Pandas 转换连接
# 导入相关库
import numpy as np
import pandas as pd
拼接
有两个 DataFrame,都存储了用户的一些信息,现在要拼接起来,组成一个 DataFrame。 如何实现?
创建数据
data1 = { www.neuedu.com
"name": ["Tom", "Bob"],
"age": [18, 30],
"city": ["Bei Jing ", "Shang Hai "]
}
df1 = pd.DataFrame(data=data1)
data2 = {
"name": ["Mary", "James"],
"age": [35, 18],
"city": ["Guang Zhou", "Shen Zhen"]
}
df2 = pd.DataFrame(data=data2)
append 拼接
append 是最简单的拼接两个DataFrame的方法
df1.append(df2)
拼接后的索引默认还是原有的索引,如果想要重新生成索引的话,设置参数ignore_index=True 即可
df1.append(df2, ignore_index=True)
concat 拼接
objs=[df1, df2]
pd.concat(objs, ignore_index=True)
如果想要区分出不同的 DataFrame 的数据,可以通过设置参数 keys,还需要设置参数 ignore_index=False
pd.concat(objs, ignore_index=False, keys=["df1", "df2"])
关联
有两个DataFrame,分别存储了用户的部分信息,现在需要将用户的这些信息关联起来,如何实现呢?
创建数据
data1 = {
"name": ["Tom", "Bob", "Mary", "James"],
"age": [18, 30, 35, 18],
"city": ["Bei Jing ", "Shang Hai ", "Guang Zhou", "Shen Zhen"]
}
df1 = pd.DataFrame(data=data1)
data2 = {
"name": ["Bob", "Mary", "James", "Andy"],
"sex": ["male", "female", "male", np.nan],
"income": [8000, 8000, 4000, 6000]
}
df2 = pd.DataFrame(data=data2)
merge 关联
通过 pd.merge 可以关联两个 DataFrame,这里我们设置参数 on="name",表示依据
name 来作为关联键
pd.merge(df1, df2, on="name")
关联后发现数据变少了,这是因为默认关联的方式是 inner,如果不想丢失任何数据,可以设置参数 how="outer"
pd.merge(df1, df2, on="name", how="outer")
如果我们想保留左边所有的数据,可以设置参数 how="left"
反之,如果想保留右边的所有数据,可以设置参数 how="right"
pd.merge(df1, df2, on="name", how="left")
两个 DataFrame 中需要关联的键的名称不一样,可以通过 left_on 和 right_on 来分别设置。
df1.rename(columns={"name": "name1"}, inplace=True)
df2.rename(columns={"name": "name2"}, inplace=True)
pd.merge(df1, df2, left_on="name1", right_on="name2")
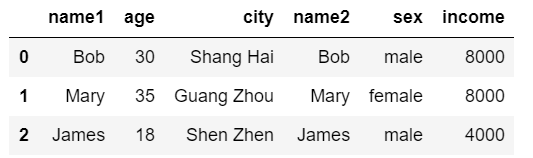
两个 DataFrame 中都包含相同名称的字段,我们可以设置参数 suffixes,默认suffixes=('_x', '_y') 表示将相同名称的左边的 DataFrame 的字段名加上后缀 _x,右边加上后缀 _y
df1["sex"] = "male"
pd.merge(df1, df2, left_on="name1", right_on="name2")
pd.merge(df1, df2, left_on="name1", right_on="name2", suffixes=("_left", "_right"))

join
除了 merge 这种方式外,还可以通过 join 这种方式实现关联。相比 merge , join 这种方式有以下几个不同:
- 默认参数 on=None ,表示关联时使用左边和右边的索引作为键,设置参数 on 可以指定的是关联时左边的所用到的键名
- 左边和右边字段名称重复时,通过设置参数 lsuffix 和 rsuffix 来解决
df1.join(df2.set_index("name2"), on="name1", lsuffix="_left")

Pandas 转换连接的更多相关文章
- Pandas系列(十)-转换连接详解
目录 1. 拼接 1.1 append 1.2 concat 2. 关联 2.1 merge 2.2 join 数据准备 # 导入相关库 import numpy as np import panda ...
- pandas合并/连接
Pandas具有功能全面的高性能内存中连接操作,与SQL等关系数据库非常相似.Pandas提供了一个单独的merge()函数,作为DataFrame对象之间所有标准数据库连接操作的入口 - pd.me ...
- pandas的连接函数concat()函数
pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False, keys=None, levels=No ...
- pandas.concat连接dataframe
https://blog.csdn.net/stevenkwong/article/details/52528616
- 使用第三方库连接MySql数据库:PyMysql库和Pandas库
使用PyMysql库和Pandas库链接Mysql 1 系统环境 系统版本:Win10 64位 Mysql版本: 8.0.15 MySQL Community Server - GPL pymysql ...
- 使用Python Pandas处理亿级数据
在数据分析领域,最热门的莫过于Python和R语言,此前有一篇文章<别老扯什么Hadoop了,你的数据根本不够大>指出:只有在超过5TB数据量的规模下,Hadoop才是一个合理的技术选择. ...
- IOS 时间字符串转换时间戳失败问题
链接:https://pan.baidu.com/s/1nw6VWoD 密码:1peh 有时候获取到的时间带有毫秒数或者是(2018-2-6 11:11:11)格式的(别说你没遇到过,也别什么都让后台 ...
- Windows Server 2012R2 网络地址转换NAT
一.NAT概述 网络地址转换NAT(Network Address Translation)可以动态改变通过路由器的IP报文的内容(修改报文的源IP地址和/或目的IP地址).离开路由器的报文的源地址或 ...
- Pandas教程目录
Pandas数据结构 Pandas系列 Pandas数据帧(DataFrame) Pandas面板(Panel) Pandas基本功能 Pandas描述性统计 Pandas函数应用 Pandas重建索 ...
随机推荐
- 是男人就过八题A_A String Game题解
题意 给一个字符串\(s\),和\(n\)个子串\(t[i]\),两个人博弈,每次取出一个串\(t[i]\),在后面加入一个字符,保证新字符串仍然是\(s\)的子串,无法操作的人输. 分析 n个子串, ...
- Maven配置JRE版本
Maven配置JRE版本 apache-maven-3.5.0\conf\settings.xml <profiles> <profile> <id>develop ...
- Java 学习笔记之 线程脏读
线程脏读: 发生脏读的情况是在读取实例变量时,值已经被其他线程更改过了. public class DirtyReadVar { public String username = "A&qu ...
- CSDN VIP如何添加引流自定义栏目
几个月前我也开始在csdn上开了博客,一来给自己加几个少的可怜的流量,再者,让公众号的原创文章获得更多的曝光,让有需要的同学看到. 写过csdn博客的同学都知道,默认只有打赏c币功能:也没有专门广告位 ...
- OEMCC 13.3 主机agent部署问题排查
部署安装 具体的安装过程可参考,Alfred Zhao的文章,非常详细,文章是OEMCC13.2的部署过程.OEMCC13.3没有太大差别. https://www.cnblogs.com/jyzha ...
- Flex 布局——语法属性详解
前言 Flexbox 是 flexible box 的简称(注:意思是“灵活的盒子容器”),是 CSS3 引入的新的布局模式.它决定了元素如何在页面上排列,使它们能在不同的屏幕尺寸和设备下可预测地展现 ...
- 走进JavaWeb技术世界1:JavaWeb的由来和基础知识
本系列文章将整理到我在GitHub上的<Java面试指南>仓库,更多精彩内容请到我的仓库里查看 https://github.com/h2pl/Java-Tutorial 喜欢的话麻烦点下 ...
- Vue中组件
0828自我总结 Vue中组件 一.组件的构成 组件:由 template + css + js 三部分组成(.vue文件) 1)组件具有复用性 2) 复用组件时,数据要隔离 3) 复用组件时,方法不 ...
- Vue核心之数据劫持
前瞻 当前前端界空前繁荣,各种框架横空出世,包括各类mvvm框架横行霸道,比如Anglar,Regular,Vue,React等等,它们最大的优点就是可以实现数据绑定,再也不需要手动进行DOM操作了, ...
- iOS开发请您把握现在 — 面向未来学习
iOS开发请您把握现在 — 面向未来学习 这一篇文章,如果你是一名iOS开发正好也处于开发晋升瓶颈迷茫期,不妨停下你的脚步,花五分钟看看,兴许有你需要的!文章结尾有彩蛋 群里常见的唱哀 iOS现在到底 ...