Xml日志记录文件最优方案(附源代码)
Xml作为数据存储的一种方式,当数据非常大的时候,我们将碰到很多Xml处理的问题。通常,我们对Xml文件进行编辑的最直接的方式是将xml文件加载到XmlDocument,在内存中来对XmlDocument进行修改,然后再保存到磁盘中。这样的话我们将不得不将整个XML document 加载到内存中,这明显是不明智的(对于大数据XML文件来说,内存将消耗很大,哥表示鸭梨很大)。下面我们将要讲的是如何高效的增加内容(对象实体内容)到xml日志文件中。
(一)设计概要
总体来说,我们将(通过代码)创建两种不同的文件,第一种为Xml文件,第二种为xml片段(txt文件),如下图所示:
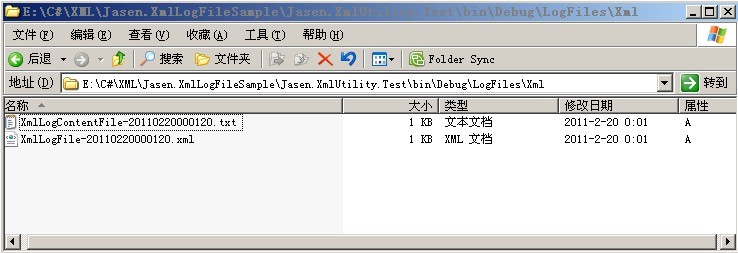
我们通过如下的定义来使2个不同的文件相关联。
<!ENTITY yourEntityRefName SYSTEM "your xml fragement address(relative or obsolute address) ">
(二)xml文件的生成
先来看下如何创建相关的xml文件,代码如下:
private static void InitXmlFile(string xmlLogFilePath, string xmlLogContentFileName, string entityRef)
{
string docType = string.Format("\n<!DOCTYPE XmlLogFile \n [ \n <!ENTITY {0} SYSTEM \"{1}\">\n ]>\n", entityRef, xmlLogContentFileName);
XmlWriterSettings wrapperSettings = new XmlWriterSettings()
{
Indent = true
};
using (XmlWriter writer = XmlWriter.Create(xmlLogFilePath, wrapperSettings))
{
writer.WriteStartDocument();
writer.WriteRaw(docType);
writer.WriteStartElement(ConfigResource.XmlLogFile); writer.WriteStartElement(ConfigResource.XmlLogContent);
writer.WriteEntityRef(entityRef);
writer.WriteEndElement(); writer.WriteEndElement();
writer.Close();
}
}
对xml文件内容的写入主要通过XmlWriter来进行操作的。这个方法比较简单,不再讲解,看下我们通过这个方法生成的文件内容:
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE XmlLogFile
[
<!ENTITY Locations SYSTEM "XmlLogContentFile-20110220000120.txt">
]>
<XmlLogFile>
<XmlLogContent>&Locations;</XmlLogContent>
</XmlLogFile>
Locations 为实体引用名称,与之相对应的为&Locations; 。
XmlLogContentFile-20110220000120.txt为Xml片段的文件名称,路径是相对于XmlLogFile-20110220000120.xml的。
&Locations;相当于占位符的作用,将用XmlLogContentFile-20110220000120.txt文件的内容来替换XmlLogFile-20110220000120.xml的&Locations;
(三)Xml片段文件的生成
Xml片段文件的生成过程思路为:通过System.IO.FileStream和System.Xml.XmlWriter在文件的末尾处增加文件的内容(效率较高,因为是直接在文件的末尾添加的内容),内容格式为Xml,其中涉及到反射的部分内容。
private static void InitEntityRefFile(string xmlLogContentFilePath, object logObject, string entityRef)
{
using (FileStream fileStream = new FileStream(xmlLogContentFilePath, FileMode.Append,
FileAccess.Write, FileShare.Read))
{
XmlWriterSettings settings = new XmlWriterSettings()
{
ConformanceLevel = ConformanceLevel.Fragment,
Indent = true,
OmitXmlDeclaration = false
}; WriteContent(logObject, fileStream, settings);
}
} private static void WriteContent(object logObject, FileStream fileStream, XmlWriterSettings settings)
{
using (XmlWriter writer = XmlWriter.Create(fileStream, settings))
{
Type type = logObject.GetType();
writer.WriteStartElement(type.Name);
writer.WriteAttributeString(ConfigResource.Id,logObject.GetHashCode().ToString()); if (logObject.GetType().IsPrimitive ||
(logObject.GetType() == typeof(string)))
{
writer.WriteElementString(logObject.GetType().Name, logObject.ToString());
}
else
{
PropertyInfo[] infos = type.GetProperties();
foreach (PropertyInfo info in infos)
{
if (ValidateProperty(info))
{
writer.WriteElementString(info.Name,
(info.GetValue(logObject, null) ?? string.Empty).ToString());
}
}
} writer.WriteEndElement();
writer.WriteWhitespace("\n");
writer.Close();
}
}
private static bool ValidateProperty(PropertyInfo info)
{
return info.CanRead && (info.PropertyType.IsPrimitive
|| (info.PropertyType == typeof(string))
|| (info.PropertyType == typeof(DateTime)
|| (info.PropertyType == typeof(DateTime?))));
}
代码 writer.WriteAttributeString(ConfigResource.Id,logObject.GetHashCode().ToString());
if (logObject.GetType().IsPrimitive ||
(logObject.GetType() == typeof(string)))
{
writer.WriteElementString(logObject.GetType().Name, logObject.ToString());
}
第一行为该实体增加一个Id特性,采用对象的哈希值来进行赋值,方便以后的单元测试(通过对象的哈希值来查找相应的Xml内容)。
余下的几行为:当实体的类型是基元类型或者字符串类型的时候,直接通过writer.WriteElementString()方法将类型名称,实体对象值作为参数直接写入xml片段文件中。
否则 else
{
PropertyInfo[] infos = type.GetProperties();
foreach (PropertyInfo info in infos)
{
if (ValidateProperty(info))
{
writer.WriteElementString(info.Name,
(info.GetValue(logObject, null) ?? string.Empty).ToString());
}
}
}
通过反射来获取所有属性相对应的值,其中属性必须是可读的,并且为(基元类型,string,DateTiem?,DateTime)其中一种(这个大家可以扩展一下相关功能)。
如下所示,我们通过基元类型float,字符串类型string,对象类型Error【Point为Error的属性,不是(基元类型,string,DateTiem?,DateTime)其中一种】来进行测试。
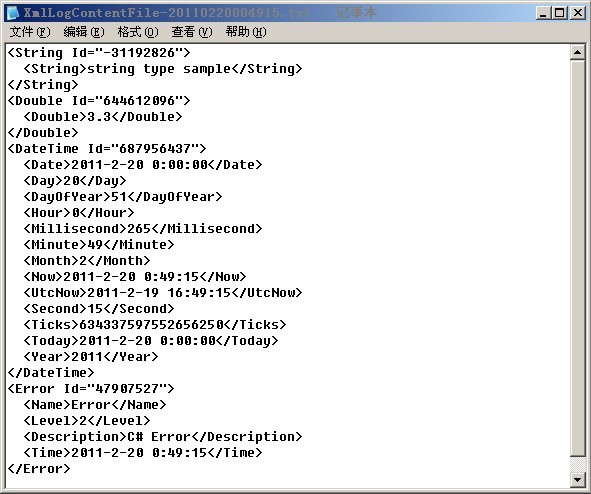
XmlLogHelper.Write("string type sample");
XmlLogHelper.Write(3.3);
XmlLogHelper.Write(DateTime.Now);
Error error = new Error()
{
Time = DateTime.Now,
Point = new System.Drawing.Point(0, 0),
Description = "C# Error",
Level = 2,
Name = "Error"
};
XmlLogHelper.Write(error);
输出内容如下:
(四)采用lock来避免异常的发生,其次特别要注意对资源的及时释放。
private static readonly object lockObject = new object();
public static void Write(object logObject)
{
if (logObject == null)
{
return;
} lock (lockObject)
{
Writing(logObject);
}
} private static void Writing(object logObject)
{
string entityRef = ConfigResource.EntityRef;
string baseDirectory = InitDirectory();
string baseName = DateTime.Now.ToString("yyyyMMddHHmmss");
string xmlLogFilePath =Path.Combine(baseDirectory ,string.Format(ConfigResource.XmlLogFileName,baseName));
XmlLogHelper.XmlFilePath = xmlLogFilePath;
string xmlLogContentFileName = string.Format(ConfigResource.XmlLogContentFileName,baseName);
string xmlLogContentFilePath = Path.Combine(baseDirectory, xmlLogContentFileName); if (!File.Exists(xmlLogFilePath))
{
InitXmlFile(xmlLogFilePath, xmlLogContentFileName, entityRef);
} InitEntityRefFile(xmlLogContentFilePath, logObject, entityRef);
}
采用lock来避免同时对文件进行操作,避免异常的发生,保证每次操作都是仅有一个在进行。
lock (lockObject)
{
Writing(logObject);
}
采用using来及时释放掉资源。
using (FileStream fileStream = new FileStream(xmlLogContentFilePath, FileMode.Append,
FileAccess.Write, FileShare.Read))
{
}
(五)单元测试
单元测试的主要代码如下,主要是对Write()方法进行测试,如下:
[TestMethod()]
public void WriteTest()
{
DeleteFiles();//删除目录下所有文件,避免产生不必要的影响。
List<Error> errors = InitErrorData(9);
AssertXmlContent(errors);
} private static void AssertXmlContent(List<Error> errors)
{
foreach (Error error in errors)
{
XmlLogHelper.Write(error); XmlDocument doc = GetXmlDocument();
XmlNode node = doc.SelectSingleNode("//Error[@Id='" + error.GetHashCode().ToString() + "']");
Assert.IsTrue(node.Name == typeof(Error).Name); string path = string.Format("//Error[@Id='{0}']//", error.GetHashCode().ToString());
XmlNode levelNode = doc.SelectSingleNode(path + "Level");
XmlNode nameNode = doc.SelectSingleNode(path + "Name");
XmlNode descriptionNode = doc.SelectSingleNode(path + "Description");
XmlNode timeNode = doc.SelectSingleNode(path + "Time");
XmlNode pointNode = doc.SelectSingleNode(path + "Point"); Assert.IsTrue(nameNode.Name == "Name");
Assert.IsTrue(levelNode.Name == "Level");
Assert.IsTrue(descriptionNode.Name == "Description");
Assert.IsTrue(timeNode.Name == "Time"); Assert.IsNotNull(levelNode);
Assert.IsNotNull(nameNode);
Assert.IsNotNull(descriptionNode);
Assert.IsNotNull(timeNode);
Assert.IsNull(pointNode); Assert.IsTrue(nameNode.InnerText == (error.Name ?? string.Empty));
Assert.IsTrue(levelNode.InnerText == error.Level.ToString());
Assert.IsTrue(timeNode.InnerText == DateTime.MinValue.ToString());
Assert.IsTrue(descriptionNode.InnerText == (error.Description ?? string.Empty));
}
}
上面仅仅是针对一个自定义的Error类进行了验证................
(六)其他应用
当我们的Xml日志文件可以记录的时候,我们可能想通过界面来看下效果,比如如下所示意的图中,点击【生成XML日志文件】,再点击【获取XML日志文件】的时候,我们能够看到生成的XML日志文件。
其中生成的文件名称显示如下:

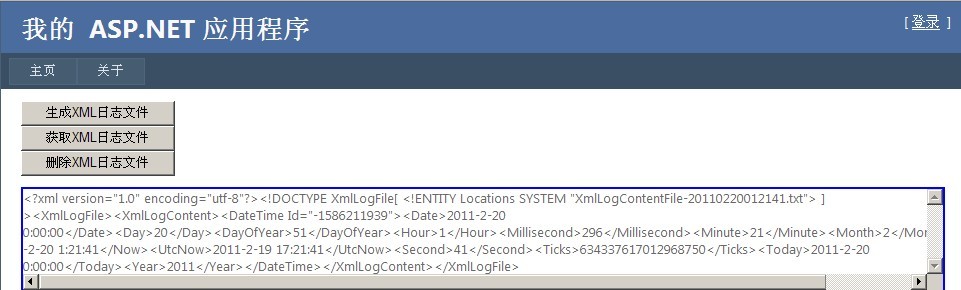
多次点击【生成XML日志文件】,再点击【获取XML日志文件】的时候,我们能够看到生成的XML日志文件数量也递增(因为我将文件的名称设置为string baseName = DateTime.Now.ToString("yyyyMMddHHmmss");,按照秒数来计算的)。点击任何一个文件,将显示该文件的相关全部xml内容(包括xml文件和xml片段)。

点击【删除XML日志文件】将删除所有的xml文件,如下:
(七)总结
对于流的操作来说,应尽快释放掉系统资源,促使GC的Finalize()方法的执行,同时可以避免异常的发生。对于Xml日志来说,当数据量越来越大的时候,我们可以将内容分为两部分,一部分为标准的哦xml文件,另一部分为xml片段文件。这样,我们能够在xml片段文件中方便地在文件末尾处增加相关的内容,这种效率是非常快的,而通常我们通过XMLDocument来加载数据非常消耗内存,效率较低(数据量越大越明显)。同时在读取xml文件的时候也会通过实体引用将相关的xml片段引用进来,从而使二个文件成为一个整体。再次,在将对象转换成xml的时候,通过反射来获取相关的数据,并将数据写入xml格式中,这个地方还有提高。希望各位在看完此文后也能熟练的运用XML日志文件来对日志进行记录。
源代码下载:Jasen.XmlLogFileSample.rar XML日志文件源代码下载
Xml日志记录文件最优方案(附源代码)的更多相关文章
- Java学习-007-Log4J 日志记录配置文件详解及实例源代码
此文主要讲述在初学 Java 时,常用的 Log4J 日志记录配置文件详解及实例源代码整理.希望能对初学 Java 编程的亲们有所帮助.若有不足之处,敬请大神指正,不胜感激!源代码测试通过日期为:20 ...
- Java 标准日志工具 Log4j 的使用(附源代码)
源代码下载 Log4j 是事实上的 Java 标准日志工具.会不会用 Log4j 在一定程度上可以说是衡量一个开发人员是否是一位合格的 Java 程序员的标准.如果你是一名 Java 程序员,如果你还 ...
- 动态配置log4j2.xml日志输出文件的位置
目标:根据启动jar时传进main()的参数动态修改日志位置 一.修改启动项 MainMapLookup.setMainArguments(args);注:不要在lookup设置之前初始化log(如: ...
- PHP错误日志记录文件位置确定
1.确定web服务器 ( IIS, APACHE, NGINX 等) 以哪一种方式支持PHP,通常是有下面2种方式 通过模块加载的方式, 适用于apache 通过 CGI/fastCGI 模式, 该模 ...
- 扔掉log4j、log4j2,自己动手实现一个多功能日志记录框架,包含文件,数据库日志写入,实测5W+/秒日志文件写入,2W+/秒数据库日志写入,虽然它现在还没有logback那么强大
讲到log4j,现在国外基本是没有开发者用这个框架了,原因大致有几点,1.功能太少:2.效率低下:3.线程锁bug等等等各种莫名其妙的bug一直都没解决. 其实最重要的是log4j的作者自己也放弃了l ...
- Python开发之日志记录模块:logging
1 引言 最近在开发一个应用软件,为方便调试和后期维护,在代码中添加了日志,用的是Python内置的logging模块,看了许多博主的博文,颇有所得.不得不说,有许多博主大牛总结得确实很好.似乎我再写 ...
- Python学习 :常用模块(三)----- 日志记录
常用模块(三) 七.logging模块 日志中包含的信息应有正常的程序访问日志,还可能有错误.警告等信息输出 python的 logging 模块提供了标准的日志接口,你可以通过它存储各种格式的日志, ...
- Hibernate使用Log4j日志记录(使用xml文件)
日志记录使程序员能够将日志详细信息永久写入文件. Log4j和Logback框架可以在hibernate框架中使用来支持日志记录. 使用log4j执行日志记录有两种方法: 通过log4j.xml文件( ...
- log4j教程 11、日志记录到文件
要写日志信息到一个文件中,必须使用org.apache.log4j.FileAppender.有以下FileAppender的配置参数: FileAppender配置: 属性 描述 immediate ...
随机推荐
- iMX6 yocto平台QT交叉编译环境搭建
转:https://blog.csdn.net/morixinguan/article/details/79351909 . /opt/fsl-imx-fb/4.9.11-1.0.0/environm ...
- python补充知识点
1. 在python2中用xrange,在python3中直接使用range就好了 2. 常数 None在逻辑判断的时候指代False,其他方式不代表True或者False 3. for循环只作用域容 ...
- Java中的UDP协议编程
一. UDP协议定义 UDP协议的全称是用户数据报,在网络中它与TCP协议一样用于处理数据包.在OSI模型中,在第四层——传输层,处于IP协议的上一层.UDP有不提供数据报分组.组装和不能对数据包 ...
- Centos6.5安装php5.6.7
1. 下载 官网:http://php.net/downloads.php wget http://cn2.php.net/get/php-5.6.7.tar.gz/from/this/mirror ...
- spark学习4(zookeeper3.4集群搭建)
第一步:zookeeper安装 通过WinSCP软件将zookeeper-3.4.8.tar.gz软件传送到/usr/zookeeper/目录下 [root@spark1 zookeeper]# ch ...
- 电子商务的几种模式,b2b,c2c等
B2B(Business to Business) ——这是指商家与商家建立的商业关系.(最早的一种模式) C2C (Customer to Consumer) ——个人与个人的商业关系,也就是消费者 ...
- java——base64 加密和解密
base64 一.加密 *.若有要求输入字符必须为UTF-8: 则需str.getByte("utf-8"); //在getByte()中指定utf-8编码,否则中文字符将被加密 ...
- Windows下MetaMap工具安装
Windows下MetaMap工具安装 一.Main MetaMap安装 Prerequisties 12G磁盘空间 JAVA6 or newer JRE or SDK installed Downl ...
- nova conductor
nova conductor是一个RPC 服务,所有支持的API都在 nova.conductor.rpcapi.ConductorAPI 它是stateless,可以水平扩展. 优点: 安全: 如果 ...
- spring boot: Annotation 注解之@Target的用法介绍
前言 目前,越来越多的架构设计在使用注解,例如spring3.0.struts2等框架.让我们先来看看注解的定义.如下是一段使用了JDK 5 Annotation @Target的代码: @Targe ...