Java并发(8)- 读写锁中的性能之王:StampedLock
在上一篇《你真的懂ReentrantReadWriteLock吗?》中我给大家留了一个引子,一个更高效同时可以避免写饥饿的读写锁---StampedLock。StampedLock实现了不仅多个读不互相阻塞,同时在读操作时不会阻塞写操作。
为什么StampedLock这么神奇?能够达到这种效果,它的核心思想在于,在读的时候如果发生了写,应该通过重试的方式来获取新的值,而不应该阻塞写操作。这种模式也就是典型的无锁编程思想,和CAS自旋的思想一样。这种操作方式决定了StampedLock在读线程非常多而写线程非常少的场景下非常适用,同时还避免了写饥饿情况的发生。这篇文章将通过以下几点来分析StampedLock。
- StampedLock的官方使用示例分析
- 源码分析:读写锁共享的状态量
- 源码分析:写锁的释放和获取
- 源码分析:悲观读锁的释放和获取
- 性能测试
StampedLock的官方使用示例分析
先来看一个官方给出的StampedLock使用案例:
public class Point {
private double x, y;
private final StampedLock stampedLock = new StampedLock();
//写锁的使用
void move(double deltaX, double deltaY){
long stamp = stampedLock.writeLock(); //获取写锁
try {
x += deltaX;
y += deltaY;
} finally {
stampedLock.unlockWrite(stamp); //释放写锁
}
}
//乐观读锁的使用
double distanceFromOrigin() {
long stamp = stampedLock.tryOptimisticRead(); //获得一个乐观读锁
double currentX = x;
double currentY = y;
if (!stampedLock.validate(stamp)) { //检查乐观读锁后是否有其他写锁发生,有则返回false
stamp = stampedLock.readLock(); //获取一个悲观读锁
try {
currentX = x;
} finally {
stampedLock.unlockRead(stamp); //释放悲观读锁
}
}
return Math.sqrt(currentX*currentX + currentY*currentY);
}
//悲观读锁以及读锁升级写锁的使用
void moveIfAtOrigin(double newX,double newY) {
long stamp = stampedLock.readLock(); //悲观读锁
try {
while (x == 0.0 && y == 0.0) {
long ws = stampedLock.tryConvertToWriteLock(stamp); //读锁转换为写锁
if (ws != 0L) { //转换成功
stamp = ws; //票据更新
x = newX;
y = newY;
break;
} else {
stampedLock.unlockRead(stamp); //转换失败释放读锁
stamp = stampedLock.writeLock(); //强制获取写锁
}
}
} finally {
stampedLock.unlock(stamp); //释放所有锁
}
}
}
首先看看第一个方法move,可以看到它和ReentrantReadWriteLock写锁的使用基本一样,都是简单的获取释放,可以猜测这里也是一个独占锁的实现。需要注意的是 在获取写锁是会返回个只long类型的stamp,然后在释放写锁时会将stamp传入进去。这个stamp是做什么用的呢?如果我们在中间改变了这个值又会发生什么呢?这里先暂时不做解释,后面分析源码时会解答这个问题。
第二个方法distanceFromOrigin就比较特别了,它调用了tryOptimisticRead,根据名字判断这是一个乐观读锁。首先什么是乐观锁?乐观锁的意思就是先假定在乐观锁获取期间,共享变量不会被改变,既然假定不会被改变,那就不需要上锁。在获取乐观读锁之后进行了一些操作,然后又调用了validate方法,这个方法就是用来验证tryOptimisticRead之后,是否有写操作执行过,如果有,则获取一个读锁,这里的读锁和ReentrantReadWriteLock中的读锁类似,猜测也是个共享锁。
第三个方法moveIfAtOrigin,它做了一个锁升级的操作,通过调用tryConvertToWriteLock尝试将读锁转换为写锁,转换成功后相当于获取了写锁,转换失败相当于有写锁被占用,这时通过调用writeLock来获取写锁进行操作。
看过了上面的三个方法,估计大家对怎么使用StampedLock有了一个初步的印象。下面就通过对StampedLock源码的分析来一步步了解它背后是怎么解决锁饥饿问题的。
源码分析:读写锁共享的状态量
从上面的使用示例中我们看到,在StampedLock中,除了提供了类似ReentrantReadWriteLock读写锁的获取释放方法,还提供了一个乐观读锁的获取方式。那么这三种方式是如何交互的呢?根据AQS的经验,StampedLock中应该也是使用了一个状态量来标志锁的状态。通过下面的源码可以证明这点:
// 用于操作state后获取stamp的值
private static final int LG_READERS = 7;
private static final long RUNIT = 1L; //0000 0000 0001
private static final long WBIT = 1L << LG_READERS; //0000 1000 0000
private static final long RBITS = WBIT - 1L; //0000 0111 1111
private static final long RFULL = RBITS - 1L; //0000 0111 1110
private static final long ABITS = RBITS | WBIT; //0000 1111 1111
private static final long SBITS = ~RBITS; //1111 1000 0000
//初始化时state的值
private static final long ORIGIN = WBIT << 1; //0001 0000 0000
//锁共享变量state
private transient volatile long state;
//读锁溢出时用来存储多出的毒素哦
private transient int readerOverflow;
上面的源码中除了定义state变量外,还提供了一系列变量用来操作state,用来表示读锁和写锁的各种状态。为了方便理解,我将他们都表示成二进制的值,长度有限,这里用低12位来表示64的long,高位自动用0补齐。要理解这些状态的作用,就需要具体分析三种锁操作方式是怎么通过state这一个变量来表示的,首先来看看获取写锁和释放写锁。
源码分析:写锁的释放和获取
public StampedLock() {
state = ORIGIN; //初始化state为 0001 0000 0000
}
public long writeLock() {
long s, next;
return ((((s = state) & ABITS) == 0L && //没有读写锁
U.compareAndSwapLong(this, STATE, s, next = s + WBIT)) ? //cas操作尝试获取写锁
next : acquireWrite(false, 0L)); //获取成功后返回next,失败则进行后续处理,排队也在后续处理中
}
public void unlockWrite(long stamp) {
WNode h;
if (state != stamp || (stamp & WBIT) == 0L) //stamp值被修改,或者写锁已经被释放,抛出错误
throw new IllegalMonitorStateException();
state = (stamp += WBIT) == 0L ? ORIGIN : stamp; //加0000 1000 0000来记录写锁的变化,同时改变写锁状态
if ((h = whead) != null && h.status != 0)
release(h);
}
这里先说明两点结论:读锁通过前7位来表示,每获取一个读锁,则加1。写锁通过除前7位后剩下的位来表示,每获取一次写锁,则加1000 0000,这两点在后面的源码中都可以得倒证明。
初始化时将state变量设置为0001 0000 0000。写锁获取通过((s = state) & ABITS)操作等于0时默认没有读锁和写锁。写锁获取分三种情况:
没有读锁和写锁时,state为0001 0000 0000
0001 0000 0000 & 0000 1111 1111 = 0000 0000 0000 // 等于0L,可以尝试获取写锁有一个读锁时,state为0001 0000 0001
0001 0000 0001 & 0000 1111 1111 = 0000 0000 0001 // 不等于0L有一个写锁,state为0001 1000 0000
0001 1000 0000 & 0000 1111 1111 = 0000 1000 0000 // 不等于0L
获取到写锁,需要将s + WBIT设置到state,也就是说每次获取写锁,都需要加0000 1000 0000。同时返回s + WBIT的值
0001 0000 0000 + 0000 1000 0000 = 0001 1000 0000
释放写锁首先判断stamp的值有没有被修改过或者多次释放,之后通过state = (stamp += WBIT) == 0L ? ORIGIN : stamp来释放写锁,位操作表示如下:
stamp += WBIT
0010 0000 0000 = 0001 1000 0000 + 0000 1000 0000
这一步操作是重点!!!写锁的释放并不是像ReentrantReadWriteLock一样+1然后-1,而是通过再次加0000 1000 0000来使高位每次都产生变化,为什么要这样做?直接减掉0000 1000 0000不就可以了吗?这就是为了后面乐观锁做铺垫,让每次写锁都留下痕迹。
大家可以想象这样一个场景,字母A变化为B能看到变化,如果在一段时间内从A变到B然后又变到A,在内存中自会显示A,而不能记录变化的过程,这也就是CAS中的ABA问题。在StampedLock中就是通过每次对高位加0000 1000 0000来达到记录写锁操作的过程,可以通过下面的步骤理解:
第一次获取写锁:
0001 0000 0000 + 0000 1000 0000 = 0001 1000 0000
第一次释放写锁:
0001 1000 0000 + 0000 1000 0000 = 0010 0000 0000
第二次获取写锁:
0010 0000 0000 + 0000 1000 0000 = 0010 1000 0000
第二次释放写锁:
0010 1000 0000 + 0000 1000 0000 = 0011 0000 0000
第n次获取写锁:
1110 0000 0000 + 0000 1000 0000 = 1110 1000 0000
第n次释放写锁:
1110 1000 0000 + 0000 1000 0000 = 1111 0000 0000
可以看到第8位在获取和释放写锁时会产生变化,也就是说第8位是用来表示写锁状态的,前7位是用来表示读锁状态的,8位之后是用来表示写锁的获取次数的。这样就有效的解决了ABA问题,留下了每次写锁的记录,也为后面乐观锁检查变化提供了基础。
关于acquireWrite方法这里不做具体分析,方法非常复杂,感兴趣的同学可以网上搜索相关资料。这里只对该方法做下简单总结,该方法分两步来进行线程排队,首先通过随机探测的方式多次自旋尝试获取锁,然后自旋一定次数失败后再初始化节点进行插入。
源码分析:悲观读锁的释放和获取
public long readLock() {
long s = state, next;
return ((whead == wtail && (s & ABITS) < RFULL && //队列为空,无写锁,同时读锁未溢出,尝试获取读锁
U.compareAndSwapLong(this, STATE, s, next = s + RUNIT)) ? //cas尝试获取读锁+1
next : acquireRead(false, 0L)); //获取读锁成功,返回s + RUNIT,失败进入后续处理,类似acquireWrite
}
public void unlockRead(long stamp) {
long s, m; WNode h;
for (;;) {
if (((s = state) & SBITS) != (stamp & SBITS) ||
(stamp & ABITS) == 0L || (m = s & ABITS) == 0L || m == WBIT)
throw new IllegalMonitorStateException();
if (m < RFULL) { //小于最大记录值(最大记录值127超过后放在readerOverflow变量中)
if (U.compareAndSwapLong(this, STATE, s, s - RUNIT)) { //cas尝试释放读锁-1
if (m == RUNIT && (h = whead) != null && h.status != 0)
release(h);
break;
}
}
else if (tryDecReaderOverflow(s) != 0L) //readerOverflow - 1
break;
}
}
悲观读锁的获取和ReentrantReadWriteLock类似,不同在于StampedLock的读锁很容易溢出,最大只有127,超过后通过一个额外的变量readerOverflow来存储,这是为了给写锁留下更大的空间,因为写锁是在不停增加的。悲观读锁获取分下面四种情况:
没有读锁和写锁时,state为0001 0000 0000
// 小于 0000 0111 1110,可以尝试获取读锁
0001 0000 0000 & 0000 1111 1111 = 0000 0000 0000有一个读锁时,state为0001 0000 0001
// 小于 0000 0111 1110,可以尝试获取读锁
0001 0000 0001 & 0000 1111 1111 = 0000 0000 0001有一个写锁,state为0001 1000 0000
// 大于 0000 0111 1110,不可以获取读锁
0001 1000 0000 & 0000 1111 1111 = 0000 1000 0000读锁溢出,state为0001 0111 1110
// 等于 0000 0111 1110,不可以获取读锁
0001 0111 1110 & 0000 1111 1111 = 0000 0111 1110
读锁的释放过程在没有溢出的情况下是通过s - RUNIT操作也就是-1来释放的,当溢出后则将readerOverflow变量-1。
乐观读锁的获取和验证
乐观读锁因为实际上没有获取过锁,所以也就没有释放锁的过程,只是在操作后通过验证检查和获取前的变化。源码如下:
//尝试获取乐观锁
public long tryOptimisticRead() {
long s;
return (((s = state) & WBIT) == 0L) ? (s & SBITS) : 0L;
}
//验证乐观锁获取之后是否有过写操作
public boolean validate(long stamp) {
//该方法之前的所有load操作在内存屏障之前完成,对应的还有storeFence()及fullFence()
U.loadFence();
return (stamp & SBITS) == (state & SBITS); //比较是否有过写操作
}
乐观锁基本原理就时获取锁时记录state的写状态,然后在操作完成之后检查写状态是否有变化,因为写状态每次都会在高位留下记录,这样就避免了写锁获取又释放后得不到准确数据。获取写锁记录有三种情况:
没有读锁和写锁时,state为0001 0000 0000
//((s = state) & WBIT) == 0L) true
0001 0000 0000 & 0000 1000 0000 = 0000 0000 0000
//(s & SBITS)
0001 0000 0000 & 1111 1000 0000 = 0001 0000 0000有一个读锁时,state为0001 0000 0001
//((s = state) & WBIT) == 0L) true
0001 0000 0001 & 0000 1000 0000 = 0000 0000 0000
//(s & SBITS)
0001 0000 0001 & 1111 1000 0000 = 0001 0000 0000有一个写锁,state为0001 1000 0000
//((s = state) & WBIT) == 0L) false
0001 1000 0000 & 0000 1000 0000 = 0000 1000 0000
//0L
0000 0000 0000
验证过程中是否有过写操作,分四种情况
写过一次
0001 0000 0000 & 1111 1000 0000 = 0001 0000 0000
0010 0000 0000 & 1111 1000 0000 = 0010 0000 0000 //false未写过,但读过
0001 0000 0000 & 1111 1000 0000 = 0001 0000 0000
0001 0000 1111 & 1111 1000 0000 = 0001 0000 0000 //true正在写
0001 0000 0000 & 1111 1000 0000 = 0001 0000 0000
0001 1000 0000 & 1111 1000 0000 = 0001 1000 0000 //false之前正在写,无论是否写完都不会为0L
0000 0000 0000 & 1111 1000 0000 = 0000 0000 0000 //false
性能测试
分析完了StampedLock的实现原理,这里对StampedLock、ReentrantReadWriteLock以及Synchronized分别在各种场景下进行性能测试,测试的基准代码采用https://blog.takipi.com/java-8-stampedlocks-vs-readwritelocks-and-synchronized/ 文章中的代码,首先贴出上述博客中的测试结果,文章中的OPTIMISTIC模式由于采用了“脏读”模式,这里不采用OPTIMISTIC的测试结果,只比较StampedLock、ReentrantReadWriteLock以及Synchronized。
5个读线程和5个写线程场景:表现最好的是StampedLock的正常模式以及ReentrantReadWriteLock。
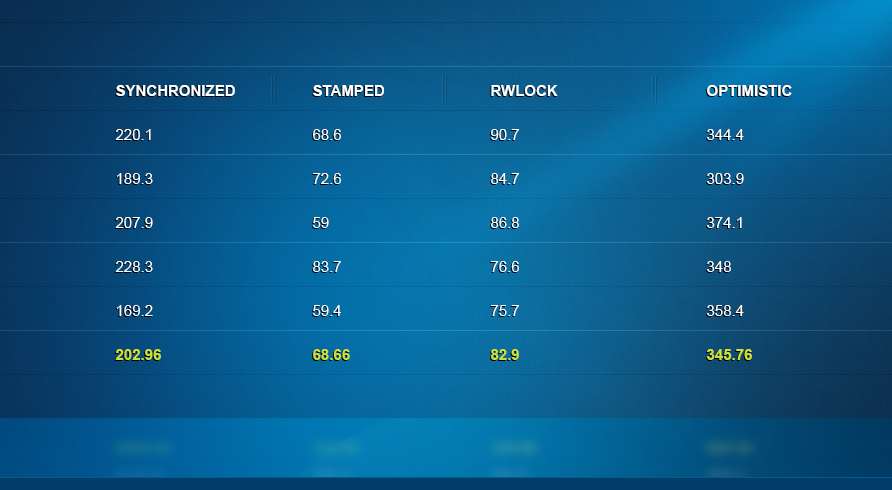
10个读线程和10个写线程场景:表现最好的是StampedLock的正常模式以及Synchronized。

16个读线程和4个写线程场景:表现最好的是StampedLock的正常模式以及Synchronized。
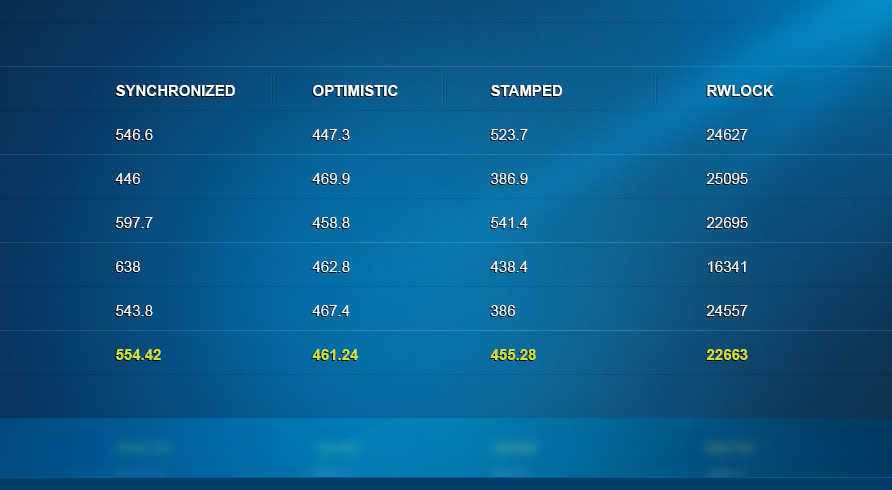
19个读线程和1个写线程场景:表现最好的是Synchronized。
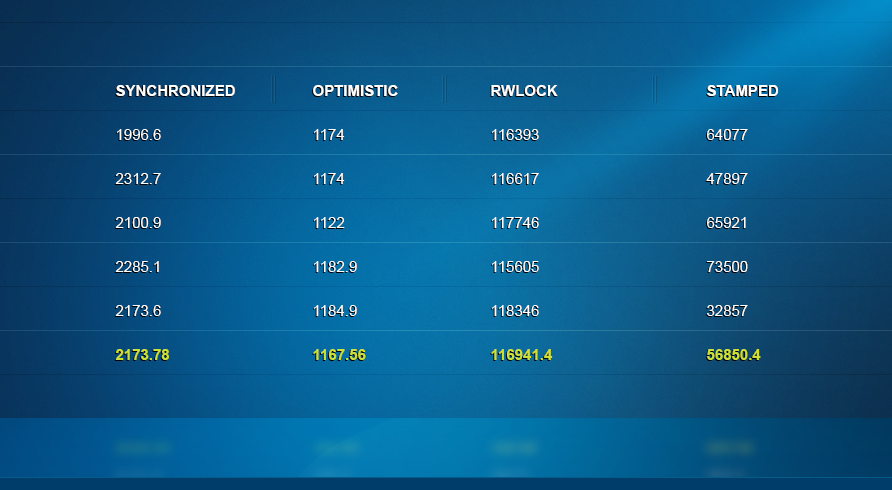
博客评论中还有一种测试场景2000读线程和1个写线程,测试结果如下:
StampedLock ... 12814.2 ReentrantReadWriteLock ... 18882.8 Synchronized ... 22696.4
表现最好的是StampedLock。
看完了上面的测试,前面3种场景表现最好的都为StampedLock,但第4种情况下StampedLock表现很差,于是我自己对代码又进行了一遍测试,同时鉴于读写锁的大量应用在缓存场景下,读写差距极大,我增加了100个读和1个写的场景。
测试机器:MAC OS(10.12.6),CPU : 2.4 GHz Intel Core i5,内存:8G 软件版本:JDK1.8
测试结果如下:
19个读线程和1个写线程场景:表现最好的是StampedLock以及Synchronized。
读线程: 19. 写线程: 1. 循环次数: 5. 计算总和: 1000000
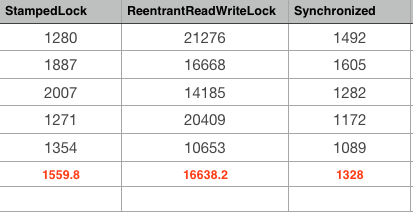
100个读线程和1个写线程场景:表现最好的是StampedLock以及Synchronized。
读线程: 100. 写线程: 1. 循环次数: 5. 计算总和: 100000
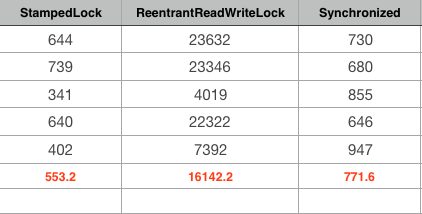
通过上述测试,可以发现整体性能平均而言StampedLock和Synchronized相差不大,StampedLock在读写差距加大时稍微有点优势。而ReentrantReadWriteLock性能之差有点出乎意料,基本可以达到抛弃使用的地步了,不知道大家对ReentrantReadWriteLock的使用场景有什么建议?
同时鉴于原生的Synchronized后期可优化空间比较大,而且在代码复杂性以及安全性上面都具有一定优势,因此在绝大多数场景可以使用Synchronized来进行同步,对性能有一定要求的在某些特定场景下可以使用StampedLock。测试所用代码在我所引用的博客中都可以找到,大家可以自行尝试测试,如果对结果有什么疑问,欢迎在评论中提出。
参考资料:
https://blog.takipi.com/java-8-stampedlocks-vs-readwritelocks-and-synchronized/
Java并发(8)- 读写锁中的性能之王:StampedLock的更多相关文章
- java并发编程-读写锁
最近项目中需要用到读写锁 读写锁适用于读操作多,写操作少的场景,假设你的程序中涉及到对一些共享资源的读和写操作,且写操作没有读操作那么频繁.在没有写操作的时候,两个线程同时读一个资源没有任何问题,所以 ...
- java并发:读写锁ReadWriteLock
在没有写操作的时候,两个线程同时读一个资源没有任何问题,允许多个线程同时读取共享资源. 但是如果有一个线程想去写这些共享资源,就不应该再有其它线程对该资源进行读或写. 简单来说,多个线程同时操作同一资 ...
- JAVA 并发编程-读写锁之模拟缓存系统(十一)
在多线程中,为了提高效率有些共享资源同意同一时候进行多个读的操作,但仅仅同意一个写的操作,比方一个文件,仅仅要其内容不变能够让多个线程同一时候读,不必做排他的锁定,排他的锁定仅仅有在写的时候须要,以保 ...
- Java并发编程(3) JUC中的锁
一 前言 前面已经说到JUC中的锁主要是基于AQS实现,而AQS(AQS的内部结构 .AQS的设计与实现)在前面已经简单介绍过了.今天记录下JUC包下的锁是怎么基于AQS上实现的 二 同步锁 同步锁不 ...
- Java并发编程实战 第11章 性能与可伸缩性
关于性能 性能的衡量标准有很多,如: 服务时间,等待时间用来衡量程序的"运行速度""多快". 吞吐量,生产量用于衡量程序的"处理能力",能够 ...
- 整理一下《java并发编程实战》中的知识点
分工.同步.互斥的历史由来 分工:单道.多道.分时 同步:线程通信(组织编排任务) 互斥:因(多线程访问共享资源)果(串行化共享资源的访问) 1切都是为了提高性能 2.可见性.原子性.有序性 可见性: ...
- java并发之读写锁ReentrantReadWriteLock的使用
Lock比传统线程模型中的synchronized方式更加面向对象,与生活中的锁类似,锁本身也应该是一个对象.两个线程执行的代码片段要实现同步互斥的效果,它们必须用同一个Lock对象. 读写锁:分为读 ...
- java多线程 -- ReadWriteLock 读写锁
写一条线程,读多条线程能够提升效率. 写写/读写 需要“互斥”;读读 不需要互斥. ReadWriteLock 维护了一对相关的锁,一个用于只读操作,另一个用于写入操作.只要没有 writer,读取锁 ...
- java 多线程 day12 读写锁
import java.util.Random;import java.util.concurrent.locks.ReadWriteLock;import java.util.concurrent. ...
随机推荐
- [bzoj5158][Tjoi2014]Alice and Bob
好羞愧啊最近一直在刷水... 题意:给定序列$c$的$a_i$,构造出一个序列$c$使得$\sum b_i$最大. 其中$a_i$表示以$c_i$结尾的最长上升子序列长度,$b_i$表示以$c_i$为 ...
- 【Consul】Consul架构-Consensus协议
Consul使用Consensus协议提供一致性(Consistency)--CAP定义的一致性.Consensus协议是基于"Raft:In search of an Understand ...
- 常用操作提高效率 之 for 与in
问题如何而来: 对于刚参加工作的我 批量删除数据通常采用的是前端传递到后台一个对象的id字符串 通过逗号分隔的多个id 或者收的直接是一个id数组 两个原理一样第一个后台要在次使用split(& ...
- guacamole实现剪切复制
主要功能是实现把堡垒机的内容复制到浏览器端,把浏览器端的文本复制到堡垒机上. 借助一个中间的文本框,现将堡垒机内容复制到一个文本框,然后把文本框内容复制出来.或者将需要传递到堡垒机的内容先复制到文本框 ...
- Unity和Lua交互
用lua就表示项目用到了热更新,通常每次热更新都会从服务器获取最新的lua脚本放到Android/ios设备的本地目录下,但是lua应该放到哪个目录下呢,这里就先说说lua里面的路径问题 1.不可以放 ...
- storm_jdbc 最完整的版本
开头:我这里是根据bolt与trident进行分类的,写入和读取的方法可能会在同一个类中,最后会展示一个测试的类来说明怎么用. JdbcSpout:这个类是我写入数据和读取数据的公用spout,细节注 ...
- 1098 Insertion or Heap Sort (25 分)(堆)
这里的第二序列相当于是排序还没拍好的序列 对于第二个样例的第二个序列其实已经是大顶堆了 然后才进行的堆排序 知道这个就好做了 #include<bits/stdc++.h> using n ...
- Python之tornado框架原理
Python web框架 1.简单概念 tornado socket.逻辑处理 Django flask 逻辑处理 第三方处理模块(包含了socket) jinja2模块 Models 数据库处理 V ...
- 初学者学习python2还是python3?
如果你是一个初学者,或者你以前接触过其他的编程语言,你可能不知道,在开始学习python的时候都会遇到一个比较让人很头疼的问题:版本问题!!是学习python2 还是学习 python3 ?这是非常让 ...
- Dispose的调用顺序
非托管资源的释放顺序. 这是应该先释放 reader 再释放 stream. 或者直接使用using,防止出错 .