大模型参数组成计算QwQ-32B为例
计算大模型参数量主要依赖于模型的架构和各层配置,我们把常用大模型分为三层:输入层、transformer层、输出层。
输入层
参数组成是Embedding的词表总和
transformer层
参数组成包括归一化参数、QKV的参数、输出全连接线性变换参数、FFN投影参数
输出层
归一化参数、全连接线性变换参数
我们以QwQ-32B为例,计算32B参数组成
QwQ-32B
架构 :使用了 RoPE(旋转位置编码)、SwiGLU、RMSNorm 和带有偏置项的注意力 QKV
各参数维度参考modelscope文件:
| 名称 | 大小 | |
|---|---|---|
| token词表大小 | vocab_size | 152064 |
| 词向量维度 | hidden_size | 5120 |
| 中间维度 | intermediate_size | 27648 |
| KV共享 | num_key_value_heads | 8 |
| Q | num_heads | 40 |
| 头维度 | head_dim | 128 |
| 层数 | transformer block | 64 |
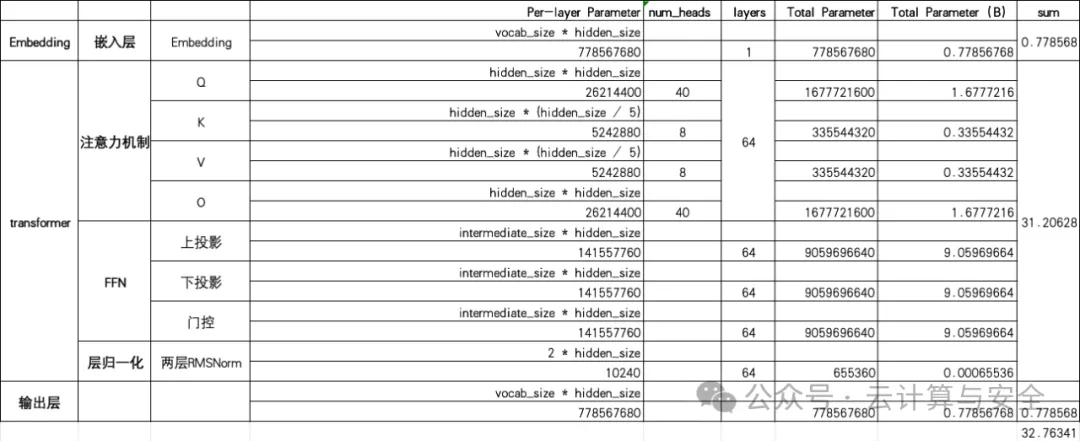
输入层
词表参数:vocab_size * hidden_size = 152064 * 5120
transformer层
Q的参数:hidden_size * hidden_size = 5120 * 5120
K的参数:由于KV是GQA,总共8个头,所以分成5组,hidden_size * (hidden_size / 5) = (5120 * 5120 / 5)
V的参数:和K一样,hidden_size * (hidden_size / 5) = (5120 * 5120 / 5)
输出后全连接线性转换参数:hidden_size * hidden_size = 5120 * 5120
FFN上投影:intermediate_size * hidden_size = 27648 * 5120
FFN下投影:intermediate_size * hidden_size = 27648 * 5120
SwiGLU门控参数:intermediate_size * hidden_size = 27648 * 5120
两个RMSNorm归一化:2 * hidden_size = 2 * 5120
输出层
归一化忽略不计,全连接线性变换:vocab_size * hidden_size = 152064 * 5120
总参数量
输入层 +(transformer层 * 64 )+ 输出层
关注微信公众号

大模型参数组成计算QwQ-32B为例的更多相关文章
- 使用excel估计GARCH模型参数——以GARCH(1,1)为例
本文的知识点:使用excel求解GARCH模型的系数,以GARCH模型为例,主要采用的是极大似然估计法MLE. 同时给出了R语言的输出结果作为对照验证. 参考了:http://investex ...
- MXNET:深度学习计算-模型参数
我们将深入讲解模型参数的访问和初始化,以及如何在多个层之间共享同一份参数. 之前我们一直在使用默认的初始函数,net.initialize(). from mxnet import init, nd ...
- 千亿参数开源大模型 BLOOM 背后的技术
假设你现在有了数据,也搞到了预算,一切就绪,准备开始训练一个大模型,一显身手了,"一朝看尽长安花"似乎近在眼前 -- 且慢!训练可不仅仅像这两个字的发音那么简单,看看 BLOOM ...
- 莫烦python教程学习笔记——利用交叉验证计算模型得分、选择模型参数
# View more python learning tutorial on my Youtube and Youku channel!!! # Youtube video tutorial: ht ...
- 深度学习方法(七):最新SqueezeNet 模型详解,CNN模型参数降低50倍,压缩461倍!
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld. 技术交流QQ群:433250724,欢迎对算法.技术感兴趣的同学加入. 继续前面关于深度学习CNN经典模型的 ...
- 华为高级研究员谢凌曦:下一代AI将走向何方?盘古大模型探路之旅
摘要:为了更深入理解千亿参数的盘古大模型,华为云社区采访到了华为云EI盘古团队高级研究员谢凌曦.谢博士以非常通俗的方式为我们娓娓道来了盘古大模型研发的"前世今生",以及它背后的艰难 ...
- 12. 亿级流量电商系统JVM模型参数二次优化
亿级流量电商系统JVM模型参数预估方案,在原来的基础上采用ParNew+CMS垃圾收集器 一.亿级流量分析及jvm参数设置 1. 需求分析 大促在即,拥有亿级流量的电商平台开发了一个订单系统,我们应该 ...
- 图神经网络之预训练大模型结合:ERNIESage在链接预测任务应用
1.ERNIESage运行实例介绍(1.8x版本) 本项目原链接:https://aistudio.baidu.com/aistudio/projectdetail/5097085?contribut ...
- DeepSpeed Chat: 一键式RLHF训练,让你的类ChatGPT千亿大模型提速省钱15倍
DeepSpeed Chat: 一键式RLHF训练,让你的类ChatGPT千亿大模型提速省钱15倍 1. 概述 近日来,ChatGPT及类似模型引发了人工智能(AI)领域的一场风潮. 这场风潮对数字世 ...
- fluent批量处理——模型参数的设置
对于常见的工程应用来说,计算的工况很多,尤其优化工作,少则几百,多则上千,面对如此之多的case文件要写,假如按照一个一个的读写的话,相信你一定会为这么机械的工作烦躁,甚至影响今后好几天的心情,那么有 ...
随机推荐
- dart安装教程详解
官网 https://dart.dev 关于发布通道和版本字符串 Dart SDK有三个发布通道: 1==>:稳定释放,大约每三个月更新一次: 稳定释放适合生产使用. 2==>:预览发布, ...
- Python更换下载源:提升包安装速度的实用指南
Python更换下载源:提升包安装速度的实用指南 Python作为一门广泛使用的编程语言,其强大的生态系统和丰富的第三方库是吸引众多开发者的关键因素之一.然而,在使用pip安装这些第三方库时,由于网络 ...
- STM32 DMA操作
https://blog.csdn.net/u014754841/article/details/79525637?utm_medium=distribute.pc_relevant.none-tas ...
- Redis 大 Key 分析利器:支持 TOP N、批量分析与从节点优先
背景 Redis 大 key 分析工具主要分为两类: 1. 离线分析 基于 RDB 文件进行解析,常用工具是 redis-rdb-tools(https://github.com/sripathikr ...
- QT5笔记:4. 设置应用图标
4. 设置应用图标 参考视频:https://www.bilibili.com/video/BV1AX4y1w7Nt # 在项目的.pro文件中添加如下内容,ico文件名称可变 RC_ICONS = ...
- oracle - [01] 安装部署
超级详细的Oracle安装图文详解!手把手教会您从下载到安装! https://blog.csdn.net/weixin_46329056/article/details/125451601
- Flume - [01] 概述
一.什么是Flume Flume 是Cloudera提供的一个高可用,高可靠的,分布式的海量日志采集.聚合和传输的系统. Flume最主要的作用就是:实时读取服务器本地磁盘的数据,将数据写入HDFS. ...
- [译] DeepSeek开源smallpond开启DuckDB分布式之旅
DeepSeek 正通过 smallpond(一种新的.简单的分布式计算方法)推动 DuckDB 超越其单节点的局限.然而,我们也需要探讨,解决了横向扩展的挑战后,会不会是带来新的权衡问题呢? 译者序 ...
- form-create-designer中怎么扩展自定义组件
form-create-designer中怎么扩展自定义组件 form-create-designer 是基于 @form-create/element-ui实现的表单设计器组件.可以通过拖拽的方式快 ...
- React从webpack迁移到rsbuild 纪实
Why 随着团队项目规模越来越大之后,继从babel-loader迁移到esbuild之后发现打包.热重载性能随着时间迭代之后又慢慢开始成为性能瓶颈,所以决定用新的打包工具去解决这个问题.esbuil ...