ubuntu上搭建ChatGLM2-6b环境及ptuing微调训练的坑
清华大学的chatGLM2-6B可以说是目前亚洲唯一能打的对中文支持不错的LLM大模型,网上已经有很多介绍如何在本机搭建环境的文章,就不再重复了,这里记录下最近踩的一些坑:
1、为啥要使用ubuntu?
chatGLM2-6b项目里有很多.sh文件,在windows下正常运行通常要折腾一番,最后能不能全部通关,讲究1个“缘”字,还不如直接找个linux环境,能避免不少麻烦,如果不想安装双系统的同学们,也可以使用windows 10/11的WSL子系统(见:windows WSL2避坑指南)
2、没有GPU显卡能玩GLM大模型吗?
能!但体验极差,几乎只能跑个hello world,干不了啥正事儿,不久会被劝退,还是建议租个服务器,或者至少弄个8G显存的N卡,我用的就是RTX4060.
注:如果实在想在纯CPU环境跑,建议使用c++重构版本的chatglm
3、ubuntu上怎么安装cuda及cudnn?
这里有一个很坑的地方,网上几乎所有文章全是清一色的介绍怎么用命令行,一步步下载安装,巨复杂,关键还不一定好使,我的ubuntu 22.04 LTS参照这些方法,试了2次,每次安装到最后,把gdm3关闭后,安装完再重启,就黑屏进不去了,按网上的各种解救方法也没效果,最后只能把ubuntu重装,浪费我不少时间 。
后面发现,软件与更新里,点点鼠标就能完成的事儿
3.1 先把服务器源设置成中国或主服务器
强烈建议:先不要按网上说的,把源换成阿里云、清华 这些国内镜像站点,不是说它们不好,而是国内镜像站点或多或少,可能更新不及时,有些依赖包不全,导致最后各种其名其妙的问题。
我在安装gcc/g++/make时就因为这个源的问题,折腾了好久,一直提示依赖项不满足 ,最后换成主服务器,就解决了。
在3.2之前,建议先安装以下组件(可能并不需要)
sudo apt install gcc
sudo apt install g++
sudo apt install make
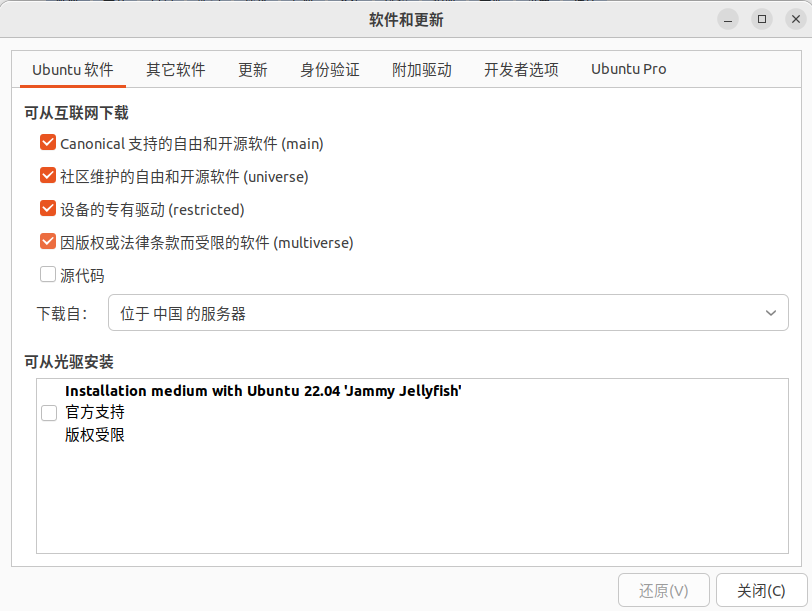
3.2 附加驱动,选择专有驱动(默认是带-open的)
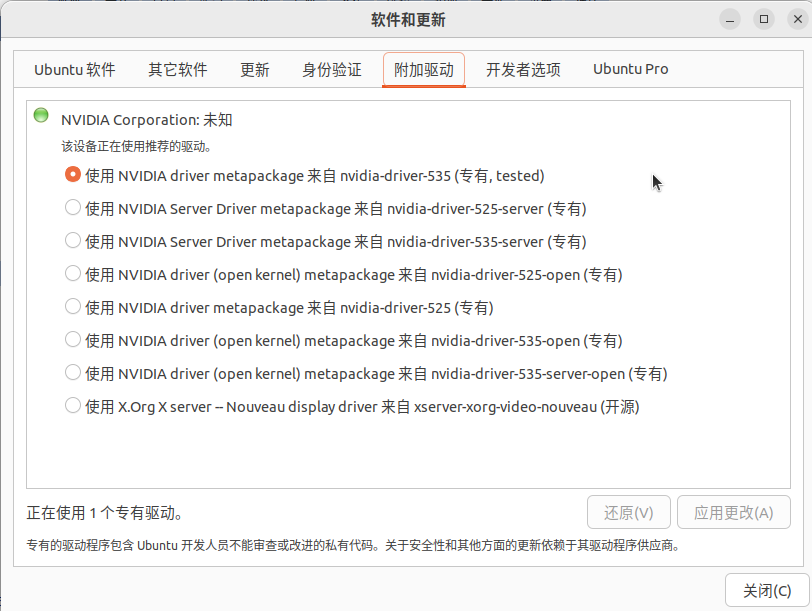
然后关闭,等着安装完成即可.
3.3 安装nvitop
这一步是可选的,推荐大家安装这个小工具 , 比nvidia-smi 好用太多,参见下面的截图, GPU的使用情况一目了然
conda install -c conda-forge nvitop

4、ptuning微调问题
按ptuing/readme.md的介绍,把AdvertiseGen训练了一把,量化8(其它核心参数没改)
PRE_SEQ_LEN=128
LR=2e-2
NUM_GPUS=1 torchrun --standalone --nnodes=1 --nproc-per-node=$NUM_GPUS main.py \
--do_train \
--train_file AdvertiseGen/train.json \
--validation_file AdvertiseGen/dev.json \
--preprocessing_num_workers 10 \
--prompt_column content \
--response_column summary \
--overwrite_cache \
--model_name_or_path /home/jimmy/code/model/chatglm2-6b \
--output_dir /home/jimmy/code/model/output/adgen-chatglm2-6b-pt-$PRE_SEQ_LEN-$LR \
--overwrite_output_dir \
--max_source_length 64 \
--max_target_length 128 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 16 \
--predict_with_generate \
--max_steps 3000 \
--logging_steps 10 \
--save_steps 1000 \
--learning_rate $LR \
--pre_seq_len $PRE_SEQ_LEN \
--quantization_bit 8
跑了15小时,下面是output目录里的结果汇总:
{
"epoch": 0.42,
"train_loss": 3.3751344401041665,
"train_runtime": 54080.5566,
"train_samples": 114599,
"train_samples_per_second": 0.888,
"train_steps_per_second": 0.055
}
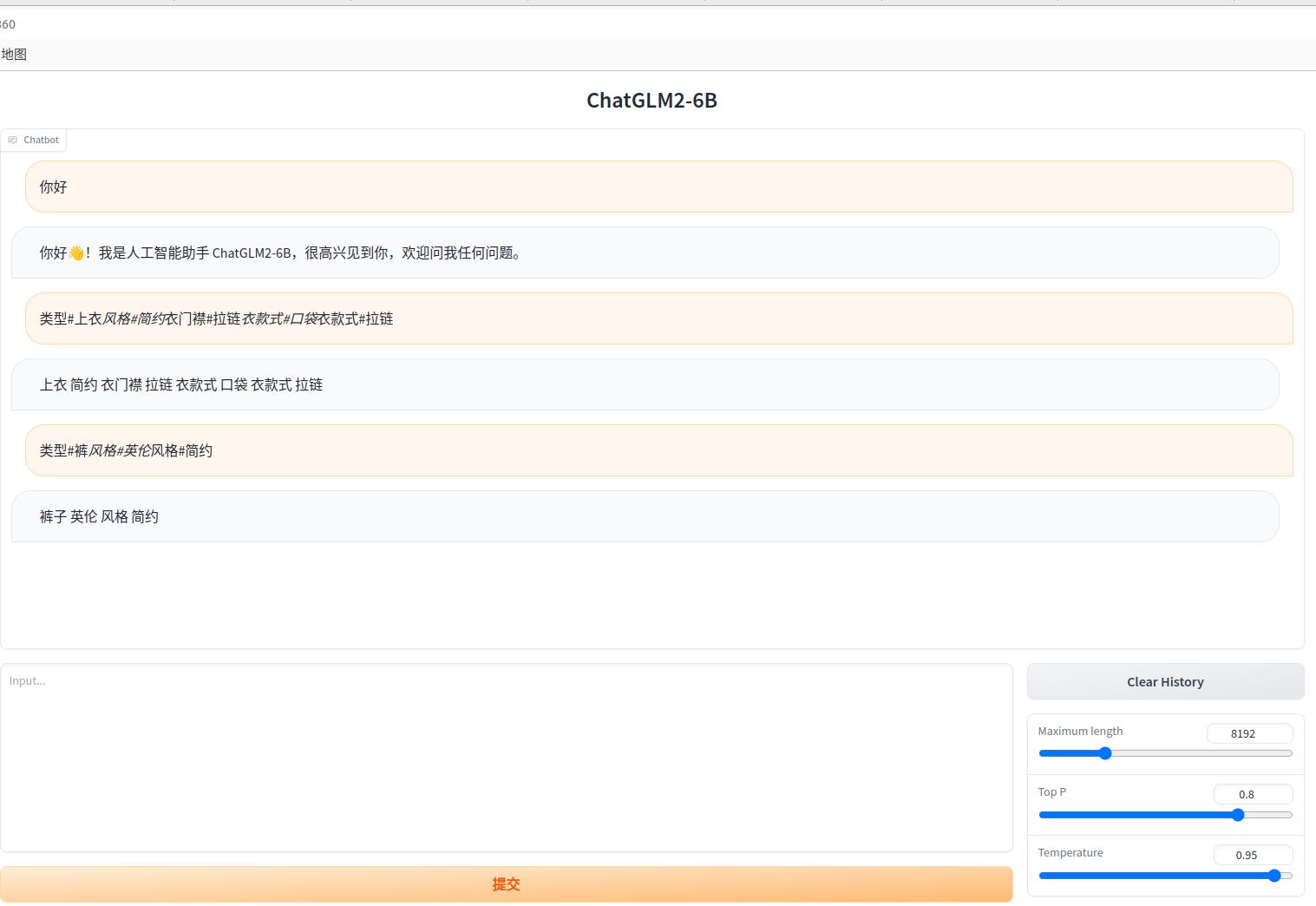
跑完之后,对比了下,对于服装类的问题,回答确实看上去更专业了 ,参考下图:
徾调前:
徾调后:
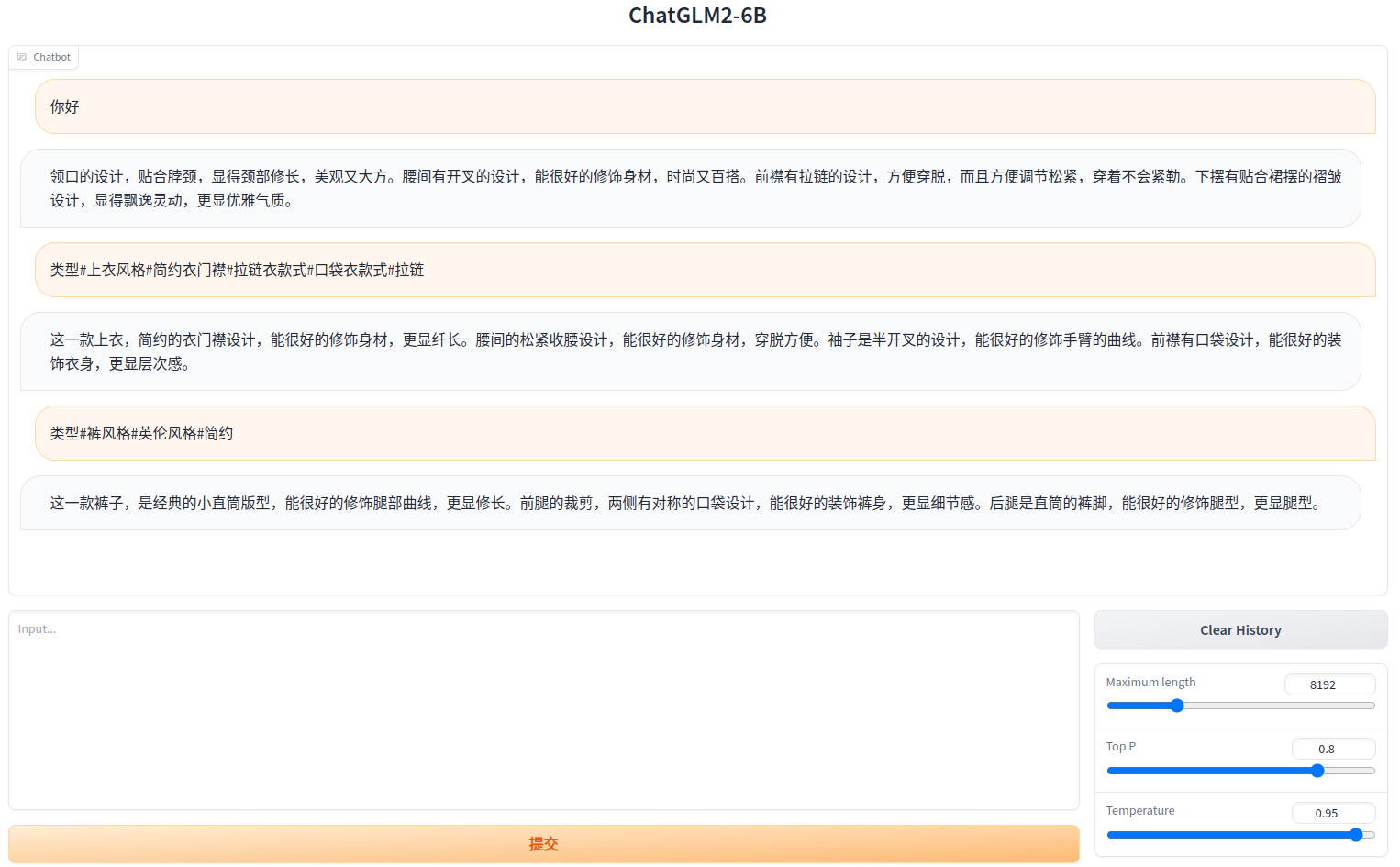
但也出现了1个严重的新问题:原来的通用对话能力退化了,问个“你好”都回答服装问题。在ChatGLM的微信交流群里问了下,发现不止我1个这样,大致原因是好比1个德智体美劳全面发展的学生,后面让他专门训练体育,到后来就成了体育生,只会运动,其它能力就退化了,解决办法是训练集中也加入其它通用知识一起训练,以保证其它能力依然可用;或者降低学习速率(即LR值),但是这样会导致专项能力的训练结果也跟着降低。看来微调训练是一门艺术!
ubuntu上搭建ChatGLM2-6b环境及ptuing微调训练的坑的更多相关文章
- Ubuntu上搭建比特币运行环境
Ubuntu版本:16.04.3 Bitcoin Core版本:0.16 1. 比特币运行依赖的开源库 (1)必须依赖的库 库 目的 描述 libssl 加密 随机数生成,椭圆曲线加密算法 libbo ...
- 【玩转Ubuntu】02. Ubuntu上搭建Android开发环境
一. 基本环境搭建 1.官网http://developer.android.com/sdk/index.html ,下载adt-bundle-linux-x86_64-20130729.zip 2. ...
- 在ubuntu上搭建交叉编译环境---arm-none-eabi-gcc
最近要开始搞新项目,基于arm的高通方案的项目. 那么,如何在ubuntu上搭建这个编译环境呢? 1.找到相关的安装包:http://download.csdn.net/download/storea ...
- Ubuntu上搭建Watir-Webdriver与Cucumber环境
本文主要演示如何在Ubuntu上搭建Watir-Webdriver与Cucumber环境,用于自动化测试. 1. Ubuntu环境 A. 安装 因为我的工作机是Windows,所以采用虚拟机的方式使用 ...
- Ubuntu上搭建Hadoop环境(单机模式+伪分布模式)
首先要了解一下Hadoop的运行模式: 单机模式(standalone) 单机模式是Hadoop的默认模式.当首次解压Hadoop的源码包时,Hadoop无法了解硬件安装环境,便保守地选 ...
- 在Ubuntu上搭建kindle gtk开发环境
某个角度上说,kindle很类似android,同样的Linux内核,同样的Java用户层.不过kindle更注重简单.节能.稳定.Amazon一向认为,功能过多会分散人们阅读时候的注意力. Kind ...
- Ubuntu上搭建Hadoop环境(单机模式+伪分布模式) (转载)
Hadoop在处理海量数据分析方面具有独天优势.今天花了在自己的Linux上搭建了伪分布模式,期间经历很多曲折,现在将经验总结如下. 首先,了解Hadoop的三种安装模式: 1. 单机模式. 单机模式 ...
- Ubuntu上搭建Hadoop环境(单机模式+伪分布模式)【转】
[转自:]http://blog.csdn.net/hitwengqi/article/details/8008203 最近一直在自学Hadoop,今天花点时间搭建一个开发环境,并整理成文. 首先要了 ...
- 如何快速在Ubuntu上搭建python环境?
如何快速在Ubuntu上搭建python环境? 一.准备好python源码包 使用curl命令获取python源码包的过程很缓慢且容易失败,因此提前去官网下载好后放在本地是最好的办法. 二.启动镜像并 ...
- 在Ubuntu14.04 64bit上搭建单机Spark环境,IDE为Intelli IDEA
在Ubuntu14.04 64bit上搭建单机Spark环境,IDE为Intelli IDEA 一. 环境 Ubuntu14.04 64位 JDK 1.8.0_73 scala-2.10. ...
随机推荐
- edge浏览器新版,开心的扔掉chrome!还是微软更良心!windows系统全球用也没说啥!让你android能!
直接上图吧,这下google慌了吧!微软给力呀!关键是版本直接最新的chromium!比起qq浏览器70,360浏览器78新的多了: 微软开发,质量信得过,就个人隐私之类的我更相信微软,比起googl ...
- github无法加载图片的解决办法--转载
windows下hosts文件提示不能修改的,可以剪切到其他地方修改后再剪切回去. https://blog.csdn.net/u011583927/article/details/104384169
- Go 1.22 相比 Go 1.21 有哪些值得注意的改动?
本系列旨在梳理 Go 的 release notes 与发展史,来更加深入地理解 Go 语言设计的思路. https://go.dev/doc/go1.22 Go 1.22 值得关注的改动: for ...
- Linux的API
一.常用命令 1.Linux命令之剪切 mv 目标文件 目的文件 2.Linux之新增文件夹 mkdir 路径+文件名 3.Linux之删除命令 rm 删除文件 rmdir 删除文件夹
- B1037 在霍格沃茨找零钱
如果你是哈利·波特迷,你会知道魔法世界有它自己的货币系统 -- 就如海格告诉哈利的:"十七个银西可(Sickle)兑一个加隆(Galleon),二十九个纳特(Knut)兑一个西可,很容易.& ...
- 阅读类元服务开发笔记---week3
.markdown-body { line-height: 1.75; font-weight: 400; font-size: 16px; overflow-x: hidden; color: rg ...
- Spring注解之@Autowired组件装配
前言 说起Spring的@Autowired注解,想必大家已经耳熟能详:对于小编而言,虽然一直知道怎么用,但是并没有去了解过,因此,本文就梳理一下@Autowired注解的功能,如有写的不准确的地方, ...
- Nginx配置HTTPS认证
概述 什么是https? 可以阅读这篇文章:https://www.cnblogs.com/huangSir-devops/p/18806406 在生产环境中,网站的访问一般都是使用https加密的, ...
- Python字符串进化史:从青涩到成熟的蜕变
Python字符串进化史:从青涩到成熟的蜕变 Python 2.x 的字符串世界 在 Python 2.x 的时代,字符串处理已经是编程中的基础操作,但与现在相比,有着不少差异.在 Python 2. ...
- C++数据结构和算法代码模板总结——算法部分
数据结构和算法学*了将*两周,及时总结和整理一下相关的知识点温故而知新.(一)C++双指针,有个经典的问题:荷兰国旗问题.[leetcode]75.颜色分类 public void sortColor ...