Spark小问题合集
1)在win7下使用spark shell运行spark程序,通过以下形式读取文件时
sc.sequenceFile[Int,String]("./sparkF")
偶尔会出现“Input path does not exist”,原因是没有使用“file:///”表示文件时本地文件系统上的文件,相对路径形式如下:
sc.sequenceFile[Int,String]("file:///.\\sparkF")
不过,还可以使用绝对路径,更保险些。
2)在Ubuntu上读取文件,貌似三种都可以。参考0
sc.sequenceFile[Int,String]("file:///home/hadoop/sparkF")
sc.sequenceFile[Int,String]("file://home/hadoop/sparkF")
sc.sequenceFile[Int,String]("file:/home/hadoop/sparkF")
3)可以使用println()打印某些变量值,然后在Exector对应的stdout可以看到打印的内容
4)有时候电脑IP没有固定的话,从教研室把电脑背回来,在IDEA上单机运行spark程序就失败了,提示如下:
ERROR NettyTransport: failed to bind to host.home/192.168.1.124:
“192.168.1.124”是在教研室的IP。出错的原因就是,创建sparkContext时,在“SparkEnv.scala”中,可以看到“spark.driver.host”对应值是:
192.1681.1.124//正好是教研室地址,与当前地址不同,自然报错
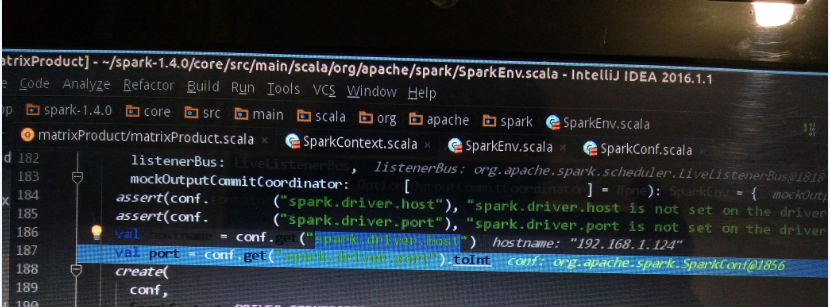
修改代码即可,原先代码如下:
val conf2=new SparkConf().setAppName("matrixProduct").setMaster(args())
修改后代码如下:
val conf2=new SparkConf().setAppName("matrixProduct").setMaster(args()).set("spark.local.ip","127.0.0.1")
.set("spark.driver.host","127.0.0.1")
5)有时候运行spark作业会提示“WARN TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient memory”,原因是申请的Exector内存比节点自身内存还要大。访问web界面中8080端口,看到每个节点的RAM是979MB,而提交作业时使用关键字 --executor-memory 1g,这样就超过了自身内存,所以报错。参考
6)使用IDEA调试spark程序时,在控制台窗口会打印出很多的“INFO,WARN”类信息,这些信息,我们并不需要,我们只需要打印出“ERROR”信息,解决方法如下:
1.首先生成spark_Home/conf中的“log4j.properties“文件,方法如下:
Even simpler you just cd SPARK_HOME/conf
then mv log4j.properties.template log4j.properties then open log4j.properties and change all INFO to ERROR.
Here SPARK_HOME is the root directory of your spark installation.
其实生成了“log4j.properties”文件之后,当我们使用集群的方式运行spark程序时,就可以在控制台屏蔽掉那些”INFO“和”WARN“类的信息,但是如果是在IDEA本地调试spark程序时,”INFO“ ”WARN“类信息仍然会打印出来,解决方法参考以下方法
2.在完成了上述步骤之后,为了保证在IDEA中调试spark程序时避免打印”INFO“、”WARN“类信息,需要在spark程序在添加如下代码:
import org.apache.log4j.PropertyConfigurator
PropertyConfigurator.configure("path to log4j.properties")
sparkconf.set("log4j.configuration", "path to log4j.properties");
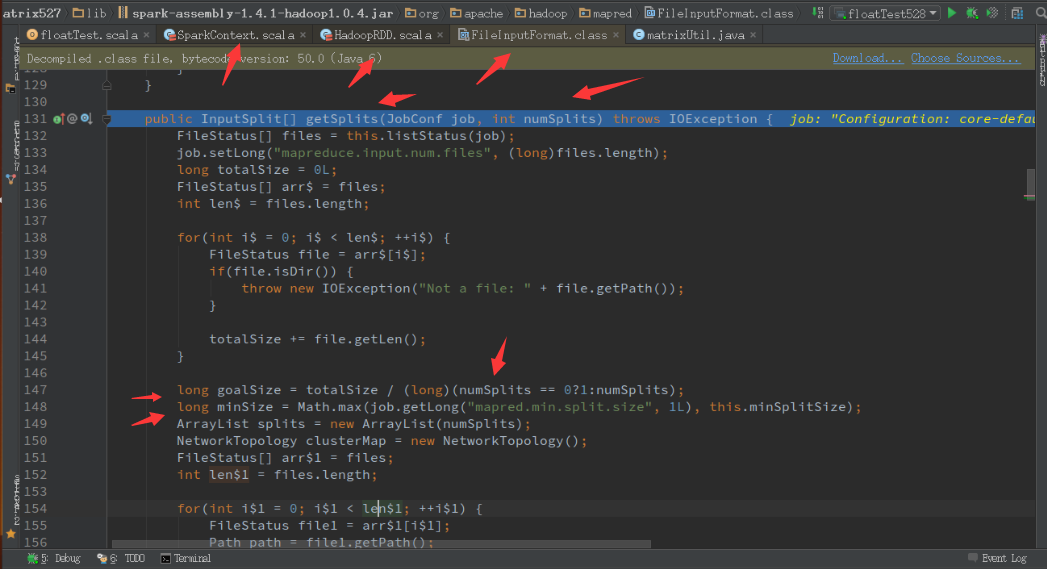
7)Spark下SequenceFile文件分片数量的确定
http://www.cnblogs.com/gaoze/p/5208970.html
对于在spark中使用Sequence,其分片数量的计算方式与hadoop中相同,其实就是调用了hadoop中的实现来计算,计算goalSize,minSize,maxSize。如下图:
8)sortBy和sortByKey函数
http://www.iteblog.com/archives/1240
9)遍历了一次 Iterable 之后,再次遍历的时候,数据都没了
https://my.oschina.net/leejun2005/blog/131744
Spark小问题合集的更多相关文章
- html 小游戏合集(1.0)
最近做了个小游戏合集,有点沙雕,毕竟是1.0,将就看看. <!DOCTYPE html> <html> <head> <meta charset=" ...
- spark 入门教程合集
看到一篇不错的 spark 入门教程的合集,在此记录一下 http://www.cnblogs.com/shishanyuan/p/4699644.html
- js小功能合集:计算指定时间距今多久、评论树核心代码、字符串替换和去除。
1.计算指定时间距今多久 var date1=new Date('2017/02/08 17:00'); //开始时间 var date2=new Date(); //当前时间 var date3=d ...
- Vue-小demo、小效果 合集(更新中...)
(腾讯课堂学习小demo:https://ke.qq.com/course/256052) 一.简单的指令应用 --打击灭火器 图片素材点击腾讯课堂的链接获取 html: <!DOC ...
- 小tips合集
No. 1 同一个文本文件里的行结束符如果不一致,比如有些行结束符是0D0A-Windows风格的,而有些行又是UNIX风格的0A,在这种混杂情况下,VIM将非UNIX风格的显示为^M,但如果都是0D ...
- Android小项目合集(经典教程)包含十五个Android开发应用实例
http://www.cnblogs.com/aimeng/archive/2012/03/28/2422435.html
- 【前端学习笔记】JavaScript 小案例合集
获取一个0-9的随机数: Math.round(Math.random()*9); 去除数组中重复的元素: var arr=[1,3,5,4,3,3,1,4] function editArr(arr ...
- 常见Z纯CSS小样式合集(三角形)
三角形 .sanjiao{ width:0px; height: 0px; overflow: hidden; border-width: 100px; border-color: transpare ...
- Nginx小功能合集
13.1. 跨域处理 问题由来:浏览器拒绝执行其它域名下的ajax运作 ---如果浏览器在static.enjoy.com对应的html页面内,发起ajax请求偷盗www.enjoy.com域名下的内 ...
随机推荐
- 用spring的@Validated注解和org.hibernate.validator.constraints.*的一些注解在后台完成数据校验
这个demo主要是让spring的@Validated注解和hibernate支持JSR数据校验的一些注解结合起来,完成数据校验.这个demo用的是springboot. 首先domain对象Foo的 ...
- 一串跟随鼠标的DIV
div跟随鼠标移动的函数: <!DOCTYPE HTML><html><head> <meta charset="utf-8"> & ...
- [ZOJ2341]Reactor Cooling解题报告|带上下界的网络流|无源汇的可行流
Reactor Cooling The terrorist group leaded by a well known international terrorist Ben Bladen is bul ...
- [BZOJ3238][Ahoi2013]差异解题报告|后缀数组
Description 先分析一下题目,我们显然可以直接算出sigma(len[Ti]+len[Tj])的值=(n-1)*n*(n+1)/2 接着就要去算这个字符串中所有后缀的两两最长公共前缀总和 首 ...
- hdu 3003 Pupu
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=3003 题目大意:一种动物身上有n种不同的皮肤,每种皮肤有透明很不透明两种状态,经过一天的日晒,透明的可 ...
- A way escape rbash
hacker@beta:~$ ls -rbash: /usr/bin/python: restricted: cannot specify `/' in command names ryuu@beta ...
- algorithm ch6 priority queque
堆数据结构的一个重要用处就是:最为高效的优先级队列.优先级队列分为最大优先级队列和最小优先级队列,其中最大优先级队列的一个应用实在一台分时计算机上进行作业的调度.当用堆来实现优先级队列时,需要在队中的 ...
- mysql五-2:多表查询
一 介绍 本节主题 多表连接查询 复合条件连接查询 子查询 准备表 company.employeecompany.department #建表 create table department( id ...
- Oracle基础 12 对象 objects 同义词/序列/试图/索引
--创建同义词create public synonym employees for hr.employees; --公共同义词需要 create public synonym 权限 表的所有用户授 ...
- IPython Notebook error: Error loading notebook
打开jupyter突然报错: An unknown error occurred while loading this notebook. This version can load notebook ...