06-Mysql数据库----表的操作
本节掌握
- 存储引擎介绍(了解)
- 表的增删改查
一、存储引擎(了解)
前几节我们知道mysql中建立的库===》文件夹,库中的表====》文件
现实生活中我们用来存储数据的文件有不同的类型,每种文件类型对应各自不同的处理机制:比如处理文本用txt类型,处理表格用excel,处理图片用png等
数据库中的表也应该有不同的类型,表的类型不同,会对应mysql不同的存取机制,表类型又称为存储引擎。
ps: 存储引擎说白了就是如何存储数据、如何为存储的数据建立索引和如何更新、查询数据等技术的实现方法。因为在关系数据库中数据的存储是以表的形式存储的,所以存储引擎也可以称为表类型(即存储和操作此表的类型)
在Oracle 和SQL Server等数据库中只有一种存储引擎,所有数据存储管理机制都是一样的。而MySql
数据库提供了多种存储引擎。用户可以根据不同的需求为数据表选择不同的存储引擎,用户也可以根据
自己的需要编写自己的存储引擎
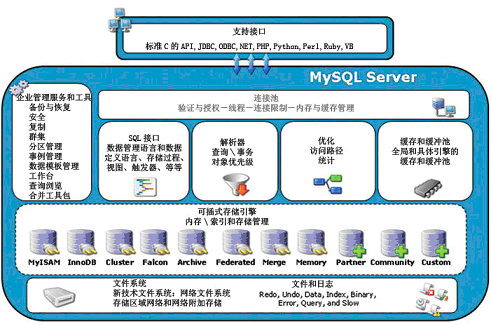
SQL 解析器、SQL 优化器、缓冲池、存储引擎等组件在每个数据库中都存在,但不是每 个数据库都有这么多存储引擎。MySQL 的插件式存储引擎可以让存储引擎层的开发人员设 计他们希望的存储层,例如,有的应用需要满足事务的要求,有的应用则不需要对事务有这 么强的要求 ;有的希望数据能持久存储,有的只希望放在内存中,临时并快速地提供对数据 的查询。
二、mysql支持的存储引擎
mysql> show engines\G;# 查看所有支持的引擎
mysql> show variables like 'storage_engine%'; # 查看正在使用的存储引擎
1、InnoDB 存储引擎----常用
支持事务,其设计目标主要面向联机事务处理(OLTP)的应用。其
特点是行锁设计、支持外键,并支持类似 Oracle 的非锁定读,即默认读取操作不会产生锁。 从 MySQL 5.5.8 版本开始是默认的存储引擎。
InnoDB 存储引擎将数据放在一个逻辑的表空间中,这个表空间就像黑盒一样由 InnoDB 存储引擎自身来管理。从 MySQL 4.1(包括 4.1)版本开始,可以将每个 InnoDB 存储引擎的 表单独存放到一个独立的 ibd 文件中。此外,InnoDB 存储引擎支持将裸设备(row disk)用 于建立其表空间。
InnoDB 通过使用多版本并发控制(MVCC)来获得高并发性,并且实现了 SQL 标准 的 4 种隔离级别,默认为 REPEATABLE 级别,同时使用一种称为 netx-key locking 的策略来 避免幻读(phantom)现象的产生。除此之外,InnoDB 存储引擎还提供了插入缓冲(insert buffer)、二次写(double write)、自适应哈希索引(adaptive hash index)、预读(read ahead) 等高性能和高可用的功能。
对于表中数据的存储,InnoDB 存储引擎采用了聚集(clustered)的方式,每张表都是按 主键的顺序进行存储的,如果没有显式地在表定义时指定主键,InnoDB 存储引擎会为每一 行生成一个 6 字节的 ROWID,并以此作为主键。
InnoDB 存储引擎是 MySQL 数据库最为常用的一种引擎,Facebook、Google、Yahoo 等 公司的成功应用已经证明了 InnoDB 存储引擎具备高可用性、高性能以及高可扩展性。对其 底层实现的掌握和理解也需要时间和技术的积累。如果想深入了解 InnoDB 存储引擎的工作 原理、实现和应用,可以参考《MySQL 技术内幕:InnoDB 存储引擎》一书。
2、MyISAM 存储引擎----常用
不支持事务、表锁设计、支持全文索引,主要面向一些 OLAP 数 据库应用,在 MySQL 5.5.8 版本之前是默认的存储引擎(除 Windows 版本外)。数据库系统 与文件系统一个很大的不同在于对事务的支持,MyISAM 存储引擎是不支持事务的。究其根 本,这也并不难理解。用户在所有的应用中是否都需要事务呢?在数据仓库中,如果没有 ETL 这些操作,只是简单地通过报表查询还需要事务的支持吗?此外,MyISAM 存储引擎的 另一个与众不同的地方是,它的缓冲池只缓存(cache)索引文件,而不缓存数据文件,这与 大多数的数据库都不相同。
3、NDB 存储引擎
年,MySQL AB 公司从 Sony Ericsson 公司收购了 NDB 存储引擎。 NDB 存储引擎是一个集群存储引擎,类似于 Oracle 的 RAC 集群,不过与 Oracle RAC 的 share everything 结构不同的是,其结构是 share nothing 的集群架构,因此能提供更高级别的 高可用性。NDB 存储引擎的特点是数据全部放在内存中(从 5.1 版本开始,可以将非索引数 据放在磁盘上),因此主键查找(primary key lookups)的速度极快,并且能够在线添加 NDB 数据存储节点(data node)以便线性地提高数据库性能。由此可见,NDB 存储引擎是高可用、 高性能、高可扩展性的数据库集群系统,其面向的也是 OLTP 的数据库应用类型。
4、Memory 存储引擎----常用
正如其名,Memory 存储引擎中的数据都存放在内存中,数据库重 启或发生崩溃,表中的数据都将消失。它非常适合于存储 OLTP 数据库应用中临时数据的临时表,也可以作为 OLAP 数据库应用中数据仓库的维度表。Memory 存储引擎默认使用哈希 索引,而不是通常熟悉的 B+ 树索引。
5、Infobright 存储引擎
第三方的存储引擎。其特点是存储是按照列而非行的,因此非常 适合 OLAP 的数据库应用。其官方网站是 http://www.infobright.org/,上面有不少成功的数据 仓库案例可供分析。
6、NTSE 存储引擎
网易公司开发的面向其内部使用的存储引擎。目前的版本不支持事务, 但提供压缩、行级缓存等特性,不久的将来会实现面向内存的事务支持。
7、BLACKHOLE----常用
黑洞存储引擎,可以应用于主备复制中的分发主库。
MySQL 数据库还有很多其他存储引擎,上述只是列举了最为常用的一些引擎。如果 你喜欢,完全可以编写专属于自己的引擎,这就是开源赋予我们的能力,也是开源的魅 力所在。
指定表类型/存储引擎
create table t1(id int)engine=innodb;# 默认不写就是innodb
小练习:
创建四张表,分别使用innodb,myisam,memory,blackhole存储引擎,进行插入数据测试
create table t1(id int)engine=innodb;
create table t2(id int)engine=myisam;
create table t3(id int)engine=memory;
create table t4(id int)engine=blackhole;
查看data文件下db1数据库中的文件:
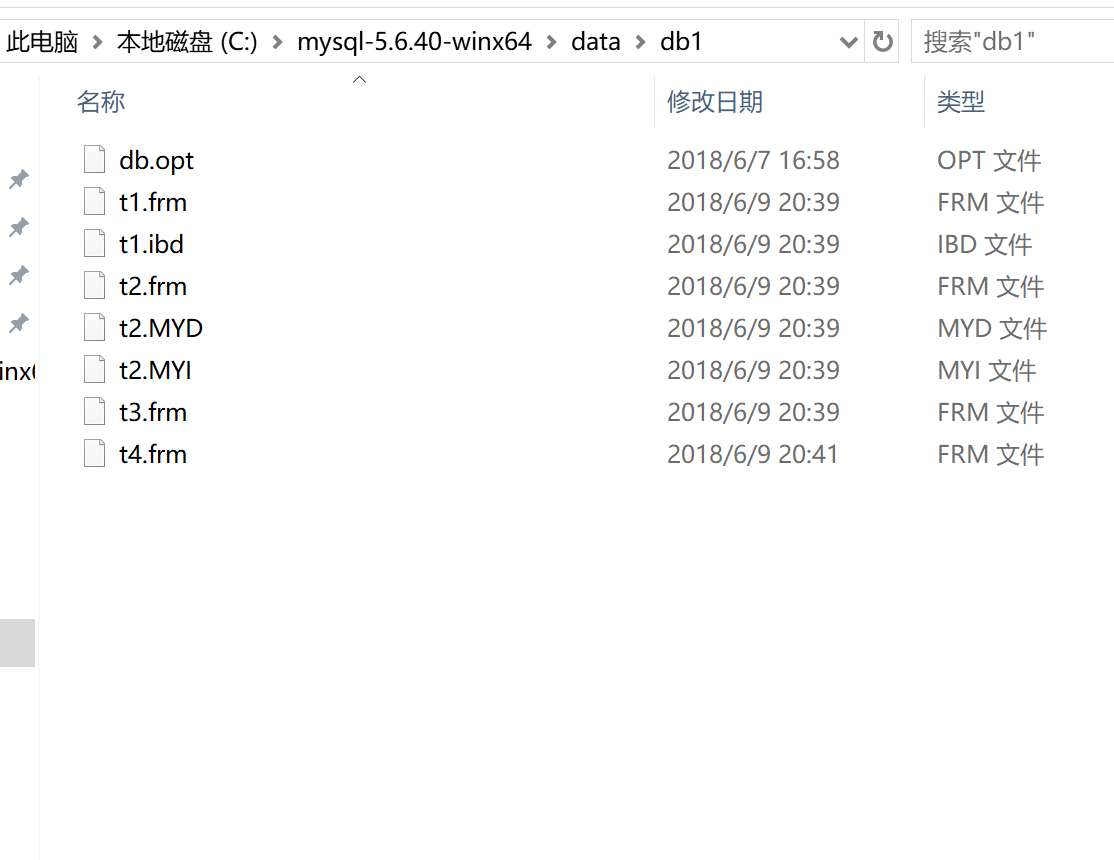

#.frm是存储数据表的框架结构 # .ibd是mysql数据文件 #.MYD是MyISAM表的数据文件的扩展名 #.MYI是MyISAM表的索引的扩展名 #发现后两种存储引擎只有表结构,无数据 #memory,在重启mysql或者重启机器后,表内数据清空
#blackhole,往表内插入任何数据,都相当于丢入黑洞,表内永远不存记录
三、表介绍
表相当于文件,表中的一条记录就相当于文件的一行内容,不同的是,表中的一条记录有对应的标题,称为表的字段

id,name,sex,age,birth称为字段,其余的,一行内容称为一条记录
四、创建表
语法:
create table 表名(
字段名1 类型[(宽度) 约束条件],
字段名2 类型[(宽度) 约束条件],
字段名3 类型[(宽度) 约束条件]
); #注意:
1. 在同一张表中,字段名是不能相同
2. 宽度和约束条件可选
3. 字段名和类型是必须的
1.创建数据库
create database db2 charset utf8;
2.使用数据库
use db2;
3.创建a1表
create table a1(
id int,
name varchar(50),
age int(3)
);
4.插入表的记录
insert into a1 values
(1,'mjj',18),
(2,'wusir',28);
ps:以;作为mysql的结束语
5.查询表的数据和结构
(1)查询a1表中的存储数据
mysql> select * from a1;
+------+-------+------+
| id | name | age |
+------+-------+------+
| 1 | mjj | 18 |
| 2 | wusir | 28 |
+------+-------+------+
2 rows in set (0.02 sec)
mysql>
(2)查看a1表的结构
mysql> desc a1;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(50) | YES | | NULL | |
| age | int(3) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
3 rows in set (0.16 sec)
(3)查看表的详细结构
mysql> show create table a1\G;
*************************** 1. row ***************************
Table: a1
Create Table: CREATE TABLE `a1` (
`id` int(11) DEFAULT NULL,
`name` varchar(50) DEFAULT NULL,
`age` int(3) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
6.复制表
(1)新创建一个数据库db3
mysql> create database db3 charset utf8;
Query OK, 1 row affected (0.00 sec)
(2)使用db3
mysql> use db3;
Database changed
#这是上个创建的db2数据库中的a1表
mysql> select * from db2.a1;
+------+-------+------+
| id | name | age |
+------+-------+------+
| 1 | mjj | 18 |
| 2 | wusir | 28 |
+------+-------+------+
(3)复制db2.a1的表结构和记录
# 这就是复制表的操作(既复制了表结构,又复制了记录)
mysql> create table b1 select * from db2.a1;
Query OK, 2 rows affected (0.03 sec)
(4)查看db3.b1中的数据和表结构
#再去查看db3文件夹下的b1表发现 跟db2文件下的a1表数据一样
mysql> select * from db3.b1;
+------+-------+------+
| id | name | age |
+------+-------+------+
| 1 | mjj | 18 |
| 2 | wusir | 28 |
+------+-------+------+
2 rows in set (0.00 sec)
ps1:如果只要表结构,不要记录
#在db2数据库下新创建一个b2表,给一个where条件,条件要求不成立,条件为false,只拷贝表结构
mysql> create table b2 select * from db2.a1 where 1>5;
Query OK, 0 rows affected (0.05 sec)
Records: 0 Duplicates: 0 Warnings: 0
查看表结构:
# 查看表结构
mysql> desc b2;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(50) | YES | | NULL | |
| age | int(3) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
3 rows in set (0.02 sec) #查看表结构中的数据,发现是空数据
mysql> select * from b2;
Empty set (0.00 sec)
ps2:还有一种做法,使用like(只拷贝表结构,不拷贝记录)
mysql> create table b3 like db2.a1;
Query OK, 0 rows affected (0.01 sec) mysql> desc b3;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(50) | YES | | NULL | |
| age | int(3) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
3 rows in set (0.02 sec) mysql> select * from db3.b3;
Empty set (0.00 sec)
7.删除表:
drop table 表名;
06-Mysql数据库----表的操作的更多相关文章
- 第二百七十八节,MySQL数据库-表内容操作
MySQL数据库-表内容操作 1.表内容增加 insert into 表 (列名,列名...) values (值,值,值...); 添加表内容添加一条数据 insert into 表 (列名,列名. ...
- MySQL数据库---表的操作
存储引擎 表就是文件,表的存储引擎就是文件的存储格式,即数据的组织存储方式. 字段类型 1.整数类型 整数类型:TINYINT SMALLINT MEDIUMINT INT BIGINT 作用:存储年 ...
- MySQL数据库-表内容操作
1.表内容增加 insert into 表 (列名,列名...) values (值,值,值...); 添加表内容添加一条数据 insert into 表 (列名,列名...) values (值,值 ...
- Database学习 - mysql 数据库 表操作
mysql 数据库 表操作 创建数据表 基本语法格式: 创建数据表: create table 表名( 字段名 datatype 约束, 字段名 datatype 约束, ...... ) 修改表名 ...
- 对mysql数据库表的相关操作
虫师博客(Python使用MySQL数据库(新)): https://www.cnblogs.com/fnng/p/3565912.html 1.更改表的结构,增加一个字段放置新增的属性 alter ...
- MySQL数据库表的数据插入、修改、删除、查询操作及实例应用
一.MySQL数据库表的数据插入.修改.删除和查询 CREATE DATABASE db0504; USE db0504; CREATE TABLE student ( sno ) NOT NULL ...
- MySQL数据库(3)_MySQL数据库表记录操作语句
附: MYSQL5.7版本sql_mode=only_full_group_by问题 .查询当前sql_mode: select @@sql_mode .查询出来的值为: set @@sql_mode ...
- python操作mysql数据库的相关操作实例
python操作mysql数据库的相关操作实例 # -*- coding: utf-8 -*- #python operate mysql database import MySQLdb #数据库名称 ...
- 在php中需要用到的mysql数据库的简单操作
1.数据库连接 1.1用windows命令行链接数据库服务器 几个DOS命令 在DOS环境下命令后面没有分号,在MySQL环境下,命令后面有分号 进入盘符: 语法:盘符: 进入盘符下的某个文件夹 语法 ...
- Mysql数据库表排序规则不一致导致联表查询,索引不起作用问题
Mysql数据库表排序规则不一致导致联表查询,索引不起作用问题 表更描述: 将mysql数据库中的worktask表添加ishaspic字段. 具体操作:(1)数据库worktask表新添是否有图片字 ...
随机推荐
- Docker 常用指令
1.检查内核版本,必须是3.10及以上uname ‐r2.安装dockeryum install docker3.输入y确认安装4.启动docker[root@localhost ~]# system ...
- CF821E 【Okabe and El Psy Kongroo】
首先我们从最简单的dp开始 \(dp[i][j]=dp[i-1][j]+dp[i-1][j+1]+dp[i-1][j-1]\) 然后这是一个O(NM)的做法,肯定行不通,然后我们考虑使用矩阵加速 \( ...
- POJ 3616 Milking Time(加掩饰的LIS)
传送门: http://poj.org/problem?id=3616 Milking Time Time Limit: 1000MS Memory Limit: 65536K Total Sub ...
- HDU1214 圆桌会议(找规律,数学)
传送门: http://acm.hdu.edu.cn/showproblem.php?pid=1214 圆桌会议 Time Limit: 2000/1000 MS (Java/Others) M ...
- ListItem Updating事件监视有没有上传附件
using System; using System.Collections.Generic; using System.Text; using Microsoft.SharePoint; using ...
- Restframework的版本及分页
1.版本 1.1基于url的get传参方式 1.创建django项目(起名我的是version),再创建一个app01应用 创建完成,通过python3 manage.py startapp api ...
- UICollectionViewCell「居左显示」
UICollectionViewCell「居左显示」 准备: 1.UICollectionView Left Aligned Layout 一款UICollectionView居左显示的约束点击下载_ ...
- <逆向学习第二天>如何手动脱UPX、Aspack壳
UPS.AsPack压缩壳介绍: UPX .AsPack是一款先进的可执行程序文件压缩器.压缩过的可执行文件体积缩小50%-70% ,这样减少了磁盘占用空间.网络上传下载的时间和其它分布以及存储费用. ...
- Java中Lambda表达式的简单使用
Lambda表达式是Java SE 8中一个重要的新特性.你可以把 Lambda表达式 理解为是一段可以传递的代码 (将代码像数据一样进行传递).可以写出更简洁.更灵活的代码.作为一种更紧凑的代码风格 ...
- python元组操作
元组:(tuple)元素不可被修改,不能被增加或者删除 一般写元组的时候,建议在最后加上一个逗号 可以索引取值 可以切片取值 元组一级元素不可被修改,但是二级及以后可以被修改 count() 获 ...