pandas DataFrame的查询方法(loc,iloc,at,iat,ix的用法和区别)
pandas DataFrame的增删查改总结系列文章:
在操作DataFrame时,肯定会经常用到loc,iloc,at等函数,各个函数看起来差不多,但是还是有很多区别的,我们一起来看下吧。
首先,还是列出一个我们用的DataFrame,注意index一列,如下:

接下来,介绍下各个函数的用法:
1、loc函数
愿意看官方文档的,请戳这里,这里一般最权威。
loc函数是基于“标签”选择数据的,但是也可以接受一个boolean的array,对于每个用法,我们从参数方面来一一举例:
1.1 单个label
接受一个“标签”(label)参数,返回一个Series,例如下面这个例子收一个标签,返回通过这个标签定位的行的值,注意这里是通过标签定位,而不是通过中括号中的数字定位第几行,之后我们通过对比iloc函数时还会细说。
test_dict_df.loc[1] #return the row with name 'Bob'
test_dict_df.loc[7] #return the row with name 'Time' important!!!
# type(test_dict_df.loc[1]) #pandas.core.series.Series
1.2 一个label的array
如果键入一个标签的array,那么就返回一个对应的DataFrame:
test_dict_df.loc[[1,2,4]]
结果如下:

1.3 加入一个切片array
test_dict_df.loc[[1:4]]
结果如下:

1.4 行标签,列标签
通过在中括号中加入行标签和列标签来定位一个cell,相当于坐标的定位:
test_dict_df.loc[1,'english'] #result:94
1.5 行标签或者列标签是切片array
test_dict_df.loc[1:4,'english']
# test_dict_df.loc[1:4,'english':'math']
1.6 还可以接受条件,进行选择
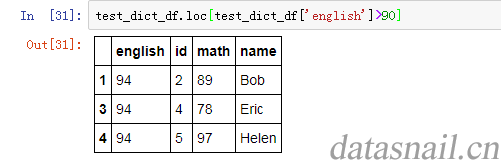
例如我们选择英语成绩超过90的所有行:
test_dict_df.loc[test_dict_df['english']>90]
当然,也可以再条件选择后,再加入列选择,列选择的时候可以单列,也可以是切片数组,通过上面的介绍这里就可以灵活处理:
test_dict_df.loc[test_dict_df['english']>90,'english'] #single label
test_dict_df.loc[test_dict_df['english']>90,'english':'name'] #slice array
test_dict_df.loc[test_dict_df['english']>90,['english','name']] #label array
1.7 接受一个boolean的array
可以接受一个boolean的array,相当于按照这个表的真假按照位置的顺序选择值
test_dict_df.loc[[True,False,False,True]]
loc还有很多用法,这里先介绍到这里吧,当然如果你的DataFrame是复合的行或者复合列,写法也是不同的,具体就可以查阅官方文档了!
2、iloc函数
官方文档戳这里。
iloc函数与loc函数不同的是,它接受的是一个数字,代表着要选择数据的位置:
test_dict_df.iloc[6]
这代表我们选择的是第6行,而不是index为6的那一行。当然,也可以接受一个boolean的array,相当于按照这个表的真假按照位置的顺序选择值:
test_dict_df.iloc[[True,False,False,True]]
这里iloc也可以接受切片array:
# test_dict_df.iloc[1:2]
test_dict_df.iloc[[1,2,4]]
3、ix函数(0.20.0版本后已经弃用)
ix就是一种混合索引,字符串的标签和证书的数据索引都可以作为合法输入,其实相当于loc和iloc的一个混合方法:
test_dict_df.ix['Alice']
test_dict_df.ix[1]
上述两种方法都能得到值,这里我们就不追究这个函数具体是怎样的检索顺序或者工作原理了。因为官方给出的是从pandas0.20.0之后,ix函数已经被弃用。其实在使用的时候,ix函数虽然方便,但是的确有时候会显得比较混乱,所以我们之后也尽量少用这个函数吧,还是按照官方大佬的指导。
4、at函数
at是用来选择单个值的,此时用法类似于loc:
test_dict_df.at[1,'english']
test_dict_df.loc[1,'english']
以上两种方法都能选择到,label为1,列为'english'的那个值,但是据说at速度要快,这点我没有考证过。
5、iat函数
iat函数相对于at函数,就相当于iloc相对于loc函数。iat也只能选择一个值。只不过是用索引位置来选择,注意:行列都是索引位置来选择,从0开始数。
# test_dict_df.iat[1,'english'] #error!!!
test_dict_df.iat[2,2] #right!!!
6、概括一下
最后我们概括一下:
1、 loc和iloc函数都是用来选择某行的,iloc与loc的不同是:iloc是按照行索引所在的位置来选取数据,参数只能是整数。而loc是按照索引名称来选取数据,参数类型依索引类型而定;
2、 at和iat函数是只能选择某个位置的值,iat是按照行索引和列索引的位置来选取数据的。而at是按照行索引和列索引来选取数据;
3、 loc和iloc函数的功能包含at和iat函数的功能。
相应的代码连接:github代码
先写到这里,如有新的再补充。
pandas DataFrame的查询方法(loc,iloc,at,iat,ix的用法和区别)的更多相关文章
- pandas中Dataframe的查询方法([], loc, iloc, at, iat, ix)
数据介绍 先随机生成一组数据: import pandas as pd import numpy as np state = ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'N ...
- pandas DataFrame的修改方法
pandas DataFrame的增删查改总结系列文章: pandas DaFrame的创建方法 pandas DataFrame的查询方法 pandas DataFrame行或列的删除方法 pand ...
- pandas DataFrame的创建方法
pandas DataFrame的增删查改总结系列文章: pandas DaFrame的创建方法 pandas DataFrame的查询方法 pandas DataFrame行或列的删除方法 pand ...
- 把pandas dataframe转为list方法
把pandas dataframe转为list方法 先用numpy的 array() 转为ndarray类型,再用tolist()函数转为list
- pandas 选取数据 修改数据 loc iloc []
pandas选取数据可以通过 loc iloc [] 来选取 使用loc选取某几列: user_fans_df = sample_data.loc[:,['uid','fans_count']] 使 ...
- pandas.DataFrame的groupby()方法的基本使用
pandas.DataFrame的groupby()方法是一个特别常用和有用的方法.让我们快速掌握groupby()方法的基础使用,从此数据分析又多一法宝. 首先导入package: import p ...
- C#中??和?分别是什么意思? 在ASP.NET开发中一些单词的标准缩写 C#SESSION丢失问题的解决办法 在C#中INTERFACE与ABSTRACT CLASS的区别 SQL命令语句小技巧 JQUERY判断CHECKBOX是否选中三种方法 JS中!=、==、!==、===的用法和区别 在对象比较中,对象相等和对象一致分别指的是什么?
C#中??和?分别是什么意思? 在C#中??和?分别是什么意思? 1. 可空类型修饰符(?):引用类型可以使用空引用表示一个不存在的值,而值类型通常不能表示为空.例如:string str=null; ...
- pandas.DataFrame 中save方法
In [5]: frame.save('frame_pickle') ----------------------------------------------------------------- ...
- Pandas:DataFrame数据选择方法(索引)
#首先创建我们的Series对象,然后合并到dataframe对象里面去 import pandas as pd import numpy as np area=pd.Series({,,,}) po ...
随机推荐
- Entity Framework 四
实体框架支持三种类型的查询:1)LINQ to Entities,2)Entity SQL,3)Native SQL LINQ方法语法: LINQ查询语法: 实体SQL: 这种可以简单的了解,不必深入 ...
- 7.Vue-Quill-Editor图片插入自定义
Vue-Quill-Editor图片插入自定义 前言: 因为在项目中前端采用了Vue来实现,正好用到了富文本编辑器这一块,于是,经过技术上的选择,决定使用Vue-Quill-Editor. 使用的过程 ...
- #leetcode刷题之路20-有效的括号
#include <iostream> #include <string> #include <stack> using namespace std; bool i ...
- 【赛事总结】◇赛时·8◇ AGC-027
[赛时·8]AGC-027 日常AGC坑……还好能涨Rating +传送门+ ◇ 简单总结 感觉像打多校赛一样,应该多关注一下排名……考试的时候为了避免影响心态,管都没有管排名,就在那里死坑B题.最后 ...
- SAP ABAP 日期,时间 相关函数
获的两个日期之间的分钟数 data min TYPE i. CALL FUNCTION 'DELTA_TIME_DAY_HOUR' EXPORTING T1 = ' T2 = ' D1 = ' D2 ...
- SpringBoot配置全局自定义异常
不同于传统集中时Springmvc 全局异常,具体查看前面的章节https://www.cnblogs.com/zwdx/p/8963311.html 对于springboot框架来讲,这里我就介绍一 ...
- Solr6.6.0添加IK中文分词器
IK分词器就是一款中国人开发的,扩展性很好的中文分词器,它支持扩展词库,可以自己定制分词项,这对中文分词无疑是友好的. jar包下载链接:http://pan.baidu.com/s/1o85I15o ...
- 利用百度地图API实现地址和经纬度互换查询
import json import requests def baiduMap(input_para): headers = { 'User-Agent': 'Mozilla/5.0 (Window ...
- Firewalld共享上网及本地yum仓库搭建
1.firewalld共享上网 1.服务端操作(有外网的服务器) 1.开启防火墙并加入开机自启动 [root@zeq ~]# systemctl start firewalld [root@zeq ~ ...
- 【解决】venv 的名字在 zsh prompt 中不显示
venv 的名字在 zsh prompt 中不显示 ➜ liyongjiandeMBP.lan [/Users/liyongjian/lyj] python3 -m venv lyj_venv ➜ l ...