MaxKB中如何选择向量模型?
MaxKB内置的向量模型不足?
在MaxKB中知识文档Emdeding是很重要的一环,而这个过程就必须依赖向量模型。目前MaxKB内置的向量模型为text2vec-base-Chinese,一个针对中文语义匹配任务优化的向量模型,特别适用于中文句子级别的语义匹配任务。早期的时候在多个领域表现出了优秀的性能。但是,刚刚也说了是早期,以现在的时间点来看,不可避免的有些其他不足:
长文本处理能力:在处理长文本时,可能无法有效搜索到相关结果,这表明在长文本处理方面可能存在一定的局限性。
向量模型“坍缩”现象:这个现象指的是BERT对所有的句子都倾向于编码到一个较小的空间区域内,这使得大多数的句子对都具有较高的相似度分数。这会导致模型难以准确地反映出两个句子的语义相似度,尤其是在处理长文本时,可能会经常搜索不到不准确的结果。
模型实时性问题:至目前为主,text2vec-base-Chinese官方库最新一次更新时间为[2023/09/20] v1.2.9版本,也就是一年多的时间没有更新了,在这个AI快速发展的时代,一年的时间显的很长。
备注:BERT(Bidirectional Encoder Representations from Transformers)是由 Google 在 2018 年提出的一种预训练语言表示模型,它基于 Transformer 架构构建,通过深度双向训练来理解语言的上下文信息。
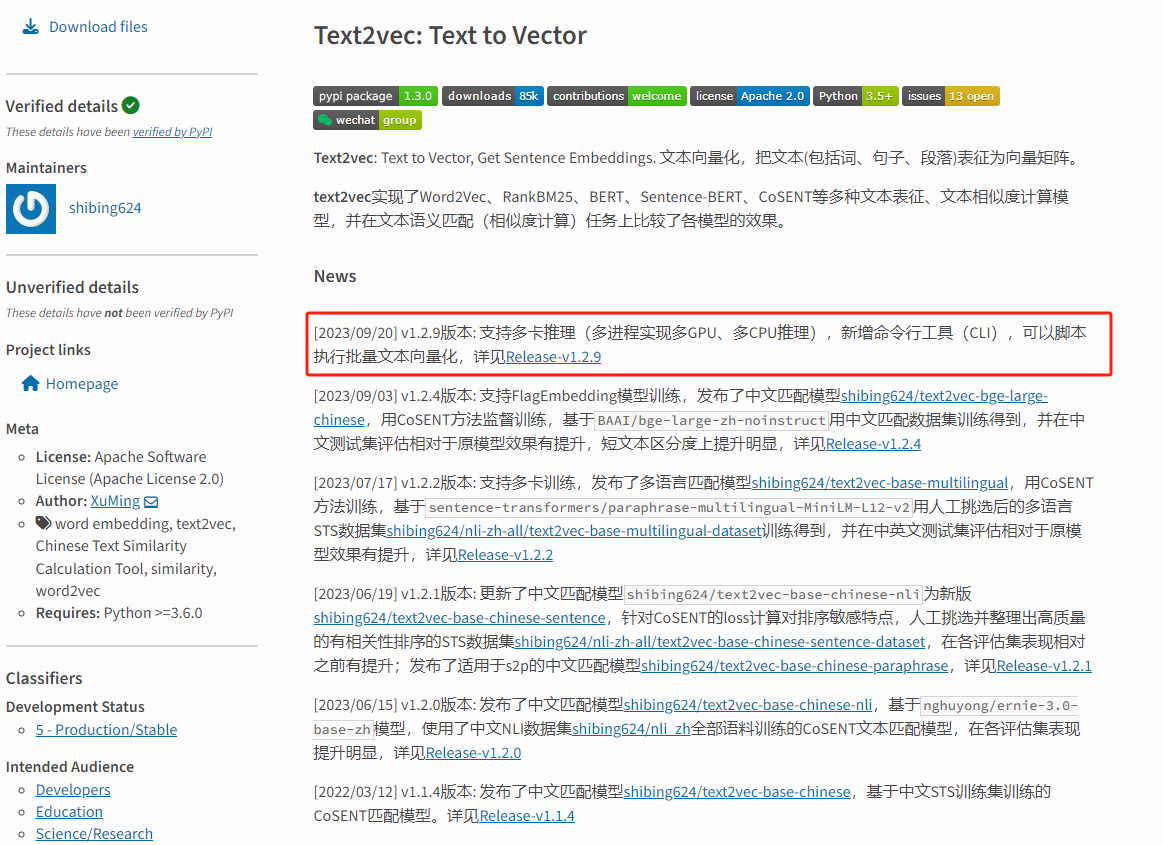
并且,为了应对不同文档Emdeding,有时候我们也需要在MaxKB更换不同的向量模型。现在向量模型的种类大概分为六大类,向量模型的数量基本也有上百种以上,如何选择向量模型一直是个难题。
BERT (Bidirectional Encoder Representations from Transformers):这是一种基于 Transformer 架构的预训练语言表示模型,它通过深度双向训练来理解语言的上下文信息。BERT 在自然语言处理(NLP)领域取得了显著的性能提升,被广泛应用于各种任务,如情感分析、问答系统、命名实体识别等。
M3E (Massive Mixed Embedding):M3E 在私有部署和大规模文本处理方面表现出色,适用于需要私有化和资源节约的场景。它通过大规模混合嵌入技术提高了词向量的表达能力和泛化能力,适用于各种文本处理任务。
BGE (Baidu General Embedding):BGE 系列模型在全球下载量超过1500万,位居国内开源 AI 模型首位,表明其资源使用高效且受欢迎。BGE 在多语言支持、文本处理能力和检索精度方面表现优异,尤其适合需要高精度和高效率的场景。
Sentence Transformers:基于孪生 BERT 网络预训练得到的模型,对句子的嵌入效果比较好。
OpenAI Embedding (text-embedding-ada-002): OpenAI 提供的模型,嵌入效果表现不错,且可以处理最大 8191 标记长度的文本。
Instructor Embedding:这是一个经过指令微调的文本嵌入模型,可以根据任务(例如分类、检索、聚类、文本评估等)和领域(例如科学、金融等),提供任务指令而生成相对定制化的文本嵌入向量,无需进行任何微调。
那么我们应该在MaxKB中如何选择向量模型?
选择向量模型的第一点需要考虑模型的排行,应用场景等。但是这些在huggingface、魔塔社区都有相应的说明,反而不是太过担心。
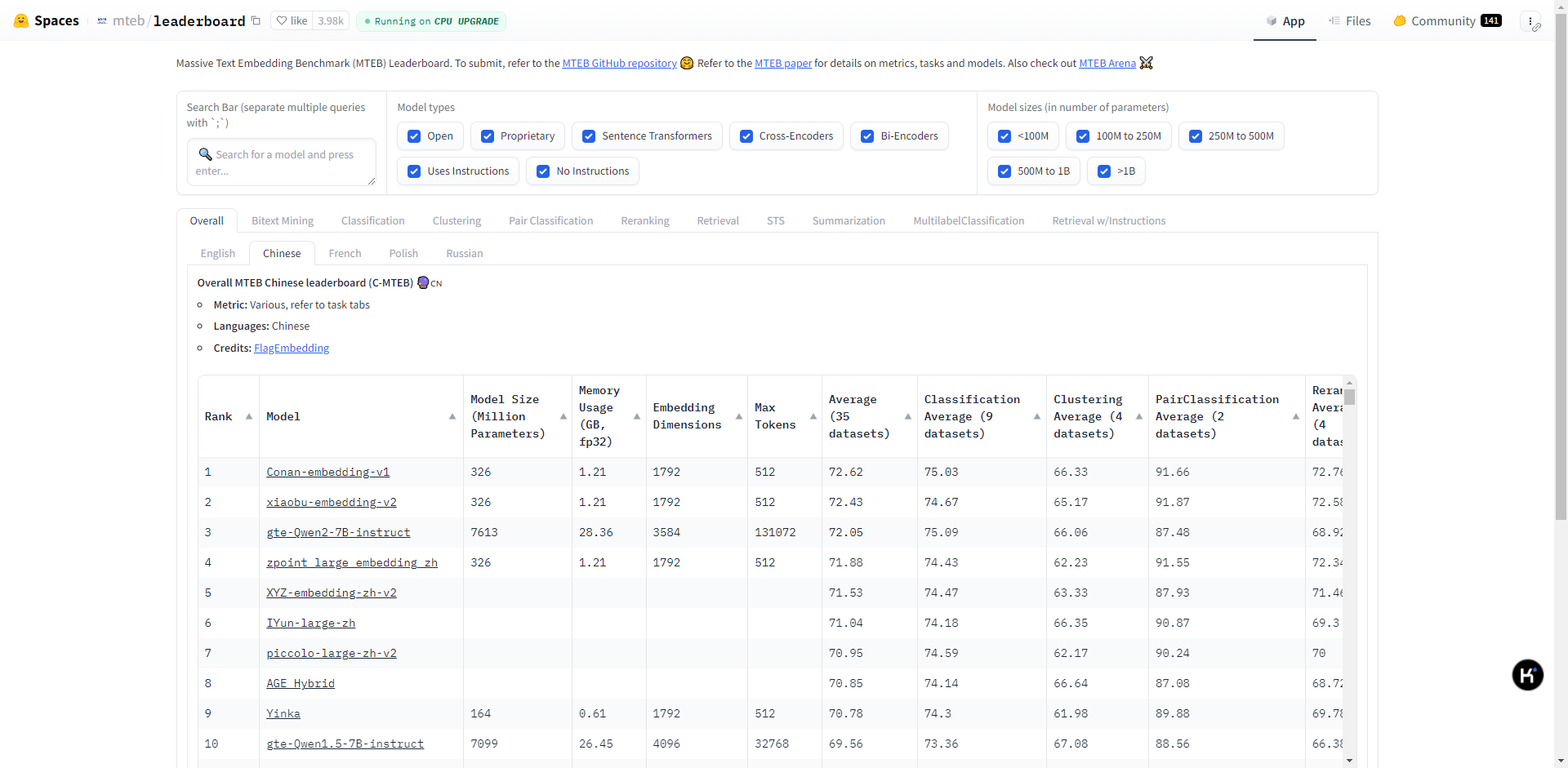
比如huggingface的MTEB榜单:https://huggingface.co/spaces/mteb/leaderboard(评估和比较不同文本嵌入模型的基准测试性能,MTEB榜单涵盖了多种语言和任务类型,包括法语、英语、中文等112种语言,涉及检索、排序、句子相似度、推理、分类、聚类等任务。通过这些任务,MTEB能够评估模型在不同场景下的表现,为用户提供选择依据)
魔塔社区(https://modelscope.cn/) ModelScope社区成立于2022年6月,是一个模型开源社区及创新平台,由阿里巴巴达摩院,联合CCF开源发展委员会,共同作为项目发起方。
具体在MaxKB中替换向量模型时选择哪一种?这个就需要结合上述六大分类的向量模型,综合以下几个方面进行考量:
- 语义理解能力:需要能够理解句子或段落级别的语义,而不仅仅是词汇级别的相似度。
- 运行效率:针对大规模语料的检索需要考虑计算效率和相似度检索时间。
- 上下文依赖性:选择模型时需要考虑上下文对语义匹配的重要性。
- 领域适配性:有些模型对特定任务或领域(如法律、医学)需要采用专业领域模型(微调或者现有的)以提供最佳性能。
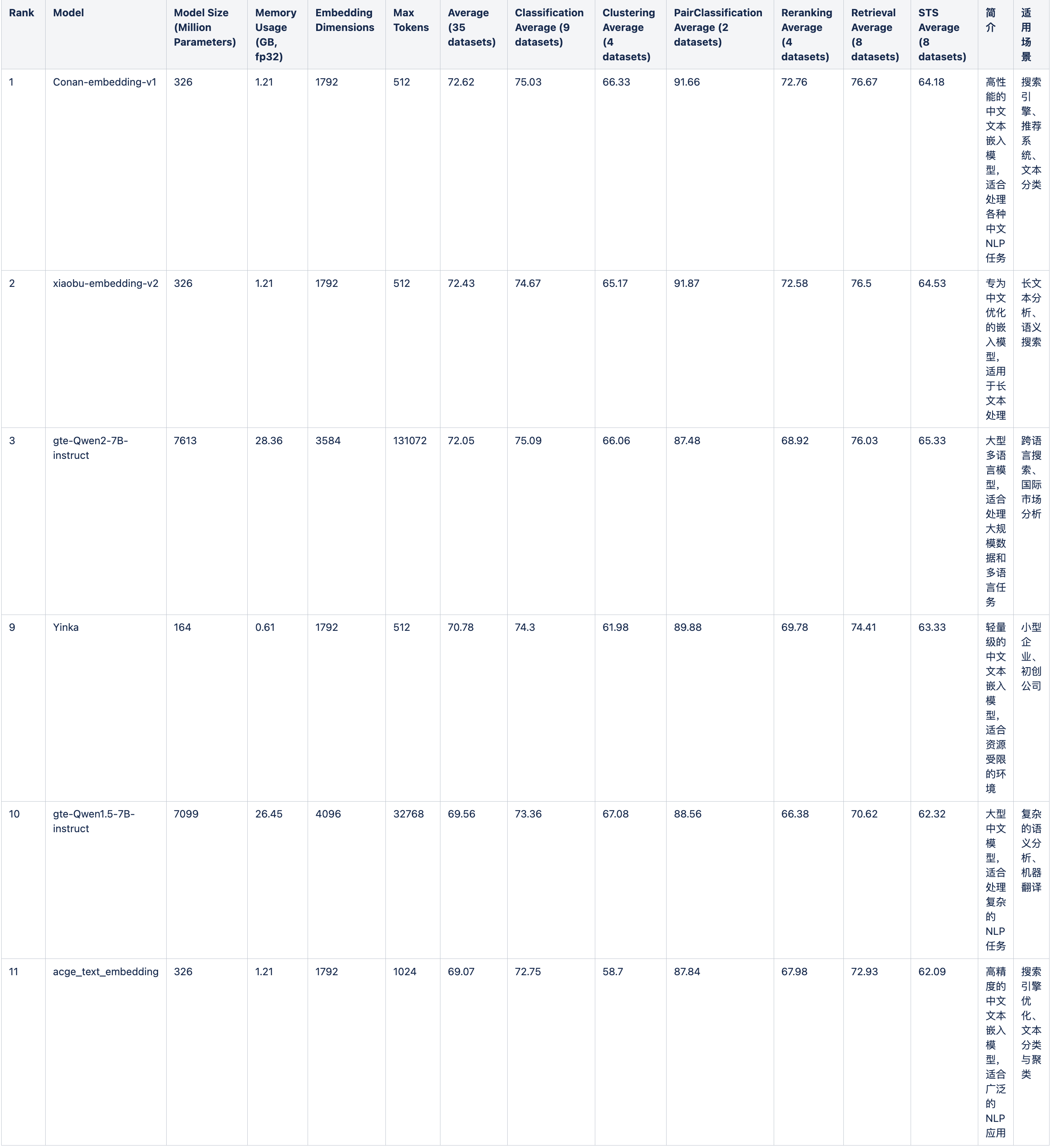
从huggingface的MTEB中文榜单中,可以看出目前支持中文主流的向量模型有以下几种(相对而言,模型更新太快)。以下是汇总了MTEB排行榜中第1至第20位中包含具体参数信息的模型,及其性能参数,补充了模型简介和适用场景:
当然,上述为通用模型,在一些特殊领域也可以使用以下场景模型,比如面向电商、医疗等,可以按照实际场景进行选择:

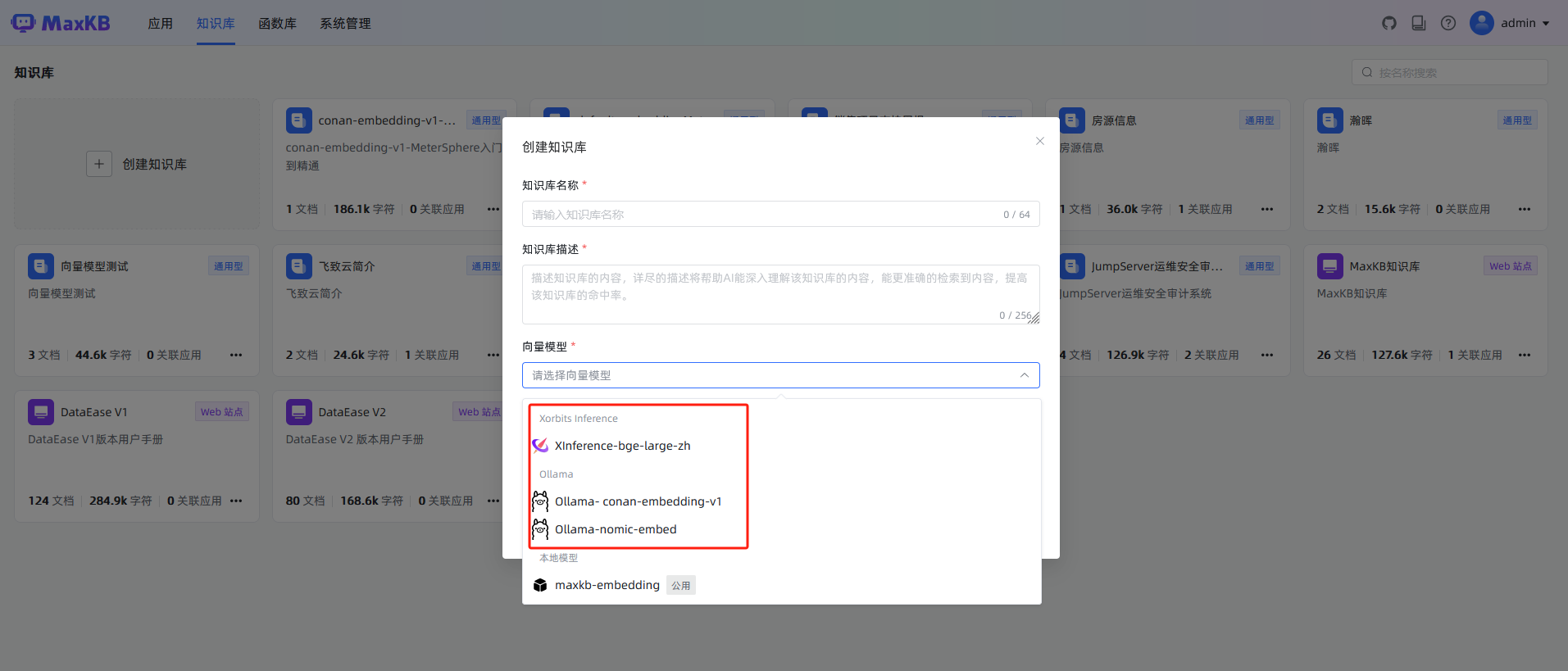
关于在MaxKB中如何替换向量模式这边就不过多介绍,可以通过接入公有向量模型、Xinference、或者本地模型方式接入,具体可以参考手册,比如在Xinference中启用本地向量模型(用ollama、本地模型的方式也可以)。
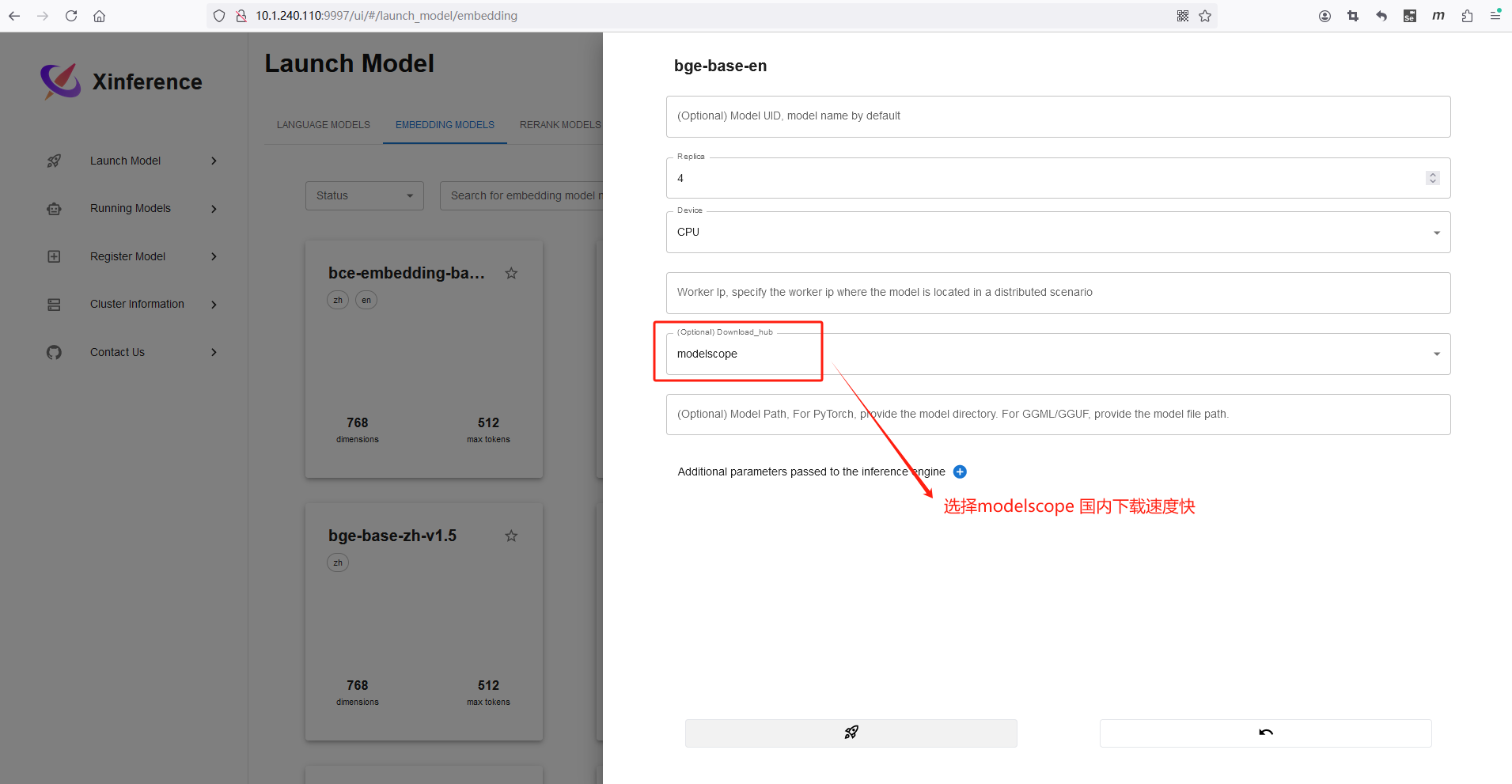
启动后,在MaxKB中接入使用即可。
MaxKB中如何选择向量模型?的更多相关文章
- Elasticsearch中的相似度模型(原文:Similarity in Elasticsearch)
原文链接:https://www.elastic.co/blog/found-similarity-in-elasticsearch 原文 By Konrad Beiske 翻译 By 高家宝 译者按 ...
- NLP学习(1)---Glove模型---词向量模型
一.简介: 1.概念:glove是一种无监督的Word representation方法. Count-based模型,如GloVe,本质上是对共现矩阵进行降维.首先,构建一个词汇的共现矩阵,每一行是 ...
- 在C 中加载TorchScript模型
本教程已更新为可与PyTorch 1.2一起使用 顾名思义,PyTorch的主要接口是Python编程语言.尽管Python是合适于许多需要动态性和易于迭代的场景,并且是首选的语言,但同样的,在 许多 ...
- 词向量模型word2vector详解
目录 前言 1.背景知识 1.1.词向量 1.2.one-hot模型 1.3.word2vec模型 1.3.1.单个单词到单个单词的例子 1.3.2.单个单词到单个单词的推导 2.CBOW模型 3.s ...
- 对词向量模型Word2Vec和GloVe的理解
Word2Vec Word2Vec 是 google 在2013年提出的词向量模型,通过 Word2Vec 可以用数值向量表示单词,且在向量空间中可以很好地衡量两个单词的相似性. 简述 我们知道,在使 ...
- [Algorithm & NLP] 文本深度表示模型——word2vec&doc2vec词向量模型
深度学习掀开了机器学习的新篇章,目前深度学习应用于图像和语音已经产生了突破性的研究进展.深度学习一直被人们推崇为一种类似于人脑结构的人工智能算法,那为什么深度学习在语义分析领域仍然没有实质性的进展呢? ...
- 一文读懂高性能网络编程中的I/O模型
1.前言 随着互联网的发展,面对海量用户高并发业务,传统的阻塞式的服务端架构模式已经无能为力.本文(和下篇<高性能网络编程(六):一文读懂高性能网络编程中的线程模型>)旨在为大家提供有用的 ...
- 词袋模型bow和词向量模型word2vec
在自然语言处理和文本分析的问题中,词袋(Bag of Words, BOW)和词向量(Word Embedding)是两种最常用的模型.更准确地说,词向量只能表征单个词,如果要表示文本,需要做一些额外 ...
- scikit-learn 中常用的评估模型
一,scikit-learn中常用的评估模型 1.评估分类模型: 2.评估回归模型: 二.常见模型评估解析: •对于二分类问题,可将样例根据其真实类别和分类器预测类别划分为:(T,F表示预测的 ...
- Chem 3D中怎么创建立体模型
ChemDraw作为一款很受大家欢迎的化学绘图软件,其在绘制平面化学方面的功能已经非常的强大了,其实它也可以绘制3D图形.Chem 3D就是绘制3D图形的重要组件.而且为了满足不同的用户绘图的需求,可 ...
随机推荐
- Flink白话解析Watermark
一.摘要 如果想使用Flink,Flink的Watermark是很难绕过去的概念.本文帮大家梳理Watermark概念 二.Watermark疑问 1.Flink应用的常见需求是什么 如公司运营一个官 ...
- 推荐一款人人可用的开源 BI 工具,更符合国人使用习惯的数据可视化分析工具,数据大屏开发神器!
前言 今天大姚给大家推荐一款人人可用的开源.免费的 BI 工具,更符合国人使用习惯的数据可视化分析工具,数据大屏开发神器,Tableau.帆软的开源替代:DataEase. 工具介绍 DataEase ...
- Android应用禁止屏幕休眠的3种方法
做android应用开发时,有时需要在应用前台运行时,禁止休眠,以下几种方法供参考. 方法一:持有wakelock 添加休眠锁,休眠锁必须成对出现. private wakelock mwakeloc ...
- 纯离线部署本地知识库LLM大模型
纯离线部署本地知识库LLM大模型 一.下载离线大模型 下载的网址:https://hf-mirror.com/ deepseek qwen 相关的模型,只建议使用1.5B的,GGUF后缀的模型 推荐下 ...
- 基于标签值分布的强化学习推荐算法(Reinforcement Learning Recommendation Algorithm Based on Label Value Distribution)
前言 看论文的第三天,坚持下去. 慢慢来,比较快. -- 唐迟 本文基于2023年6月28日发表在MATHEMATICS上的一篇名为"基于标签值分布的强化学习推荐算法"(Reinf ...
- C# Quartz 调度任务辅助类
1 public class QuartzHelper 2 { 3 /// <summary> 4 /// 时间间隔执行任务 5 /// </summary> 6 /// &l ...
- AI 核心能力与开发框架工程能力的共生关系解析
一.本质定位:能力层与载体层的互补 1. AI 能力:突破性认知的"大脑" - 定义:AI 的核心能力(如大语言模型的泛化推理.多模态感知)源于算法创新.海量数据与算力突破,其本质 ...
- Qt修改exe文件图标
修改Qt生成exe的图标以及软件标题图标 目录 修改Qt生成exe的图标以及软件标题图标 简介 QtCreator下添加exe图标 直接添加.ico 通过.rc文件修改 Visual Studio下添 ...
- go gin Next()方法
示例 gin Next()使用方法 package main import ( "fmt" "github.com/gin-gonic/gin" "n ...
- PLSQL中查询数据的时候查询结果显示中文乱码
要需要很努力才能看起来毫不费力.....1.在PLSQL中查询数据的时候查询结果显示中文乱码这里写图片描述2.需要在环境变量中新建两个环境变量:第一个:设置 NLS_LANG=SIMPLIFIED C ...