7.InfluxDB-InfluxQL基础语法教程--INTO子句
本文翻译自官网,官网地址:(https://docs.influxdata.com/influxdb/v1.7/query_language/data_exploration/)
通过INTO子句,可以将用户的查询结果插入到用户指定的measurement中。
语法
SELECT_clause
INTO <measurement_name>
FROM_clause [WHERE_clause] [GROUP_BY_clause]
INTO子句支持如下语法,使得用户可以使用不同方式来指定要插入数据的measurement:
| 子句 | 意义 |
|---|---|
| INTO <measurement_name> | 插入到指定measurement中。此时使用的是当前库、使用默认的retention policy |
| INTO <database_name>.<retention_policy_name>.<measurement_name> | 往全路径的measurement中插入数据。此时指定了库、指定retention policy、指定measurement |
| INTO <database_name>..<measurement_name> | 往指定库的指定measurement中插入数据,使用默认的retention policy |
| INTO <database_name>.<retention_policy_name>.:MEASUREMENT FROM /<regular_expression>/ | 往指定库、指定retentioin policy,并且符合FROM子句中的正则规则的measurement中插入数据 |
INTO示例sql
- 示例一
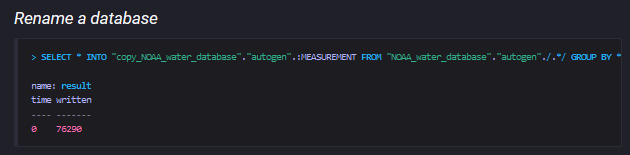
在InfluxDB中,是无法直接重命名一个库的,所以一个通常的做法是,像如上的sql那样,把一个库的所有数据全部复制到另一库中去。
其中 GROUP BY * 子句使得在源库中是tag key的字段,复制到目标库中之后依然是tag key。下面的sql就不维护tag的series上下文环境,如此一来在源库中的tag key在被复制到目标库之后,就变成fields了:
SELECT *
INTO "copy_NOAA_water_database"."autogen".:MEASUREMENT
FROM "NOAA_water_database"."autogen"./.*/
当需要复制大量的数据时,官方推荐一个一个measurement的进行复制,并且最好通过WHERE子句来指定时间区间,这样可以避免系统出现内存溢出的错误。如下面的sql就展示了通过指定时间区间来分批的进行数据复制操作:
SELECT *
INTO <destination_database>.<retention_policy_name>.<measurement_name>
FROM <source_database>.<retention_policy_name>.<measurement_name>
WHERE time > now() - 100w and time < now() - 90w GROUP BY *
SELECT *
INTO <destination_database>.<retention_policy_name>.<measurement_name>
FROM <source_database>.<retention_policy_name>.<measurement_name>}
WHERE time > now() - 90w and time < now() - 80w GROUP BY *
SELECT *
INTO <destination_database>.<retention_policy_name>.<measurement_name>
FROM <source_database>.<retention_policy_name>.<measurement_name>
WHERE time > now() - 80w and time < now() - 70w GROUP BY *
示例二
将一次查询结果写入到一个measurement中:

上面sql将它的查询结果插入到一个新建的名为h2o_feet_copy_1的measurement中。执行sql的结果显示总共插入了7604条结果数据到h2o_feet_copy_1中,时间戳1970-01-01T00:00:00Z则没有什么意思,前面说过,在InfluxDB中,使用1970-01-01T00:00:00Z来表示timestamp的null。示例三
将查询结果插入到一个全路径的measurement中
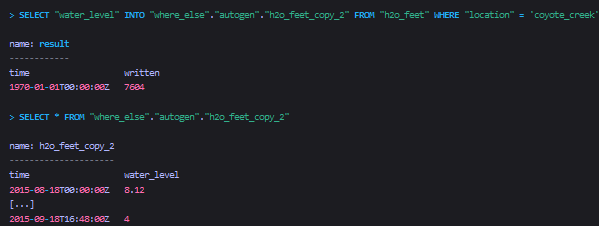
Note that both where_else and autogen must exist prior to running the INTO query.示例四
将聚合查询结果插入到measurement中(缩减取样)
SELECT MEAN("water_level") INTO "all_my_averages" FROM "h2o_feet"
WHERE "location" = 'coyote_creek'
AND time >= '2015-08-18T00:00:00Z'
AND time <= '2015-08-18T00:30:00Z'
GROUP BY time(12m)

- 示例五
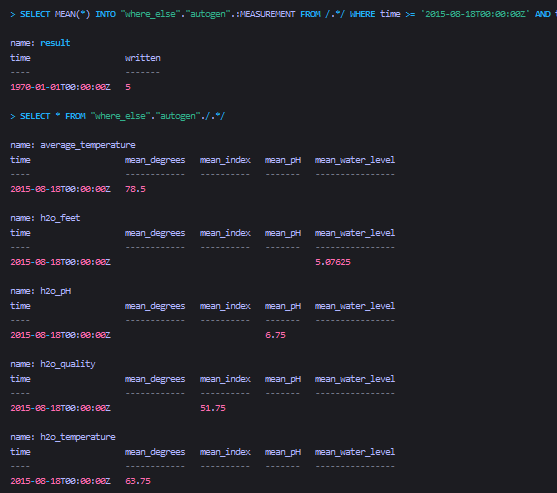
将多个表的汇总查询结果,复制到另一个库中
Sql
SELECT MEAN(*)
INTO "where_else"."autogen".:MEASUREMENT
FROM /.*/
WHERE time >= '2015-08-18T00:00:00Z'
AND time <= '2015-08-18T00:06:00Z'
GROUP BY time(12m)
查询结果
INTO子句常见问题
问题1:丢失数据
如果在一个INTO查询中,再把数据复制到目标库时会把源库的tag key转换为fields,这可能会导致influxdb覆盖先前由tag key区分的点。注意,此行为不适用于使用top()或bottom()函数的查询。在常见问题文档中可查看到该问题的详细描述。
为了防止源库的tag key复制到目标库之后编程fields,可以在INTO查询sql中使用group by有意义的tag key,或者group by \*.
问题2:使用into子句自动化查询
本小节展示了如何通过into子句来实现手动插入复制数据的操作。可以在Continuous Queries的相关文档中查看到如何利用into子句实现实时的查询数据。
7.InfluxDB-InfluxQL基础语法教程--INTO子句的更多相关文章
- 5.InfluxDB-InfluxQL基础语法教程--WHERE子句
本文翻译自官网,官网地址:(https://docs.influxdata.com/influxdb/v1.7/query_language/data_exploration/) WHERE子句 语法 ...
- 2.InfluxDB-InfluxQL基础语法教程--目录
本文翻译自官网,官方文档地址:(https://docs.influxdata.com/influxdb/v1.7/query_language/data_exploration/) InfluxQL ...
- 前端开发利器 Emmet 介绍与基础语法教程
在前端开发的过程中,编写 HTML.CSS 代码始终占据了很大的工作比例.特别是手动编写 HTML 代码,效率特别低下,因为需要敲打各种“尖括号”.闭合标签等.而现在 Emmet 就是为了提高代码编写 ...
- 10.InfluxDB-InfluxQL基础语法教程--OFFSET 和SOFFSET子句
本文翻译自官网,官网地址:(https://docs.influxdata.com/influxdb/v1.7/query_language/data_exploration/) OFFSET 和SO ...
- 6.InfluxDB-InfluxQL基础语法教程--GROUP BY子句
本文翻译自官网,官网地址:(https://docs.influxdata.com/influxdb/v1.7/query_language/data_exploration/) GROUP BY子句 ...
- 9.InfluxDB-InfluxQL基础语法教程--LIMIT and SLIMIT 子句
本文翻译自官网,官网地址:(https://docs.influxdata.com/influxdb/v1.7/query_language/data_exploration/) LIMIT和SLIM ...
- 8.InfluxDB-InfluxQL基础语法教程--ORDER BY子句
本文翻译自官网,官网地址:(https://docs.influxdata.com/influxdb/v1.7/query_language/data_exploration/) 在InfluxDB中 ...
- 4.InfluxDB-InfluxQL基础语法教程--基本select语句
本文翻译自官网,官网地址:(https://docs.influxdata.com/influxdb/v1.7/query_language/data_exploration/) 基本语法如下: SE ...
- 3.InfluxDB-InfluxQL基础语法教程--数据说明
下面是本次演示的示例数据 表名:h2o_feet 数据示例: 数据描述 : 表h2o_feet中所存储的是6分钟时间区间内的数据. 该表有一个tag,即location,该tag有两个值,分别为coy ...
随机推荐
- JSP中 JSTL和EL标签的使用
使用JSTL前的准备 想要使用JSTL,首先需要给工程导入JSTL的包(JSTL.jar和standard.jar). JSTL简介 JSP标准标签库(JSTL)是一个JSP标签集合,它封装了JSP应 ...
- drf扩展知识点总结视图
- 对CNN 的理解
CNN 的强大之处在于它的多层结构能自动学习特征,并且可以学习到多个层次的特征:较浅的卷积层感知域较小,学习到一些局部区域的特征. 较深的卷积层具有较大的感知域,能够学习到更加抽象一些的特征.这些抽象 ...
- markdown 编辑格式
# h1## h2### h3#### h4##### h5###### h6 *em* **strong** ***斜体加粗*** ~~待删除~~ 无序列表,用 * + - 都可以表示,[可以用四个 ...
- LeetCode98. 验证二叉搜索树
验证二叉搜索树 * * https://leetcode-cn.com/problems/validate-binary-search-tree/description/ * * algor ...
- ES2019 的新特性
JavaScript 不断演变,每次迭代都会得到一些新的内部更新.让我们来看看 ES2019 有哪些新的特性,并加入到我们日常开发中 Array.prototype.flat() Array.prot ...
- 洛谷P3723 [AH2017/HNOI2017]礼物
吴迪说他化学会考上十分钟就想出来了,太神了%%%不过我也十分钟 但是调了一个多小时啊大草 懒得人话翻译了,自己康吧: 我的室友(真的是室友吗?)最近喜欢上了一个可爱的小女生.马上就要到她的生日了,他决 ...
- 物联网架构成长之路(34)-物联网数据可视化grafana展示
一.前言 前面介绍了利用后台业务服务器监听EMQ的Topic,作为EMQ的一个客户端方式来保存数据.然后将数据保存到时序数据库InfluxDB中.本小节就简单介绍一下如何安装和使用,及如何利用Graf ...
- 本地运行vue项目webpack提示 Compiled successfully
最近在github下载运行别人的vue项目后,如下图提示编译成功,但项目并没有启动 最开始我以为是端口问题,修改了config-index.js里的port端口,重新运行后依然是上图提示 ...
- VMware workstation 12虚拟机安装CentOS7详细安装教程
虚拟机(Virtual Machine)指通过软件模拟的具有完整硬件系统功能的.运行在一个完全隔离环境中的完整计算机系统. 虚拟系统通过生成现有操作系统的全新虚拟镜像,它具有真实windows系统完全 ...