机器学习之scikit-learn库
前面讲到了,这个库适合学习,轻量级,所以先学它。
安装就不讲了,简单。不过得先安装numpy和pandas库才能安装scikit-learn库。
如果安装了anaconda得话,会自带有这个库。
----------------------------------------------------------------------------------------------------------
1、首先进行字典特征提取
作用:对字典数据进行特征值提取。
API:sklearn.feature_extraction.DictVectorizer

流程:1、实例化类 DictVectorizer()
2、调用fit_transorm方法输入数据并转换
上代码:
from sklearn.feature_extraction import DictVectorizer def dictvec():
'''
字典数据抽取
:return: None
'''
# 实例化
dict = DictVectorizer() # 调用fit_transorm
data = dict.fit_transform([{'name':'X','score': 80},{'name':'Y','score': 90},{'name':'Z','score': 100}]) print(data) return None if __name__ == '__main__':
dictvec()

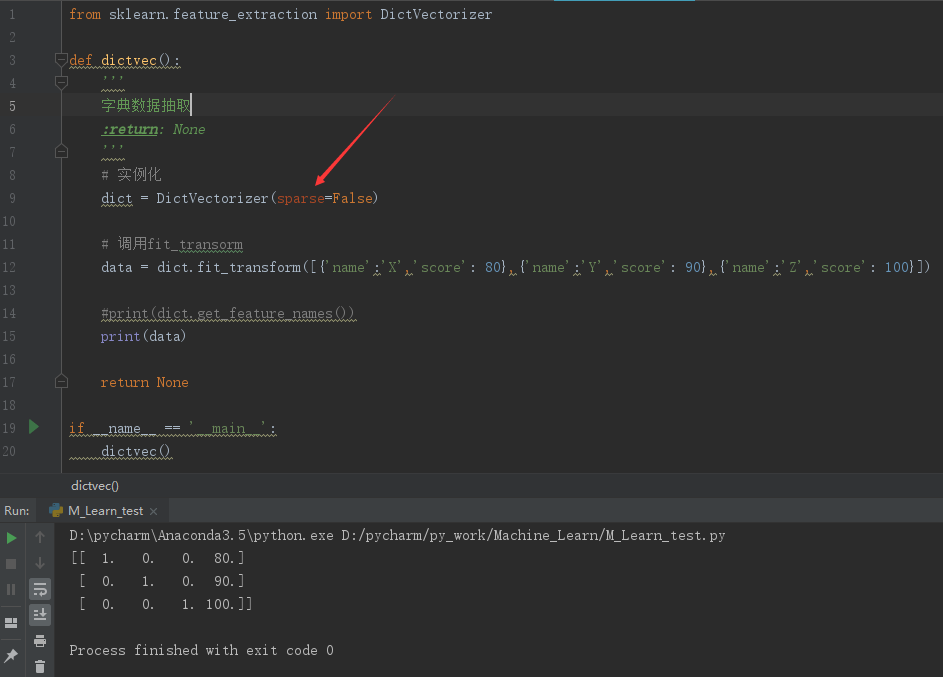
可以看到输出结果是一个Sparse矩阵,前面得括号里面是坐标,后面的数字是这个坐标的值,比如:(0,0) 1.0 表示在第0行0列的值为1。
其他没有列出来的坐标如(0,1)、(0,2)等的值默认为0.
将DictVectorizer()中的sparse参数设置为False可以使得结果容易可读。
2、文本特征提取
作用:对文本数据进行提取 API:sklearn.feature_extraction.text.CountVectorizer上代码:假设有两篇文章分别为:'life is shortm,i like Python'和'life is too long, i dislike Python'
from sklearn.feature_extraction.text import CountVectorizer def countvec():
'''
对文本进行特征值提取
:return: None
'''
# 实例化
cv = CountVectorizer() # 调用fit_transorm
data = cv.fit_transform(['life is shortm,i like Python','life is too long, i dislike Python']) print(data) return None if __name__ == '__main__':
countvec()
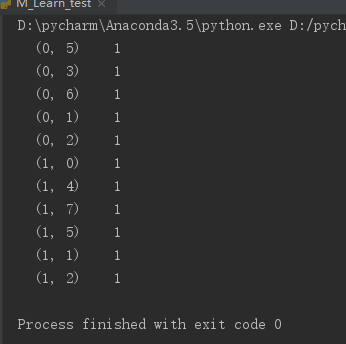
结果和字典提取是一样的,值得注意的是这里要将parse矩阵转换成比较容易读的二维矩阵的话,是在结果中调用toarray(),而不是设置sparse参数
如下图:
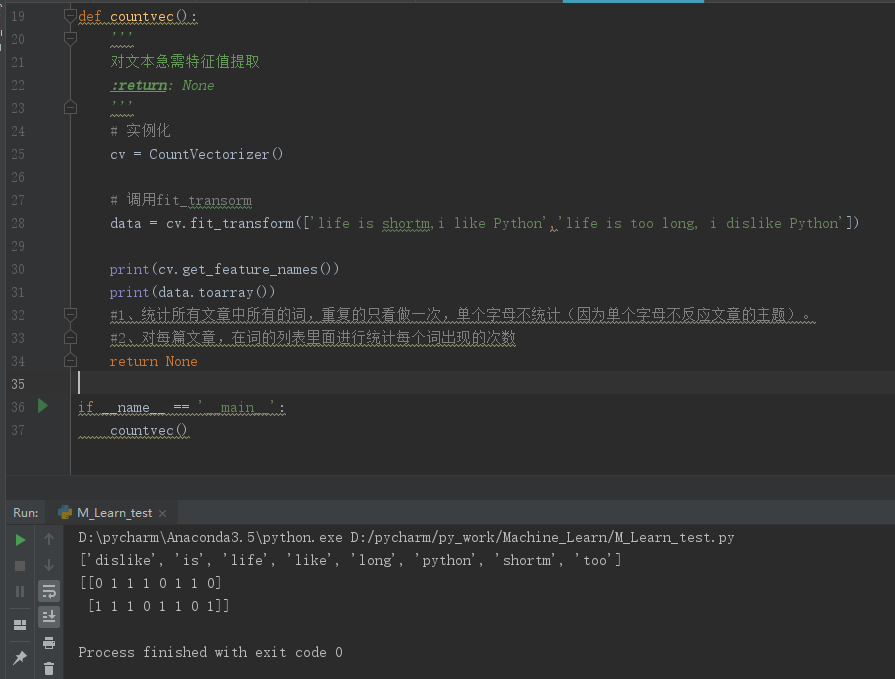
get_feature_names()返回一个列表,列表里面是提取的所有特征(本例中提取出了8个单词,单个字母不统计)。
结果中有两个列表,每个列表对应一篇文章。第一个列表中第一个0表示第一篇文章中dislike没有出现,第一个列表中第一个1表示is出现了,依次类推
机器学习之scikit-learn库的更多相关文章
- 机器学习框架Scikit Learn的学习
一 安装 安装pip 代码如下:# wget "https://pypi.python.org/packages/source/p/pip/pip-1.5.4.tar.gz#md5=83 ...
- Scikit Learn: 在python中机器学习
转自:http://my.oschina.net/u/175377/blog/84420#OSC_h2_23 Scikit Learn: 在python中机器学习 Warning 警告:有些没能理解的 ...
- (原创)(三)机器学习笔记之Scikit Learn的线性回归模型初探
一.Scikit Learn中使用estimator三部曲 1. 构造estimator 2. 训练模型:fit 3. 利用模型进行预测:predict 二.模型评价 模型训练好后,度量模型拟合效果的 ...
- (原创)(四)机器学习笔记之Scikit Learn的Logistic回归初探
目录 5.3 使用LogisticRegressionCV进行正则化的 Logistic Regression 参数调优 一.Scikit Learn中有关logistics回归函数的介绍 1. 交叉 ...
- scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类 (python代码)
scikit learn 模块 调参 pipeline+girdsearch 数据举例:文档分类数据集 fetch_20newsgroups #-*- coding: UTF-8 -*- import ...
- 机器学习三剑客之Numpy库基本操作
NumPy是Python语言的一个扩充程序库.支持高级大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库.Numpy内部解除了Python的PIL(全局解释器锁),运算效率极好,是大量机 ...
- Scikit Learn
Scikit Learn Scikit-Learn简称sklearn,基于 Python 语言的,简单高效的数据挖掘和数据分析工具,建立在 NumPy,SciPy 和 matplotlib 上.
- Python第三方库(模块)"scikit learn"以及其他库的安装
scikit-learn是一个用于机器学习的 Python 模块. 其主页:http://scikit-learn.org/stable/. GitHub地址: https://github.com/ ...
- 机器学习-scikit learn学习笔记
scikit-learn官网:http://scikit-learn.org/stable/ 通常情况下,一个学习问题会包含一组学习样本数据,计算机通过对样本数据的学习,尝试对未知数据进行预测. 学习 ...
- Python机器学习笔记:sklearn库的学习
网上有很多关于sklearn的学习教程,大部分都是简单的讲清楚某一方面,其实最好的教程就是官方文档. 官方文档地址:https://scikit-learn.org/stable/ (可是官方文档非常 ...
随机推荐
- 响应系统设置的事件(Configuration类)
1.Configuration给我们提供的方法列表 densityDpi:屏幕密度 fontScale:当前用户设置的字体的缩放因子 hardKeyboardHidden:判断硬键盘是否可见,有两个可 ...
- Apache Kylin 概述
1 Kylin是什么 今天,随着移动互联网.物联网.AI等技术的快速兴起,数据成为了所有这些技术背后最重要,也是最有价值的"资产".如何从数据中获得有价值的信息?这个问题驱动了相关 ...
- 搭建docker+swoole+php7 的环境
最近在学习swoole php扩展,苦恼于其运行环境不能在win系统下运行, 但开发代码一直在win系统上,很无奈,,,, 所以就用docker来代替,舒服~ 有很多相关docker的swoole镜像 ...
- bugku账号被盗了
首先访问这个网站. 点击一下 使用burp抓包 将false改为true试试,获得了新的返回包,包含了一个网站,访问这个网站,下载下发现是一个软件. 随便填写一个账号密码,并使用wireshark抓包 ...
- if循环判断
if循环判断 if-else循环的语法格式 if 逻辑判断句: 代码块 # 缩进表示所属关系 else 逻辑判断句: 代码块 if 和elif同时使用来做多层判断 if 逻辑判断式: 代码块 ...
- python编程系列---args与kwargs详解
args与kwargs详解 """ Process([group [, target [, name [, args [, kwargs]]]]]) - target:目 ...
- Spring Cloud Alibaba学习笔记(23) - 调用链监控工具Spring Cloud Sleuth + Zipkin
随着业务发展,系统拆分导致系统调用链路愈发复杂一个前端请求可能最终需要调用很多次后端服务才能完成,当整个请求陷入性能瓶颈或不可用时,我们是无法得知该请求是由某个或某些后端服务引起的,这时就需要解决如何 ...
- vue移动端 实现手机左右滑动入场动画
app.vue <template> <div id="app"> <transition :name="transitionName&qu ...
- 基于STM32F103和Cube的输入捕获例程
1.开发环境 (1)Cube5.24 (2)Keil5 (3)STM32F103 2.Cube配置 Cube配置很简单,只要打开TIM4通道1的引脚,设置为输入捕获模式,在配置是高或低电平沿触发 TI ...
- SpringBoot学习(三)探究Springboot自动装配
目录 什么是自动装配 何时自动装配 原理分析 注:以下展示的代码springboot的版本为2.0.3版.因源码过长,大家选择展开代码 ㄟ( ▔, ▔ )ㄏ 什么是自动装配 自动装配还是利用了Spri ...