数据降维-PCA主成分分析
1.什么是PCA?
PCA(Principal Component Analysis),即主成分分析方法,是一种使用最广泛的数据降维算法。PCA的主要思想是将n维特征映射到k维上,这k维是全新的正交特征也被称为主成分,是在原有n维特征的基础上重新构造出来的k维特征。PCA的工作就是从原始的空间中顺序地找一组相互正交的坐标轴,新的坐标轴的选择与数据本身是密切相关的。其中,第一个新坐标轴选择是原始数据中方差最大的方向,第二个新坐标轴选取是与第一个坐标轴正交的平面中使得方差最大的,第三个轴是与第1,2个轴正交的平面中方差最大的。依次类推,可以得到n个这样的坐标轴。通过这种方式获得的新的坐标轴,我们发现,大部分方差都包含在前面k个坐标轴中,后面的坐标轴所含的方差几乎为0。于是,我们可以忽略余下的坐标轴,只保留前面k个含有绝大部分方差的坐标轴。事实上,这相当于只保留包含绝大部分方差的维度特征,而忽略包含方差几乎为0的特征维度,实现对数据特征的降维处理。
数学原理:
目标函数:投影的维度上数据的方差最大
我们如何得到这些包含最大差异性的主成分方向呢?
事实上,通过计算数据矩阵的协方差矩阵,然后得到协方差矩阵的特征值特征向量,选择特征值最大(即方差最大)的k个特征所对应的特征向量组成的矩阵。这样就可以将数据矩阵转换到新的空间当中,实现数据特征的降维。
2.鸢尾花例子
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline # decomposition降解
# 化学变化降解之后得到的数据和原来的数据不一样,成分变了,属性变了
# PCA将原来的属性变少,少量的数据可以代表原来比较多的数据
from sklearn.decomposition import PCA
from sklearn.linear_model import LogisticRegression
from sklearn import datasets
from sklearn.model_selection import train_test_split X,y=datasets.load_iris(True)
# n_components 保留多少特征,取权重靠前的 whiten 标准化
# 标准化:输出范围是负无穷到正无穷
# 归一化:输出范围在0-1之间
pca=PCA(n_components=0.95,whiten=False)
X_pca=pca.fit_transform(X)
X_pca[:10]
3.PCA的原理(可以去查看源码)
# 1.去中心化,取平均值的意思
B=X-X.mean(axis=0) # 2.计算协方差 协方差矩阵 bias表示偏差
V=np.cov(B,rowvar=False,bias=True) # 3.计算协方差矩阵的特征值和特征向量 矩阵的概念
# eig表示从大到小
eigen,ev=np.linalg.eig(V)
# 若挑选出百分之95的,找出权重在前95%,若不够,则加一,可多不可少
cond=(eigen/eigen.sum()).cumsum()>=0.95
index=cond.argmax()
vector=ev[:,:index+1] # 4.降维标准,2个特征,选取两个最大的特征值所对应的的特征的特征向量
# 百分比,计算各特征值所占的权重,累加
vector=ev[:,:2] # 5.进行矩阵运算
pca_result=B.dot(vector)
pca_result[:10]

预测出来的结果:
特征值分解:
(1) 特征值与特征向量
如果一个向量v是矩阵A的特征向量,将一定可以表示成下面的形式:
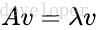
(2) 特征值分解矩阵
对于矩阵A,有一组特征向量v,将这组向量进行正交化单位化,就能得到一组正交单位向量。特征值分解,就是将矩阵A分解为如下式:

其中,Q是矩阵A的特征向量组成的矩阵,则是一个对角阵,对角线上的元素就是特征值。
这个其实就是根据 实对称矩阵不同特征值的特征向量正交这句话推导得来的,
这两个结论我推导了一下,请参考:
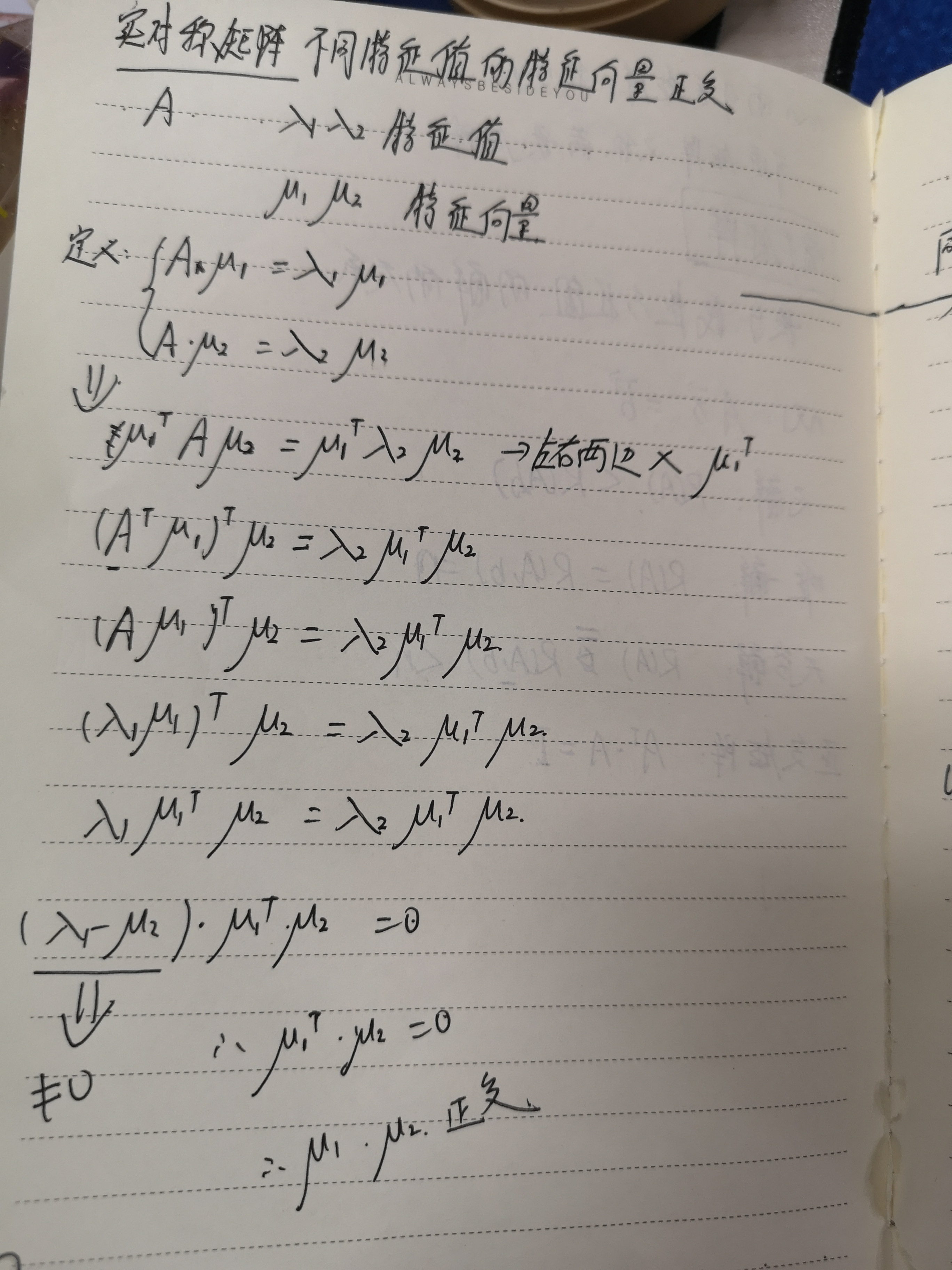
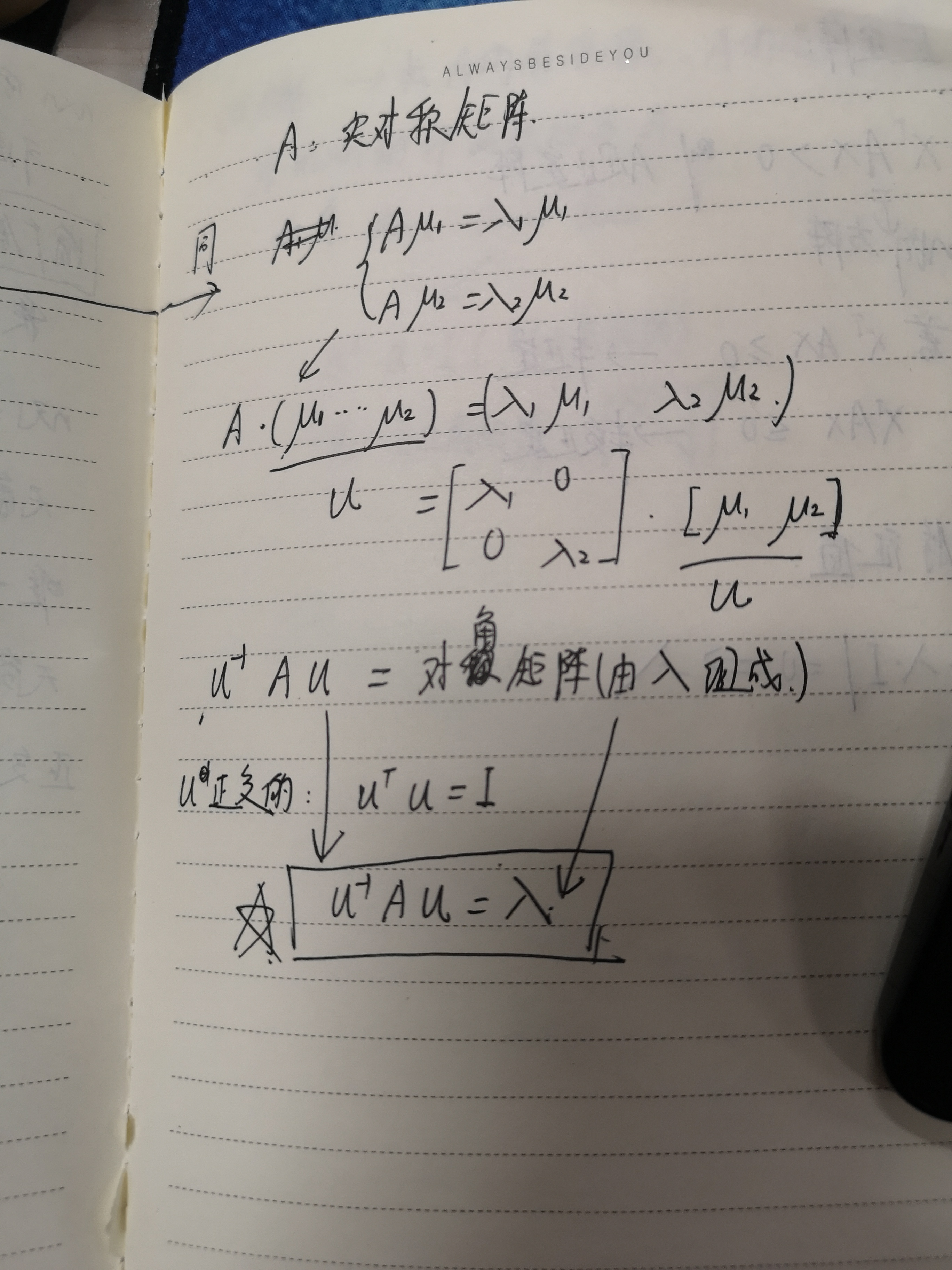
再举个例子:
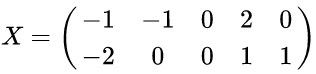
以X为例,我们用PCA方法将这两行数据降到一行。
1)因为X矩阵的每行已经是零均值,所以不需要去平均值。
2)求协方差矩阵:
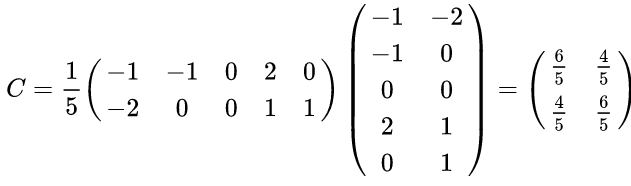
3)求协方差矩阵的特征值与特征向量。
求解后的特征值为:
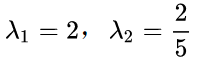
对应的特征向量

其中对应的特征向量分别是一个通解,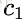
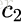
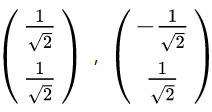
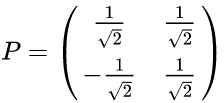
最后我们用P的第一行乘以数据矩阵X,就得到了降维后的表示:
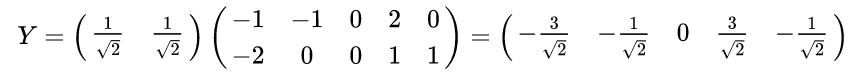
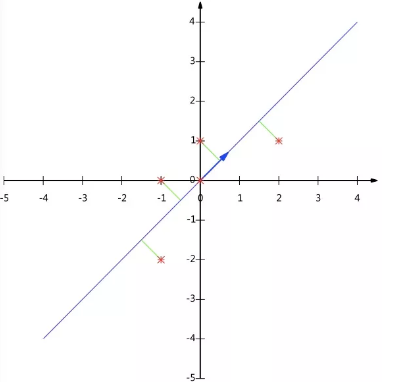
数据矩阵X降维投影结果:
数据降维-PCA主成分分析的更多相关文章
- 11_数据降维PCA
1.sklearn降维API:sklearn. decomposition 2.PCA是什么:主成分分析 本质:PCA是一种分析.简化数据集的技术. 目的:是数据维数压缩,尽可能降低原数据的维数(复杂 ...
- 数据降维PCA——学习笔记
PCA主成分分析 无监督学习 使方差(数据离散量)最大,更易于分类. 可以对隐私数据PCA,数据加密. 基变换 投影->内积 基变换 正交的基,两个向量垂直(内积为0,线性无关) 先将基化成各维 ...
- SIGAI机器学习第八集 数据降维1
讲授数据降维原理,PCA的核心思想,计算投影矩阵,投影算法的完整流程,非线性降维技术,流行学习的概念,局部线性嵌入,拉普拉斯特征映射,局部保持投影,等距映射,实际应用 大纲: 数据降维问题PCA的思想 ...
- 主成分分析PCA数据降维原理及python应用(葡萄酒案例分析)
目录 主成分分析(PCA)——以葡萄酒数据集分类为例 1.认识PCA (1)简介 (2)方法步骤 2.提取主成分 3.主成分方差可视化 4.特征变换 5.数据分类结果 6.完整代码 总结: 1.认识P ...
- [机器学习之13]降维技术——主成分分析PCA
始终贯彻数据分析的一个大问题就是对数据和结果的展示,我们都知道在低维度下数据处理比较方便,因而数据进行简化成为了一个重要的技术.对数据进行简化的原因: 1.使得数据集更易用使用.2.降低很多算法的计算 ...
- [机器学习]-PCA数据降维:从代码到原理的深入解析
&*&:2017/6/16update,最近几天发现阅读这篇文章的朋友比较多,自己阅读发现,部分内容出现了问题,进行了更新. 一.什么是PCA:摘用一下百度百科的解释 PCA(Prin ...
- 降维之主成分分析法(PCA)
一.主成分分析法的思想 我们在研究某些问题时,需要处理带有很多变量的数据,比如研究房价的影响因素,需要考虑的变量有物价水平.土地价格.利率.就业率.城市化率等.变量和数据很多,但是可能存在噪音和冗余, ...
- 降维算法-PCA主成分分析
1.PCA算法介绍主成分分析(Principal Components Analysis),简称PCA,是一种数据降维技术,用于数据预处理.一般我们获取的原始数据维度都很高,比如1000个特征,在这1 ...
- 降维PCA技术
降维技术使得数据变得更易使用,并且它们往往能够去除数据中的噪声,使得机器学习任务往往更加精确. 降维往往作为预处理步骤,在数据应用到其它算法之前清洗数据.有很多技术可以用于数据降维,在这些技术中,独立 ...
随机推荐
- 实战SpringCloud响应式微服务系列教程(第九章)使用Spring WebFlux构建响应式RESTful服务
本文为实战SpringCloud响应式微服务系列教程第九章,讲解使用Spring WebFlux构建响应式RESTful服务.建议没有之前基础的童鞋,先看之前的章节,章节目录放在文末. 从本节开始我们 ...
- 第二篇 Flask的Response三剑客及两个小儿子
一.Response三剑客 (一)Flask中的HTTPResponse @app.route("/") #app中的route装饰器 def index(): #视图函数 ret ...
- vue-socket.io 及 egg-socket.io 的简单使用
egg-socket.io 的使用 官方文档看这里 egg-socket.io 接下来的内容其实与文档里差不多,介意的童鞋略过就好,目前只是简单的引入,下周往后会写复杂些的逻辑,在后面的文章会介绍. ...
- git 陷阱小记
1.文件添加陷阱: 1).git 提交命令快捷键: git commit -a -m "",能够跳过git添加文件到暂存目录步骤 2)git add . git commit -m ...
- 学习笔记24_MVC前后台数据交互
*最普通的交互方式,在Contoller中的Action方法内 public ActionResult Index() { ViewData["Key"] =Value; Retu ...
- m98 lsc rp-- 赛
lsc 这次又烧rp了! T1随机化艹spj 本机测试输出字符串长度没有低于1W的,考完发现凉凉 但是lemon又救了我的*命,垃圾lsc又烧rp了!
- 使用.net core中的类DispatchProxy实现AOP
在软件业,AOP为Aspect Oriented Programming的缩写,意为:面向切面编程,通过预编译方式和运行期动态代理实现程序功能的统一维护的一种技术.AOP是软件开发中的一个热点,利用A ...
- 更新linux时候提示“由于没有公钥,无法验证下列签名".
本文链接:https://blog.csdn.net/loovejava/article/details/21837935 新安装的Ubuntu在使用sudo apt-get update更新源码的时 ...
- JavaScript部分案例
JavaScript 是 Web 的编程语言. 所有现代的 HTML 页面都使用 JavaScript. JavaScript 非常容易学. 阅读本教程,您需要有以下基础: HTML 教程 CSS 教 ...
- 一种logging封装方法,不会产生重复log
在调试logging的封装的时候,发现已经调用了logging封装的函数,在被其它函数再调用时,会出现重复的logging.原因是不同的地方创建了不同的handler,所以会重复,可以使用暴力方法解决 ...