.一般情况下主键会默认创建聚簇索引,且一张表只允许存在一个聚簇索引. 在<数据库原理&g ...
- MySQL 聚簇索引和非聚簇索引的认识
聚簇索引是对磁盘上实际数据重新组织以按指定的一个或多个列的值排序的算法.特点是存储数据的顺序和索引顺序一致.一般情况下主键会默认创建聚簇索引,且一张表只允许存在一个聚簇索引. 在<数据库原理&g ...
- mysql索引总结(3)-MySQL聚簇索引和非聚簇索引
mysql索引总结(1)-mysql 索引类型以及创建 mysql索引总结(2)-MySQL聚簇索引和非聚簇索引 mysql索引总结(3)-MySQL聚簇索引和非聚簇索引 mysql索引总结(4)-M ...
- mysql索引总结(2)-MySQL聚簇索引和非聚簇索引
mysql索引总结(1)-mysql 索引类型以及创建 mysql索引总结(2)-MySQL聚簇索引和非聚簇索引 mysql索引总结(3)-MySQL聚簇索引和非聚簇索引 mysql索引总结(4)-M ...
- mysql 聚簇索引、非聚簇索引的区别
索引分为聚簇索引和非聚簇索引. 以一本英文课本为例,要找第8课,直接翻书,若先翻到第5课,则往后翻,再翻到第10课,则又往前翻.这本书本身就是一个索引,即"聚簇索引". 如果要找& ...
- mysql索引之聚簇索引与非聚簇索引
1 数据结构及算法基础 1.1 索引的本质 官方定义:索引(Index)是帮助MySQL高效获取数据的数据结构 本质:索引是数据结构 查询是数据库的最主要功能之一.我们都希望查询速度能尽可能快,因此数 ...
- 【Mysql优化】聚簇索引与非聚簇索引概念
必须为主键字段创建一个索引,这个索引就是所谓的"主索引".主索引与唯一索引的唯一区别是:前者在定义时使用的关键字是PRIMARY而不是UNIQUE. 首先明白两句话: innod ...
- MySQL中Innodb的聚簇索引和非聚簇索引
聚簇索引 数据库表的索引从数据存储方式上可以分为聚簇索引和非聚簇索引(又叫二级索引)两种.Innodb的聚簇索引在同一个B-Tree中保存了索引列和具体的数据,在聚簇索引中,实际的数据保存在叶子页中, ...
- 一分钟明白MySQL聚簇索引和非聚簇索引
MySQL的InnoDB索引数据结构是B+树,主键索引叶子节点的值存储的就是MySQL的数据行,普通索引的叶子节点的值存储的是主键值,这是了解聚簇索引和非聚簇索引的前提 什么是聚簇索引? 很简单记住一 ...
- MySQL聚簇索引和非聚簇索引的对比
首先要清楚:聚簇索引并不是一种单独的索引类型,而是一种存储数据的方式. 聚簇索引在实际中用的很多,Innodb就是聚簇索引,Myisam 是非聚簇索引. 在之前我想插入一段关于innodb和myisa ...
随机推荐
- linux之DNS服务
1.DNS (Domain Name Service 域名解析) DNS是因特网上作为域名和IP地址相互映射的一个分布式数据库,能够使用户更方便的访问互联网而不需要记忆能够直接被机器识别的IP. BI ...
- linux下内存释放
细心的朋友会注意到,当你在linux下频繁存取文件后,物理内存会很快被用光,当程序结束后,内存不会被正常释放,而是一直作为caching.这个问题,貌似有不少人在问,不过都没有看到有什么很好解决的办法 ...
- MySQL存储索引InnoDB数据结构为什么使用B+树,而不是其他树呢?
InnoDB的一棵B+树可以存放多少行数据? 答案:约2千万 为什么是这么多? 因为这是可以算出来的,要搞清楚这个问题,先从InnoDB索引数据结构.数据组织方式说起. 计算机在存储数据的时候,有最小 ...
- sqlilab less23-less27a
less23 本关过滤掉了注释符号-- 和#,并且变量带入数据库时被单引号包裹.需要将后边的单引号闭合.使用and '1'='1,将其加在注入语句的末尾,使用suffix参数 less-24 以后填坑 ...
- mysql学习——数据库基本操作
查看当前数据库 创建数据库 查看数据库定义 删除数据库
- 新鲜出炉!花了三天整理的JVM复习知识点,面试突击必备!
此次JVM知识点包含以下几个部分 1.类加载机制 2.jvm运行时数据区 3.java对象内存布局 4.jvm内存模型 5.垃圾回收机制 6.垃圾收集器 7.问题排查 一 类加载机制 主要说的部分是这 ...
- C语言新手入门
include<stdio.h> int main() { //输入一个数 输出它的反序列 c int a,b=0; scanf("%d",&a);//输入一个 ...
- 2016湖南省赛 A 2016 题解(同余)
题目链接 题目大意 给出正整数 n 和 m,统计满足以下条件的正整数对 (a, b) 的数量: 1<=a<=n 1<=b<=m a*b%2016=0 题目思路 我本来以为是容斥 ...
- qsort的cmp函数理解
qsort使用 近期频繁使用qsort函数,但是对于cmp函数却一直不太熟悉,现用现查.故写一篇小笔记记录一下. 函数原型: void qsort(void *base,size_t NumEle,s ...
- 一周一个中间件-hbase
前言 hbase是大数据的生态的一部分,是高可靠性.高性能.列存储.可伸缩.实时读写的数据库系统.介于nosql和RDBMS之间.主要存储非结构化和半结构化的松散数据. 海量数据存储 快速随机访问 大 ...