分布式任务调度框架 Azkaban —— Flow 2.0 的使用
一、Flow 2.0 简介
1.1 Flow 2.0 的产生
Azkaban 目前同时支持 Flow 1.0 和 Flow2.0 ,但是官方文档上更推荐使用 Flow 2.0,因为 Flow 1.0 会在将来的版本被移除。Flow 2.0 的主要设计思想是提供 1.0 所没有的流级定义。用户可以将属于给定流的所有 job / properties 文件合并到单个流定义文件中,其内容采用 YAML 语法进行定义,同时还支持在流中再定义流,称为为嵌入流或子流。
1.2 基本结构
项目 zip 将包含多个流 YAML 文件,一个项目 YAML 文件以及可选库和源代码。Flow YAML 文件的基本结构如下:
- 每个 Flow 都在单个 YAML 文件中定义;
- 流文件以流名称命名,如:
my-flow-name.flow; - 包含 DAG 中的所有节点;
- 每个节点可以是作业或流程;
- 每个节点 可以拥有 name, type, config, dependsOn 和 nodes sections 等属性;
- 通过列出 dependsOn 列表中的父节点来指定节点依赖性;
- 包含与流相关的其他配置;
- 当前 properties 文件中流的所有常见属性都将迁移到每个流 YAML 文件中的 config 部分。
官方提供了一个比较完善的配置样例,如下:
config:
user.to.proxy: azktest
param.hadoopOutData: /tmp/wordcounthadoopout
param.inData: /tmp/wordcountpigin
param.outData: /tmp/wordcountpigout
# This section defines the list of jobs
# A node can be a job or a flow
# In this example, all nodes are jobs
nodes:
# Job definition
# The job definition is like a YAMLified version of properties file
# with one major difference. All custom properties are now clubbed together
# in a config section in the definition.
# The first line describes the name of the job
- name: AZTest
type: noop
# The dependsOn section contains the list of parent nodes the current
# node depends on
dependsOn:
- hadoopWC1
- NoOpTest1
- hive2
- java1
- jobCommand2
- name: pigWordCount1
type: pig
# The config section contains custom arguments or parameters which are
# required by the job
config:
pig.script: src/main/pig/wordCountText.pig
- name: hadoopWC1
type: hadoopJava
dependsOn:
- pigWordCount1
config:
classpath: ./*
force.output.overwrite: true
input.path: ${param.inData}
job.class: com.linkedin.wordcount.WordCount
main.args: ${param.inData} ${param.hadoopOutData}
output.path: ${param.hadoopOutData}
- name: hive1
type: hive
config:
hive.script: src/main/hive/showdb.q
- name: NoOpTest1
type: noop
- name: hive2
type: hive
dependsOn:
- hive1
config:
hive.script: src/main/hive/showTables.sql
- name: java1
type: javaprocess
config:
Xms: 96M
java.class: com.linkedin.foo.HelloJavaProcessJob
- name: jobCommand1
type: command
config:
command: echo "hello world from job_command_1"
- name: jobCommand2
type: command
dependsOn:
- jobCommand1
config:
command: echo "hello world from job_command_2"二、YAML语法
想要使用 Flow 2.0 进行工作流的配置,首先需要了解 YAML 。YAML 是一种简洁的非标记语言,有着严格的格式要求的,如果你的格式配置失败,上传到 Azkaban 的时候就会抛出解析异常。
2.1 基本规则
- 大小写敏感 ;
- 使用缩进表示层级关系 ;
- 缩进长度没有限制,只要元素对齐就表示这些元素属于一个层级;
- 使用#表示注释 ;
- 字符串默认不用加单双引号,但单引号和双引号都可以使用,双引号表示不需要对特殊字符进行转义;
- YAML 中提供了多种常量结构,包括:整数,浮点数,字符串,NULL,日期,布尔,时间。
2.2 对象的写法
# value 与 : 符号之间必须要有一个空格
key: value2.3 map的写法
# 写法一 同一缩进的所有键值对属于一个map
key:
key1: value1
key2: value2
# 写法二
{key1: value1, key2: value2}2.3 数组的写法
# 写法一 使用一个短横线加一个空格代表一个数组项
- a
- b
- c
# 写法二
[a,b,c]2.5 单双引号
支持单引号和双引号,但双引号不会对特殊字符进行转义:
s1: '内容\n 字符串'
s2: "内容\n 字符串"
转换后:
{ s1: '内容\\n 字符串', s2: '内容\n 字符串' }2.6 特殊符号
一个 YAML 文件中可以包括多个文档,使用 --- 进行分割。
2.7 配置引用
Flow 2.0 建议将公共参数定义在 config 下,并通过 ${} 进行引用。
三、简单任务调度
3.1 任务配置
新建 flow 配置文件:
nodes:
- name: jobA
type: command
config:
command: echo "Hello Azkaban Flow 2.0."在当前的版本中,Azkaban 同时支持 Flow 1.0 和 Flow 2.0,如果你希望以 2.0 的方式运行,则需要新建一个 project 文件,指明是使用的是 Flow 2.0:
azkaban-flow-version: 2.03.2 打包上传

3.3 执行结果
由于在 1.0 版本中已经介绍过 Web UI 的使用,这里就不再赘述。对于 1.0 和 2.0 版本,只有配置方式有所不同,其他上传执行的方式都是相同的。执行结果如下:
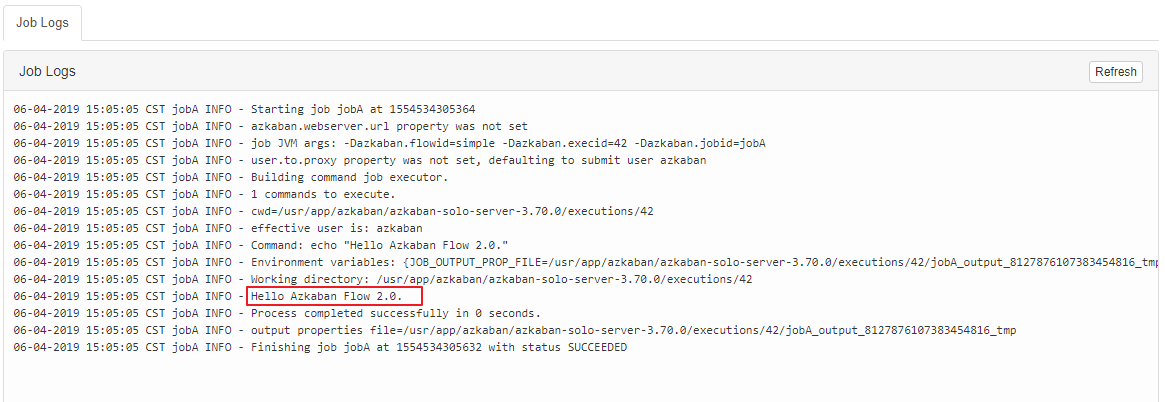
四、多任务调度
和 1.0 给出的案例一样,这里假设我们有五个任务(jobA——jobE), D 任务需要在 A,B,C 任务执行完成后才能执行,而 E 任务则需要在 D 任务执行完成后才能执行,相关配置文件应如下。可以看到在 1.0 中我们需要分别定义五个配置文件,而在 2.0 中我们只需要一个配置文件即可完成配置。
nodes:
- name: jobE
type: command
config:
command: echo "This is job E"
# jobE depends on jobD
dependsOn:
- jobD
- name: jobD
type: command
config:
command: echo "This is job D"
# jobD depends on jobA、jobB、jobC
dependsOn:
- jobA
- jobB
- jobC
- name: jobA
type: command
config:
command: echo "This is job A"
- name: jobB
type: command
config:
command: echo "This is job B"
- name: jobC
type: command
config:
command: echo "This is job C"五、内嵌流
Flow2.0 支持在一个 Flow 中定义另一个 Flow,称为内嵌流或者子流。这里给出一个内嵌流的示例,其 Flow 配置如下:
nodes:
- name: jobC
type: command
config:
command: echo "This is job C"
dependsOn:
- embedded_flow
- name: embedded_flow
type: flow
config:
prop: value
nodes:
- name: jobB
type: command
config:
command: echo "This is job B"
dependsOn:
- jobA
- name: jobA
type: command
config:
command: echo "This is job A"内嵌流的 DAG 图如下:
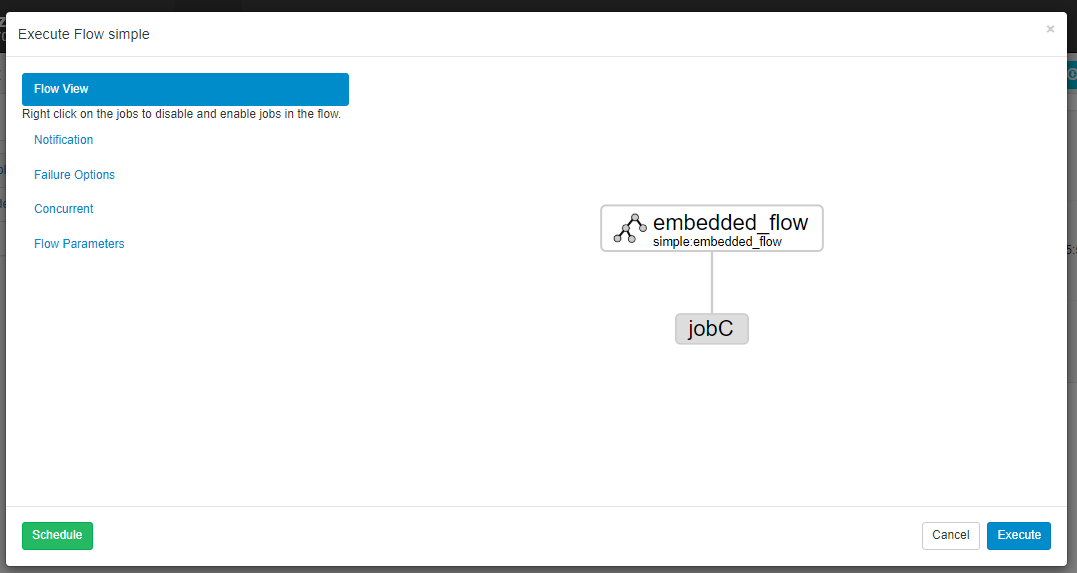
执行情况如下:

参考资料
更多大数据系列文章可以参见 GitHub 开源项目: 大数据入门指南
分布式任务调度框架 Azkaban —— Flow 2.0 的使用的更多相关文章
- 分布式任务调度框架 Azkaban —— Flow 1.0 的使用
一.简介 Azkaban 主要通过界面上传配置文件来进行任务的调度.它有两个重要的概念: Job: 你需要执行的调度任务: Flow:一个获取多个 Job 及它们之间的依赖关系所组成的图表叫做 Flo ...
- Azkaban学习之路(四)—— Azkaban Flow 2.0的使用
一.Flow 2.0 简介 1.1 Flow 2.0 的产生 Azkaban 目前同时支持 Flow 1.0 和 Flow2.0 ,但是官方文档上更推荐使用Flow 2.0,因为Flow 1.0会在将 ...
- Azkaban Flow 2.0 使用简介
官方建议使用Flow 2.0来创建Azkaban工作流,且Flow 1.0将被弃用 目录 目录 一.简单的Flow 1. 新建 flow20.project 文件 2. 新建 .flow 文件 3. ...
- 新一代分布式任务调度框架:当当elastic-job开源项目的10项特性
作者简介: 张亮,当当网架构师.当当技术委员会成员.消息中间件组负责人.对架构设计.分布式.优雅代码等领域兴趣浓厚.目前主导当当应用框架ddframe研发,并负责推广及撰写技术白皮书. 一.为什么 ...
- Azkaban学习之路(三)—— Azkaban Flow 1.0 的使用
一.简介 Azkaban主要通过界面上传配置文件来进行任务的调度.它有两个重要的概念: Job: 你需要执行的调度任务: Flow:一个获取多个Job及它们之间的依赖关系所组成的图表叫做Flow. 目 ...
- 【niubi-job——一个分布式的任务调度框架】----niubi-job这下更牛逼了!
niubi-job迎来第一次重大优化 niubi-job是一款专门针对定时任务所设计的分布式任务调度框架,它可以进行动态发布任务,并且有超高的可用性保证. 有多少人半夜被叫起来查BUG,结果差到最后发 ...
- Java任务调度框架之分布式调度框架XXL-Job介绍
Java任务调度框架之分布式调度框架XXL-Job介绍及快速入门 调度器使用场景: Java开发中经常会使用到定时任务:比如每月1号凌晨生成上个月的账单.比如每天凌晨1点对上一天的数据进行对账操作 ...
- 【niubi-job——一个分布式的任务调度框架】----安装教程
niubi-job是什么 niubi-job是LZ耗时三个星期,费尽心血打造的一个具备高可靠性以及水平扩展能力的分布式任务调度框架,采用quartz作为底层的任务调度管理器,zookeeper做集群的 ...
- ElasticJob分布式任务调度应用v2.5.2
为何要使用分布式任务调度 **本人博客网站 **IT小神 www.itxiaoshen.com 演示项目源码地址** https://gitee.com/yongzhebuju/spring-task ...
随机推荐
- codemirror使用
JS使用 使用bower下载 bower i codemirror 引入样式文件 <link rel="stylesheet" type="text/css&quo ...
- CCNA笔记(一)
R1#enable R1#configure terminal R1(config)#interface fastEthernet 0/0R1(config-if)#ip address 12.1.1 ...
- 关于Hack术语方面
1.肉鸡 所谓“肉鸡”是一种很形象的比喻,比喻那些可以随意被我们控制的电脑,对方可以是WINDOWS系统,也可以是UNIX/LINUX系统,可以是普通的个人电脑,也可以是大型的服务器,我们 ...
- golang "[]uint8" to string
关于Uinit8和Byte: The Go Programming Language Specification Numeric types uint8 the set of all unsigned ...
- ioc和aop的区别
IoC,(Inverse of Control)控制反转,其包含两个内容:其一是控制,其二是反转.在程序中,被调用类的选择控制权从调用它的类中移除,转交给第三方裁决.这个第三方指的就是Spring的容 ...
- 【iOS】获取项目名和版本号
iOS 开发中,有时候需要获取项目名和版本号,示例代码如下: -(void)getProjectNameAndVersion{ appName = [[[NSBundle mainBundle] in ...
- 爬虫环境搭建及 scrapy 启动
创建虚拟环境 C:\Users\Toling>mkvirtualenv article 这个是普通的创建虚拟环境,但是实际开发中可能会使用python2或python3所以我们需要指定开发的环境 ...
- UVA11388 GCD LCM
(链接点这儿) 题目: The GCD of two positive integers is the largest integer that divides both the integers w ...
- JAVA基础知识(六)Java 静态多分派&动态单分派
1.分派发生在编译期和运行期,编译期的分派为静态分派,运行期的为动态分派. 2.编译期是根据对象声明的类型来选择方法,运行期是根据对象实际类型来选择方法. 3.单分派和多分派取决于宗量, 方法调用者和 ...
- mybatis学习笔记(一)
mybatis学习笔记 mybatis简介 Mybatis 开源免费框架.原名叫iBatis,2010在googlecode,2013年迁移到 github 作用: 数据访问层框架,底层对JDBC进行 ...