java爬虫-简单爬取网页图片
刚刚接触到“爬虫”这个词的时候是在大一,那时候什么都不明白,但知道了百度、谷歌他们的搜索引擎就是个爬虫。
现在大二。再次燃起对爬虫的热爱,查阅资料,知道常用java、python语言编程,这次我选择了java。在网上查找的
代码在本地跑大部分都不能使用,查找相关的资料教程也没有适合的。实在头疼、、、
现在自己写了一个简单爬取网页图片的代码,先分析一下自己写的代码吧
//获得html文本内容
String HTML = cm.getHtml(URL);
//获取图片标签
List<String> imgUrl = cm.getImageUrl(HTML);
//获取图片src地址
List<String> imgSrc = cm.getImageSrc(imgUrl);
//下载图片
cm.Download(imgSrc);
简单分为四个功能方法(函数),首先是要获取html文本
//获取HTML内容
private String getHtml(String url)throws Exception{
URL url1=new URL(url);//使用java.net.URL
URLConnection connection=url1.openConnection();//打开链接
InputStream in=connection.getInputStream();//获取输入流
InputStreamReader isr=new InputStreamReader(in);//流的包装
BufferedReader br=new BufferedReader(isr); String line;
StringBuffer sb=new StringBuffer();
while((line=br.readLine())!=null){//整行读取
sb.append(line,0,line.length());//添加到StringBuffer中
sb.append('\n');//添加换行符
}
//关闭各种流,先声明的后关闭
br.close();
isr.close();
in.close();
return sb.toString();
}
然后在获取的html文本中寻找图片,根据html标记语言不难发现图片通常带有<img>,所以
写一个关于img的正则表达式
// 获取img标签正则
private static final String IMGURL_REG = "<img.*src=(.*?)[^>]*?>";
接着是获取img标签信息,大部分涉及的是集合接口和正则表达式的知识
//获取ImageUrl地址
private List<String> getImageUrl(String html){
Matcher matcher=Pattern.compile(IMGURL_REG).matcher(html);
List<String>listimgurl=new ArrayList<String>();
while (matcher.find()){
listimgurl.add(matcher.group());
}
return listimgurl;
}
然后获取img标签信息中找取图片的地址信息,需要构造图片地址的正则表达式
// 获取src路径的正则
private static final String IMGSRC_REG = "[a-zA-z]+://[^\\s]*";
接着是获取图片地址的信息,大部分涉及的也是集合接口和正则表达式的知识
//获取ImageSrc地址
private List<String> getImageSrc(List<String> listimageurl){
List<String> listImageSrc=new ArrayList<String>();
for (String image:listimageurl){
Matcher matcher=Pattern.compile(IMGSRC_REG).matcher(image);
while (matcher.find()){
listImageSrc.add(matcher.group().substring(0, matcher.group().length()-1));
}
}
return listImageSrc;
}
最后通过图片地址信息下载图片
//下载图片
private void Download(List<String> listImgSrc) {
try {
//开始时间
Date begindate = new Date();
for (String url : listImgSrc) {
//开始时间
Date begindate2 = new Date();
String imageName = url.substring(url.lastIndexOf("/") + 1, url.length());
URL uri = new URL(url);
InputStream in = uri.openStream();
FileOutputStream fo = new FileOutputStream(new File("src/res/"+imageName));//文件输出流
byte[] buf = new byte[1024];
int length = 0;
System.out.println("开始下载:" + url);
while ((length = in.read(buf, 0, buf.length)) != -1) {
fo.write(buf, 0, length);
}
//关闭流
in.close();
fo.close();
System.out.println(imageName + "下载完成");
//结束时间
Date overdate2 = new Date();
double time = overdate2.getTime() - begindate2.getTime();
System.out.println("耗时:" + time / 1000 + "s");
}
Date overdate = new Date();
double time = overdate.getTime() - begindate.getTime();
System.out.println("总耗时:" + time / 1000 + "s");
} catch (Exception e) {
System.out.println("下载失败");
}
}
展示一下运行结果:
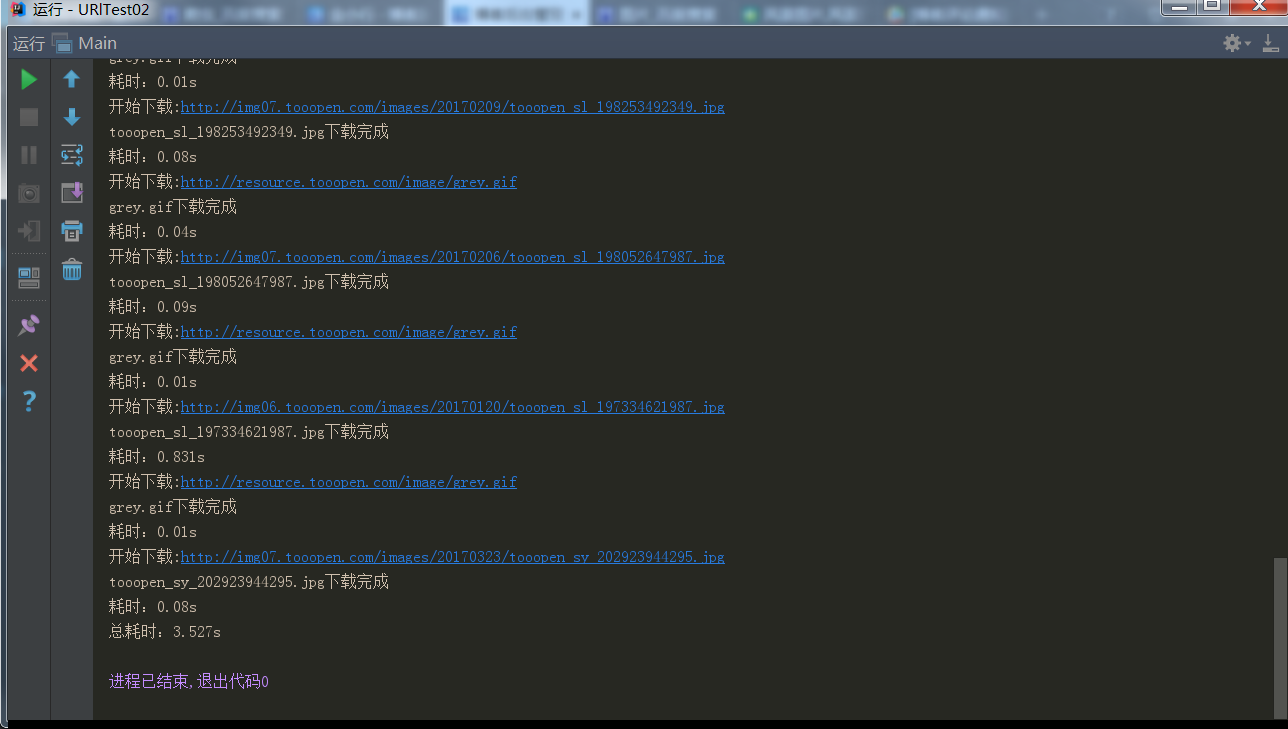
上一下全部代码:
import java.io.*;
import java.net.URL;
import java.net.URLConnection;
import java.util.*;
import java.util.regex.Matcher;
import java.util.regex.Pattern; public class Main { // 地址
private static final String URL = "http://www.tooopen.com/view/1439719.html";
// 获取img标签正则
private static final String IMGURL_REG = "<img.*src=(.*?)[^>]*?>";
// 获取src路径的正则
private static final String IMGSRC_REG = "[a-zA-z]+://[^\\s]*"; public static void main(String[] args) {
try {
Main cm=new Main();
//获得html文本内容
String HTML = cm.getHtml(URL);
//获取图片标签
List<String> imgUrl = cm.getImageUrl(HTML);
//获取图片src地址
List<String> imgSrc = cm.getImageSrc(imgUrl);
//下载图片
cm.Download(imgSrc); }catch (Exception e){
System.out.println("发生错误");
} } //获取HTML内容
private String getHtml(String url)throws Exception{
URL url1=new URL(url);
URLConnection connection=url1.openConnection();
InputStream in=connection.getInputStream();
InputStreamReader isr=new InputStreamReader(in);
BufferedReader br=new BufferedReader(isr); String line;
StringBuffer sb=new StringBuffer();
while((line=br.readLine())!=null){
sb.append(line,0,line.length());
sb.append('\n');
}
br.close();
isr.close();
in.close();
return sb.toString();
} //获取ImageUrl地址
private List<String> getImageUrl(String html){
Matcher matcher=Pattern.compile(IMGURL_REG).matcher(html);
List<String>listimgurl=new ArrayList<String>();
while (matcher.find()){
listimgurl.add(matcher.group());
}
return listimgurl;
} //获取ImageSrc地址
private List<String> getImageSrc(List<String> listimageurl){
List<String> listImageSrc=new ArrayList<String>();
for (String image:listimageurl){
Matcher matcher=Pattern.compile(IMGSRC_REG).matcher(image);
while (matcher.find()){
listImageSrc.add(matcher.group().substring(0, matcher.group().length()-1));
}
}
return listImageSrc;
} //下载图片
private void Download(List<String> listImgSrc) {
try {
//开始时间
Date begindate = new Date();
for (String url : listImgSrc) {
//开始时间
Date begindate2 = new Date();
String imageName = url.substring(url.lastIndexOf("/") + 1, url.length());
URL uri = new URL(url);
InputStream in = uri.openStream();
FileOutputStream fo = new FileOutputStream(new File("src/res/"+imageName));
byte[] buf = new byte[1024];
int length = 0;
System.out.println("开始下载:" + url);
while ((length = in.read(buf, 0, buf.length)) != -1) {
fo.write(buf, 0, length);
}
in.close();
fo.close();
System.out.println(imageName + "下载完成");
//结束时间
Date overdate2 = new Date();
double time = overdate2.getTime() - begindate2.getTime();
System.out.println("耗时:" + time / 1000 + "s");
}
Date overdate = new Date();
double time = overdate.getTime() - begindate.getTime();
System.out.println("总耗时:" + time / 1000 + "s");
} catch (Exception e) {
System.out.println("下载失败");
}
}
}
本人还是java初学者,能力有限,如有更好的代码或者教程可以留言,我们可以交流学习。
以上还有不足或者不对之处请指出,非常感谢个位。
java爬虫-简单爬取网页图片的更多相关文章
- node:爬虫爬取网页图片
代码地址如下:http://www.demodashi.com/demo/13845.html 前言 周末自己在家闲着没事,刷着微信,玩着手机,发现自己的微信头像该换了,就去网上找了一下头像,看着图片 ...
- python requests库爬取网页小实例:爬取网页图片
爬取网页图片: #网络图片爬取 import requests import os root="C://Users//Lenovo//Desktop//" #以原文件名作为保存的文 ...
- Java爬虫一键爬取结果并保存为Excel
Java爬虫一键爬取结果并保存为Excel 将爬取结果保存为一个Excel表格 官方没有给出导出Excel 的教程 这里我就发一个导出为Excel的教程 导包 因为个人爱好 我喜欢用Gradle所以这 ...
- erlang 爬虫——爬取网页图片
说起爬虫,大家第一印象就是想到了python来做爬虫.其实,服务端语言好些都可以来实现这个东东. 在我们日常上网浏览网页的时候,经常会看到一些好看的图片,我们就希望把这些图片保存下载,或者用户用来做桌 ...
- 【网络爬虫】【python】网络爬虫(五):scrapy爬虫初探——爬取网页及选择器
在上一篇文章的末尾,我们创建了一个scrapy框架的爬虫项目test,现在来运行下一个简单的爬虫,看看scrapy爬取的过程是怎样的. 一.爬虫类编写(spider.py) from scrapy.s ...
- python 爬虫(爬取网页的img并下载)
from urllib.request import urlopen # 引用第三方库 import requests #引用requests/用于访问网站(没安装需要安装) from pyquery ...
- Python简单爬取Amazon图片-其他网站相应修改链接和正则
简单爬取Amazon图片信息 这是一个简单的模板,如果需要爬取其他网站图片信息,更改URL和正则表达式即可 1 import requests 2 import re 3 import os 4 de ...
- Java爬虫实践--爬取CSDN网站图片为例
实现的效果,自动在工程下创建Pictures文件夹,根据网站URL爬取图片,层层获取.在Pictures下以网站的层级URL命名文件夹,用来装该层URL下的图片.同时将文件名,路径,URL插入数据库, ...
- Python多线程爬虫爬取网页图片
临近期末考试,但是根本不想复习!啊啊啊啊啊啊啊!!!! 于是做了一个爬虫,网址为 https://yande.re,网页图片为动漫美图(图片带点颜色........宅男福利 github项目地址为:h ...
随机推荐
- 序列化和反序列化Java 8的时间/日期类
序列化 假如有 Clock 类: public class Clock { private LocalDate localDate; private LocalTime localTime; priv ...
- java 学习帮助
java学习这一部分其实也算是今天的重点,这一部分用来回答很多群里的朋友所问过的问题,那就是我你是如何学习Java的,能不能给点建议?今 天我是打算来点干货,因此咱们就不说一些学习方法和技巧了,直接来 ...
- 使用zTree插件构建树形菜单
zTree下载:https://github.com/zTree/zTree_v3 目录: 就我看来,zTree较为实用的有以下几点: zTree 是一个依靠 jQuery 实现的多功能 “树插件”. ...
- PHP-深入理解Opcode缓存
1.什么是opcode缓存? 当解释器完成对脚本代码的分析后,便将它们生成可以直接运行的中间代码,也称为操作码(Operate Code,opcode).Opcode cache的目地是避免重复编译, ...
- strults2标签s:set的用法
struts2标签<s:set></s:set>的用法.原理 http://liuna718-163-com.iteye.com/blog/1124654 我的例子: ...
- ADO.NET基础知识学习(SQLCOnnection&SQLCommand&SQLDataReader&SQLDataAdapter&DataSet)
通过ADO.NET技术,我们可以高效的完成客户端同数据库之间的数据访问操作,便于我们在客户端程序简便高效的访问以及获取数据库中的有用数据,同时也可以对数据库中的数据进行更新,即可以完成客户端与数据库之 ...
- python with上下文的浅谈
python中的with一般用于上下文管理,什么是上下文管理,其实平时我们经常会用到,比如连接数据库 查询数据,操作完成后关闭连接. 还比如打开文件写入数据等操作. 具体实例: class Myres ...
- win10 环境下 MinGW-w64安装
MinGW-w64 就是 著名C/C++编译器GCC的Windows版本. 一.什么是 MinGW-w64 ?MinGW 的全称是:Minimalist GNU on Windows .它实际上是将经 ...
- JQuery实现ajax跨域
AJAX 的出现使得网页可以通过在后台与服务器进行少量数据交换,实现网页的局部刷新.但是出于安全的考虑,ajax不允许跨域通信.如果尝试从不同的域请求数据,就会出现错误.如果能控制数据驻留的远程服务器 ...
- SpringCloud系列八:自定义Ribbon配置
1. 回顾 上文使用Ribbon实现了客户端侧的负载均衡.但是很多场景下,我们可能需要自定义Ribbon的配置,比如修改Ribbon的负载均衡规则. Spring Cloud允许使用Java代码或属性 ...