数据降维-PCA主成分分析
1.什么是PCA?
PCA(Principal Component Analysis),即主成分分析方法,是一种使用最广泛的数据降维算法。PCA的主要思想是将n维特征映射到k维上,这k维是全新的正交特征也被称为主成分,是在原有n维特征的基础上重新构造出来的k维特征。PCA的工作就是从原始的空间中顺序地找一组相互正交的坐标轴,新的坐标轴的选择与数据本身是密切相关的。其中,第一个新坐标轴选择是原始数据中方差最大的方向,第二个新坐标轴选取是与第一个坐标轴正交的平面中使得方差最大的,第三个轴是与第1,2个轴正交的平面中方差最大的。依次类推,可以得到n个这样的坐标轴。通过这种方式获得的新的坐标轴,我们发现,大部分方差都包含在前面k个坐标轴中,后面的坐标轴所含的方差几乎为0。于是,我们可以忽略余下的坐标轴,只保留前面k个含有绝大部分方差的坐标轴。事实上,这相当于只保留包含绝大部分方差的维度特征,而忽略包含方差几乎为0的特征维度,实现对数据特征的降维处理。
数学原理:
目标函数:投影的维度上数据的方差最大
我们如何得到这些包含最大差异性的主成分方向呢?
事实上,通过计算数据矩阵的协方差矩阵,然后得到协方差矩阵的特征值特征向量,选择特征值最大(即方差最大)的k个特征所对应的特征向量组成的矩阵。这样就可以将数据矩阵转换到新的空间当中,实现数据特征的降维。
2.鸢尾花例子
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline # decomposition降解
# 化学变化降解之后得到的数据和原来的数据不一样,成分变了,属性变了
# PCA将原来的属性变少,少量的数据可以代表原来比较多的数据
from sklearn.decomposition import PCA
from sklearn.linear_model import LogisticRegression
from sklearn import datasets
from sklearn.model_selection import train_test_split X,y=datasets.load_iris(True)
# n_components 保留多少特征,取权重靠前的 whiten 标准化
# 标准化:输出范围是负无穷到正无穷
# 归一化:输出范围在0-1之间
pca=PCA(n_components=0.95,whiten=False)
X_pca=pca.fit_transform(X)
X_pca[:10]
3.PCA的原理(可以去查看源码)
# 1.去中心化,取平均值的意思
B=X-X.mean(axis=0) # 2.计算协方差 协方差矩阵 bias表示偏差
V=np.cov(B,rowvar=False,bias=True) # 3.计算协方差矩阵的特征值和特征向量 矩阵的概念
# eig表示从大到小
eigen,ev=np.linalg.eig(V)
# 若挑选出百分之95的,找出权重在前95%,若不够,则加一,可多不可少
cond=(eigen/eigen.sum()).cumsum()>=0.95
index=cond.argmax()
vector=ev[:,:index+1] # 4.降维标准,2个特征,选取两个最大的特征值所对应的的特征的特征向量
# 百分比,计算各特征值所占的权重,累加
vector=ev[:,:2] # 5.进行矩阵运算
pca_result=B.dot(vector)
pca_result[:10]

预测出来的结果:
特征值分解:
(1) 特征值与特征向量
如果一个向量v是矩阵A的特征向量,将一定可以表示成下面的形式:
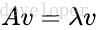
(2) 特征值分解矩阵
对于矩阵A,有一组特征向量v,将这组向量进行正交化单位化,就能得到一组正交单位向量。特征值分解,就是将矩阵A分解为如下式:

其中,Q是矩阵A的特征向量组成的矩阵,则是一个对角阵,对角线上的元素就是特征值。
这个其实就是根据 实对称矩阵不同特征值的特征向量正交这句话推导得来的,
这两个结论我推导了一下,请参考:
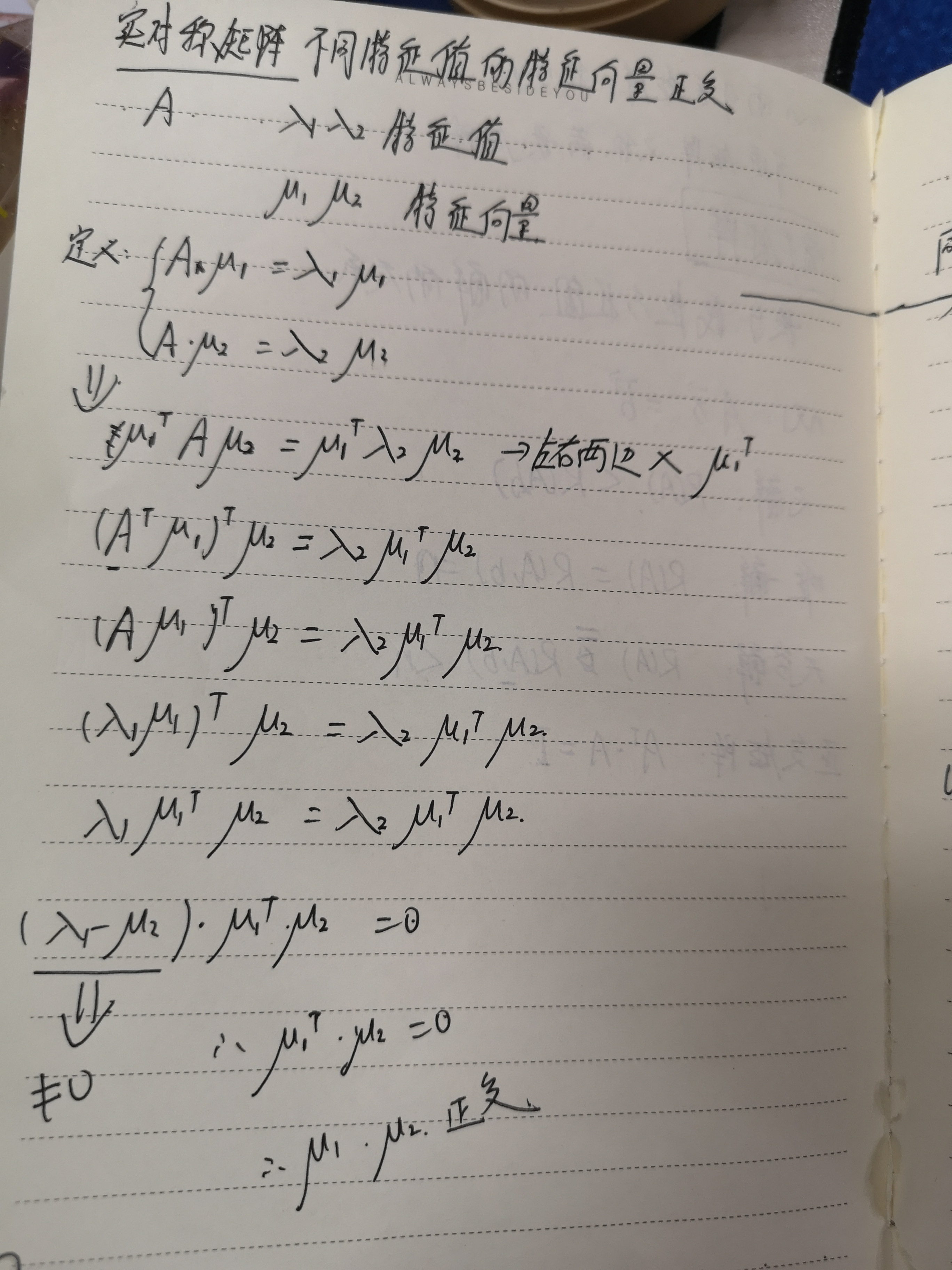
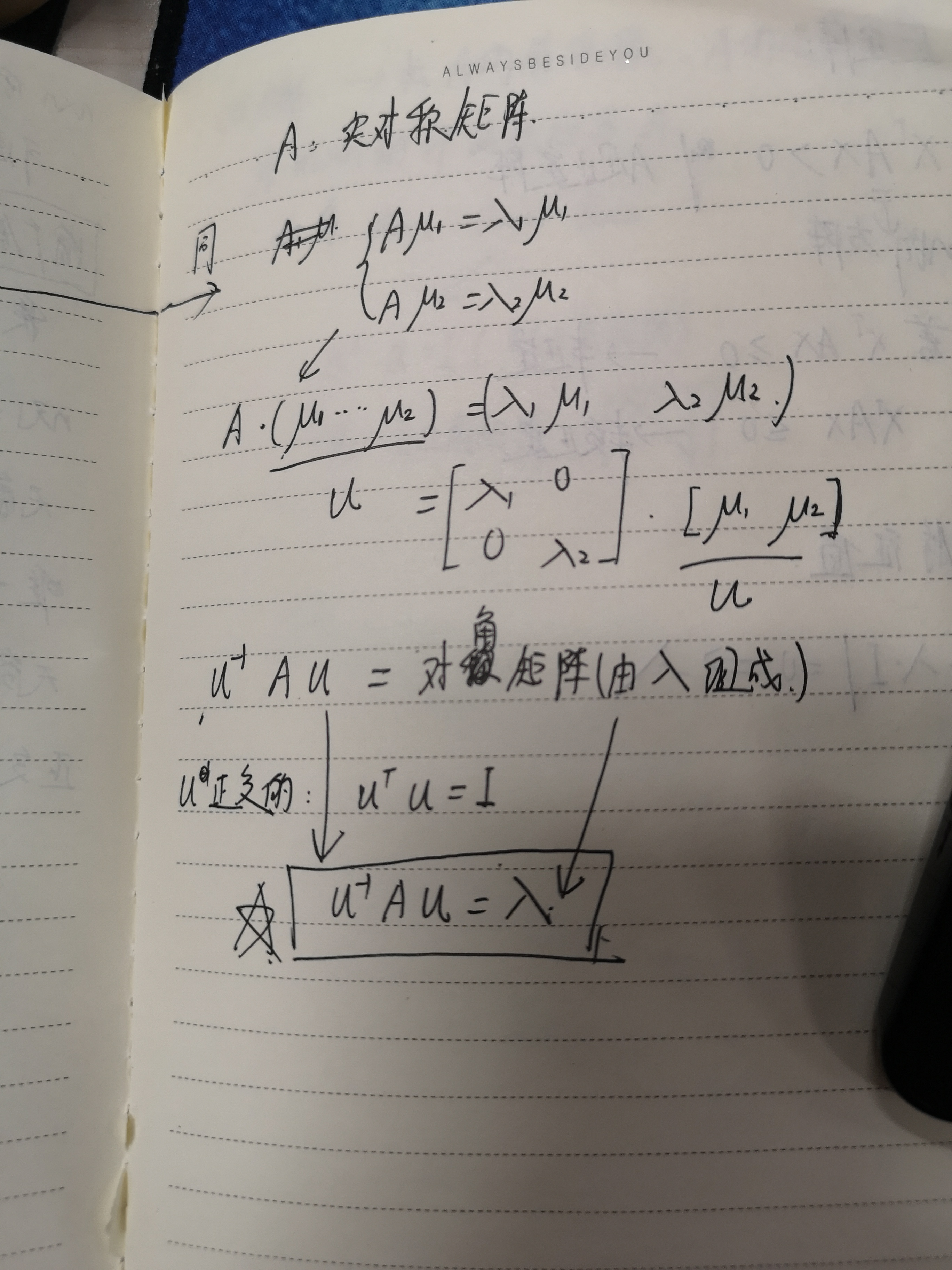
再举个例子:
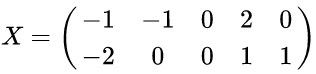
以X为例,我们用PCA方法将这两行数据降到一行。
1)因为X矩阵的每行已经是零均值,所以不需要去平均值。
2)求协方差矩阵:
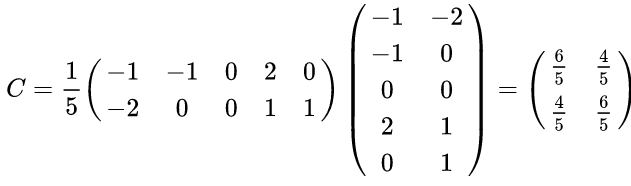
3)求协方差矩阵的特征值与特征向量。
求解后的特征值为:
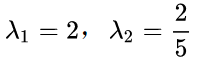
对应的特征向量

其中对应的特征向量分别是一个通解,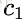
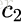
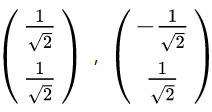
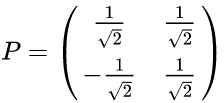
最后我们用P的第一行乘以数据矩阵X,就得到了降维后的表示:
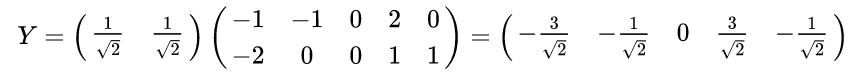
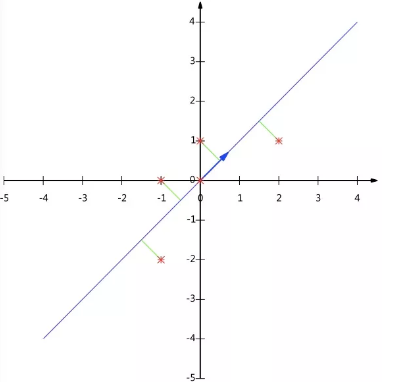
数据矩阵X降维投影结果:
数据降维-PCA主成分分析的更多相关文章
- 11_数据降维PCA
1.sklearn降维API:sklearn. decomposition 2.PCA是什么:主成分分析 本质:PCA是一种分析.简化数据集的技术. 目的:是数据维数压缩,尽可能降低原数据的维数(复杂 ...
- 数据降维PCA——学习笔记
PCA主成分分析 无监督学习 使方差(数据离散量)最大,更易于分类. 可以对隐私数据PCA,数据加密. 基变换 投影->内积 基变换 正交的基,两个向量垂直(内积为0,线性无关) 先将基化成各维 ...
- SIGAI机器学习第八集 数据降维1
讲授数据降维原理,PCA的核心思想,计算投影矩阵,投影算法的完整流程,非线性降维技术,流行学习的概念,局部线性嵌入,拉普拉斯特征映射,局部保持投影,等距映射,实际应用 大纲: 数据降维问题PCA的思想 ...
- 主成分分析PCA数据降维原理及python应用(葡萄酒案例分析)
目录 主成分分析(PCA)——以葡萄酒数据集分类为例 1.认识PCA (1)简介 (2)方法步骤 2.提取主成分 3.主成分方差可视化 4.特征变换 5.数据分类结果 6.完整代码 总结: 1.认识P ...
- [机器学习之13]降维技术——主成分分析PCA
始终贯彻数据分析的一个大问题就是对数据和结果的展示,我们都知道在低维度下数据处理比较方便,因而数据进行简化成为了一个重要的技术.对数据进行简化的原因: 1.使得数据集更易用使用.2.降低很多算法的计算 ...
- [机器学习]-PCA数据降维:从代码到原理的深入解析
&*&:2017/6/16update,最近几天发现阅读这篇文章的朋友比较多,自己阅读发现,部分内容出现了问题,进行了更新. 一.什么是PCA:摘用一下百度百科的解释 PCA(Prin ...
- 降维之主成分分析法(PCA)
一.主成分分析法的思想 我们在研究某些问题时,需要处理带有很多变量的数据,比如研究房价的影响因素,需要考虑的变量有物价水平.土地价格.利率.就业率.城市化率等.变量和数据很多,但是可能存在噪音和冗余, ...
- 降维算法-PCA主成分分析
1.PCA算法介绍主成分分析(Principal Components Analysis),简称PCA,是一种数据降维技术,用于数据预处理.一般我们获取的原始数据维度都很高,比如1000个特征,在这1 ...
- 降维PCA技术
降维技术使得数据变得更易使用,并且它们往往能够去除数据中的噪声,使得机器学习任务往往更加精确. 降维往往作为预处理步骤,在数据应用到其它算法之前清洗数据.有很多技术可以用于数据降维,在这些技术中,独立 ...
随机推荐
- nginx高可用集群
1.配置: (1)需要两台nginx服务器 (2)需要keepalived (3)需要虚拟ip 2.配置高可用的准备工作 (1)需要两台服务器192.168.180.113和192.168.180.1 ...
- Linux后台运行Jar方法
原文地址:http://blog.csdn.net/c1481118216 https://blog.csdn.net/c1481118216/article/details/53010963 在li ...
- CTR@因子分解机(FM)
1. FM算法 FM(Factor Machine,因子分解机)算法是一种基于矩阵分解的机器学习算法,为了解决大规模稀疏数据中的特征组合问题.FM算法是推荐领域被验证效果较好的推荐算法之一,在电商.广 ...
- SasS 设计原则十二因素
Heroku 是业内知名的云应用平台,从对外提供服务以来,他们已经有上百万应用的托管和运营经验.其创始人 Adam Wiggins 根据这些经验,发布了一个“十二要素应用宣言(The Twelve-F ...
- gedit一些小的新发现
写应该还有一些人正在像我一样用gedit呢. 现在vim,gedit,guide三党还是互相瞧不起呢. 我写这一篇是想稍微交流一下gedit的一些乱七八糟的玩意,非gedit党勿喷. 有些人连一些比较 ...
- 模拟80(a)
其实隔壁的那套题比这套难的多....一道都不会.. T1 题目中已经给出了递推公式,那么这题就没什么了,直接矩阵乘就完了. 然而考场上并没有看出矩阵,主要是用了好久发明crt,我知道原理,但是不会打了 ...
- 原生JS实现集合结构
1. 前言 集合是由一组无序且唯一(即不能重复)的项组成的.你可以把集合想象成一个既没有重复元素,也没有顺序概念的数组.在ES6中已经内置了集合这一数据结构--Set.接下来,我们就用原生JS来实现这 ...
- C语言程序设计100例之(4):水仙花数
例4 水仙花数 题目描述 一个三位整数(100-999),若各位数的立方和等于该数自身,则称其为“水仙花数”(如:153=13+53+33),找出所有的这种数. 输入格式 没有输入 输出格式 若 ...
- Apache Flink任意Jar包上传导致远程代码执行漏洞复现
0x00 简介 Apache Flink是由Apache软件基金会开发的开源流处理框架,其核心是用Java和Scala编写的分布式流数据流引擎.Flink以数据并行和流水线方式执行任意流数据程序,Fl ...
- cnblogs侧边栏访客统计 小插件
之前博客的侧边栏一直用的是flagcounter,直观简洁又好看,近期恍然发现被博客园禁了.禁用原因据说是由于flagcounter将香港(HongKong).台湾(TaiWan)和澳门(Macau) ...