java爬虫-简单爬取网页图片
刚刚接触到“爬虫”这个词的时候是在大一,那时候什么都不明白,但知道了百度、谷歌他们的搜索引擎就是个爬虫。
现在大二。再次燃起对爬虫的热爱,查阅资料,知道常用java、python语言编程,这次我选择了java。在网上查找的
代码在本地跑大部分都不能使用,查找相关的资料教程也没有适合的。实在头疼、、、
现在自己写了一个简单爬取网页图片的代码,先分析一下自己写的代码吧
//获得html文本内容
String HTML = cm.getHtml(URL);
//获取图片标签
List<String> imgUrl = cm.getImageUrl(HTML);
//获取图片src地址
List<String> imgSrc = cm.getImageSrc(imgUrl);
//下载图片
cm.Download(imgSrc);
简单分为四个功能方法(函数),首先是要获取html文本
//获取HTML内容
private String getHtml(String url)throws Exception{
URL url1=new URL(url);//使用java.net.URL
URLConnection connection=url1.openConnection();//打开链接
InputStream in=connection.getInputStream();//获取输入流
InputStreamReader isr=new InputStreamReader(in);//流的包装
BufferedReader br=new BufferedReader(isr); String line;
StringBuffer sb=new StringBuffer();
while((line=br.readLine())!=null){//整行读取
sb.append(line,0,line.length());//添加到StringBuffer中
sb.append('\n');//添加换行符
}
//关闭各种流,先声明的后关闭
br.close();
isr.close();
in.close();
return sb.toString();
}
然后在获取的html文本中寻找图片,根据html标记语言不难发现图片通常带有<img>,所以
写一个关于img的正则表达式
// 获取img标签正则
private static final String IMGURL_REG = "<img.*src=(.*?)[^>]*?>";
接着是获取img标签信息,大部分涉及的是集合接口和正则表达式的知识
//获取ImageUrl地址
private List<String> getImageUrl(String html){
Matcher matcher=Pattern.compile(IMGURL_REG).matcher(html);
List<String>listimgurl=new ArrayList<String>();
while (matcher.find()){
listimgurl.add(matcher.group());
}
return listimgurl;
}
然后获取img标签信息中找取图片的地址信息,需要构造图片地址的正则表达式
// 获取src路径的正则
private static final String IMGSRC_REG = "[a-zA-z]+://[^\\s]*";
接着是获取图片地址的信息,大部分涉及的也是集合接口和正则表达式的知识
//获取ImageSrc地址
private List<String> getImageSrc(List<String> listimageurl){
List<String> listImageSrc=new ArrayList<String>();
for (String image:listimageurl){
Matcher matcher=Pattern.compile(IMGSRC_REG).matcher(image);
while (matcher.find()){
listImageSrc.add(matcher.group().substring(0, matcher.group().length()-1));
}
}
return listImageSrc;
}
最后通过图片地址信息下载图片
//下载图片
private void Download(List<String> listImgSrc) {
try {
//开始时间
Date begindate = new Date();
for (String url : listImgSrc) {
//开始时间
Date begindate2 = new Date();
String imageName = url.substring(url.lastIndexOf("/") + 1, url.length());
URL uri = new URL(url);
InputStream in = uri.openStream();
FileOutputStream fo = new FileOutputStream(new File("src/res/"+imageName));//文件输出流
byte[] buf = new byte[1024];
int length = 0;
System.out.println("开始下载:" + url);
while ((length = in.read(buf, 0, buf.length)) != -1) {
fo.write(buf, 0, length);
}
//关闭流
in.close();
fo.close();
System.out.println(imageName + "下载完成");
//结束时间
Date overdate2 = new Date();
double time = overdate2.getTime() - begindate2.getTime();
System.out.println("耗时:" + time / 1000 + "s");
}
Date overdate = new Date();
double time = overdate.getTime() - begindate.getTime();
System.out.println("总耗时:" + time / 1000 + "s");
} catch (Exception e) {
System.out.println("下载失败");
}
}
展示一下运行结果:
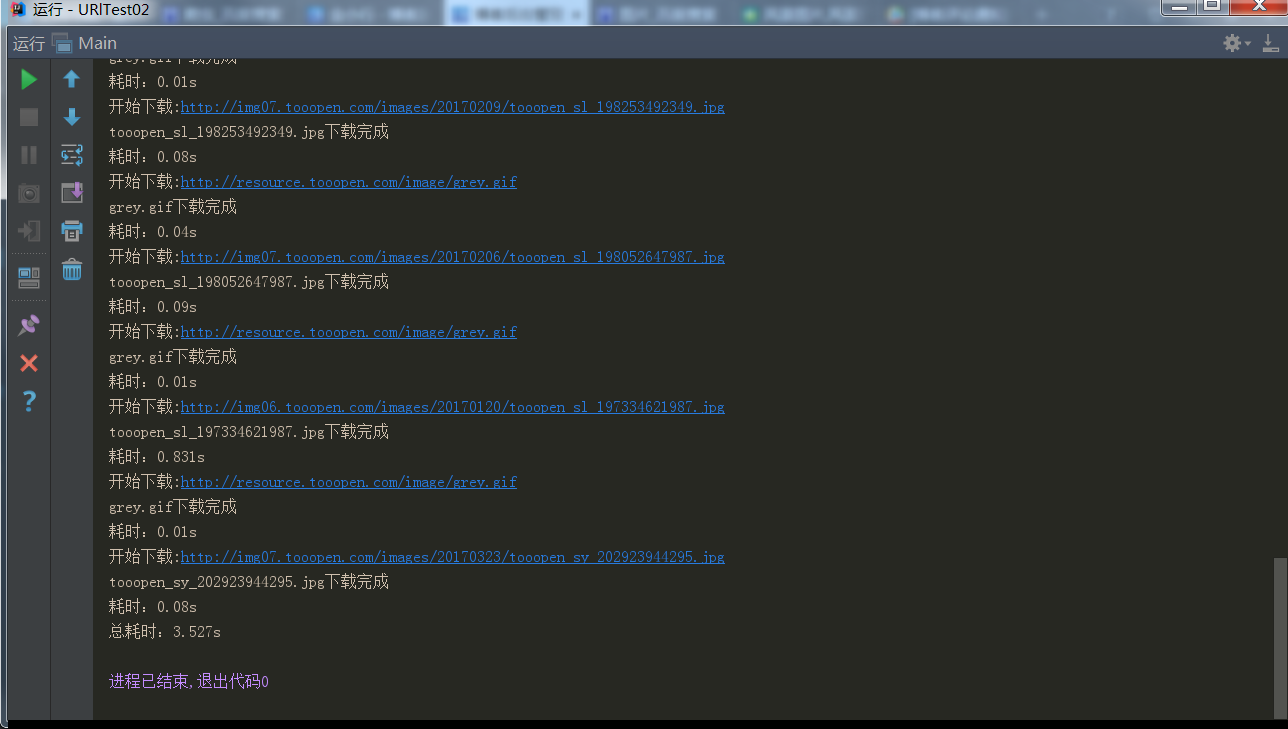
上一下全部代码:
import java.io.*;
import java.net.URL;
import java.net.URLConnection;
import java.util.*;
import java.util.regex.Matcher;
import java.util.regex.Pattern; public class Main { // 地址
private static final String URL = "http://www.tooopen.com/view/1439719.html";
// 获取img标签正则
private static final String IMGURL_REG = "<img.*src=(.*?)[^>]*?>";
// 获取src路径的正则
private static final String IMGSRC_REG = "[a-zA-z]+://[^\\s]*"; public static void main(String[] args) {
try {
Main cm=new Main();
//获得html文本内容
String HTML = cm.getHtml(URL);
//获取图片标签
List<String> imgUrl = cm.getImageUrl(HTML);
//获取图片src地址
List<String> imgSrc = cm.getImageSrc(imgUrl);
//下载图片
cm.Download(imgSrc); }catch (Exception e){
System.out.println("发生错误");
} } //获取HTML内容
private String getHtml(String url)throws Exception{
URL url1=new URL(url);
URLConnection connection=url1.openConnection();
InputStream in=connection.getInputStream();
InputStreamReader isr=new InputStreamReader(in);
BufferedReader br=new BufferedReader(isr); String line;
StringBuffer sb=new StringBuffer();
while((line=br.readLine())!=null){
sb.append(line,0,line.length());
sb.append('\n');
}
br.close();
isr.close();
in.close();
return sb.toString();
} //获取ImageUrl地址
private List<String> getImageUrl(String html){
Matcher matcher=Pattern.compile(IMGURL_REG).matcher(html);
List<String>listimgurl=new ArrayList<String>();
while (matcher.find()){
listimgurl.add(matcher.group());
}
return listimgurl;
} //获取ImageSrc地址
private List<String> getImageSrc(List<String> listimageurl){
List<String> listImageSrc=new ArrayList<String>();
for (String image:listimageurl){
Matcher matcher=Pattern.compile(IMGSRC_REG).matcher(image);
while (matcher.find()){
listImageSrc.add(matcher.group().substring(0, matcher.group().length()-1));
}
}
return listImageSrc;
} //下载图片
private void Download(List<String> listImgSrc) {
try {
//开始时间
Date begindate = new Date();
for (String url : listImgSrc) {
//开始时间
Date begindate2 = new Date();
String imageName = url.substring(url.lastIndexOf("/") + 1, url.length());
URL uri = new URL(url);
InputStream in = uri.openStream();
FileOutputStream fo = new FileOutputStream(new File("src/res/"+imageName));
byte[] buf = new byte[1024];
int length = 0;
System.out.println("开始下载:" + url);
while ((length = in.read(buf, 0, buf.length)) != -1) {
fo.write(buf, 0, length);
}
in.close();
fo.close();
System.out.println(imageName + "下载完成");
//结束时间
Date overdate2 = new Date();
double time = overdate2.getTime() - begindate2.getTime();
System.out.println("耗时:" + time / 1000 + "s");
}
Date overdate = new Date();
double time = overdate.getTime() - begindate.getTime();
System.out.println("总耗时:" + time / 1000 + "s");
} catch (Exception e) {
System.out.println("下载失败");
}
}
}
本人还是java初学者,能力有限,如有更好的代码或者教程可以留言,我们可以交流学习。
以上还有不足或者不对之处请指出,非常感谢个位。
java爬虫-简单爬取网页图片的更多相关文章
- node:爬虫爬取网页图片
代码地址如下:http://www.demodashi.com/demo/13845.html 前言 周末自己在家闲着没事,刷着微信,玩着手机,发现自己的微信头像该换了,就去网上找了一下头像,看着图片 ...
- python requests库爬取网页小实例:爬取网页图片
爬取网页图片: #网络图片爬取 import requests import os root="C://Users//Lenovo//Desktop//" #以原文件名作为保存的文 ...
- Java爬虫一键爬取结果并保存为Excel
Java爬虫一键爬取结果并保存为Excel 将爬取结果保存为一个Excel表格 官方没有给出导出Excel 的教程 这里我就发一个导出为Excel的教程 导包 因为个人爱好 我喜欢用Gradle所以这 ...
- erlang 爬虫——爬取网页图片
说起爬虫,大家第一印象就是想到了python来做爬虫.其实,服务端语言好些都可以来实现这个东东. 在我们日常上网浏览网页的时候,经常会看到一些好看的图片,我们就希望把这些图片保存下载,或者用户用来做桌 ...
- 【网络爬虫】【python】网络爬虫(五):scrapy爬虫初探——爬取网页及选择器
在上一篇文章的末尾,我们创建了一个scrapy框架的爬虫项目test,现在来运行下一个简单的爬虫,看看scrapy爬取的过程是怎样的. 一.爬虫类编写(spider.py) from scrapy.s ...
- python 爬虫(爬取网页的img并下载)
from urllib.request import urlopen # 引用第三方库 import requests #引用requests/用于访问网站(没安装需要安装) from pyquery ...
- Python简单爬取Amazon图片-其他网站相应修改链接和正则
简单爬取Amazon图片信息 这是一个简单的模板,如果需要爬取其他网站图片信息,更改URL和正则表达式即可 1 import requests 2 import re 3 import os 4 de ...
- Java爬虫实践--爬取CSDN网站图片为例
实现的效果,自动在工程下创建Pictures文件夹,根据网站URL爬取图片,层层获取.在Pictures下以网站的层级URL命名文件夹,用来装该层URL下的图片.同时将文件名,路径,URL插入数据库, ...
- Python多线程爬虫爬取网页图片
临近期末考试,但是根本不想复习!啊啊啊啊啊啊啊!!!! 于是做了一个爬虫,网址为 https://yande.re,网页图片为动漫美图(图片带点颜色........宅男福利 github项目地址为:h ...
随机推荐
- 基于python的ardrone control源码分析与心得
这里有一段python代码,可用于操控ardrone 2.0.实验室曾经借鉴用过,并添加了部分功能.如今复习一下,顺便理理python的相关知识点. #!/usr/bin/env python # A ...
- 道具搜索框(|=, & , ^=)实现的列子
需求: 勾上界面上多选框筛选出符合的道具 思路: 1. 使用组合数字让一个数字包含多这个搜索条件,比如2代表搜索衣服和武器, 数字按照2的n次幂的值递增,通过|,&,^运算符实现一个数字包含多 ...
- 网站相关技术探究keepalive_timeout(转)
网站相关技术探究keepalive设多少: /proc/$PID/fd/$number 0:标准输入 1:标准输出 2:标准错误 Test: [root@KTQT ~]# ll /proc/12 ...
- WP8数据存储--独立存储设置
<Grid x:Name="LayoutRoot" Background="Transparent"> <Grid.RowDefinition ...
- stm32 IDR寄存器软件仿真的BUG
/* * 函数名:Key_GPIO_Config * 描述 :配置按键用到的I/O口 * 输入 :无 * 输出 :无 */ void Key_GPIO_Config(void) { GPIO_Init ...
- C#实现svn server端的hook
目标 要做的东东呢,就是在向svn提交文件的时候,可以再server端读到所有提交文件的内容,并根据某些规则验证文件的合法性,如果验证失败,则终止提交,并在svn的客户端上显示错误信息. 准备工作 ...
- Gradle build.gradle to Maven pom.xml ,终于找到你了。
尊重原创:https://blog.csdn.net/kevin_luan/article/details/50996109 根据build.gradle 生成maven pox.xml 1.将以下配 ...
- win7安装RabbitMQ
1.下载并安装erlang http://www.erlang.org/downloads 2.下载并安装RabbitMQ http://www.rabbitmq.com/install-window ...
- java获取真实的ip地址
直接上代码,获取请求主机的IP地址,如果通过代理进来,则透过防火墙获取真实IP地址 public class IPUtil { private static final Logger logger = ...
- Java并发编程(十三)在现有的线程安全类中添加功能
重用现有的类而不是创建新的类,可以降低工作量,开发风险以及维护成本. 有时候线程安全类可以支持我们所有的操作,但更多时候,现有的了类只能支持大部分的操作,此时就需要在不破坏线程安全性的情况下添加一个新 ...