Redis短结构与分片
本文将介绍两种降低Redis内存占用的方法——使用短结构存储数据和对数据进行分片。
降低Redis内存占用有助于减少创建快照和加载快照所需的时间、提升载入AOF文件和重写AOF文件时的效率、缩短从服务器同步所需的时间,并能让Redis存储更多的数据。
Redis短结构
Redis为列表、集合、散列和有序集合提供了一组配置选项(配置文件中),这些选项可以让Redis以更加节约空间的方式存储长度较短的结构(即短结构)。
在列表、散列和有序集合的长度较短或者体积较小的时候,Redis可以选择使用一种名为压缩列表(ziplist)的紧凑存储方式来存储这些结构。压缩列表会以序列化的方式存储数据,这些序列化数据每次被读取的时候都要就行解码,每次被写入的时候都要进行局部的重新编码,并且可能需要对内存里的数据进行移动。因此读写一个长度较大的压缩列表可能会给性能带来负面的影响。
来看一下不同结构使用压缩列表表示的配置选项:
list-max-ziplist-entries
list-max-ziplist-value 64 当列表的元素长度都小于64字节并且列表元素数量小于512时,使用压缩列表,反之使用linkedlist。 hash-max-ziplist-entries
hash-max-ziplist-value 64 当散列的元素的键和值都小于64字节并且键值对的数量小于512时,使用压缩列表,反之使用hashtable zset-max-ziplist-entries
zset-max-ziplist-value 64 当有序集合的元素都小于64字节并且元素数量小于128个的时候,使用压缩列表,反之使用skiplist
-max-ziplist-entries:表示列表、散列和有序集合在被编码为压缩列表的情况下,允许包含的最大元素数量。
-max-ziplist-value:表示压缩列表的每个节点的最大体积是多少 。
列表、散列和有序集合的基本配置选项很相似,它们都由*-max-ziplist-entries和*-max-ziplist-value组成。当这些选项设置的限制条件中的任意一个被打破的时候,Redis就会将相应的列表、散列或者有序集合从压缩列表编码转换为其他结构,而内存的占用也会因此增加。下面给出一个例子:
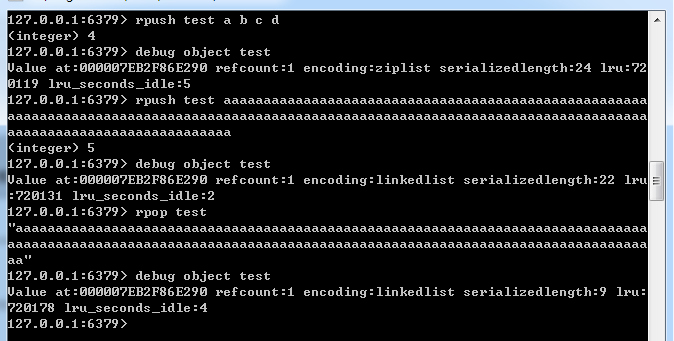
上面的图中,首先推入4个元素到test列表,然后通过debug object命令查看“test”的相关信息,可以发现“test”的存储结构为ziplist(压缩列表),当推入一个超出编码允许大小的元素时,“test”的存储结构将从ziplist转换为linkedlist,而且即使将超出编码允许大小的元素弹出后,列表test的存储结构也不会重新转换为压缩列表。
跟列表、散列和有序集合一样,体积较小的集合也有自己的短结构:如果集合包含的所有成员都可以被解释为十进制整数,而这些整数又处于平台的有符号整数范围之内,并且集合成员的数量满足配置文件中的限制条件,那么Redis就会以有序整数数组的方式存储集合。这种存储方式又被称为整数集合(intset)。
我们先来看一下集合使用整数集合表示的限制条件:
set-max-intset-entries 512 --只要集合存储的整数数量没有超过512,Redis就会使用整数集合表示以减少数据的体积。
再来看一下操作实例:
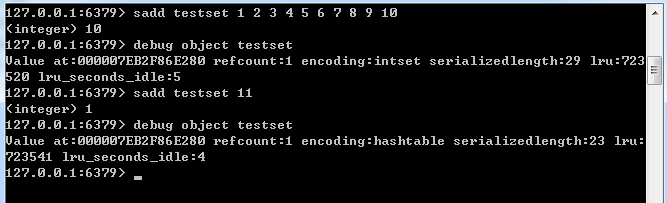
为了方便测试,我将set-max-intset-entries设置为10,首先向集合testset中加入10个整数元素,testset的存储结构为intset(整数集合),当再向testset中增加一个整数元素时,此时集合元素数量超过了set-max-intset-entries的设置,此时testset的存储结构将从整数集合(intset)转换为散列表(hashtable)。
前面提到过,读写一个长度较大的压缩列表可能会给性能带来负面的影响,同样,操作一个元素数量较多的整数集合时也可能会给性能带来负面影响,所以Redis才会在压缩列表和整数集合突破限制条件时,将其转换为更底层的结构类型。
Redis分片结构
分片(sharding)是一种广为人知的技术,很多数据库都使用这种技术来扩展存储空间并提高自己所能处理的负载量。分片本质上就是基于某些简单的规则,将数据划分为更小的部分,然后根据数据所属的部分来决定将数据分配到哪或者从哪获取数据。而Redis分片就是将数据拆分到多个Redis服务器的过程,这样每个Redis服务器将只存储原数据的子集。
Redis分片的作用:
- 允许使用很多电脑的内存总和来支持更大的数据库。没有分片,你就被局限于单机能支持的内存容量。
- 允许伸缩计算能力到多核或多服务器,伸缩网络带宽到多服务器或多网络适配器。
Redis分片的方式:
假设我们有4个Redis服务器R0,R1,R2,R3,还有很多表示用户的键,像user:1,user:2....,我们能找到不同的方式来选择一个指定的键存储在哪个服务器中。换句话说,有许多不同的办法来映射一个键到一个指定的Redis服务器。
最简单的执行分片的方式之一是范围分片(range partitioning),通过映射对象的范围到指定的Redis实例来完成分片。例如,我可以假设用户从ID 0到ID 10000进入实例R0,用户从ID 10001到ID 20000进入实例R1。
这套办法行得通,然而,这样做有一个缺点,就是需要一个映射范围到实例的表格。这张表需要管理,不同类型的对象都需要一个表,所以范围分片在Redis中并不经常使用,因为这要比其它分片可选方案低效得多。
还有一种分片方式是哈希分片(hash partitioning)。这种模式适用于任何键,它的工作原理是 :
- 使用一个哈希函数(例如,CRC32哈希函数)将键名转换为一个数字。例如,如果键是foobar,CRC32(foobar)将会输出类似于93024922的东西。
- 对这个数据进行取模运算,以将其转换为一个0到3之间的数字,这样这个数字就可以映射到4台Redis服务器总的一个上。93024922模4等于2,所以键foobar应当存储到R2实例。
Redis分片的缺点:
- 涉及多个键的操作通常不支持。例如,你不能对映射在两个不同Redis服务器上的键执行交集。
- 涉及多个键的事务不能使用。
- 数据处理变得更复杂,例如,你需要处理多个RDB/AOF文件,备份数据时你需要聚合多个实例和主机的持久化文件。
用Java实现Redis分片:
在对数据结构进行分片的时候,我们既可以实现结构的所有功能,也可以只实现结构的部分功能。这里的例子中,实现了散列结构的分片函数以及分片散列的HSET和HGET功能。
例子中对散列进行分片的时候,使用的是哈希分片的方式,即使用CRC32函数将散列里元素的键转换为数字,再根据元素的总数量和每个分片需要存储的元素数量计算出所需要的分片数量,并使用这个分片数量和之前的数字键来决定应该把元素存储到哪个分片里面。
根据基础键和散列键计算出分片键的函数:
//在调用shardKey函数时,用户需要给定基础散列的名字、将要被存储到分片散列里面的元素的键、预计的元素总数量以及每个分片存储的元素数量
public String shardKey(String base, String key, long totalElements, int shardSize) {
long shardId = 0;
if (isDigit(key)) { //如果key是一个整数,那么它将被直接用于计算分片ID
shardId = Integer.parseInt(key, 10) / shardSize;
}else{
CRC32 crc = new CRC32();
crc.update(key.getBytes());
long shards = 2 * totalElements / shardSize; //计算分片的总数量
shardId = Math.abs(((int)crc.getValue()) % shards); //计算分片ID
}
return base + ':' + shardId; //把基础键和分片ID组合在一起,得到分片键
} //判断字符串是否为一个整数字符串
private boolean isDigit(String string) {
for(char c : string.toCharArray()) {
if (!Character.isDigit(c)){
return false;
}
}
return true;
}
分片散列的HSET和HGET函数:
public Long shardHset(
Jedis conn, String base, String key, String value, long totalElements, int shardSize)
{
String shard = shardKey(base, key, totalElements, shardSize); //计算出应该由哪个分片来存储
return conn.hset(shard, key, value); //将元素存储到分片里面
} public String shardHget(
Jedis conn, String base, String key, int totalElements, int shardSize)
{
String shard = shardKey(base, key, totalElements, shardSize); //计算出元素应该被存储到了哪个分片
return conn.hget(shard, key); //获取存储在分片里面的元素
}
分片散列的设置和获取操作并不复杂,其它的操作如HDEL、HINCRBY等也可以用类似的方式实现。
参考:
http://my.oschina.net/justfairytale/blog/598636?p=1
http://www.thinksaas.cn/group/topic/342661/
转载请注明出处
Redis短结构与分片的更多相关文章
- Redis短结构
本章将介绍3种非常有价值的降低Redis内存占用的方法.降低Redis的内存占用有助于减少创建快照和加载快照所需的时间.提升载入AOF文件和重写AOF文件时的效率.缩短从服务器进行同步所需的时间,并且 ...
- Redis高级实践之————Redis短连接性能优化
摘要: 对于Redis服务,通常我们推荐用户使用长连接来访问Redis,但是由于某些用户在连接池失效的时候还是会建立大量的短连接或者用户由于客户端限制还是只能使用短连接来访问Redis,而原生的Red ...
- 进阶的Redis之哈希分片原理与集群实战
前面介绍了<进阶的Redis之数据持久化RDB与AOF>和<进阶的Redis之Sentinel原理及实战>,这次来了解下Redis的集群功能,以及其中哈希分片原理. 集群分片模 ...
- Redis主从结构主节点执行写入后wait命令对性能的影响
这里的Redis主从结构可以是简单的主从,sentinel,redis cluster中的主从等. wait命令的作用:此命令将阻塞当前客户端,直到当前Session连接(主节点上)所有的写命令都被传 ...
- Redis底层结构全了解
第一篇文章,思来想去,写一写Redis吧,最近在深入研究它. 一丶Redis底层结构 1. redis 存储结构 redis的存储结构从外层往内层依次是redisDb.dict.dictht.dict ...
- Redis的结构和运作机制
目录 1.数据库的结构 1.1 字典的底层实现 2.过期键的检查和清除 2.1 定时删除 2.2 惰性删除 2.3 定期删除 2.4 对RDB.AOF和复制的影响 3.持久化机制 3.1 RDB方式 ...
- redis集群与分片(1)-redis服务器集群、客户端分片
下面是来自知乎大神的一段说明,个人觉得非常清晰,就收藏了. 为什么集群? 通常,为了提高网站响应速度,总是把热点数据保存在内存中而不是直接从后端数据库中读取.Redis是一个很好的Cache工具.大型 ...
- Redis高可用及分片集群
一.主从复制 使用异步复制 一个服务器可以有多个从服务器 从服务器也可以有自己的从服务器 复制功能不会阻塞主服务器 可以通过服务功能来上主服务器免于持久化操作,由从服务器去执行持久化操作即可. 以下是 ...
- Redis数据库结构与读写原理
此文已由作者赵计刚薪授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. 1.数据库结构 每一个redis服务器内部的数据结构都是一个redisDb[],该数组的大小可以在redi ...
随机推荐
- Nginx 配置指令的执行顺序(二)
我们前面已经知道,当 set 指令用在 location 配置块中时,都是在当前请求的 rewrite 阶段运行的.事实上,在此上下文中,ngx_rewrite 模块中的几乎全部指令,都运行在 rew ...
- UIView添加事件
UIView *loadView = [[UIControl alloc]initWithFrame:CGRectMake(0,0,320,480)]; loadView.backgroundColo ...
- linux之SQL语句简明教程---TRIM
SQL 中的 TRIM 函数是用来移除掉一个字串中的字头或字尾.最常见的用途是移除字首或字尾的空白.这个函数在不同的资料库中有不同的名称: MySQL: TRIM( ), RTRIM( ), LTRI ...
- 【POJ 2823 Sliding Window】 单调队列
题目大意:给n个数,一个长度为k(k<n)的闭区间从0滑动到n,求滑动中区间的最大值序列和最小值序列. 最大值和最小值是类似的,在此以最大值为例分析. 数据结构要求:能保存最多k个元素,快速取得 ...
- 【LeetCode练习题】Partition List
Given a linked list and a value x, partition it such that all nodes less than x come before nodes gr ...
- flex——dictionary跟Object的区别与遍历
AS3中Object和 Dictionary都可以用来保存key-value形式的数据,Dictionary类和Object唯一的区别在于:Dictionary对象可以使用非字符串作为键值对的键.例如 ...
- sql的基本查询语句
--------------------------------------------基本常用查询-------------------------------------- 自己简单练习做了个表. ...
- ASP.NET获取IP的6种方法 【转】
).ToString();//方法四(无视代理)HttpContext.Current.Request.ServerVariables["HTTP_X_FORWARDED_FOR" ...
- ADO.NET改进版
ADO.NET从概念上来说是指定义一种与数据源进行交互的面向对象类库.类库即类的集合,也就是说ADO.NET主要是提供一了一些实现与数据源进行交互的一些类和接口. 其实就我个人看来,我觉得ADO.NE ...
- 去除express.js 3.5中报connect.multipart() will be removed in connect 3.0的警告
1 $ node app.js 2 connect.multipart() will be removed in connect 3.0 3 visit https://github.com/s ...