并查集(不相交集合)详解与java实现
@
认识并查集
对于并查集(不相交集合),很多人会感到很陌生,没听过或者不是特别了解。实际上并查集是一种挺高效的数据结构。实现简单,只是所有元素统一遵从一个规律所以让办事情的效率高效起来。
对于定意义,百科上这么定义的:
并查集,在一些有N个元素的集合应用问题中,我们通常是在开始时让每个元素构成一个单元素的集合,然后按一定顺序将属于同一组的元素所在的集合合并,其间要反复查找一个元素在哪个集合中。其特点是看似并不复杂,但数据量极大,若用正常的数据结构来描述的话,往往在空间上过大,计算机无法承受;即使在空间上勉强通过,运行的时间复杂度也极高,根本就不可能在比赛规定的运行时间(1~3秒)内计算出试题需要的结果,只能用并查集来描述。
并查集是一种树型的数据结构,用于处理一些不相交集合(Disjoint Sets)的合并及查询问题。常常在使用中以森林来表示。
并查集解析
基本思想
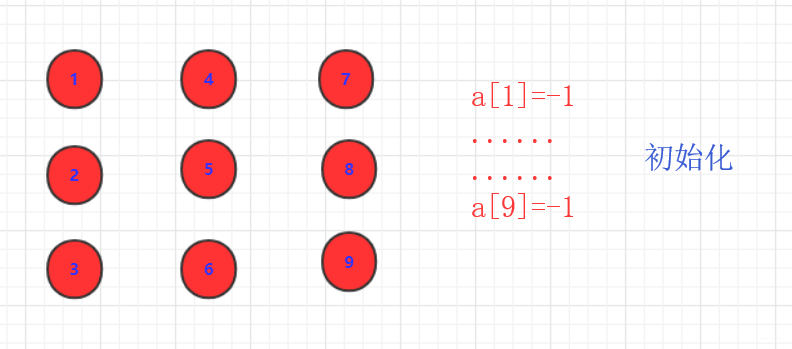
- 初始化,一个森林每个都为独立。通常用数组表示,每个值初始为-1。
各自为根
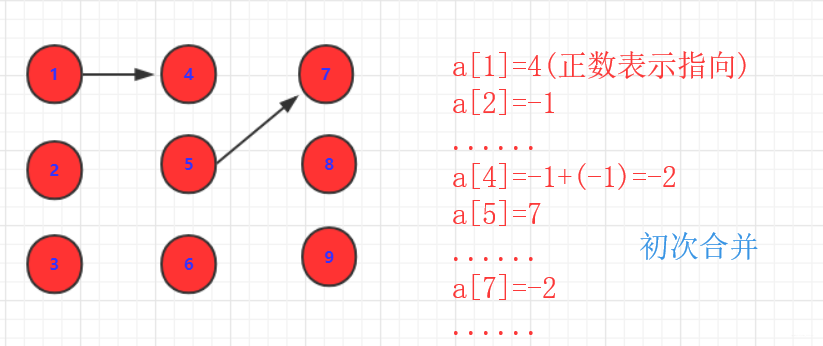
join(a,b)操作。a,b两个集合合并。注意这里的a,并不是a,b合并,而是a,b的集合合并。这就派生了一些情况:- a,b如果是独立的(没有和其他合并),那么直接a指向b(或者b指向a),即
data[a]=b;同时为了表示这个集合有多少个,原本-1的b再次-1.即data[b]=-2.表示以b为父亲的节点有|-2|个。
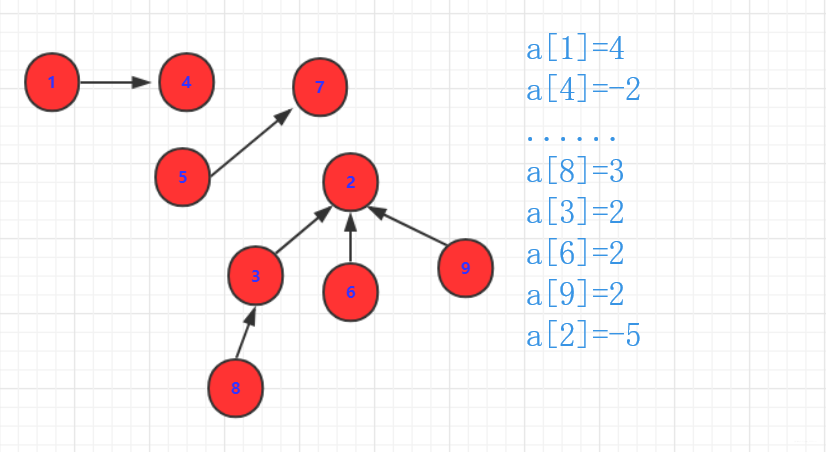
- a,b如果有集合(可能有父亲,可能自己是根),那么我们当然
不能直接操作a,b(因为a,b可能已经指向别人了.)那么我们只能操作a,b的祖先。因为a,b的祖先是没有指向的(即数据为负值表示大小)。那么他们首先一个负值要加到另外一个上面去。另外这个数值要变成指向的那个表示联系。
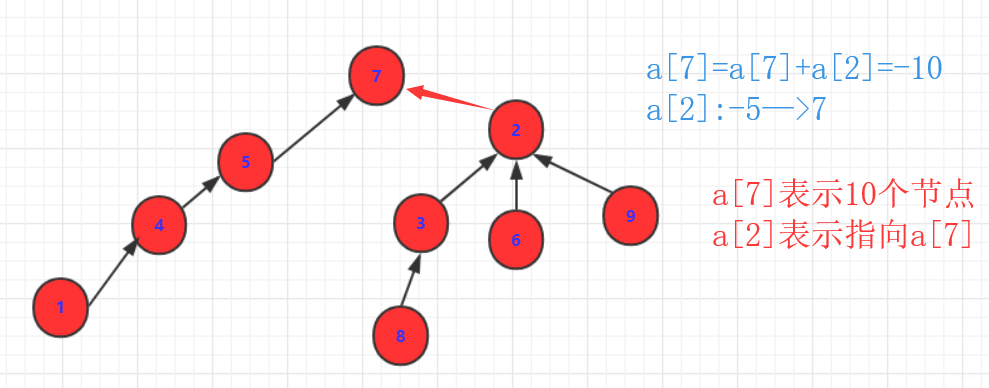
对于上述你可能会有疑问:
如何查看a,b是否在一个集合?
- 查看是否在一个集合,只需要查看
节点根祖先的结果是否相同即可。因为只有根的数值是负的,而其他都是正数表示指向的元素。所以只需要一直寻找直到不为正数进行比较即可!
a,b合并,究竟是a的祖先合并在b的祖先上,还是b的祖先合并在a上?
- 这里会遇到两种情况,这个选择也是非常重要的。你要弄明白一点:树的高度+1的化那么整个元素查询的效率都会降低!
所以我们通常是:小数指向大树(或者低树指向高树),这个使得查询效率能够增加!
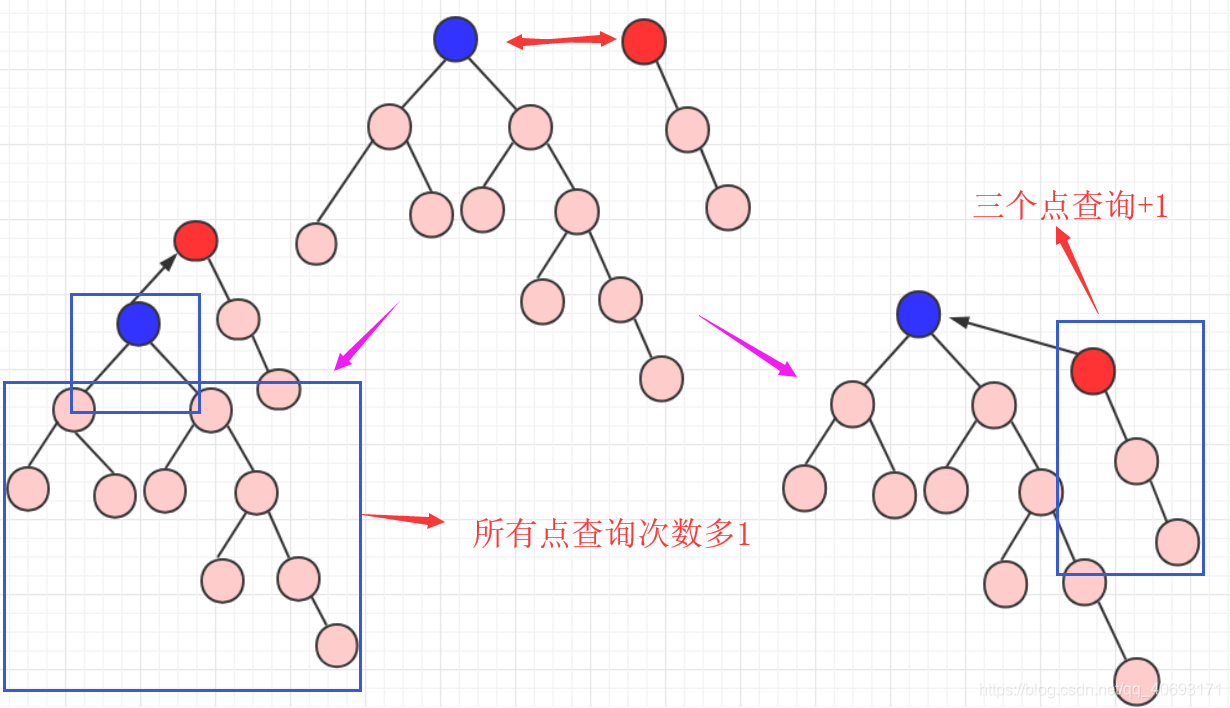
当然,在高度和数量的选择上,还需要你自己选择和考虑。
其他路径压缩?
每次查询,自下向上。当我们调用递归的时候,可以顺便压缩路径,因为我们查找一个元素其实只需要直到它的祖先,所以当他距离祖先近那么下次查询就很快。并且压缩路径的代价并不大!
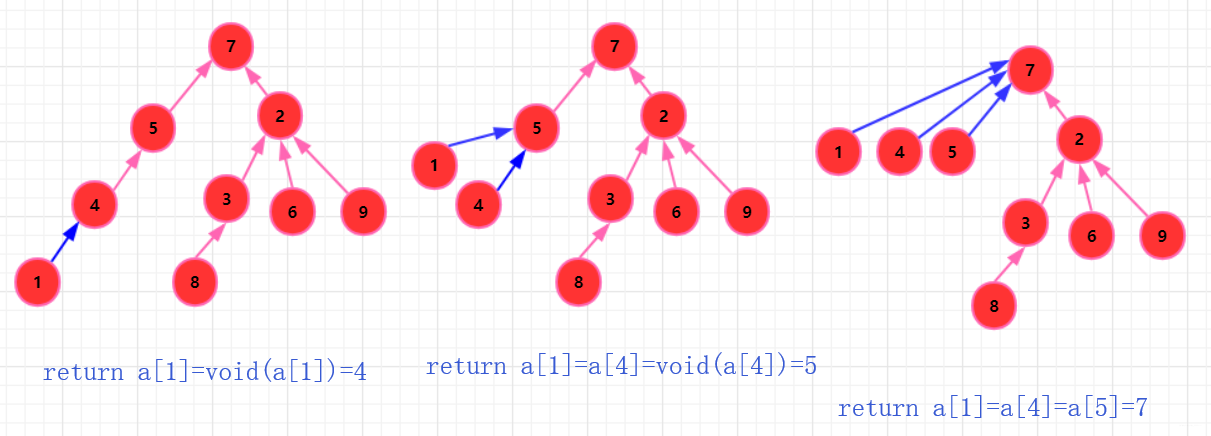
代码实现
并查集实现起来较为简单,直接贴代码!
package 并查集不想交集合;
import java.util.Scanner;
public class DisjointSet {
static int tree[]=new int[100000];//假设有500个值
public DisjointSet() {set(this.tree);}
public DisjointSet(int tree[])
{
this.tree=tree;
set(this.tree);
}
public void set(int a[])//初始化所有都是-1 有两个好处,这样他们指向-1说明是自己,第二,-1代表当前森林有-(-1)个
{
int l=a.length;
for(int i=0;i<l;i++)
{
a[i]=-1;
}
}
public int search(int a)//返回头节点的数值
{
if(tree[a]>0)//说明是子节点
{
return tree[a]=search(tree[a]);//路径压缩
}
else
return a;
}
public int value(int a)//返回a所在树的大小(个数)
{
if(tree[a]>0)
{
return value(tree[a]);
}
else
return -tree[a];
}
public void union(int a,int b)//表示 a,b所在的树合并
{
int a1=search(a);//a根
int b1=search(b);//b根
if(a1==b1) {System.out.println(a+"和"+b+"已经在一棵树上");}
else {
if(tree[a1]<tree[b1])//这个是负数,为了简单减少计算,不在调用value函数
{
tree[a1]+=tree[b1];//个数相加 注意是负数相加
tree[b1]=a1; //b树成为a的子树,直接指向a;
}
else
{
tree[b1]+=tree[a1];//个数相加 注意是负数相加
tree[a1]=b1; //b树成为a的子树,直接指向a;
}
}
}
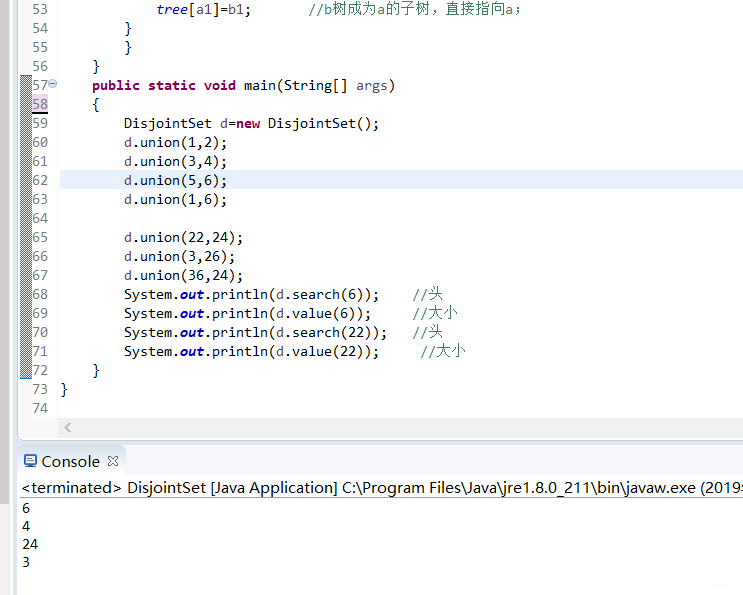
public static void main(String[] args)
{
DisjointSet d=new DisjointSet();
d.union(1,2);
d.union(3,4);
d.union(5,6);
d.union(1,6);
d.union(22,24);
d.union(3,26);
d.union(36,24);
System.out.println(d.search(6)); //头
System.out.println(d.value(6)); //大小
System.out.println(d.search(22)); //头
System.out.println(d.value(22)); //大小
}
}
结语
- 并查集属于简单但是很高效率的数据结构。在集合中经常会遇到。如果不采用并查集而传统暴力效率太低,而不被采纳。
- 另外,
并查集还广泛用于迷宫游戏中,下面有机会可以介绍用并查集实现一个走迷宫小游戏。大家欢迎关注! - 最后,欢迎大家关注笔者公众号,一起学习、交流!
笔者学习资源也放置公众号和大家一起分享!

并查集(不相交集合)详解与java实现的更多相关文章
- poj1417 true liars(并查集 + DP)详解
这个题做了两天了.首先用并查集分类是明白的, 不过判断是否情况唯一刚开始用的是搜索.总是超时. 后来看别人的结题报告, 才恍然大悟判断唯一得用DP. 题目大意: 一共有p1+p2个人,分成两组,一组p ...
- Java集合详解1:一文读懂ArrayList,Vector与Stack使用方法和实现原理
本文非常详尽地介绍了Java中的三个集合类 ArrayList,Vector与Stack <Java集合详解系列>是我在完成夯实Java基础篇的系列博客后准备开始写的新系列. 这些文章将整 ...
- Solr系列二:solr-部署详解(solr两种部署模式介绍、独立服务器模式详解、SolrCloud分布式集群模式详解)
一.solr两种部署模式介绍 Standalone Server 独立服务器模式:适用于数据规模不大的场景 SolrCloud 分布式集群模式:适用于数据规模大,高可靠.高可用.高并发的场景 二.独 ...
- Java集合详解6:TreeMap和红黑树
Java集合详解6:TreeMap和红黑树 初识TreeMap 之前的文章讲解了两种Map,分别是HashMap与LinkedHashMap,它们保证了以O(1)的时间复杂度进行增.删.改.查,从存储 ...
- Java集合详解8:Java集合类细节精讲,细节决定成败
<Java集合详解系列>是我在完成夯实Java基础篇的系列博客后准备开始写的新系列. 这些文章将整理到我在GitHub上的<Java面试指南>仓库,更多精彩内容请到我的仓库里查 ...
- Java集合详解7:一文搞清楚HashSet,TreeSet与LinkedHashSet的异同
<Java集合详解系列>是我在完成夯实Java基础篇的系列博客后准备开始写的新系列. 这些文章将整理到我在GitHub上的<Java面试指南>仓库,更多精彩内容请到我的仓库里查 ...
- Java集合详解6:这次,从头到尾带你解读Java中的红黑树
<Java集合详解系列>是我在完成夯实Java基础篇的系列博客后准备开始写的新系列. 这些文章将整理到我在GitHub上的<Java面试指南>仓库,更多精彩内容请到我的仓库里查 ...
- Java集合详解4:一文读懂HashMap和HashTable的区别以及常见面试题
<Java集合详解系列>是我在完成夯实Java基础篇的系列博客后准备开始写的新系列. 这些文章将整理到我在GitHub上的<Java面试指南>仓库,更多精彩内容请到我的仓库里查 ...
- Java集合详解3:一文读懂Iterator,fail-fast机制与比较器
<Java集合详解系列>是我在完成夯实Java基础篇的系列博客后准备开始写的新系列. 这些文章将整理到我在GitHub上的<Java面试指南>仓库,更多精彩内容请到我的仓库里查 ...
随机推荐
- 爬虫的盗亦有道Robots协议
爬虫的规定 Robots协议 网站开发者对于网络爬虫的规范的公告,你可以不遵守可能存在法律风险,但尽量去遵守 Robots协议:在网页的根目录+robots.txt Robots协议的基本语法: #注 ...
- C语言入门2-程序设计的灵魂—算法及Raptor的应用
一. 什么是算法(5个特性) 算法就是 解决问题的方法和步骤. 算法为解决一个具体问题而采取的确定的 有限的 执行步骤 ,仅指 计算机 能执行的算法. 算法是程序设计的灵魂和核心 ...
- linux初学者-常用基本命令篇
linux系统中有着许许多多的命令,并且软件也有可能自带命令,要想全部了解这些命令是很困难的,但是有一些基本命令是在平时的学习工作中应用的很广泛的.以下简要介绍几种linux系统中的常用命令. 1.m ...
- tcp 3次握手四次挥手
转载link:http://www.jianshu.com/p/9968b16b607e 最近在复习计算机网络,看到TCP这一章,总结一下. 建立TCP需要三次握手才能建立,而断开连接则需要四次握手. ...
- flink入门实战总结
随着大数据技术在各行各业的广泛应用,要求能对海量数据进行实时处理的需求越来越多,同时数据处理的业务逻辑也越来越复杂,传统的批处理方式和早期的流式处理框架也越来越难以在延迟性.吞吐量.容错能力以及使用便 ...
- solr集群
一.所需环境 1.linux系统(内存分大点) 2.JDK 3.zookeeper 4.solr 二.安装zookeeper 1.此次安装3个zookeeper 2.tar -zxf zookeepe ...
- Hack The Box Web Pentest 2019
[20 Points] Emdee five for life [by L4mpje] 问题描述: Can you encrypt fast enough? 初始页面,不管怎么样点击Submit都会显 ...
- 实战SpringCloud响应式微服务系列教程(第二章)
接上一篇:实战SpringCloud响应式微服务系列教程(第一章) 1.1.2背压 背压是响应式编程的核心概念,这一节也是我们了解响应式编程的重点. 1.背压的机制 在生产者/消费者模型中,我们意识到 ...
- 【Android】Theme.AppCompat.Light 问题
Android 开发的 styles.xml 文件中遇到了这个问题: <style name="AppBaseTheme" parent="Theme.AppCom ...
- PPT | Docker定义存储-让应用无痛运行
编者注: 本文为9月27日晚上8点有容云平台存储架构师张朝潞在腾讯课堂中演讲的PPT,本次课堂为有容云主办的线上直播Docker Live时代●Online Meetup-第三期:Docker定义存储 ...