【mongoDB运维篇④】Shard 分片集群
简述
为何要分片
- 减少单机请求数,降低单机负载,提高总负载
- 减少单机的存储空间,提高总存空间。
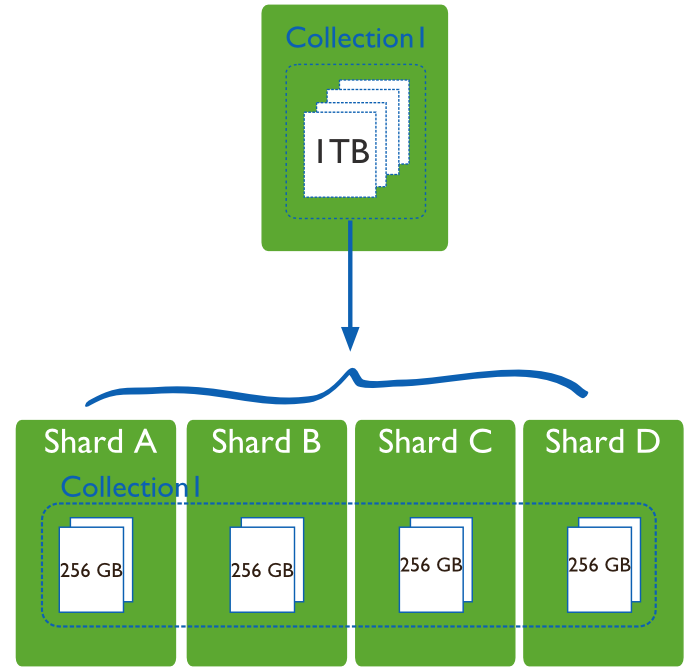
常见的mongodb sharding 服务器架构
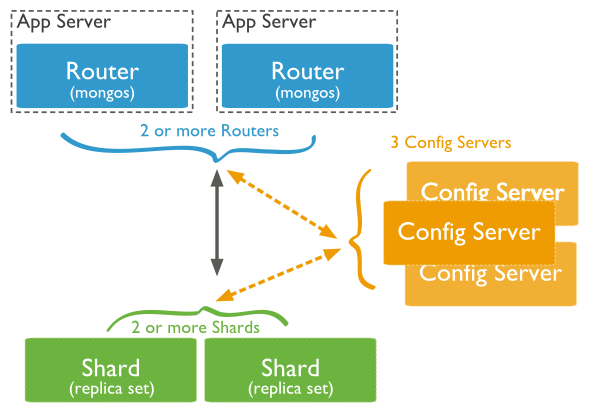
要构建一个 MongoDB Sharding Cluster,需要三种角色:
Shard Server
即存储实际数据的分片,每个Shard可以是一个mongod实例,也可以是一组mongod实例构成的Replication Set。为了实现每个Shard内部的auto-failover(自动故障切换),MongoDB官方建议每个Shard为一组Replica Set。
Config Server
为了将一个特定的collection存储在多个shard中,需要为该collection指定一个shard key(片键),例如{age: 1} ,shard key可以决定该条记录属于哪个chunk(分片是以chunk为单位,后续会介绍)。Config Servers就是用来存储:所有shard节点的配置信息、每个chunk的shard key范围、chunk在各shard的分布情况、该集群中所有DB和collection的sharding配置信息。
Route Process
这是一个前端路由,客户端由此接入,然后询问Config Servers需要到哪个Shard上查询或保存记录,再连接相应的Shard进行操作,最后将结果返回给客户端。客户端只需要将原本发给mongod的查询或更新请求原封不动地发给Routing Process,而不必关心所操作的记录存储在哪个Shard上。(所有操作在mongos上操作即可)
配置分片服务器
下面我们在同一台物理机器上构建一个简单的 Sharding Cluster:

Shard Server 1:27017
Shard Server 2:27018
Config Server :27027
Route Process:40000
步骤一: 启动Shard Server
mkdir -p ./data/shard/s0 ./data/shard/s1 #创建数据目录
mkdir -p ./data/shard/log # 创建日志目录
./bin/mongod --port 27017 --dbpath /usr/local/mongodb/data/shard/s0 --fork --logpath /usr/local/mongodb/data/shard/log/s0.log # 启动Shard Server实例1
./bin/mongod --port 27018 --dbpath /usr/local/mongodb/data/shard/s1 --fork --logpath /usr/local/mongodb/data/shard/log/s1.log # 启动Shard Server实例2
步骤二: 启动Config Server
mkdir -p ./data/shard/config #创建数据目录
./bin/mongod --port 27027 --dbpath /usr/local/mongodb/data/shard/config --fork --logpath /usr/local/mongodb/data/shard/log/config.log #启动Config Server实例
注意,这里我们完全可以像启动普通mongodb服务一样启动,不需要添加—shardsvr和configsvr参数。因为这两个参数的作用就是改变启动端口的,所以我们自行指定了端口就可以
步骤三: 启动Route Process
./bin/mongos --port 4000 --configdb localhost:27027 --fork --logpath /usr/local/mongodb/data/shard/log/route.log --chunkSize=1 # 启动Route Server实例
mongos启动参数中,chunkSize这一项是用来指定chunk的大小的,单位是MB,默认大小为200MB,为了方便测试Sharding效果,我们把chunkSize指定为 1MB。意思是当这个分片中插入的数据大于1M时开始进行数据转移
步骤四: 配置Sharding
# 我们使用MongoDB Shell登录到mongos,添加Shard节点
./bin/mongo admin --port 40000 #此操作需要连接admin库
> db.runCommand({ addshard:"localhost:27017" }) #添加 Shard Server 或者用 sh.addshard()命令来添加,下同;
{ "shardAdded" : "shard0000", "ok" : 1 }
> db.runCommand({ addshard:"localhost:27018" })
{ "shardAdded" : "shard0001", "ok" : 1 }
> db.runCommand({ enablesharding:"test" }) #设置分片存储的数据库
{ "ok" : 1 }
> db.runCommand({ shardcollection: "test.users", key: { id:1 }}) # 设置分片的集合名称。且必须指定Shard Key,系统会自动创建索引,然后根据这个shard Key来计算
{ "collectionsharded" : "test.users", "ok" : 1 }
> sh.status(); #查看片的状态
> printShardingStatus(db.getSisterDB("config"),1); # 查看片状态(完整版);
> db.stats(); # 查看所有的分片服务器状态
注意这里我们要注意片键的选择,选择片键时需要根据具体业务的数据形态来选择,切不可随意选择,实际中尤其不要轻易选择自增_id作为片键,除非你很清楚你这么做的目的,具体原因我不在此分析,根据经验推荐一种较合理的片键方式,“自增字段+查询字段”,没错,片键可以是多个字段的组合。
另外这里说明一点,分片的机制:mongodb不是从单篇文档的级别,绝对平均的散落在各个片上, 而是N篇文档,形成一个块"chunk",优先放在某个片上, 当这片上的chunk,比另一个片的chunk区别比较大时(>=3) ,会把本片上的chunk,移到另一个片上, 以chunk为单位,维护片之间的数据均衡。
也就是说,一开始插入数据时,数据是只插入到其中一块分片上的,插入完毕后,mongodb内部开始在各片之间进行数据的移动,这个过程可能不是立即的,mongodb足够智能会根据当前负载决定是立即进行移动还是稍后移动。
在插入数据后,立马执行db.users.stats();两次可以验证如上所说。
这种分片机制,节省了人工维护成本,但是由于其是优先往某个片上插入,等到chunk失衡时,再移动chunk,并且随着数据的增多,shard的实例之间,有chunk来回移动的现象,这将会为服务器带来很大的IO开销,解决这种开销的方法,就是手动预先分片;
手动预先分片
以shop.user表为例
sh.shardCollection(‘shop.user’,{userid:1}); # user表用userid做shard key
for(var i=1;i<=40;i++) { sh.splitAt('shop.user',{userid:i*1000}) } # 预先在1K 2K...40K这样的界限切好chunk(虽然chunk是空的), 这些chunk将会均匀移动到各片上.
通过mongos添加user数据. 数据会添加到预先分配好的chunk上, chunk就不会来回移动了.
repliction set and shard
一般mongoDB如果真的到了分片的级别后,那片服务器避无可免的要用到复制集,部署的基本思路同上,只需要注意两点:
sh.addShard( host ) server:port OR setname/server:port # 如果是复制集的片服务器,我们应该复制集的名称写在前面比如
sh.addShard('ras/192.168.42.168:27017'); # 27017也就是复制集中的primary
另外在启动本机的mongod服务的时候,最好把ip也给写进去,否则有可能会有不可预知的错误;
【mongoDB运维篇④】Shard 分片集群的更多相关文章
- MongoDB DBA 实践6-----MongoDB的分片集群部署
一.分片 MongoDB使用分片技术来支持大数据集和高吞吐量操作. 1.分片目的 对于单台数据库服务器,庞大的数据量及高吞吐量的应用程序对它而言无疑是个巨大的挑战.频繁的CRUD操作能够耗尽服务器的C ...
- MongoDB DBA 实践7-----MongoDB的分片集群操
一.使用Ranged Sharding对集合进行分片 从mongo连接到的shell中mongos,使用该sh.shardCollection()方法对集合进行分片. 注意: 必须已为集合所在的数据库 ...
- mongodb模拟生产环境的分片集群
分片是指数据拆分 将其分散在不同的机器上的过程,有时候也叫分区来表示这个概念.将数据分散到不同机器上 不需要功能强大的计算机就可以储存更多的数据,处理更大的负载. 几乎所有的数据库 ...
- 【mongoDB运维篇①】用户管理
3.0版本以前 在mongodb3.0版本以前中,有一个admin数据库, 牵涉到服务器配置层面的操作,需要先切换到admin数据库.即 use admin , 相当于进入超级用户管理模式,mongo ...
- Elasticsearch 运维实战之1 -- 集群规划
规划一个可用于生产环境的elasticsearch集群. 集群节点划分 整个集群的节点分为以下三种主要类型 Master nodes -- 负责维护集群状态,不保存index数据, 硬件要求: 一般性 ...
- 【mongoDB运维篇③】replication set复制集
介绍 replicattion set 多台服务器维护相同的数据副本,提高服务器的可用性,总结下来有以下好处: 数据备份与恢复 读写分离 MongoDB 复制集的结构以及基本概念 正如上图所示,Mon ...
- 【mongoDB运维篇②】备份与恢复(导入与导出)
导入/导出可以操作的是本地的mongodb服务器,也可以是远程的服务器 所以,都有如下通用选项: -h host 主机 --port port 端口 -u username 用户名 -p passwd ...
- 网易云MongoDB分片集群(Sharding)服务已上线
此文已由作者温正湖授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. MongoDB sharding cluster(分片集群)是MongoDB提供的数据在线水平扩展方案,包括 ...
- MongoDB 分片集群实战
背景 在如今的互联网环境下,海量数据已随处可见并且还在不断增长,对于如何存储处理海量数据,比较常见的方法有两种: 垂直扩展:通过增加单台服务器的配置,例如使用更强悍的 CPU.更大的内存.更大容量的磁 ...
随机推荐
- win10任务视图
之所以用到win10任务视图源自于一个需求,就是我想在上班操作电脑的同时想将某个游戏在后台挂机,这样工作归工作,挂机归挂机,互不干扰.win10任务视图就能轻松的解决这个问题. 任务视图 新建任务视图 ...
- Global::time2StrHHMM_DNT
/*************************************************** Created Date: 13 Jul 2013 Created By: Jimmy Xie ...
- Jquery插件收集
移动端滚动条插件iScroll.js http://www.cnblogs.com/starof/p/5215845.html http://www.codeceo.com/article/35-jq ...
- Linux性能监控top及vmstat命令
监控的工具---top 第一行: 03:07:27 当前系统时间 3 days, 18:58 系统已经运行了3天18小时58分钟(在这期间没有重启过) 4 users load average: 0. ...
- 开发流程习惯的养成—TFS简单使用
才开始用,所以是个很基础的介绍,欢迎大家一起交流学习 一.追本溯源 讲到开发流程,还要从敏捷开始,因为敏捷才有了开发流程的重视,整个流程也是按照敏捷的思想进行的,这里不再叙述敏捷的定义 敏捷的流程(个 ...
- JDBC ----常用数据库的驱动程序及JDBC URL:
常用数据库的驱动程序及JDBC URL: Oracle数据库: 驱动程序包名:ojdbc14.jar 驱动类的名字:oracle.jdbc.driver.OracleDriver JDBC URL ...
- Activity的Launch mode详解 singleTask正解
Activity有四种加载模式:standard(默认), singleTop, singleTask和 singleInstance.以下逐一举例说明他们的区别: standard:Activity ...
- spring-mysqlclient开源了
https://github.com/risedragon/spring-mysqlclient/wiki/spring-mysqlclient-user-guide 开源了一个项目,总结了几年的数据 ...
- 【js】js 让图片旋转
转http://www.cnblogs.com/ustcyc/p/3760116.html 核心: canvas.style.filter = "progid:DXImageTransfo ...
- python SendMail 发送邮件
最近在学习python 时,用到了发送邮件的操作,通过整理总结如下: 1.普通文本邮件 普通文本邮件发送的实现,关键是要将MIMEText中_subtype设置为plain,首先导入smtplib和m ...