Ribbon过滤器原理解析
Ribbon过滤器整体看是一个矩阵构建与矩阵乘法,RocksDB中对它的实现是进行了合理的空间、时间上的优化的。
符号
整个过滤器都和矩阵计算CS=R相关,C是\(n*n\)矩阵,S是\(n*m\)矩阵,R是\(n*m\)矩阵。
这里为了方便讨论定义:三个哈希函数s(x),c(x),r(x),s是start函数,c是coeff函数,r是result函数。其中c的返回值是一个定长二进制整数,比如c(x)返回0010,那么c(x)返回的整数是长度为w=4的二进制整数。
此外为了方便讨论,我们假定n=8, m=3,h(x)为s(x)个0拼接c(x)拼接n-w-s(x)个0。比如:
| key | s(x) | c(x) | r(x) | h(x) |
|---|---|---|---|---|
| u | 0 | 1000 | 000 | 1000 0000 |
| v | 0 | 1100 | 111 | 1100 0000 |
| w | 0 | 1010 | 100 | 1010 0000 |
| x | 3 | 1000 | 101 | 000 1000 0 |
| y | 0 | 1001 | 111 | 1001 0000 |
构建过程
构建过程本质上是解一个CS=R的矩阵乘法。C和R是由插入的键构建的,S是C和R解出来的。这里定义的矩阵乘法是:
\]
与原本的矩阵乘法非常相似,就是乘法变成逻辑与,加法编程逻辑xor罢了。
\]
初始化
初始化,默认所有值为0
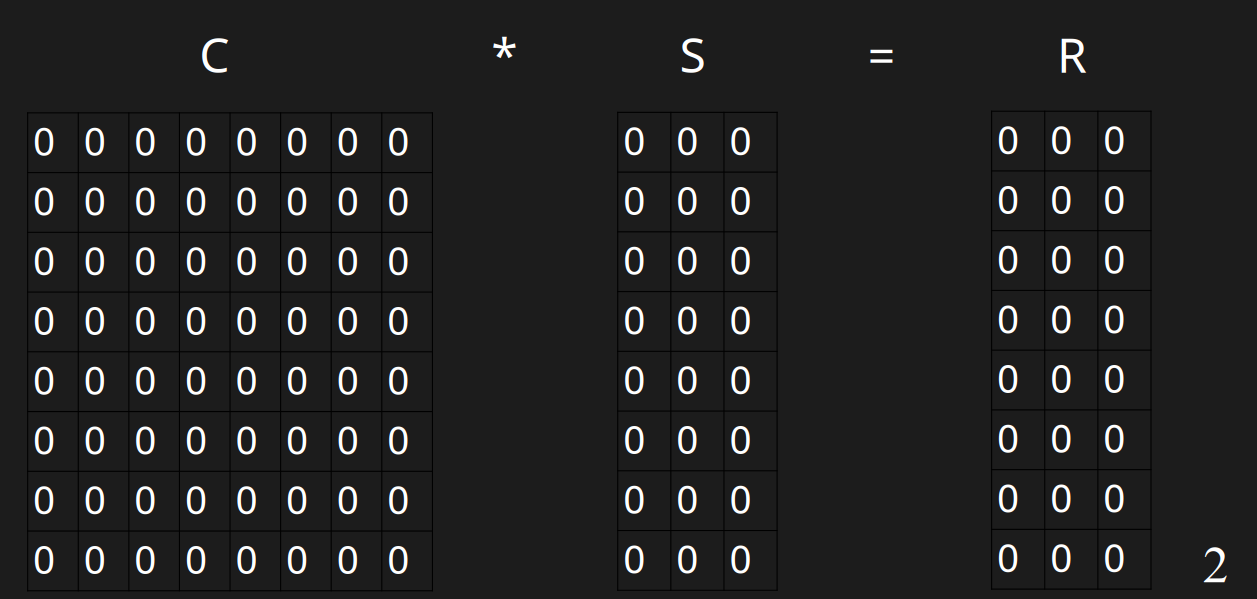
插入过程
def leading_zeros_count(self, vec: np.matrix):
for i in range(vec.shape[1]):
if vec[0, i] != 0:
return i
return vec.shape[1]
def banding_add(self, h, resultrow):
print(h, resultrow)
while True:
start = self.leading_zeros_count(h)
if np.all(h[0] == 0):
if np.all(resultrow[0] == 0):
break
else:
raise ValueError("cannot insert this row")
elif np.all(self.coeff[start] == 0): # 如果start这一行全是0,就把这一行赋值为coeffrow
self.coeff[start] = h
self.result[start] = resultrow
break
else:
h = self.row_xor(h, self.coeff[start])
resultrow = self.row_xor(resultrow, self.result[start])
print(self.coeff)
print(self.result)
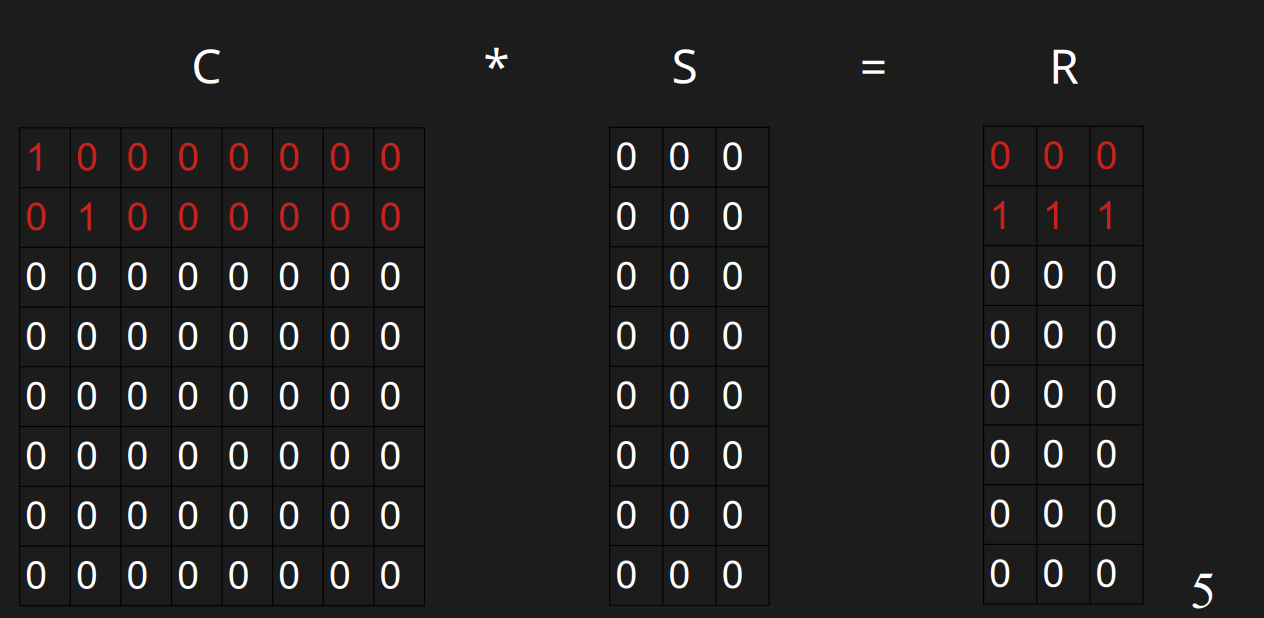
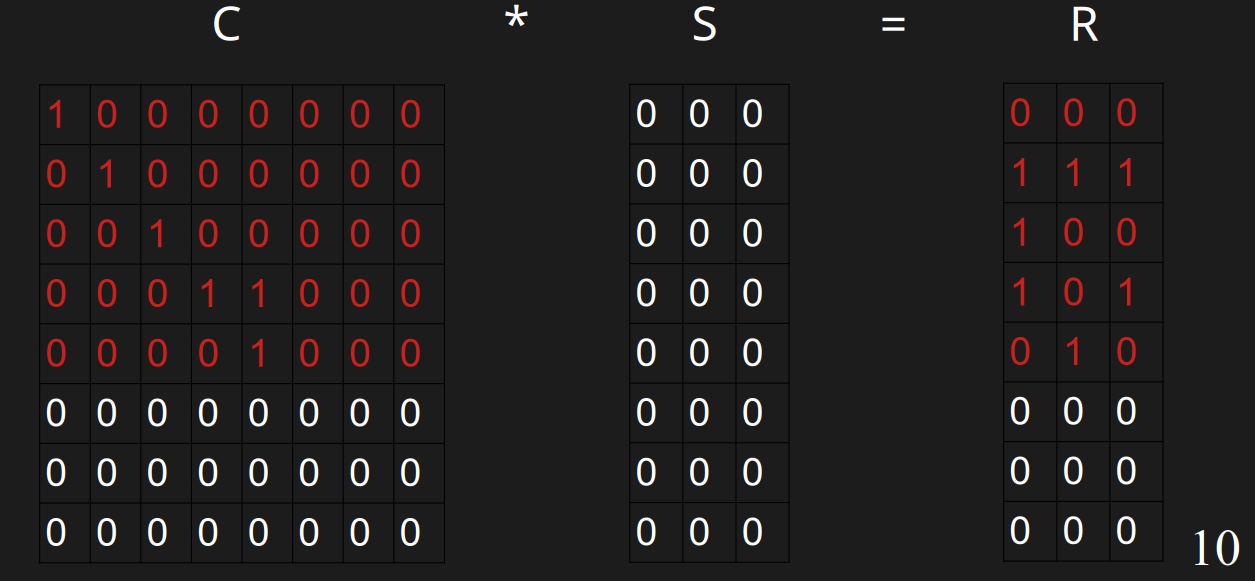
插入u
插入u的时候,此时它开头的0的数量是0,需要插入到第0行。第0行都是0,直接插入即可。

插入v
插入v的时候,此时它开头的0的数量是1,需要插入到第0行。第0行已经有值了,h(v)=11000000与r(v)=111分别与第0行异或,得到01000000与111。此时它开头的0的数量是1,需要插入到第1行,可以直接插入。
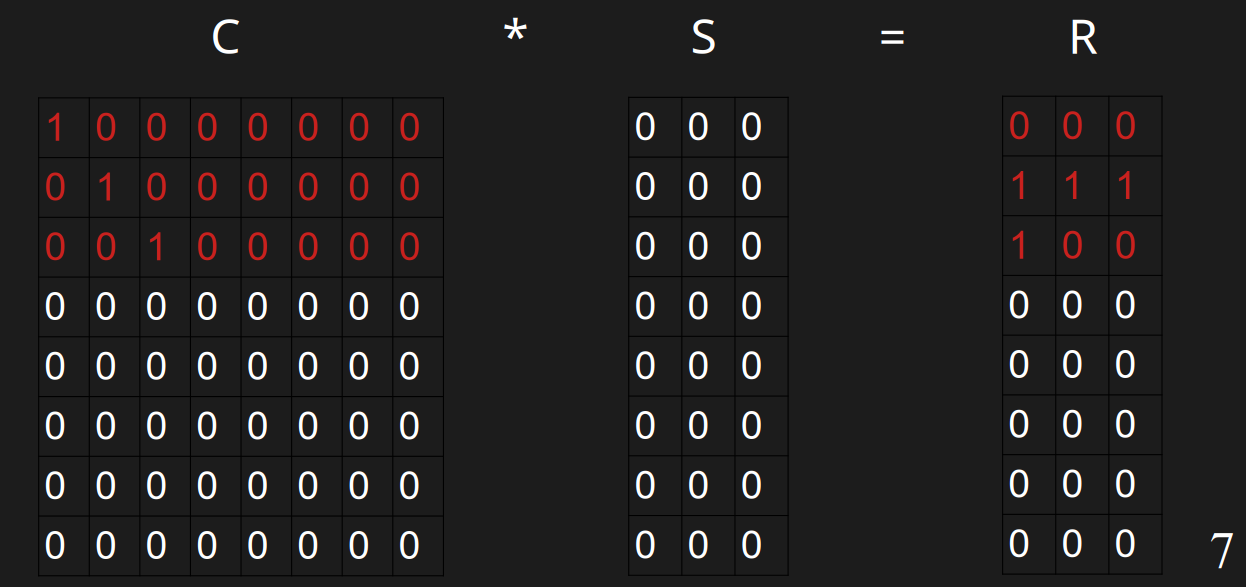
插入w
插入w的时候,h(w)=10100000,r(w)=100,此时它开头的0的数量是0,需要插入到第0行。发现第0行有值了,分别与第0行异或,得到00100000与100,此时它开头的0的数量是2,此时需要插入到第2行。
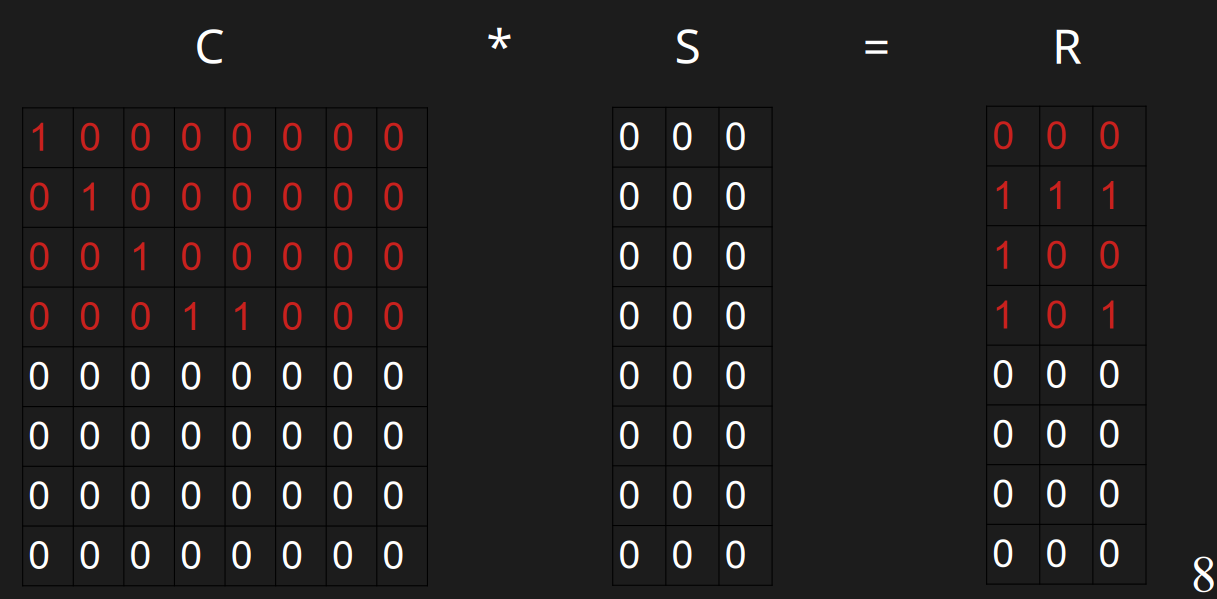
插入x
插入x的时候,h(x)=00011000,r(x)=100,此时它开头的0的数量是3,需要插入到第3行,插入到第3行。
插入y
插入y的时候,h(w)=10010000,r(w)=111,此时它开头的0的数量是0,需要插入到第0行。
发现第0行有值了,分别与第0行异或,得到00010000与111,此时它开头的0的数量是3,此时需要插入到第3行。
发现第3行有值了,分别与第3行异或,得到00001000与010,此时它开头的0的数量是4,此时需要插入到第4行。
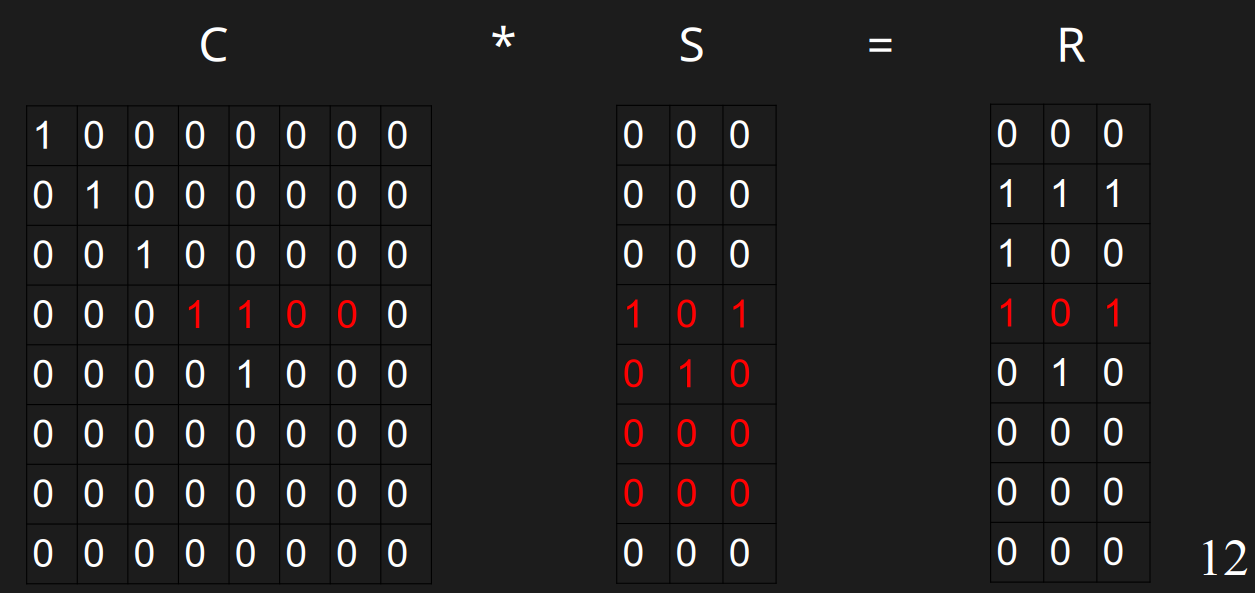
解矩阵S
现在有C和R了,可以用线性代数的方法解S的值。但是由于C是上三角矩阵,且中间长度w=4的01串以外的地方都是0,所以我们可以从下往上计算,且只需要看其中4个值。
解S的第4行
解这一行本质上是计算\(00001000*S=010\),即:
\]
\]
\]
由于C是上三角矩阵,且其中只有连续的4个wit可能为1,其他都为0,所以上面的计算可以化简为:
\]
\]
\]
由于C的最后三行是0,所以进一步化简为:
\]
\]
\]
很容易解出来S的第四行

解S的第3行
计算
\]
\]
\]
由于C是上三角矩阵,且其中只有连续的4个bit可能为1,其他都为0,所以上面的计算可以化简为:
\]
\]
\]
容易算出S的第3行是101
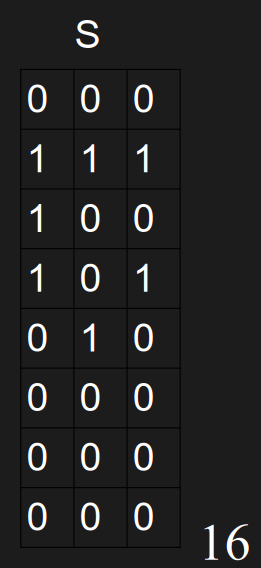
以此类推,计算完S
查询过程
查询过程即判断表达式\(h(x)S=r(x)\)。
查询\(h(a)=11000000\)与\(r(a)=110\),\(h(a)S=111\),与r(a)不同,判定为不存在,查询结果正确
查询\(h(y)=10010000\)与\(r(y)=111\),\(h(y)S=101\),与r(y)不同,出现假阴性
查询\(h(b)=01000000\)与\(r(b)=111\),得到101,与r(b)不同,出现假阳性
查询\(h(u)=11000000\)与\(r(u)=111\),得到111,与r(u)相同,判定为存在,结果正确
优化
矩阵存储优化
可以发现,ribbon过滤器完全可以用一个\(w*n\)的矩阵表示整个C,并且构建完S后完全可以丢弃C和R,所以只会在构建过中存在临时的空间消耗。
构建、查询耗时优化
可以发现h(x)只有中间连续w个bit是有用的,所以查询时可以遍历S中的w行即可。
假阳性率定制
假阳性率是\(2^{-w}\),至于如何定制,这是论文中的内容了,如图,我们将w个 bit 连续存放,每m个w bit 为一组。所以整体看是 column-major 的,而每一组实际上是 row-major 的。这种混合方式称为 ICML(Interleaved Column-MajorLayout)
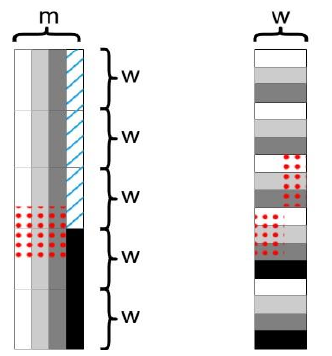
代码中,我们还需要特殊处理跨组(图中红点部分)的问题。对于 ICML 开始一段不足m列的特殊情况(图中蓝色斜线部分),我们可以忽略它。这样我们就可以存储 7、9、10bit 一行的矩阵。平均 3.4bit 一行的矩阵也是可行的,图中m = 4,但是前面三段都是使用m = 3,这样平均就是 3.4bit 一行了。
提防假阴性
从前面查询的例子我们可以发现,过滤器存在假阴性,即实际插入位置不在$$[s(x),s(x)+w-1]$$范围内,这是要避免的。为了确保假阴性率极低,需要多分配一些内存。比如插入t个key,那么实际要分配的行数是需要多于t的。具体的假阴性率真不知道怎么算,在代码中是设置为一个值来规避的。这个值是
\]
算法导论有关于线性探测哈希表的讨论。如果w=64,那么期望探测到64次,load-factor需要是\(64=1/(1-a)\),解出来loadfactor为63/64,即0.98,而这个公式在\(t=30,000,000\)时算出来是0.83左右
Ribbon过滤器原理解析的更多相关文章
- Web APi之过滤器执行过程原理解析【二】(十一)
前言 上一节我们详细讲解了过滤器的创建过程以及粗略的介绍了五种过滤器,用此五种过滤器对实现对执行Action方法各个时期的拦截非常重要.这一节我们简单将讲述在Action方法上.控制器上.全局上以及授 ...
- Web APi之过滤器创建过程原理解析【一】(十)
前言 Web API的简单流程就是从请求到执行到Action并最终作出响应,但是在这个过程有一把[筛子],那就是过滤器Filter,在从请求到Action这整个流程中使用Filter来进行相应的处理从 ...
- python实现布隆过滤器及原理解析
python实现布隆过滤器及原理解析 布隆过滤器( BloomFilter )是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地 ...
- Volley 实现原理解析(转)
Volley 实现原理解析 转自:http://blog.csdn.net/fengqiaoyebo2008/article/details/42963915 1. 功能介绍 1.1. Volley ...
- 撸一撸Spring Cloud Ribbon的原理-负载均衡器
在上一篇<撸一撸Spring Cloud Ribbon的原理>中整理发现,RestTemplate内部调用负载均衡拦截器,拦截器内最终是调用了负载均衡器来选择服务实例. 接下来撸一撸负载均 ...
- Nginx 原理解析和配置摘要
前言 Nginx 作为高性能的 http 服务器,知名度不必多言,相似产品中无出其右.本篇随笔记录我认为较为重要的原理和配置. 1. 原理解析 1.1 结构 以上是 Nginx 的结构图,其包含一个 ...
- (转)Apache和Nginx运行原理解析
Apache和Nginx运行原理解析 原文:https://www.server110.com/nginx/201402/6543.html Web服务器 Web服务器也称为WWW(WORLD WID ...
- Spring Security 解析(六) —— 基于JWT的单点登陆(SSO)开发及原理解析
Spring Security 解析(六) -- 基于JWT的单点登陆(SSO)开发及原理解析 在学习Spring Cloud 时,遇到了授权服务oauth 相关内容时,总是一知半解,因此决定先把 ...
- 三、Nginx原理解析
Nginx原理解析 一.反向代理 工作流程 用户通过域名发出访问Web服务器的请求,该域名被DNS服务器解析为反向代理服务器的IP地址: 反向代理服务器接受用户的请求: 反向代理服务器在本地缓存中查找 ...
- [原][Docker]特性与原理解析
Docker特性与原理解析 文章假设你已经熟悉了Docker的基本命令和基本知识 首先看看Docker提供了哪些特性: 交互式Shell:Docker可以分配一个虚拟终端并关联到任何容器的标准输入上, ...
随机推荐
- C#长短链接服务器端WebApi作映射
[HttpGet] public IHttpActionResult GetLongLink(string code) { if (string.IsNullOrWhiteSpace(code)) { ...
- ITSM运维管理整理总结
ITSM 和我们平常所说的软件管理最大的不同? 目标不是管理技术,主要任务是管理用户和客户的IT需求 2.人员.技术.流程[重要] 3.几大模块 模块名称 干什么 备注 服务台 1.对接客户的前方,负 ...
- IvorySQL 增量备份与合并增量备份功能解析
1. 概述 IvorySQL v4 引入了块级增量备份和增量备份合并功能,旨在优化数据库备份与恢复流程.通过 pg_basebackup 工具支持增量备份,显著降低了存储需求和备份时间.同时,pg_c ...
- Hack The Box-Chemistry靶机渗透
通过信息收集访问5000端口,cif历史cve漏洞反弹shell,获取数据库,利用低权限用户登录,监听端口,开放8080端口,aihttp服务漏洞文件包含,获取root密码hash值,ssh指定登录 ...
- 【Java】NIO
1. Java NIO 简介 Java NIO(New IO)是从Java 1.4版本开始引入的一个新的IO API,可以替代标准的Java IO API. NIO与原来的IO有同样的作用和目的,但是 ...
- Ant Design Pro 中 点击子菜单的时候,其他菜单不自动收起来
记录一波自己在这段时间碰到的一个Ant Design Pro 的坑: 每次点击菜单都会将其他菜单自动收起来,导致一系列的用户体验不佳. 设置defaultOpenAll: true后依然不管用 经过各 ...
- LLMOps MLOPS
https://www.redhat.com/en/topics/ai/llmops https://www.redhat.com/en/topics/cloud-computing/what-is- ...
- MySQL获取周、月、天日期,生成排序号
常用MySQL生成时间序列 --生成最近七天的日期,不包括当天 SELECT @cdate := date_add(@cdate, interval - 1 day) as date FROM(SEL ...
- lua三色标记的读写屏障理解
起因是已经被标记为黑色的对象无法进行再次遍历,然而黑色对象发生了引用变化:断开了引用或者引用了别的对象,会导致多标(不再被黑色对象引用的对象未能回收),漏标(黑色对象的新引用未能遍历标记)
- JMeter跨线程传参总结