redis集群(单机6节点实现)
Redis集群搭建与简单使用
1.介绍安装环境与版本:
1)Redis使用的是Redis-3.2.8版本。
2)用一台虚拟机模拟6个节点,三个master节点,三个slave节点。虚拟机使用CentOS6.5系统(192.168.0.132)。
2.原理介绍:
Redis cluster在设计的时候,就考虑到了去中心化,去中间件,也就是说,集群中的每个节点都是平等的关系,都是对等的,每个节点都保存各自的数据和整个集群的状态。每个节点都和其他所有节点连接,而且这些连接保持活跃,这样就保证了我们只需要连接集群中的任意一个节点,就可以获取到其他节点的数据。
Redis 集群没有并使用传统的一致性哈希来分配数据,而是采用另外一种叫做哈希槽 (hash slot)的方式来分配的。redis cluster 默认分配了 16384 个slot,当我们set一个key 时,会用CRC16算法来取模得到所属的slot,然后将这个key 分到哈希槽区间的节点上,具体算法就是:CRC16(key) % 16384。所以我们在测试的时候看到set 和 get 的时候,直接跳转到了7001端口的节点。
Redis 集群会把数据存在一个 master 节点,然后在这个 master 和其对应的salve 之间进行数据同步。当读取数据时,也根据一致性哈希算法到对应的 master 节点获取数据。只有当一个master 挂掉之后,才会启动一个对应的 salve 节点,充当 master 。
需要注意的是:必须要3个或以上的主节点,否则在创建集群时会失败,并且当存活的主节点数小于总节点数的一半时,整个集群就无法提供服务了。
3.安装过程:
1)解压并编译安装
#mkdir -p /data/redis/cluster;cd /data/redis //创建环境目录
#tar -zxvf redis-3.2.8.tar.gz //解压安装包
#cd redis-3.2.8/ //进入到Redis源码包
#make && make install //编译并安装
2)将 redis-trib.rb 复制到 /usr/local/bin 目录下,因为 redis-trib.rb 是基于Ruby的,所以还需要安装Ruby。
#cd src;cp redis-trib.rb /usr/local/bin/
#yum -y install ruby ruby-devel rubygems rpm-build //安装Ruby和其依赖
#gem install redis //ruby安装redis依赖
3)创建 Redis 节点
#cd /data/redis/cluster && mkdir {7001..7006}
#cp /data/redis/redis-3.2.8/redis.conf 7001/
#cp /data/redis/redis-3.2.8/redis.conf 7002/
#cp /data/redis/redis-3.2.8/redis.conf 7003/
#cp /data/redis/redis-3.2.8/redis.conf 7004/
#cp /data/redis/redis-3.2.8/redis.conf 7005/
#cp /data/redis/redis-3.2.8/redis.conf 7006/
分别修改六个配置文件:
#vi redis.conf
port 7001 //端口7001,7002,7003,7004,7005,7006
bind 192.168.0.132 //默认ip为127.0.0.1 需要改为其他节点机器可访问的ip 否则创建集群时无法访问对应的端口,无法创建集群
daemonize yes //redis后台运行
timeout 10000 //超时时间
pidfile /var/run/redis_7001.pid //pidfile文件对应7000,7001,7002
cluster-enabled yes //开启集群 把注释#去掉
cluster-config-file nodes_7000.conf //集群的配置 配置文件首次启动自动生成 7000,7001,7002
cluster-node-timeout 15000 //请求超时 默认15秒,可自行设置
appendonly yes //aof日志开启 有需要就开启,它会每次写操作都记录一条日志
appendfsync everysec //aof刷新方式
#save 900 1
#save 300 10
#save 60 10000
rdbcompression yes
dbfilename dump.rdb
loglevel verbose
databases 16
slave-serve-stale-data yes
no-appendfsync-on-rewrite no
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
slowlog-log-slower-than 10000
slowlog-max-len 1024
#hash-max-zipmap-entries 512
#hash-max-zipmap-value 64
list-max-ziplist-entries 512
list-max-ziplist-value 64
set-max-intset-entries 512
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
activerehashing yes
//重命名危险命令,安全性
rename-command config d6adsfk_config
rename-command slaveof d6adsfk_slaveof
rename-command flushall d6adsfk_flushall
rename-command flushdb d6adsfk_flushdb
##rename-command shutdown d6adsfk_shutdown
注:可以在vi的非编辑模式下使用正则批量替换端口:%s/6379/7001/g enter即可。7002-7006类似,修改对应配置文件的端口即可。
4)启动六个节点:
#/data/redis/redis-3.2.8/src/redis-server /data/redis/cluster/7001/redis.conf &
#/data/redis/redis-3.2.8/src/redis-server /data/redis/cluster/7002/redis.conf &
#/data/redis/redis-3.2.8/src/redis-server /data/redis/cluster/7003/redis.conf &
#/data/redis/redis-3.2.8/src/redis-server /data/redis/cluster/7004/redis.conf &
#/data/redis/redis-3.2.8/src/redis-server /data/redis/cluster/7005/redis.conf &
#/data/redis/redis-3.2.8/src/redis-server /data/redis/cluster/7006/redis.conf &
#ps -ef | grep redis //查看启动的进程
5)创建集群:
#redis-trib.rb create --replicas 1 192.168.0.132:7001 192.168.0.132:7002 192.168.0.132:7003 192.168.0.132:7004 192.168.0.132:7005 192.168.0.132:7006
>>> Creating cluster
>>> Performing hash slots allocation on 6 nodes...
Using 3 masters:
192.168.0.132:7001
192.168.0.132:7002
192.168.0.132:7003
Adding replica 192.168.0.132:7004 to 192.168.0.132:7001
Adding replica 192.168.0.132:7005 to 192.168.0.132:7002
Adding replica 192.168.0.132:7006 to 192.168.0.132:7003
M: 05244e4d6b721a733073b2a1ac7dc9f7a4145522 192.168.0.132:7001
slots:0-5460 (5461 slots) master
M: 5c3ed822213f1675e8e93911a12040f34844cf94 192.168.0.132:7002
slots:5461-10922 (5462 slots) master
M: 982985a7ad0f9b5800fc9315cc051d717bc870df 192.168.0.132:7003
slots:10923-16383 (5461 slots) master
S: 985b7e1b8a1c8e311c5d4ba2df3a455a18a6c2e6 192.168.0.132:7004
replicates 05244e4d6b721a733073b2a1ac7dc9f7a4145522
S: a688a187013bb6c7f22549fadda8eacc9dec6ec4 192.168.0.132:7005
replicates 5c3ed822213f1675e8e93911a12040f34844cf94
S: 550989f26bb0456df068e8d9c1a3476607b91dba 192.168.0.132:7006
replicates 982985a7ad0f9b5800fc9315cc051d717bc870df
Can I set the above configuration? (type 'yes' to accept): yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join....
>>> Performing Cluster Check (using node 192.168.0.132:7001)
M: 05244e4d6b721a733073b2a1ac7dc9f7a4145522 192.168.0.132:7001
slots:0-5460 (5461 slots) master
1 additional replica(s)
S: a688a187013bb6c7f22549fadda8eacc9dec6ec4 192.168.0.132:7005
slots: (0 slots) slave
replicates 5c3ed822213f1675e8e93911a12040f34844cf94
M: 5c3ed822213f1675e8e93911a12040f34844cf94 192.168.0.132:7002
slots:5461-10922 (5462 slots) master
1 additional replica(s)
S: 550989f26bb0456df068e8d9c1a3476607b91dba 192.168.0.132:7006
slots: (0 slots) slave
replicates 982985a7ad0f9b5800fc9315cc051d717bc870df
S: 985b7e1b8a1c8e311c5d4ba2df3a455a18a6c2e6 192.168.0.132:7004
slots: (0 slots) slave
replicates 05244e4d6b721a733073b2a1ac7dc9f7a4145522
M: 982985a7ad0f9b5800fc9315cc051d717bc870df 192.168.0.132:7003
slots:10923-16383 (5461 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
其中,前三个 ip:port 为master节点,后三个ip:port为slave节点。创建过程中需要输入一次:yes。出现上面输出的信息表示安装成功。
6)验证集群:
连接7002这个master节点进行操作:
#redis-cli -h 192.168.0.132 -c -p 7002
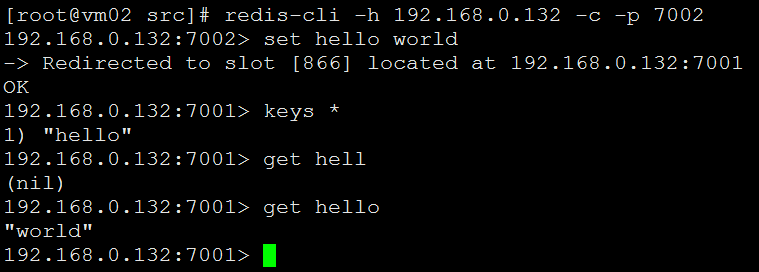
注:set数据和get数据的时候转向时自动完成的,无需用户切换。所以不管连接到哪个节点上进行操作都会返回数据并跳转到该数据分片的节点上。
说明集群运行正常,到此Redis的集群环境和简单实用操作结束。
参考连接:http://www.cnblogs.com/wuxl360/p/5920330.html
redis集群(单机6节点实现)的更多相关文章
- 峰Redis学习(10)Redis 集群(单机多节点集群和多机多节点集群)
单机多节点集群:参考博客:http://blog.java1234.com/blog/articles/326.html 多机多节点集群:参考博客:http://blog.java1234.com/b ...
- Redis 集群环境添加节点失败问题
最近在给公司网管系统Redis集群环境添加节点时候遇到一个问题,提示新增的Node不为空: [root@node00 src]# ./redis-trib.rb add-node --slave -- ...
- windows下配置redis集群,启动节点报错:createing server TCP listening socket *:7000:listen:Unknown error
windows下配置redis集群,启动节点报错:createing server TCP listening socket *:7000:listen:Unknown error 学习了:https ...
- redis集群添加删除节点
Redis3.0集群添加节点 1:首先把需要添加的节点启动 cd /usr/local/cluster/ mkdir 7006 cp /usr/local/cluster/redis.conf /u ...
- redis 集群添加新节点
准备好需要添加的节点:如何创建节点 启动创建的节点: 启动成功: 添加新节点:redis-cli --cluster add-node 127.0.0.1:7006 127.0.0.1:7000 第 ...
- redis集群添加新节点
一.创建节点(接上文) 1.在H1服务器/root/soft目录下创建7002目录 2.将7001目录的配置文件redis.conf拷贝到7002,并修改配置文件的端口 3.进入 redis-5.0. ...
- Redis集群环境各节点无法互相发现与Hash槽分配异常 CLUSTERDOWN Hash slot not served的解决方式
总结/朱季谦 在搭建Redis5.x版本的集群环境曾出现各节点无法互相发现与Hash槽分配异常 CLUSTERDOWN Hash slot not served的情况,故而把解决方式记录下来. 在以下 ...
- springBoot2.*使用redis集群/单机方法
在springboot1.x系列中,其中使用的是jedis,但是到了springboot2.x其中使用的是Lettuce. 此处springboot2.x,所以使用的是Lettuce.关于jedis跟 ...
- 如何确定Redis集群中各个节点的主从关系
1.首先通过命令(以192.168.203.141为例,-c代表集群的意思) ./redis-cli -h 192.168.203.141 -p 8001 -c 2.然后在输入 cluster no ...
- Redis集群中的节点如何保证数据一致
主从复制: 1.redis的复制功能是支持多个数据库之间的数据同步.一类是主数据库(master)一类是从数据库(slave),主数据库可以进行读写操作,当发生写操作的时候自动将数据同步到从数据库,而 ...
随机推荐
- 微信小程序把玩(十七)input组件
原文:微信小程序把玩(十七)input组件 input输入框使用的频率也是比较高的...样式的话自己外面包裹个view自己定义.input属性也不是很多,有需要自己慢慢测,尝试 主要属性: wxml ...
- DBLINK学习
1.连接本地scott用户查看拥有的表 [oracle@ORADG ~]$ sqlplus scott/tiger SQL> select * from tab; TNAME ...
- DELPHI美化界面(2009开始TPanel增加了ParentBackGround)
1.透明问题. 要重新调整界面确实很麻烦,以前用DELPHI开发的界面都很土,和WEB真是没办法比.(我以前用的是DELPHI7),现在回想起来,DELPHI难做的原因是:没有透明控件.所有控件都是不 ...
- 创建第一个ASP.NET MVC项目
创建 新建->项目->展开Web->ASP.NET Web应用程序->MVC->确认 ASP.NET MVC应用程序的目录结构 /Controllers该目录保存处理UR ...
- 关于联合体union的详细解释
1.概述 联合体union的定义方式与结构体一样,但是二者有根本区别. 在结构中各成员有各自的内存空间,一个结构变量的总长度是各成员长度之和.而在“联合”中,各成员共享一段内存空间,一个联合变量的长度 ...
- c# 关于TreeView的一点性能问题
我们要知道,treeview在新增或删除treeNode的时候会进行重绘,这也就是为什么大量数据的时候,treeview很卡.很慢的原因, 那么我们这样 treeview1.BeginUpdate() ...
- asp.net mvc实现微信外H5支付方法
一.微信支付方式介绍 微信提供了各种支付方式,试用于各种不同的支付场景,主要有如下几种: 1.刷卡支付 刷卡支付是用户展示微信钱包内的“刷卡条码/二维码”给商户系统扫描后直接完成支付的模式.主要应用线 ...
- bootstrap模态框篇【遇到的问题】
<div class="modal fade" tabindex="-1" role="dialog"> <div cl ...
- WIN8安装oracle11g时出现不满足最低配置解决办法
Windows8上面安装Oracle11g客户端和服务端时都会出现这样的错误提示:[INS-13001]环境不满足最低要求 产生这种报错的主要原因在于:oracle 11g的配置文件中并没有提供匹配w ...
- ElasticSearch2.3.1环境搭建哪些不为人知的坑
首先说明一点,大家最好不要用什么尝鲜版,用比稳定版就好了,要不麻烦不断,另外出了问题,最好去官网,或者google搜索,因为这样靠谱些,要不现在好多都是低版本的,1.4的什么的,结果按照安装,多少情况 ...