如何开发 MCP 服务?保姆级教程!
最近这段时间有个 AI 相关的概念特别火,叫 MCP,全称模型上下文协议(Model Context Protocol)。这是由 Anthropic 推出的一项开放标准,目标是为大型语言模型和 AI 助手提供一个统一、标准化的接口,使 AI 能够轻松操作外部工具并完成更复杂的任务。
这篇文章,就带大家速通 MCP,了解其核心概念,并且以我们给自己产品 面试鸭 开发的面试搜题 MCP 服务为例,带大家实战 MCP 服务端和客户端的开发!
MCP 为啥如此重要?
以前,如果想让 AI 处理我们的数据,基本只能靠预训练数据或者上传数据,既麻烦又低效。而且,就算是很强大的 AI 模型,也会有数据隔离的问题,无法直接访问新数据,每次有新的数据进来,都要重新训练或上传,扩展起来比较困难。
现在,MCP 解决了这个问题,它突破了模型对静态知识库的依赖,使其具备更强的动态交互能力,能够像人类一样调用搜索引擎、访问本地文件、连接 API 服务,甚至直接操作第三方库。所以 MCP 相当于在 AI 和数据之间架起了一座桥。更重要的是,只要大家都遵循 MCP 这套协议,AI 就能无缝连接本地数据、互联网资源、开发工具、生产力软件,甚至整个社区生态,实现真正的“万物互联”,这将极大提升 AI 的协作和工作能力,价值不可估量。
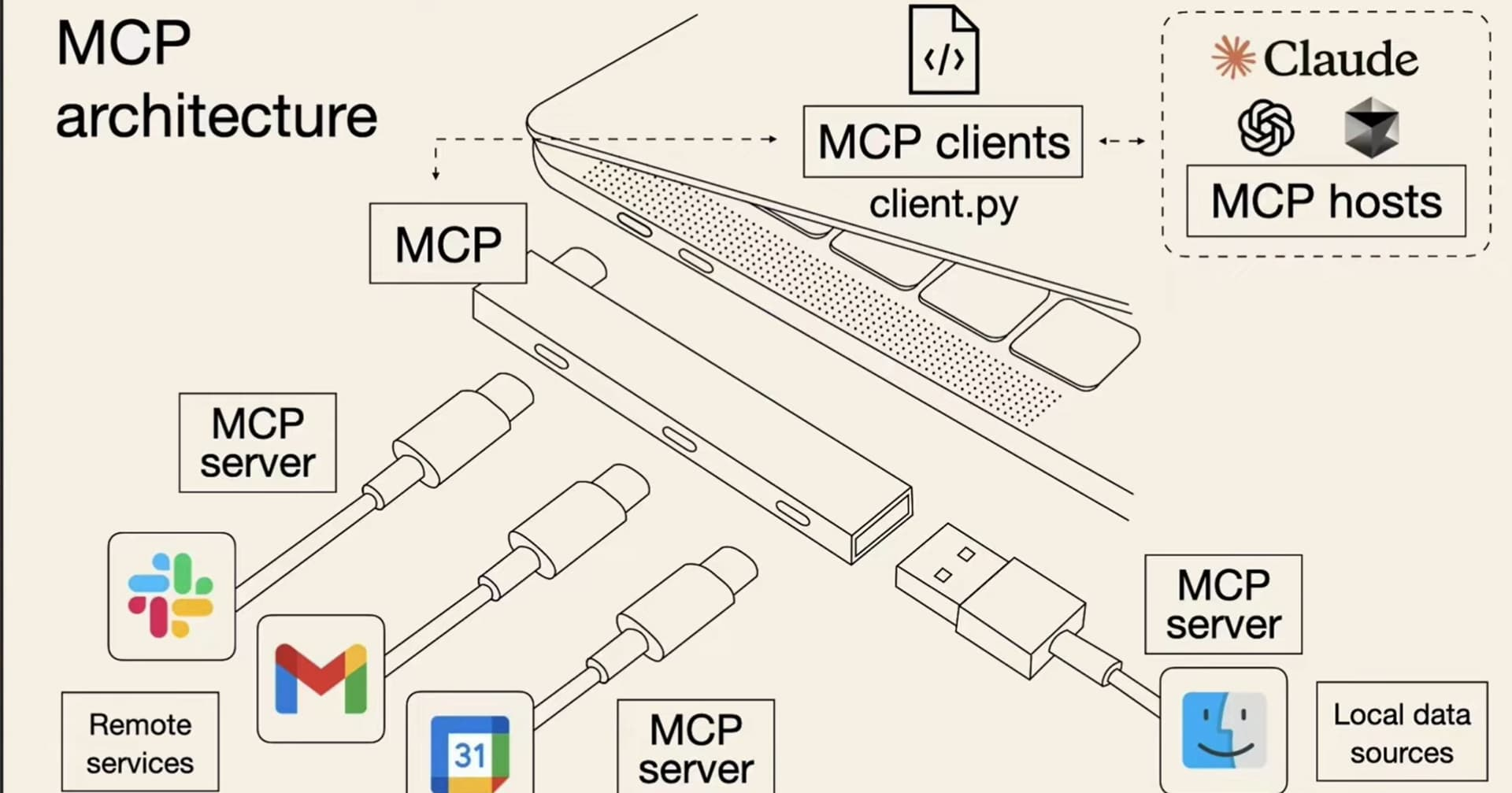
MCP 总体架构
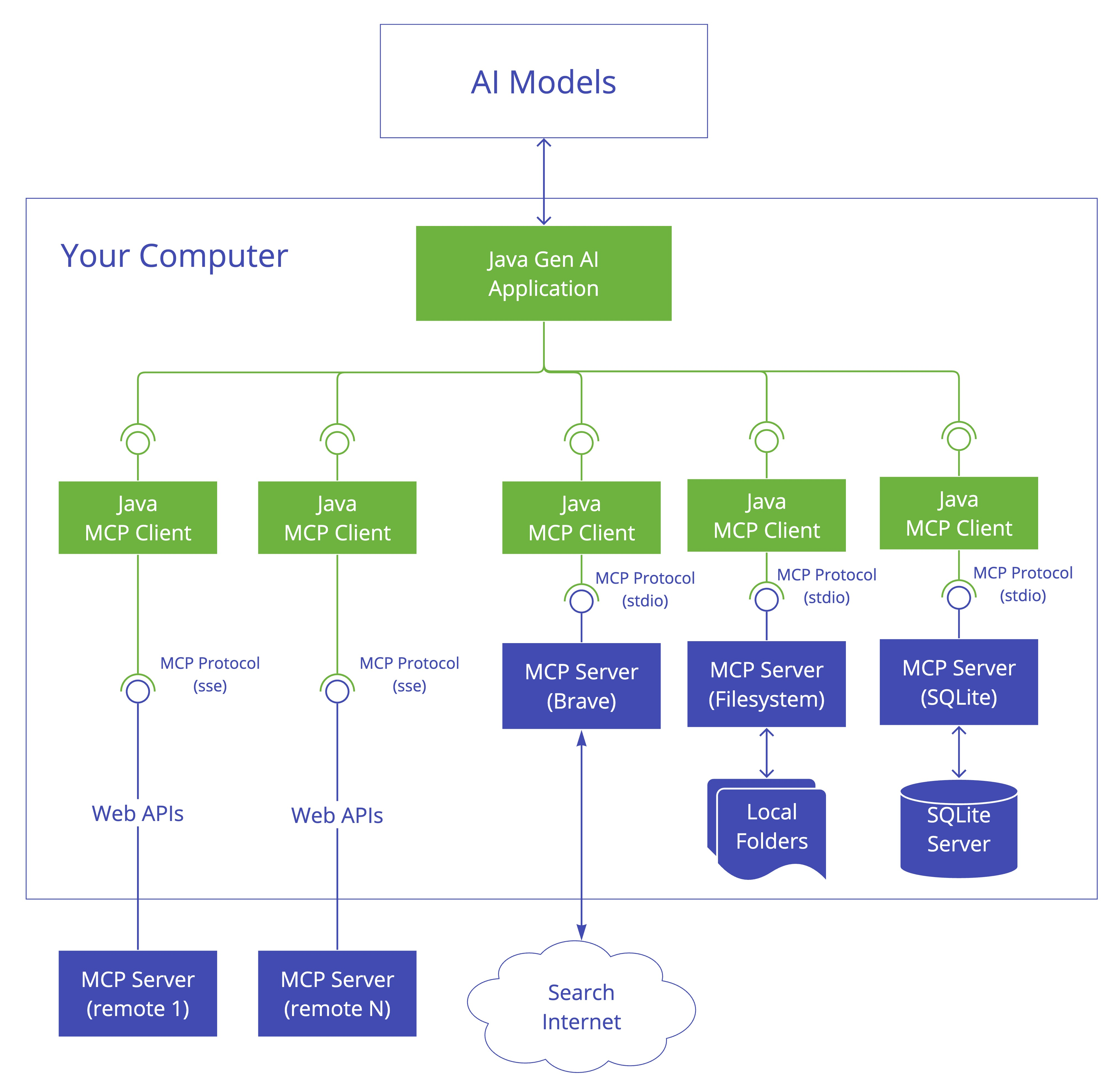
MCP 的核心是 “客户端 - 服务器” 架构,其中 MCP 客户端主机可以连接到多个服务器。客户端主机是指希望通过 MCP 访问数据的程序,比如 Claude Desktop、IDE 或 AI 工具。
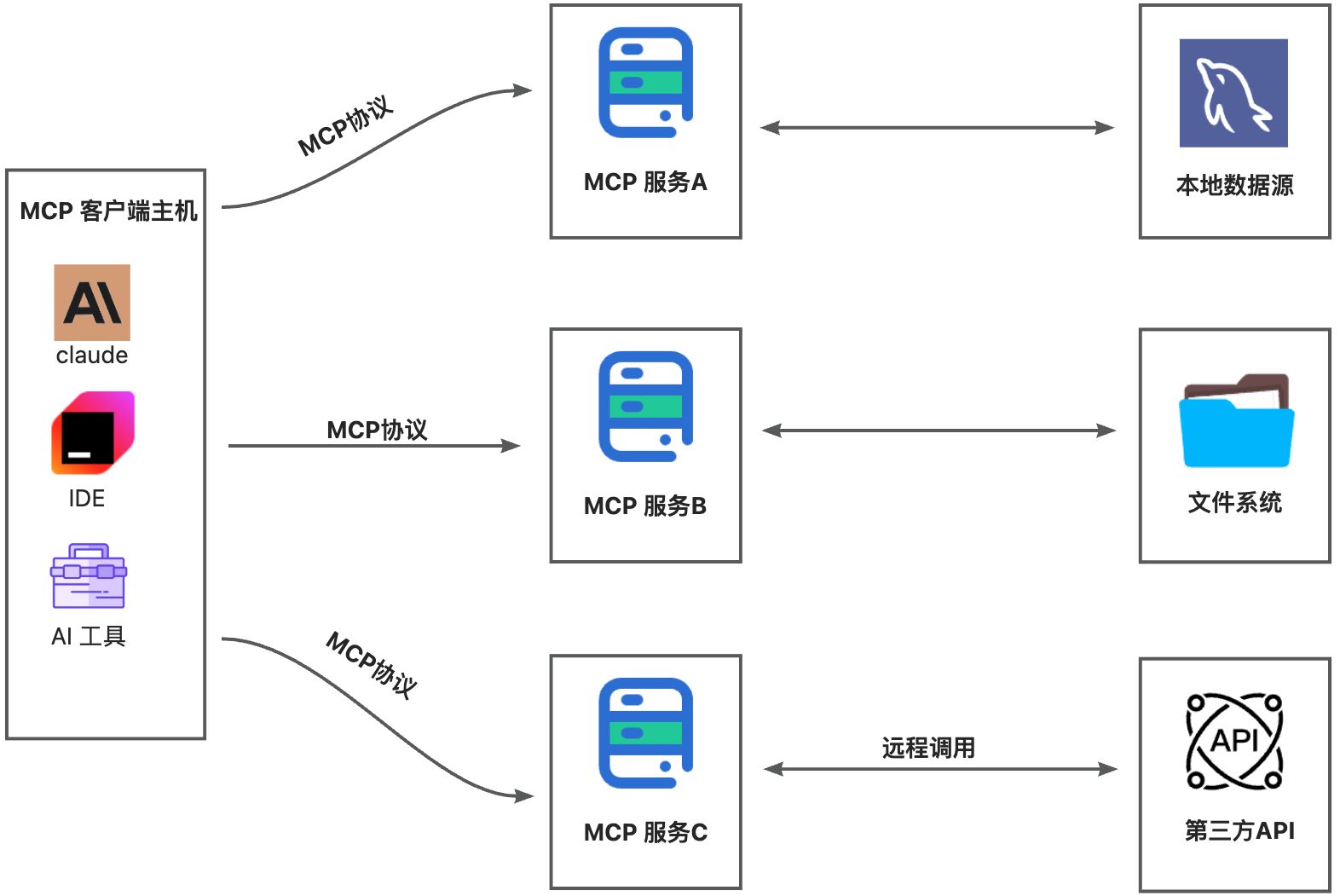
MCP Java SDK 架构
我们可以使用 Spring AI 框架来开发 MCP 服务,可以先通过 官方文档 来了解其基本架构。
遵循三层架构:
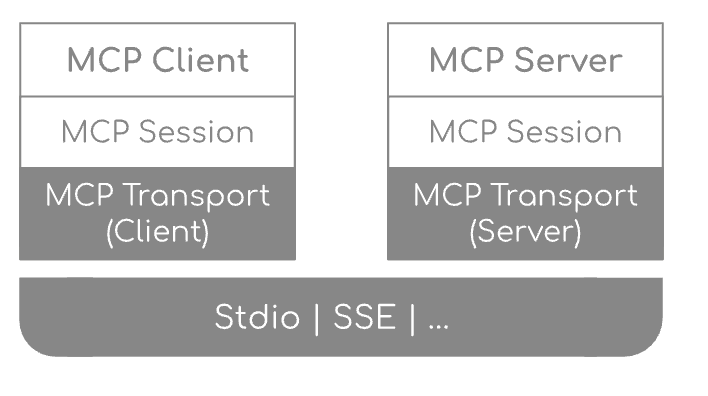
我们分别来看每一层的作用:
客户端/服务器层:McpClient 处理客户端操作,而 McpServer 管理服务器端协议操作。两者都使用 McpSession 进行通信管理。
会话层(McpSession):通过 DefaultMcpSession 实现管理通信模式和状态。
传输层(McpTransport):处理 JSON-RPC 消息序列化和反序列化,支持多种传输实现。
MCP 客户端
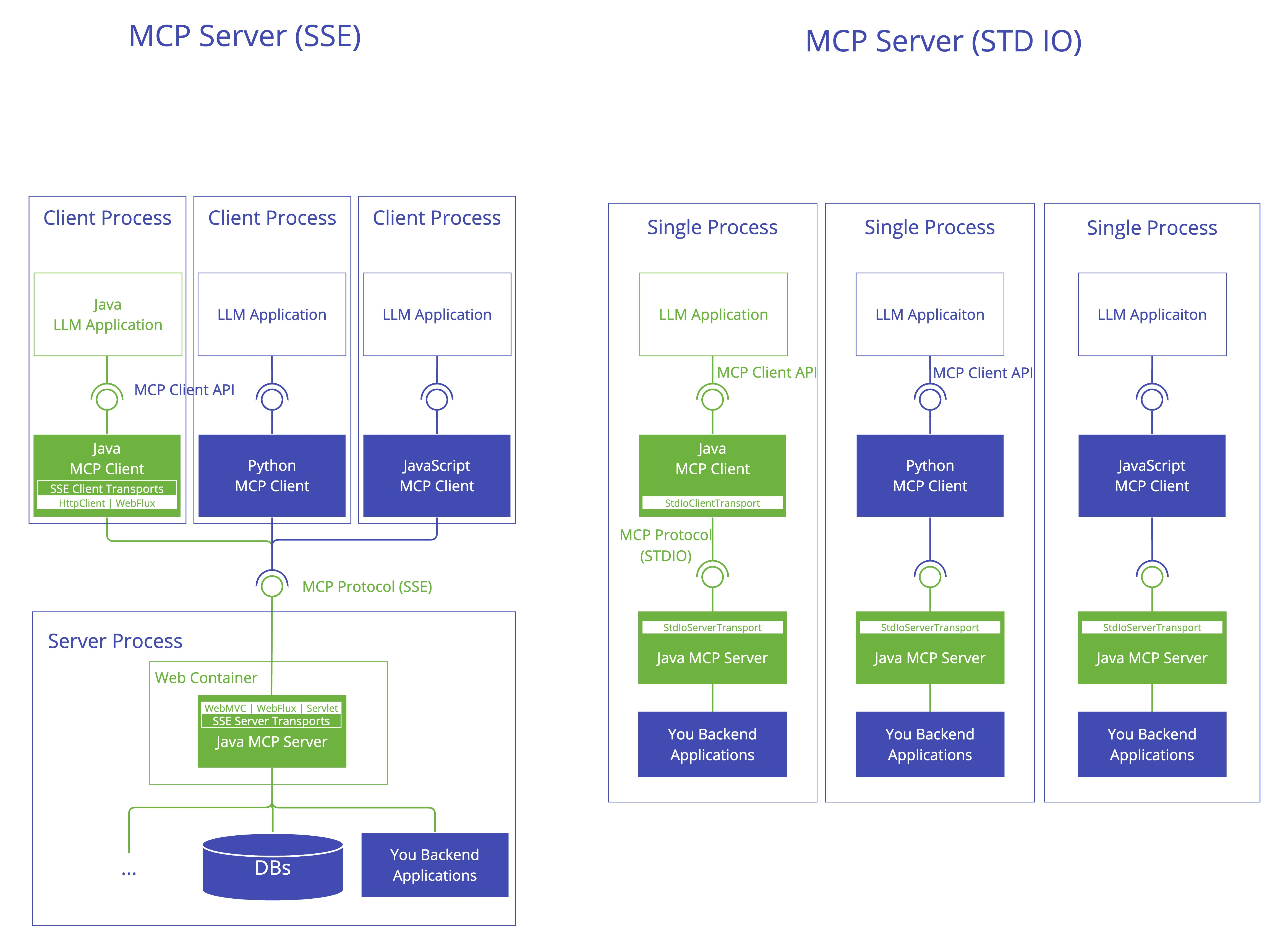
MCP 客户端是 MCP 架构中的关键组件,主要负责和 MCP 服务器建立连接并进行通信。它能自动匹配服务器的协议版本,确认可用功能,并负责数据传输和 JSON-RPC 交互。此外,它还能发现和使用各种工具、管理资源,并与提示系统进行交互。
除了这些核心功能,MCP 客户端还支持一些额外特性,比如根管理、采样控制,以及同步或异步操作。为了适应不同场景,它提供了多种数据传输方式,包括标准输入/输出、基于 Java HttpClient 和 WebFlux 的 SSE 传输。
MCP 服务端
MCP 服务器是整个 MCP 架构的核心部分,主要用来为客户端提供各种工具、资源和功能支持。它负责处理客户端的请求,包括解析协议、提供工具、管理资源以及处理各种交互信息。同时,它还能记录日志、发送通知,并且支持多个客户端同时连接,保证高效的通信和协作。它可以通过多种方式进行数据传输,比如标准输入/输出、Servlet、WebFlux 和 WebMVC,满足不同应用场景的需求。
Spring AI 集成 MCP
可以通过引入一些依赖,直接让 Spring AI 和 MCP 进行集成,在 Spring Boot 项目中轻松使用。
比如客户端启动器:
spring-ai-starter-mcp-client:核心启动器,提供 STDIO 和基于 HTTP 的 SSE 支持
spring-ai-starter-mcp-client-webflux:基于 WebFlux 的 SSE 流式传输实现
服务器启动器:
spring-ai-starter-mcp-server:核心服务器,具有 STDIO 传输支持
spring-ai-starter-mcp-server-webmvc:基于 Spring MVC 的 SSE 流式传输实现
spring-ai-starter-mcp-server-webflux:基于 WebFlux 的 SSE 流式传输实现
下面我们来实战 MCP 项目的开发。
MCP 开发
MCP 的使用分为两种模式,STDIO 模式(本地运行)和 SSE 模式(远程服务)。
MCP 服务端(基于stdio标准流)
基于 stdio 的实现是最常见的 MCP 客户端方案,它通过标准输入输出流与 MCP 服务器进行通信。这种方式简单直观,能够直接通过进程间通信实现数据交互,避免了额外的网络通信开销。特别适用于本地部署的 MCP 服务器,可以在同一台机器上启动 MCP 服务器进程,与客户端无缝对接。
1、引入依赖
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-mcp-server-spring-boot-starter</artifactId>
<version>1.0.0-M6</version>
</dependency>
2、配置 MCP 服务端
spring:
application:
name: mcp-server
main:
web-application-type: none # 必须禁用web应用类型
banner-mode: off # 禁用banner
ai:
mcp:
server:
stdio: true # 启用stdio模式
name: mcp-server # 服务器名称
version: 0.0.1 # 服务器版本
3、实现 MCP 工具
@Tool 是 Spring AI MCP 框架中用于快速暴露业务能力为 AI 工具的核心注解,该注解实现 Java 方法与 MCP 协议工具的自动映射,并且可以通过注解的属性 description,帮助人工智能模型根据用户输入的信息决定是否调用这些工具,并返回相应的结果。
下面是一段示例代码:
/**
* 根据搜索词搜索面试鸭面试题目
*
* @param searchText 搜索词
* @return 面试鸭搜索结果的题目链接
*/
@Tool(description = "根据搜索词搜索面试鸭面试题目(如果用户提的问题的技术面试题,优先搜索面试鸭的题目列表)")
public String callMianshiya(String searchText) {
// 执行从面试鸭数据库中搜索题目的逻辑(代码省略)
System.out.println("用户要搜索:" + searchText);
}
4、注册 MCP 工具
最后向 MCP 服务注册刚刚写的工具:
@Bean
public ToolCallbackProvider serverTools(MianshiyaService mianshiyaService) {
return MethodToolCallbackProvider.builder()
.toolObjects(mianshiyaService)
.build();
}
这段代码定义了一个 Spring 的 Bean,用于将面试鸭的题目搜索服务MianshiyaService中所有用 @Tool 注解标记的方法注册为工具,供 AI 模型调用。ToolCallbackProvider是 Spring AI 中的一个接口,用于定义工具发现机制,主要负责将那些使用 @Tool 注解标记的方法转换为工具回调对象,并提供给 ChatClient 或ChatModel 使用,以便 AI 模型能够在对话过程中调用这些工具。
5、运行服务端
MCP 服务端代码写完之后,直接用 Maven 打包运行项目:
mvn clean package -DskipTests
MCP 客户端(基于 stdio 标准流)
1、引入依赖
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-mcp-client-spring-boot-starter</artifactId>
<version>1.0.0-M6</version>
</dependency>
2、配置 MCP 服务器
因为刚刚服务端是通过stdio实现的,需要在application.yml中配置MCP服务器的一些参数:
spring:
ai:
mcp:
client:
stdio:
# 指定MCP服务器配置文件
servers-configuration: classpath:/mcp-servers-config.json
mandatory-file-encoding: UTF-8
其中 mcp-servers-config.json 的配置如下:
{
"mcpServers": {
"mianshiyaServer": {
"command": "java",
"args": [
"-Dspring.ai.mcp.server.stdio=true",
"-Dspring.main.web-application-type=none",
"-Dlogging.pattern.console=",
"-jar",
"/Users/yupi/Documents/mcp-server/target/mcp-server-0.0.1-SNAPSHOT.jar"
],
"env": {}
}
}
}
这个配置文件设置了 MCP 客户端的基本配置,包括 Java 命令参数,服务端 jar 包的绝对路径等。上述的 JSON 配置文件也可以直接写在application.yml里,效果是一样的。
mcp:
client:
stdio:
connections:
server1:
command: java
args:
- -Dspring.ai.mcp.server.stdio=true
- -Dspring.main.web-application-type=none
- -Dlogging.pattern.console=
- -jar
- /Users/yupi/Documents/mcp-server/target/mcp-server-0.0.1-SNAPSHOT.jar
客户端我们使用阿里巴巴的通义千问模型,所以引入 spring-ai-alibaba-starter 依赖,如果你使用的是其他的模型,也可以使用对应的依赖项,比如 openAI 引入 spring-ai-openai-spring-boot-starter 这个依赖就行了。还需要配置大模型的密钥等信息,key 可以直接 去官网 申请,模型我们用的是 qwen-max。
spring:
ai:
dashscope:
api-key: ${通义千问的key}
chat:
options:
model: qwen-max
3、初始化聊天客户端,一行代码就搞定了:
@Bean
public ChatClient initChatClient(ChatClient.Builder chatClientBuilder,
ToolCallbackProvider mcpTools) {
return chatClientBuilder.defaultTools(mcpTools).build();
}
这段代码定义了一个 Spring Bean,用于初始化一个AI 聊天客户端,里面有两个参数:
ChatClient.Builder 是 Spring AI 提供的 AI 聊天客户端构建器,用于构建 ChatClient 实例,是由 Spring AI自动注入的
另一个是 ToolCallbackProvider,用于从 MCP 服务端发现并获取 AI 工具。
4、接口调用
直接调用ChatClient,将面试问题输入给AI即可,也不需要写过多的 prompt,因为在 MCP 服务端的工具描述中,已经写的比较详细了 —— 比如用户想要搜索技术面试题,就会自动调用刚刚写的工具。
普通调用:
@PostMapping(value = "/ai/answer")
public String generate(@RequestBody AskRequest request) {
return chatClient.prompt()
.user(request.getContent())
.call()
.content();
}
如果需要实时输出返回内容,可以进行 SSE 流式调用:
@PostMapping(value = "/ai/answer/sse", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public Flux<String> generateStreamAsString(@RequestBody AskRequest request) {
Flux<String> content = chatClient.prompt()
.user(request.getContent())
.stream()
.content();
return content
.concatWith(Flux.just("[complete]"));
}
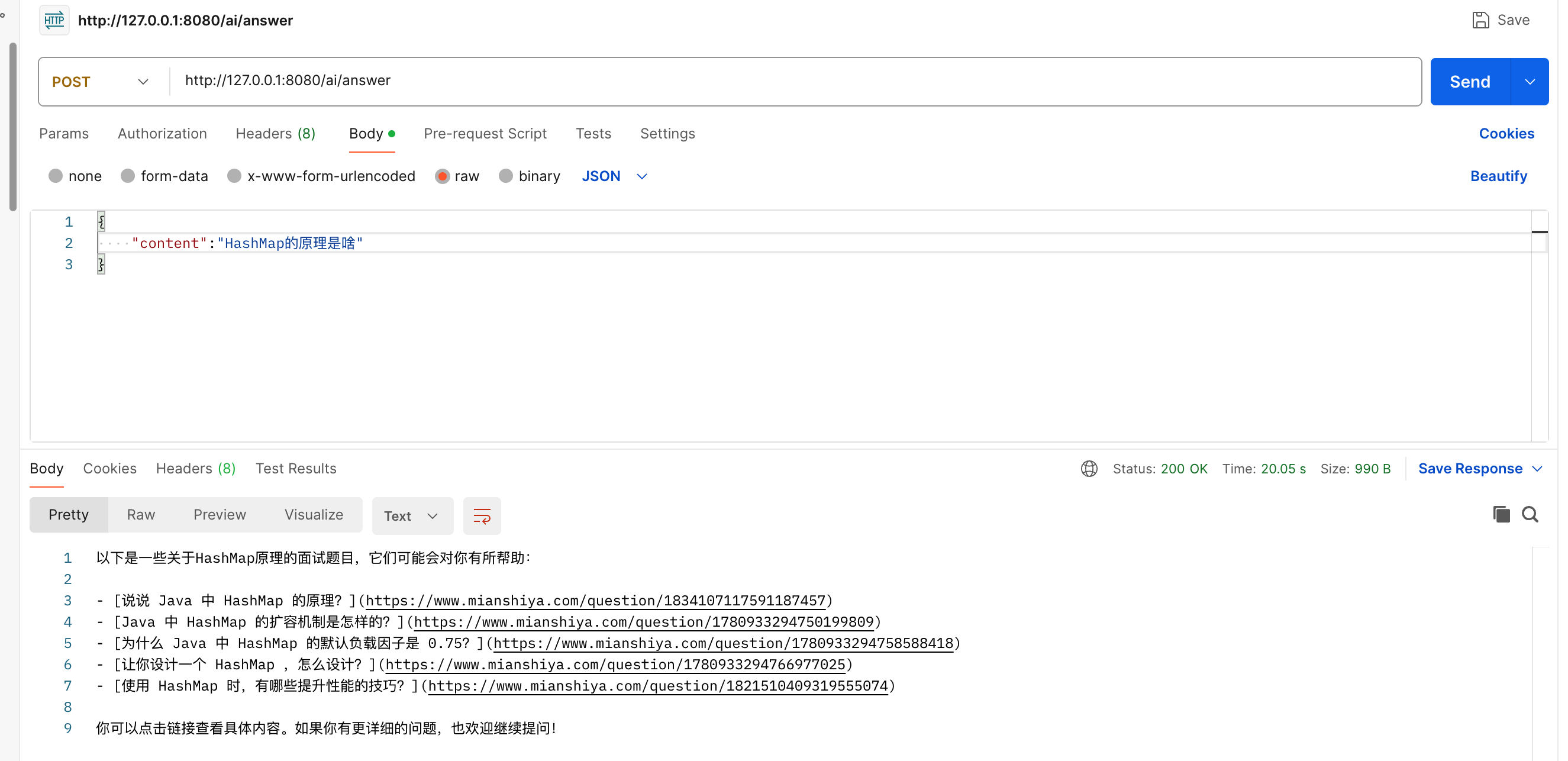
最后测试一下,输入面试题目 “HashMap的原理是啥”,就会返回 面试鸭 的题目以及链接。
MCP 服务端(基于 SSE)
除了基于 stdio 的实现外,Spring AI 还提供了基于 Server-Sent Events (SSE) 的 MCP 客户端方案。相较于 stdio 方式,SSE 更适用于远程部署的 MCP 服务器,客户端可以通过标准 HTTP 协议与服务器建立连接,实现单向的实时数据推送。基于 SSE 的 MCP 服务器支持被多个客户端远程调用。
1、引入依赖
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-mcp-server-webflux-spring-boot-starter</artifactId>
<version>1.0.0-M6</version>
</dependency>
2、配置 MCP 服务端
server:
port: 8090
spring:
application:
name: mcp-server
ai:
mcp:
server:
name: mcp-server # MCP服务器名称
version: 0.0.1 # 服务器版本号
除了引入的依赖包不一样,以及配置文件不同,其他的不需要修改。
3、运行服务端
MCP 服务端写完之后,直接打包运行:
mvn clean package -DskipTests
直接用 jar 选项运行 MCP 服务端:
java -jar target/mcp-server-0.0.1-SNAPSHOT.jar --spring.profiles.active=prod
MCP 客户端(基于 SSE)
1、引入依赖
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-mcp-client-webflux-spring-boot-starter</artifactId>
<version>1.0.0-M6</version>
</dependency>
2、配置 MCP 服务器
因为刚刚服务端是通过 SSE 实现的,需要在application.yml中配置 MCP 服务器的 URL 端口:
spring:
ai:
mcp:
client:
enabled: true
name: mcp-client
version: 1.0.0
request-timeout: 30s
type: ASYNC # 类型同步或者异步
sse:
connections:
server1:
url: http://localhost:8090
和 MCP 服务端的修改一样, 除了依赖和配置的修改,其他的也不需要调整。
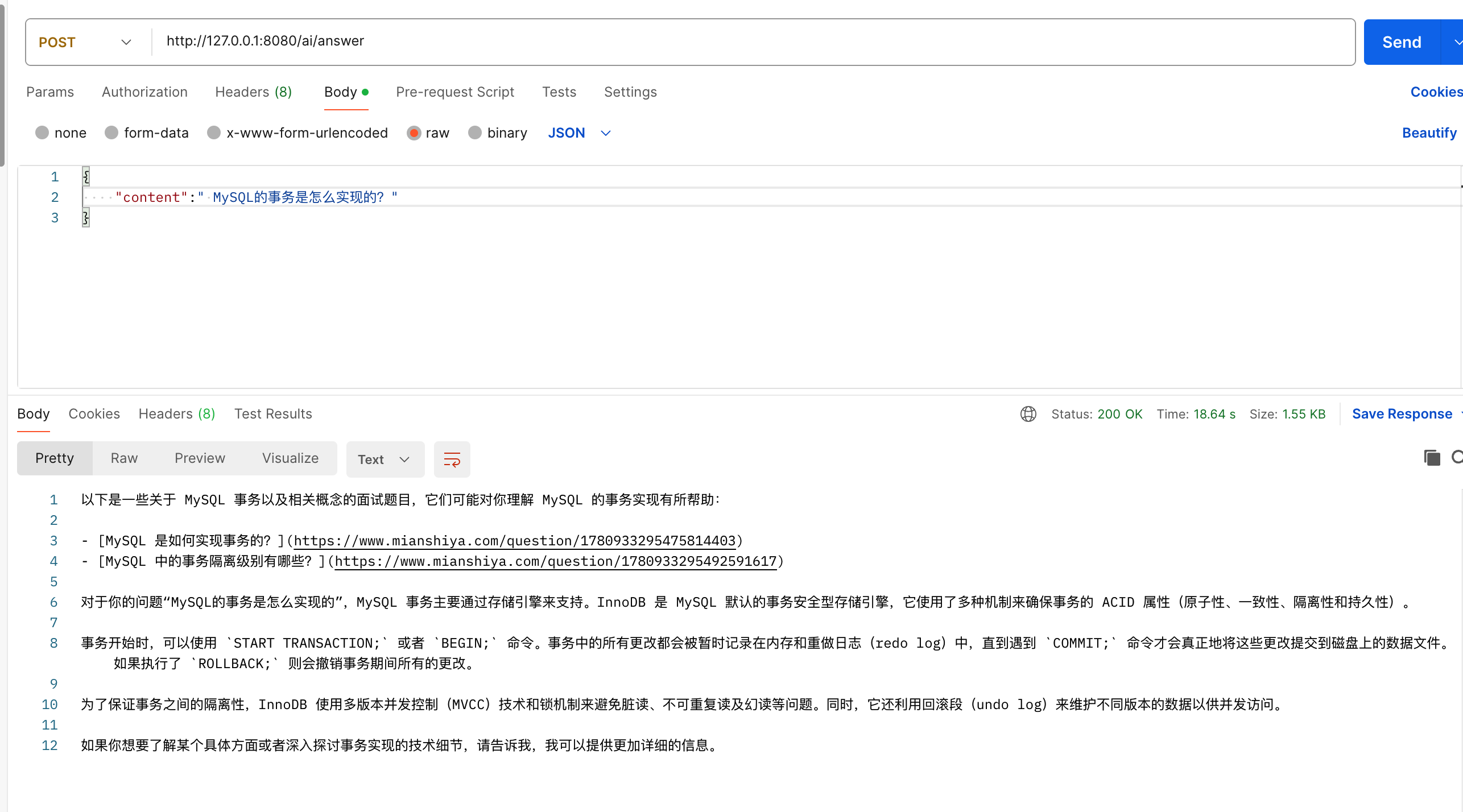
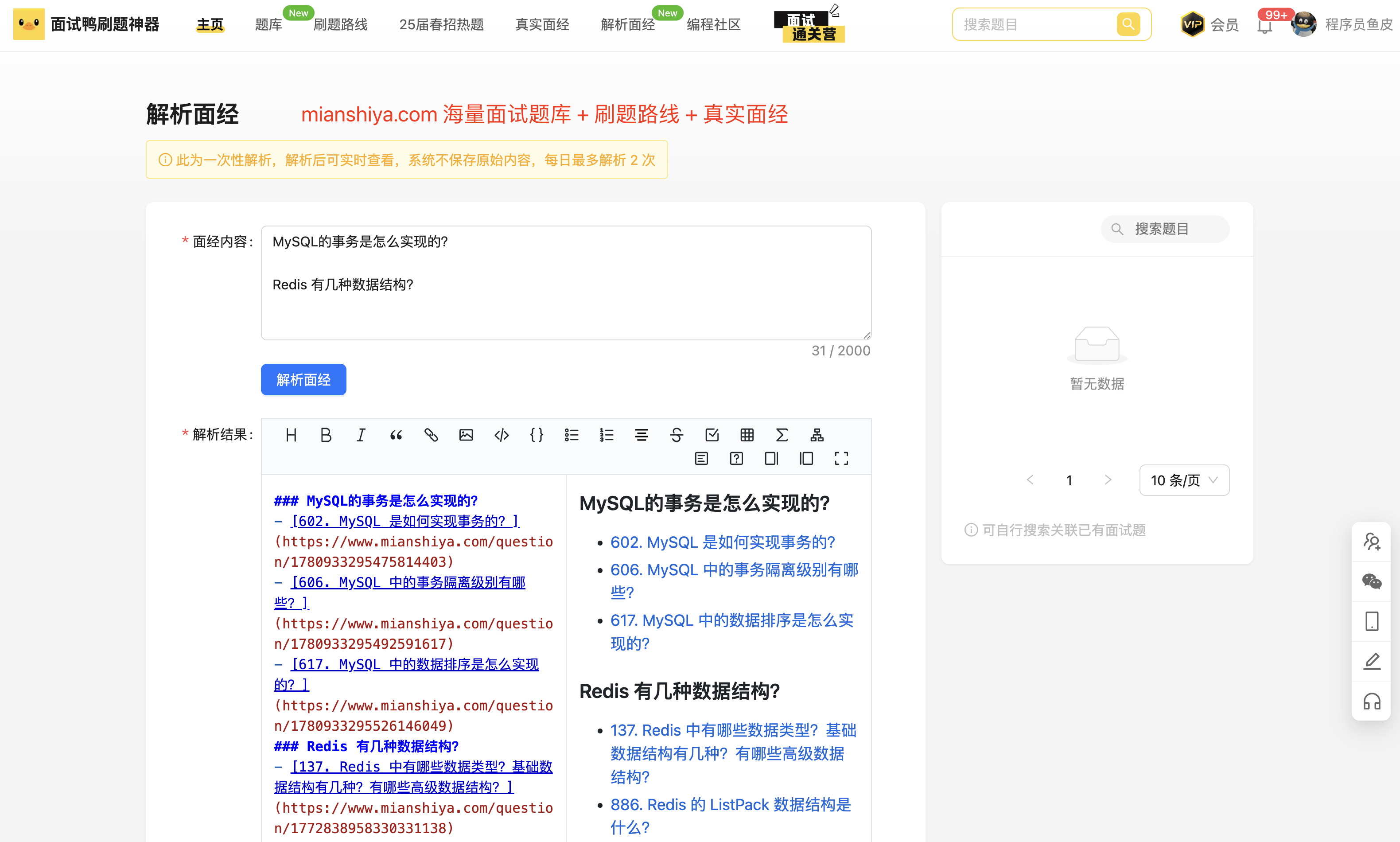
最后测试一下,输入面试题目 “MySQL的事务是怎么实现的?”,就会返回 面试鸭 的题目以及链接等。
软件使用 MCP
除了利用程序去调用 MCP 服务外,MCP 服务端还任意支持 MCP 协议的智能体助手,比如 Claude、Cursor 以及 Cherry Studio 等,都可以快速接入。(前提需要 Java 运行时环境)
首先下载我们 开源的面试鸭 MCP 服务 代码到本地:
git clone https://github.com/yuyuanweb/mcp-mianshiya-server
然后使用 Maven 打包构建项目:
cd mcp-mianshiya-server
mvn clean package
下面我们以 Cherry Studio 这样一个 AI 客户端软件为例,演示如何使用 MCP 服务。
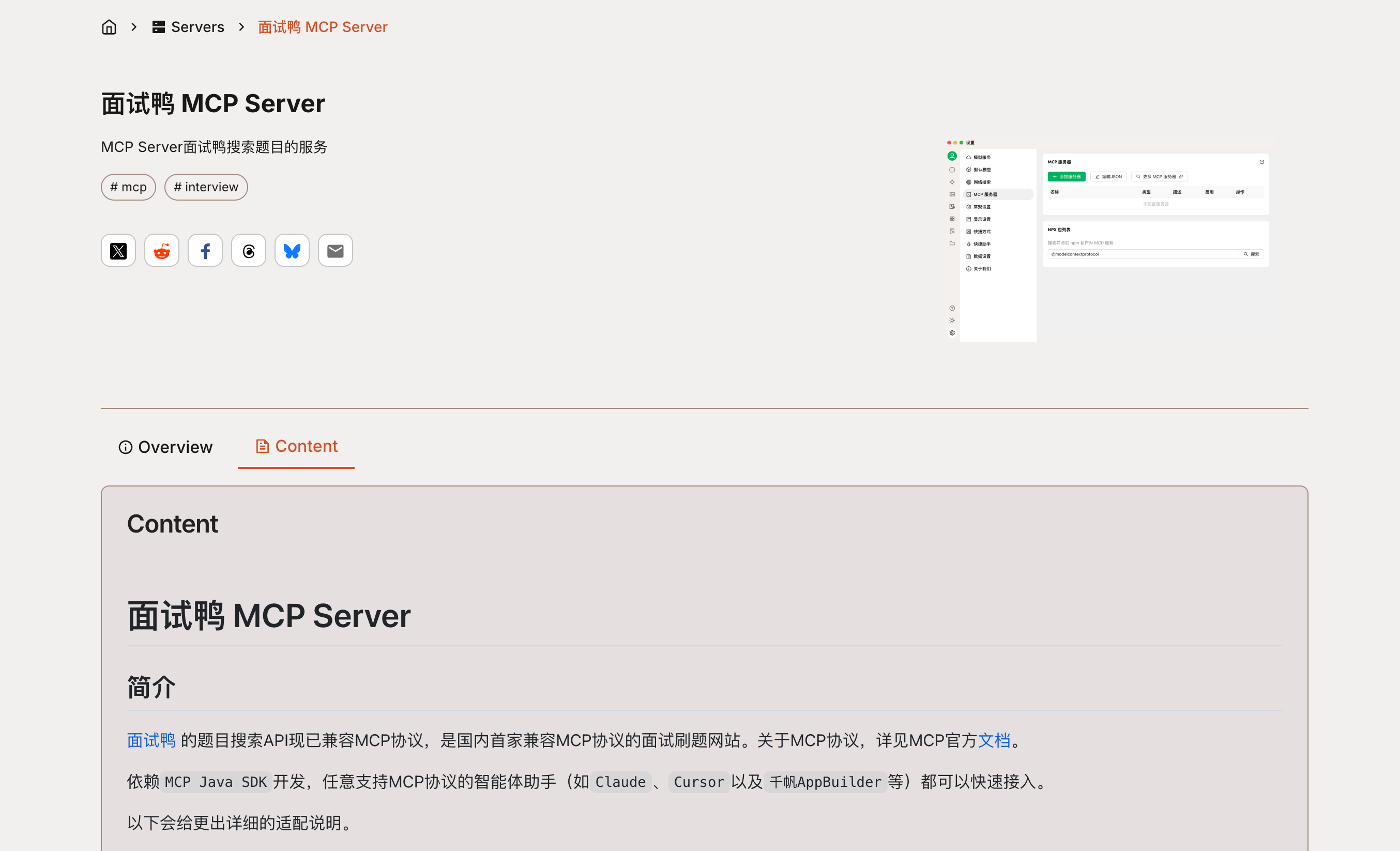
1、打开 Cherry Studio 的 “设置”,点击 “MCP 服务器”:
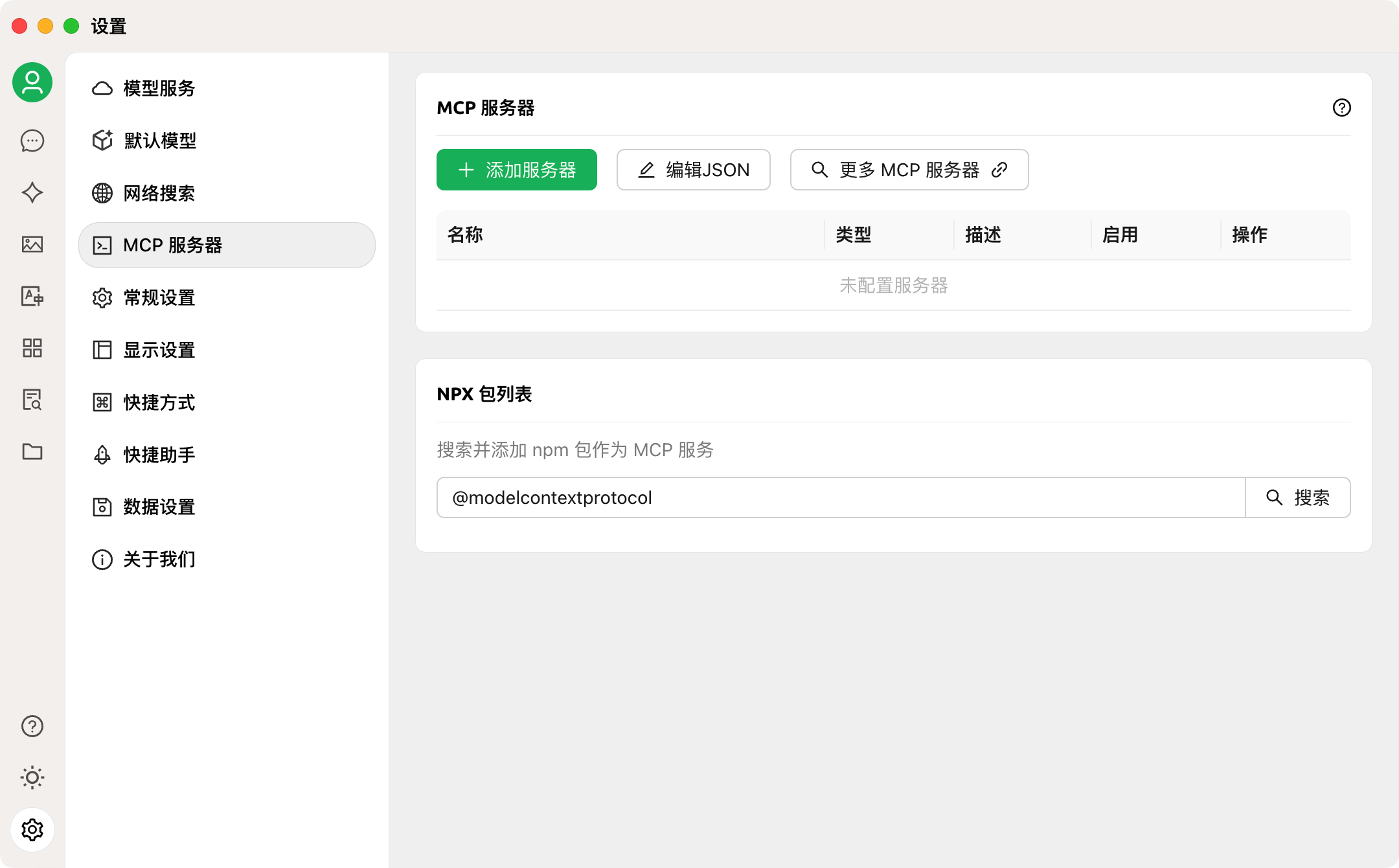
2、点击 “编辑 JSON”,将以下 MCP 配置添加到配置文件中:
{
"mcpServers": {
"mianshiyaServer": {
"command": "java",
"args": [
"-Dspring.ai.mcp.server.stdio=true",
"-Dspring.main.web-application-type=none",
"-Dlogging.pattern.console=",
"-jar",
"/yourPath/mcp-server-0.0.1-SNAPSHOT.jar"
],
"env": {}
}
}
}
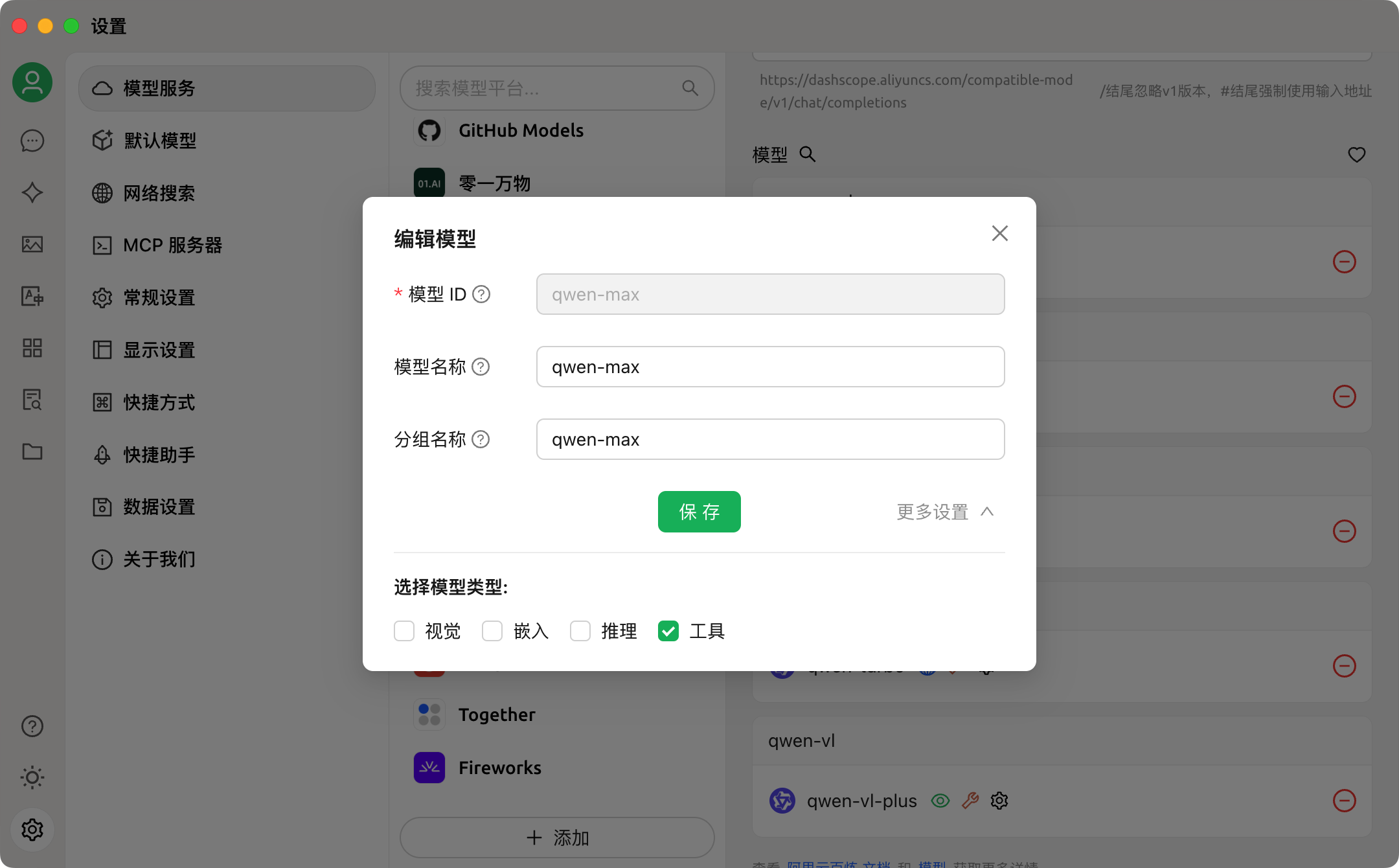
3、在 “设置 => 模型服务” 里选择一个模型,输入 API 密钥,选择模型设置,勾选下工具函数调用功能:
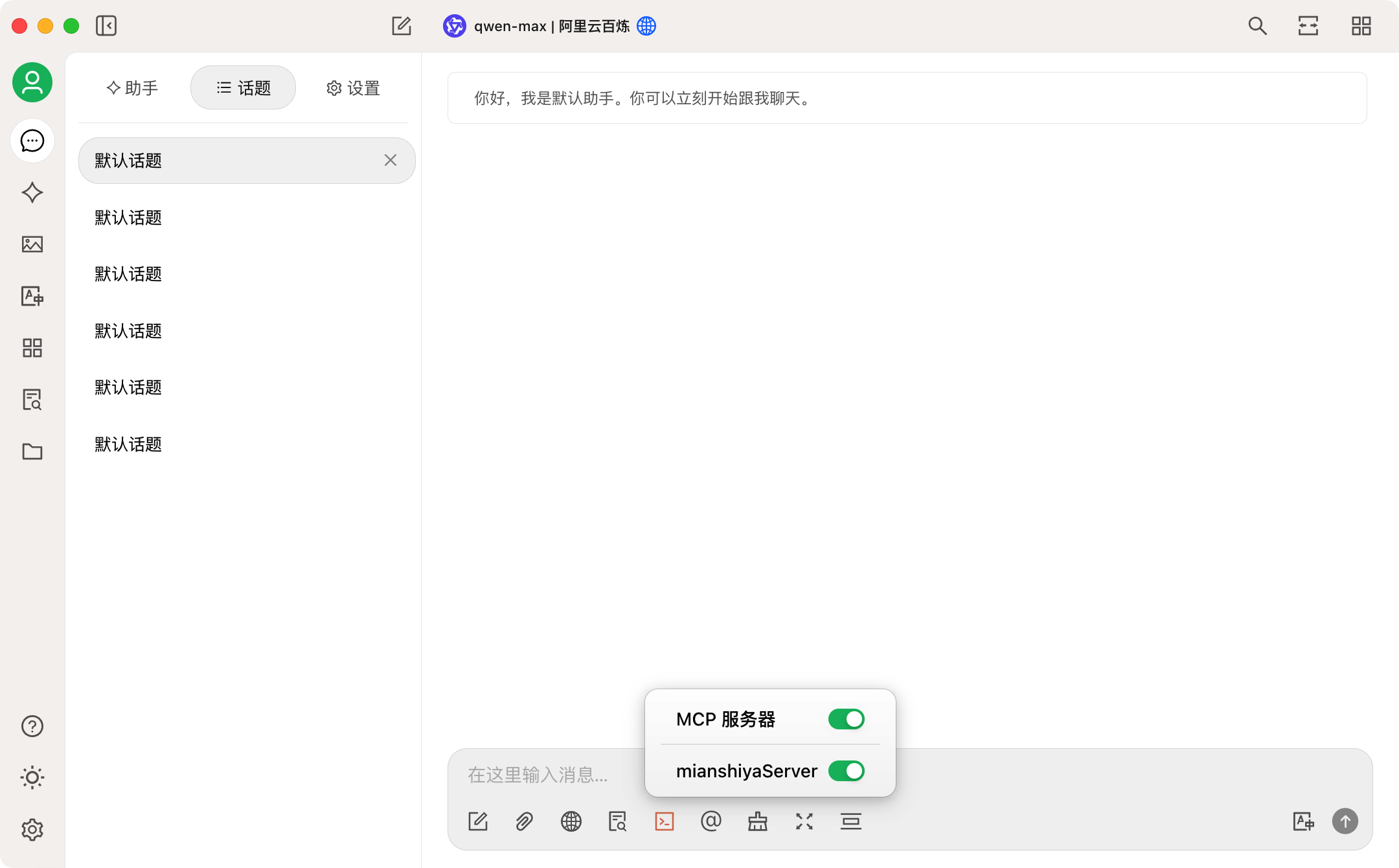
4、进入聊天页面,在输入框下面勾选开启 MCP 服务:
配置完成,尝试搜索下面试题目,效果不戳!
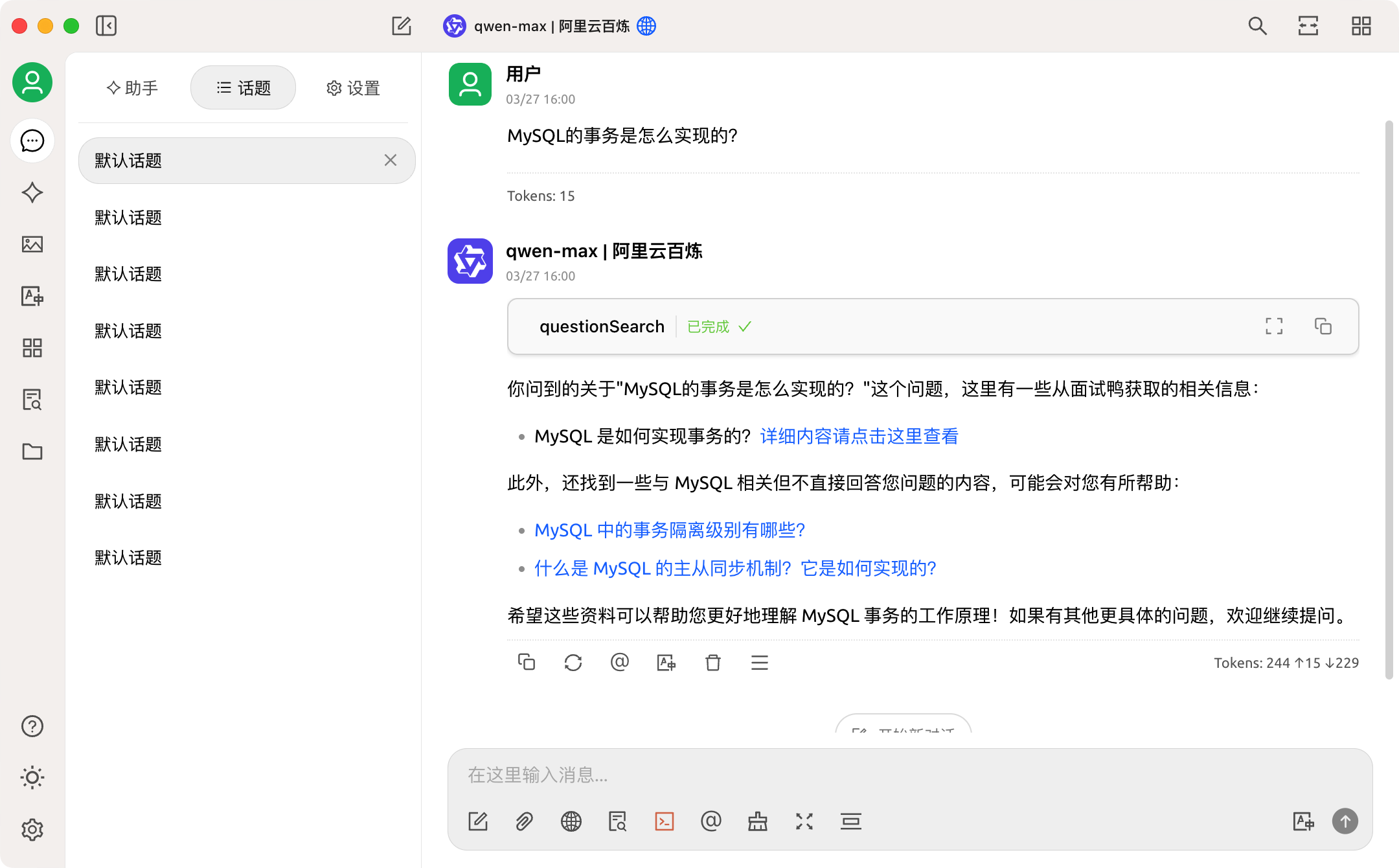
甚至还进行面经解析,返回多个面试题目与答案的链接!
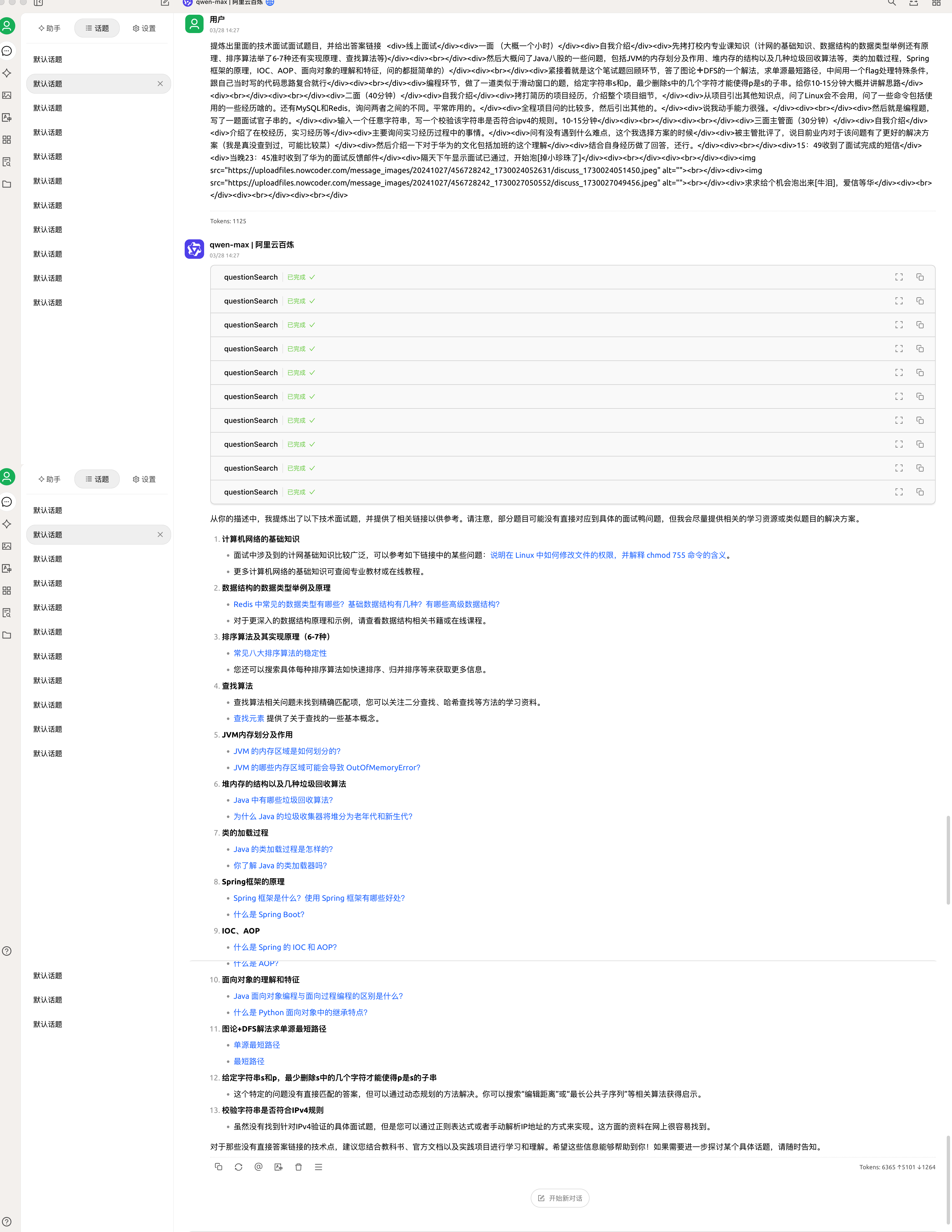
当然这个功能我们面试鸭官方也实现了,帮助大家面试复盘:
上传 MCP 服务
和开发一个 APP 一样,我们也可以把做好的 MCP 服务分享到第三方 MCP 服务平台。比如 MCP.so,可以理解为 MCP 服务的应用市场。
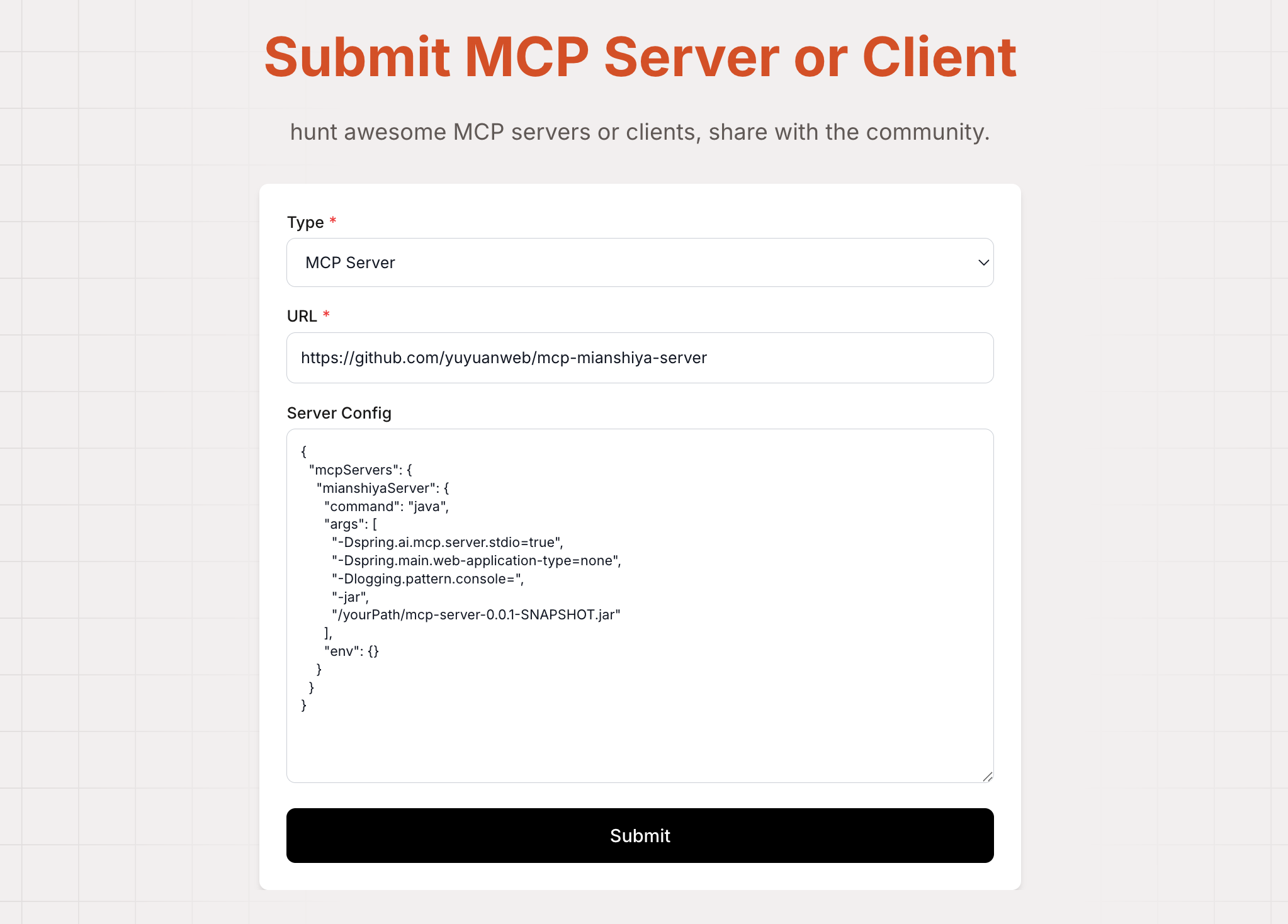
直接点击头像左侧的提交按钮,然后填写 MCP 服务的项目地址、以及服务器配置实例,点击提交即可。
提交完成后就可以在平台搜索到了:
OK 就分享到这里,学会的话记得点赞收藏哦。也欢迎大家在评论区交流你对 MCP 的看法和理解~
更多编程学习资源
如何开发 MCP 服务?保姆级教程!的更多相关文章
- Eclipse for C/C++ 开发环境部署保姆级教程
Eclipse for C/C++ 开发环境部署保姆级教程 工欲善其事,必先利其器. 对开发人员来说,顺手的开发工具必定事半功倍.自学编程的小白不知道该选择那个开发工具,Eclipse作为一个功能强大 ...
- 强大博客搭建全过程(1)-hexo博客搭建保姆级教程
1. 前言 本人本来使用国内的开源项目solo搭建了博客,但感觉1核CPU2G内存的服务器,还是稍微有点重,包括服务器内还搭建了数据库.如果自己开发然后搭建,耗费时间又比较多,于是乎开始寻找轻量型的博 ...
- 自建本地服务器,自建Web服务器——保姆级教程!
搭建本地服务器,Web服务器--保姆级教程! 本文首发于https://blog.chens.life/How-to-build-your-own-server.html. 先上图!大致思路就是如此. ...
- RocketMQ保姆级教程
大家好,我是三友~~ 上周花了一点时间从头到尾.从无到有地搭建了一套RocketMQ的环境,觉得还挺easy的,所以就写篇文章分享给大家. 整篇文章可以大致分为三个部分,第一部分属于一些核心概念和工作 ...
- 保姆级教程——Ubuntu16.04 Server下深度学习环境搭建:安装CUDA8.0,cuDNN6.0,Bazel0.5.4,源码编译安装TensorFlow1.4.0(GPU版)
写在前面 本文叙述了在Ubuntu16.04 Server下安装CUDA8.0,cuDNN6.0以及源码编译安装TensorFlow1.4.0(GPU版)的亲身经历,包括遇到的问题及解决办法,也有一些 ...
- 保姆级教程!手把手教你使用Longhorn管理云原生分布式SQL数据库!
作者简介 Jimmy Guerrero,在开发者关系团队和开源社区拥有20多年的经验.他目前领导YugabyteDB的社区和市场团队. 本文来自Rancher Labs Longhorn是Kubern ...
- ElasticSearch入门篇(保姆级教程)
本章将介绍:ElasticSearch的作用,搭建elasticsearch的环境(Windows/Linux),ElasticSearch集群的搭建,可视化客户端插件elasticsearch-he ...
- 保姆级教程!使用k3d实现K3s高可用!
你是否曾经想尝试使用K3s的高可用模式?但是苦于没有3个"备用节点",或者没有设置相同数量的虚拟机所需的时间?那么k3d这个方案也许你十分需要噢! 如果你对k3d尚不了解,它的名字 ...
- 保姆级教程:用GPU云主机搭建AI大语言模型并用Flask封装成API,实现用户与模型对话
导读 在当今的人工智能时代,大型AI模型已成为获得人工智能应用程序的关键.但是,这些巨大的模型需要庞大的计算资源和存储空间,因此搭建这些模型并对它们进行交互需要强大的计算能力,这通常需要使用云计算服务 ...
- 保姆级教程,如何发现 GitHub 上的优质项目?
先看再点赞,给自己一点思考的时间,微信搜索[沉默王二]关注这个靠才华苟且的程序员.本文 GitHub github.com/itwanger 已收录,里面还有一线大厂整理的面试题,以及我的系列文章. ...
随机推荐
- 一文搞懂企业架构与DDD融合
大家好,我是汤师爷~ 今天聊聊企业架构与DDD如何进行融合. 企业架构TOGAF 什么是企业架构TOGAF? TOGAF(The Open Group Architecture Framework)是 ...
- ORACLE 分页和行限制
行限制:示例 (此语法从12C版本开始支持) 以下语句返回具有最低employee_id值的 5 名员工: SELECT employee_id, last_name FROM Employees O ...
- 手把手教你喂养 DeepSeek 本地模型
上篇文章<手把手教你部署 DeepSeek 本地模型>首发是在公众号,但截止目前只有500多人阅读量,而在自己博客园BLOG同步更新的文章热度很高,目前已达到50000+的阅读量,流量是公 ...
- 创建Graphics对象的三种方法
参考链接:https://www.cnblogs.com/wax01/p/4982691.html 方法一.利用控件或窗体的Paint事件中的PainEventArgs 在窗体或控件的Paint事件中 ...
- Markdown 语法深度详解与实战演示
一.引言 在当今数字化的时代,高效地处理和呈现文本信息变得至关重要.Markdown 作为一种轻量级标记语言,因其简洁.易读.易写的特点,受到了广大开发者.写作者和内容创作者的喜爱.无论您是撰写博客. ...
- 机器学习中的 K-均值聚类算法及其优缺点
K-均值聚类算法是一种经典的机器学习算法,用于将数据集分成 K 个不同的簇.它是一种无监督学习算法,即不需要标签或任何先验知识来指导聚类过程. 算法的工作原理如下: 随机选择 K 个数据点作为初始聚类 ...
- DOCKER20231217: 容器引擎Docker
1.1 Docker简介 1.1.1 什么是Docker? 一种轻量级的操作系统虚拟化技术,基于Go语言实现的开源容器项目,诞生于2013年,最初发起者是dotCloud公司(现 Docker Inc ...
- php-fpm自动重启 解决方案
环境:Mac.php7.1.nginx 现象:killall php-fpm,php-fpm自动重启 共有如下几种解决方案: 1.检查php-fpm.conf的deamonize模式是否开启 2.查找 ...
- uniapp 截屏扫码
最近开发功能遇到个需求,用户点击某个操作之后,需要截取当前屏幕内容,并扫码识别屏幕截图中的二维码,代码如下: 首先将代码抽离到外部文件中,以便复用: // 截图 export function tak ...
- python 函数与方法的区别
函数与方法的区别 并不是类中的调用都叫方法 1.函数要手动传self,方法不用传self. 2.如果是一个函数,用类名去调用,如果是一个方法,用对象去调用. class Foo(object): de ...