Canal同步MySQL增量数据
引言
在现在的系统开发中,为了提高查询效率 , 以及搜索的精准度, 会大量的使用 redis 、memcache 等 nosql 系统的数据库 , 以及 solr 、 elasticsearch 类似的全文检索服务。
那么这个时候, 就又有一个问题需要我们来考虑, 就是数据同步的问题, 如何将实时变化的数据库中的数据同步到 MySQL数据库、solr 的索引库中或者 redis 中呢 ?
同步数据一般会考虑以下几个方法:
- 业务代码手动同步
- 定时任务同步
- MQ实现同步
- Canal进行同步
在以上方法中,最容易实现的就是业务代码手动同步,但它的缺点也很明显,代码耦合度很高并且执行效率低下;定时任务方法的优点是能够与业务代码解耦,但缺点是数据的实时性不高;MQ消息同步的话可以做到代码解耦,伪准时,但是已然需要添加MQ相关的代码。
而Canal就解决了以上问题,它可以做到业务代码完全解耦,API完全解耦,可以做到准实时。
Canal 是阿里知名的开源项目,主要用途是基于 MySQL 数据库增量日志(binlog)解析,提供增量数据订阅和消费。
下面就来具体学习一下Canal同步原理以及同步MySQL增量数据到ES的实现。
Canal原理
Canal架构
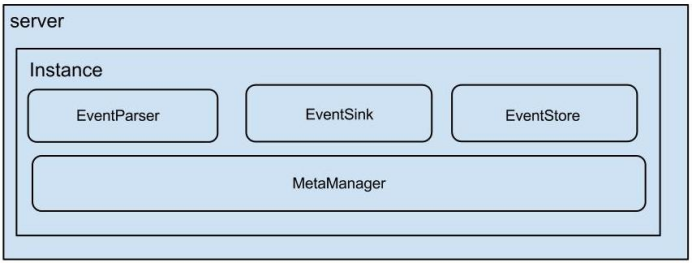
- server 代表一个 canal 运行实例,对应于一个 jvm。
- instance 对应于一个数据队列 (1个 canal server 对应 1..n 个 instance )
- instance 下的子模块
- eventParser: 数据源接入,模拟 slave 协议和 master 进行交互,协议解析
- eventSink: Parser 和 Store 链接器,进行数据过滤,加工,分发的工作
- eventStore: 数据存储
- metaManager: 增量订阅 & 消费信息管理器
工作原理
MySQL主从同步
Canal是基于MySQL的binlog实现同步的,因此先了解一下MySQL主从同步的原:
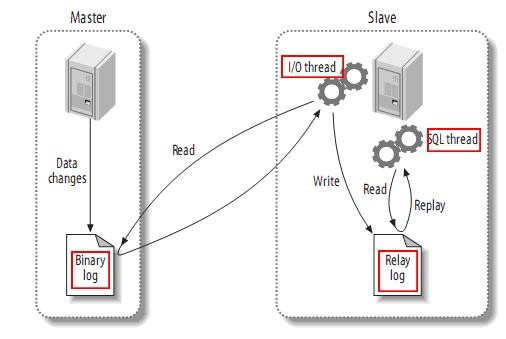
从上层来看,主从复制分成三步:
- master 将改变记录到二进制日志 (binary log) 中(这些记录叫做二进制日志事件, binary log events ,可以通过 show binlog events 进行查看);
- slave 将 master 的 binary log events 拷贝到它的中继日志 (relay log);
- slave 重做中继日志中的事件将改变反映它自己的数据。
内部原理
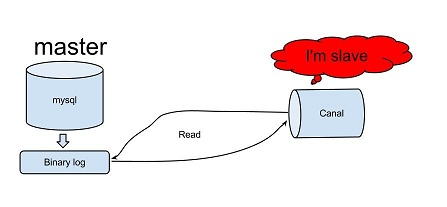
上图就是Canal的内部原理图,大致原理如下:
- canal 模拟 mysql slave 的交互协议,伪装自己为 mysql slave ,向 mysql master 发送 dump 协议。
- mysql master 收到 dump 请求,开始推送 binary log 给 slave( 也就是 canal) 。
- canal 解析 binary log 对象 ( 原始为 byte 流 ) 。
EventParser在向mysql发送dump命令之前会先从Log Position中获取上次解析成功的位置(如果是第一次启动,则获取初始指定位置或者当前数据段binlog位点)。mysql接受到dump命令后,由EventParser从mysql上pull binlog数据进行解析并传递给EventSink(传递给EventSink模块进行数据存储,是一个阻塞操作,直到存储成功),传送成功之后更新Log Position。工作流程如下图所示:
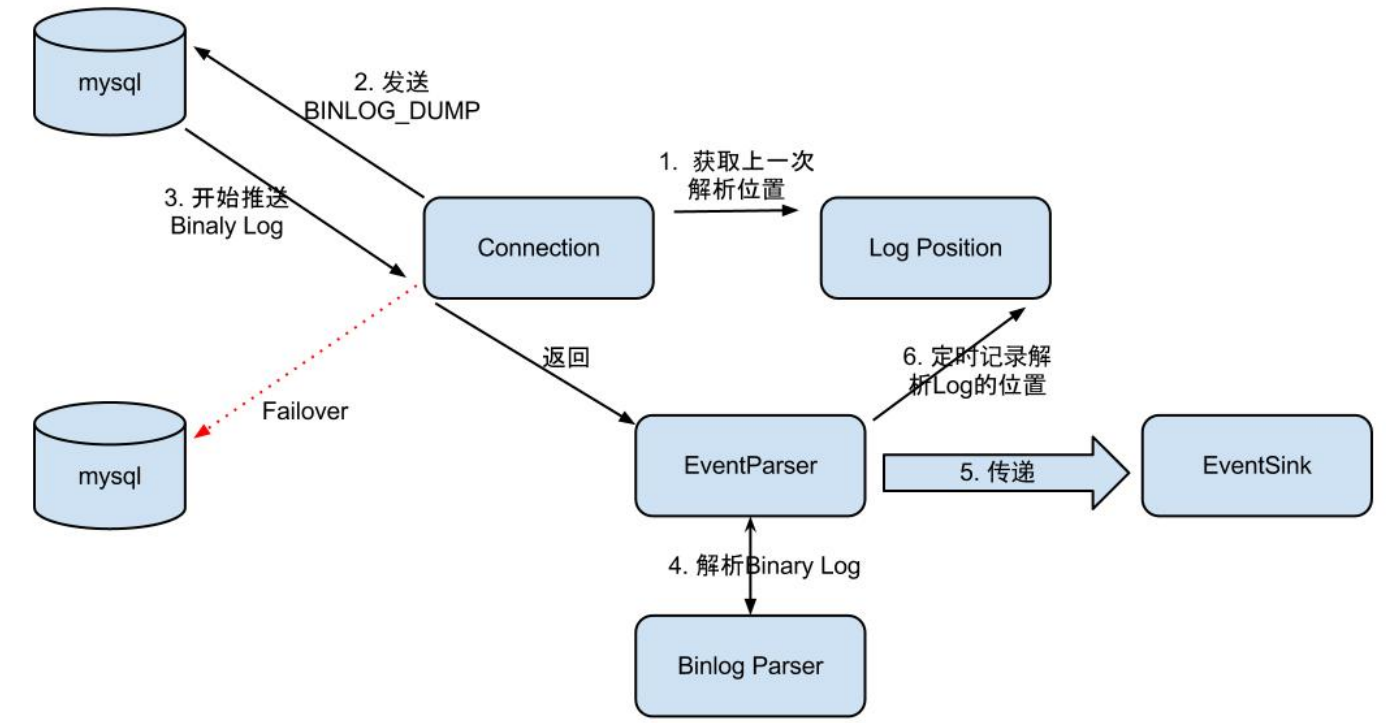
EventSink起到一个类似channel的功能,可以对数据进行过滤、分发/路由(1:n)、归并(n:1)和加工。EventSink是连接EventParser和EventStore的桥梁。
EventStore实现模式是内存模式,内存结构为环形队列,由三个指针(Put、Get和Ack)标识数据存储和读取的位置。
MetaManager是增量订阅&消费信息管理器,增量订阅和消费之间的协议包括get/ack/rollback,分别为:
- Message getWithoutAck(int batchSize),允许指定batchSize,一次可以获取多条,每次返回的对象为Message,包含的内容为:batch id[唯一标识]和entries[具体的数据对象]。
- void rollback(long batchId),顾名思义,回滚上次的get请求,重新获取数据。基于get获取的batchId进行提交,避免误操作。
- void ack(long batchId),顾名思义,确认已经消费成功,通知server删除数据。基于get获取的batchId进行提交,避免误操作。
实践
真实场景中,canal 高可用依赖 zookeeper ,我将客户端模式可以简单划分为:TCP 模式 和 MQ 模式 。
实战中我们经常会使用 MQ 模式 。因为 MQ 模式的优势在于解耦 ,canal server 将数据变更信息发送到消息队列 kafka 或者 RocketMQ ,消费者消费消息,顺序执行相关逻辑即可。
顺序消费
对于指定的一个 Topic ,所有消息根据 Sharding Key 进行区块分区,同一个分区内的消息按照严格的先进先出(FIFO)原则进行发布和消费。同一分区内的消息保证顺序,不同分区之间的消息顺序不做要求。

MySQL配置
1、对于自建 MySQL , 需要先开启 Binlog 写入功能,配置 binlog-format 为 ROW 模式,my.cnf 中配置如下
[mysqld]
log-bin=mysql-bin # 开启 binlog
binlog-format=ROW # 选择 ROW 模式
server_id=1 # 配置 MySQL replaction 需要定义,不要和 canal 的 slaveId 重复
2、授权 canal 链接 MySQL 账号具有作为 MySQL slave 的权限, 如果已有账户可直接 grant 。
CREATE USER canal IDENTIFIED BY 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
-- GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' ;
FLUSH PRIVILEGES;
3、创建数据库商品表 t_product 。
CREATE TABLE `t_product` (
`id` BIGINT ( 20 ) NOT NULL AUTO_INCREMENT,
`name` VARCHAR ( 255 ) COLLATE utf8mb4_bin NOT NULL,
`price` DECIMAL ( 10, 2 ) NOT NULL,
`status` TINYINT ( 4 ) NOT NULL,
`create_time` datetime NOT NULL,
`update_time` datetime NOT NULL,
PRIMARY KEY ( `id` )
) ENGINE = INNODB DEFAULT CHARSET = utf8mb4 COLLATE = utf8mb4_bin
Elasticsearch配置
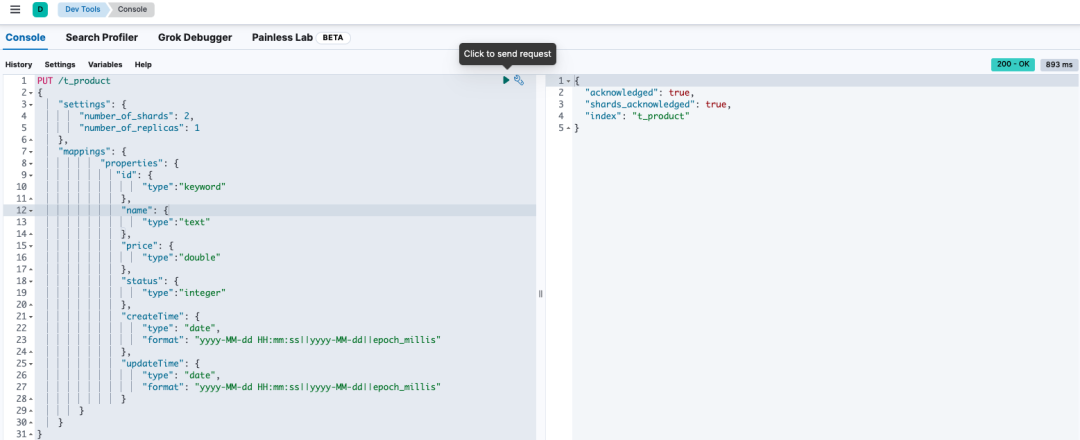
使用 Kibana 创建商品索引 。
PUT /t_product
{
"settings": {
"number_of_shards": 2,
"number_of_replicas": 1
},
"mappings": {
"properties": {
"id": {
"type":"keyword"
},
"name": {
"type":"text"
},
"price": {
"type":"double"
},
"status": {
"type":"integer"
},
"createTime": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
},
"updateTime": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
}
}
}
执行完成,如图所示 :
MQ配置
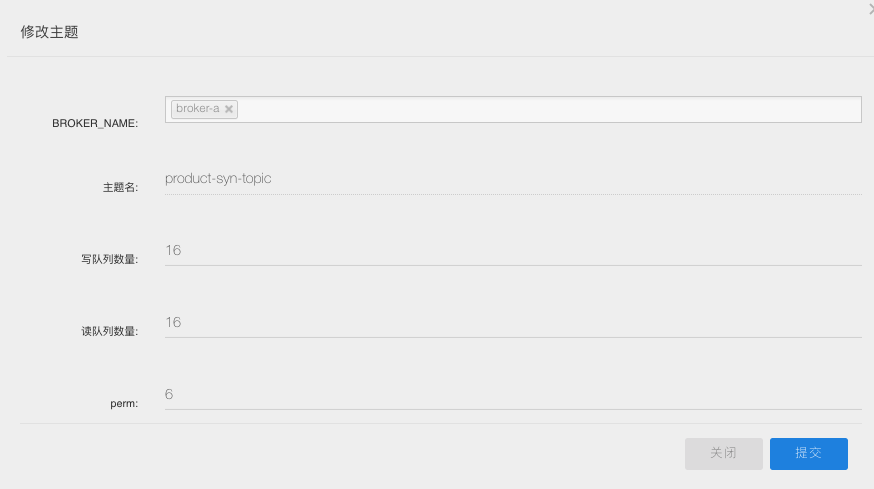
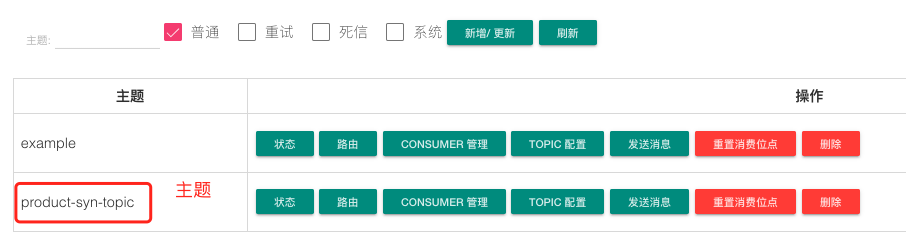
这里我是用的是RocketMQ,创建主题:product-syn-topic ,canal 会将 Binlog 的变化数据发送到该主题。
Canal配置
我选取 canal 版本 1.1.6 ,进入 conf 目录。
1、配置 canal.properties
#集群模式 zk地址
canal.zkServers = localhost:2181
#本质是MQ模式和tcp模式 tcp, kafka, rocketMQ, rabbitMQ, pulsarMQ
canal.serverMode = rocketMQ
#instance 列表
canal.destinations = product-syn
#conf root dir
canal.conf.dir = ../conf
#全局的spring配置方式的组件文件 生产环境,集群化部署
canal.instance.global.spring.xml = classpath:spring/default-instance.xml
###### 以下部分是默认值 展示出来
# Canal的batch size, 默认50K, 由于kafka最大消息体限制请勿超过1M(900K以下)
canal.mq.canalBatchSize = 50
# Canal get数据的超时时间, 单位: 毫秒, 空为不限超时
canal.mq.canalGetTimeout = 100
# 是否为 flat json格式对象
canal.mq.flatMessage = true
2、instance 配置文件
在 conf 目录下创建实例目录 product-syn , 在 product-syn 目录创建配置文件 :instance.properties。
# 按需修改成自己的数据库信息
#################################################
...
canal.instance.master.address=192.168.1.20:3306
# username/password,数据库的用户名和密码
...
canal.instance.dbUsername = canal
canal.instance.dbPassword = canal
...
# table regex
canal.instance.filter.regex=mytest.t_product
# mq config
canal.mq.topic=product-syn-topic
# 针对库名或者表名发送动态topic
#canal.mq.dynamicTopic=mytest,.*,mytest.user,mytest\\..*,.*\\..*
canal.mq.partition=0
# hash partition config
#canal.mq.partitionsNum=3
#库名.表名: 唯一主键,多个表之间用逗号分隔
#canal.mq.partitionHash=mytest.person:id,mytest.role:id
#################################################
3、服务启动
启动两个 canal 服务,我们从 zookeeper gui 中查看服务运行情况 。
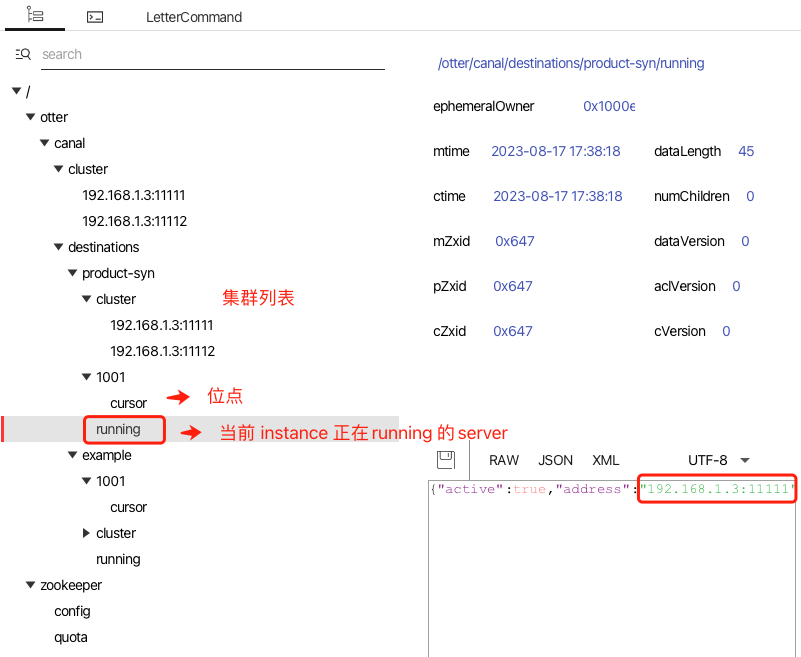
修改一条 t_product 表记录,可以从 RocketMQ 控制台中观测到新的消息。

消费者
1、产品索引操作服务
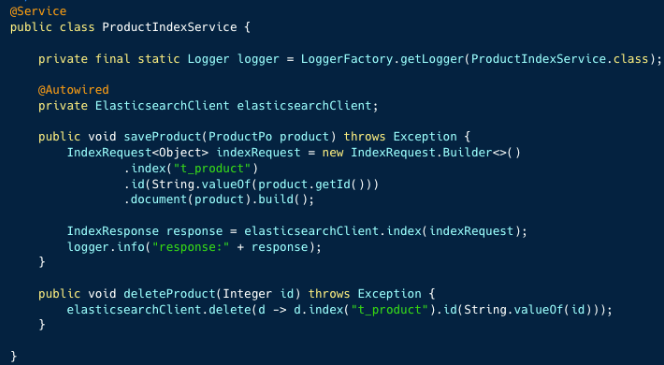
2、消费监听器
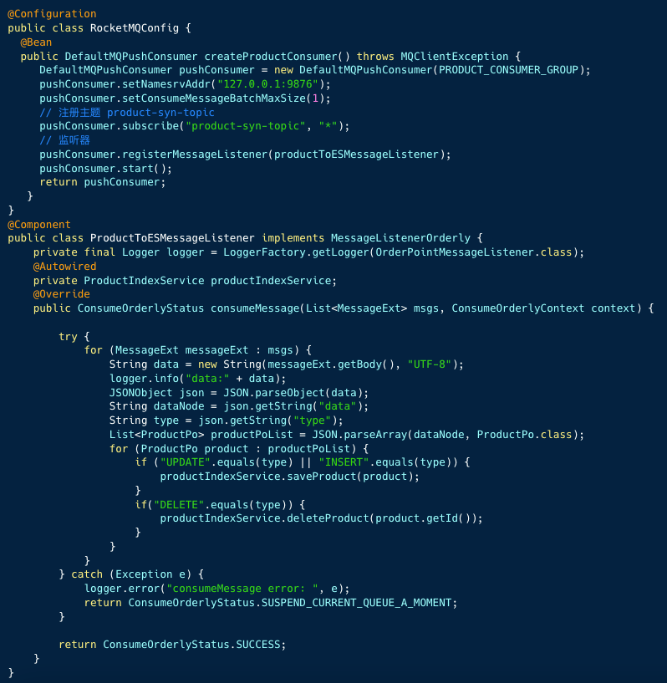
消费者逻辑重点有两点:
- 顺序消费监听器
- 将消息数据转换成 JSON 字符串,从
data节点中获取表最新数据(批量操作可能是多条)。然后根据操作类型UPDATE、INSERT、DELETE执行产品索引操作服务的方法。
最后
Canal 是一个非常有趣的开源项目,实际生产中很多公司使用 Canal 构建数据传输服务( Data Transmission Service ,简称 DTS ) 。
推荐大家阅读这个开源项目,你可以从中学习到网络编程、多线程模型、高性能队列 Disruptor、 流程模型抽象等。
Canal同步MySQL增量数据的更多相关文章
- Canal:同步mysql增量数据工具,一篇详解核心知识点
老刘是一名即将找工作的研二学生,写博客一方面是总结大数据开发的知识点,一方面是希望能够帮助伙伴让自学从此不求人.由于老刘是自学大数据开发,博客中肯定会存在一些不足,还希望大家能够批评指正,让我们一起进 ...
- canal同步MySQL数据到ES6.X
背景: 最近一段时间公司做一个技术架构的更改,由于之前使用的solr和目前的业务不太匹配,具体原因不多说啦.所以要把数据放到Elasticsearch中进行快速的搜索,这是便产生了一个数据迁移的需求, ...
- 使用Canal作为mysql的数据同步工具
一.Canal介绍 1.应用场景 在前面的统计分析功能中,我们采取了服务调用获取统计数据,这样耦合度高,效率相对较低,目前我采取另一种实现方式,通过实时同步数据库表的方式实现,例如我们要统计每天注册与 ...
- 基于Spark Streaming + Canal + Kafka对Mysql增量数据实时进行监测分析
Spark Streaming可以用于实时流项目的开发,实时流项目的数据源除了可以来源于日志.文件.网络端口等,常常也有这种需求,那就是实时分析处理MySQL中的增量数据.面对这种需求当然我们可以通过 ...
- 开源基于Canal的开源增量数据订阅&消费中间件
CanalSync canal 是阿里巴巴开源的一款基于数据库增量日志解析,提供增量数据订阅&消费,目前主要支持了MySQL(也支持mariaDB). 我开发的这个CanalSync项目 ht ...
- 如何通过 Docker 部署 Logstash 同步 Mysql 数据库数据到 ElasticSearch
在开发过程中,我们经常会遇到对业务数据进行模糊搜索的需求,例如电商网站对于商品的搜索,以及内容网站对于内容的关键字检索等等.对于这些高级的搜索功能,显然数据库的 Like 是不合适的,通常我们采用 E ...
- ElasticSearch 安装 go-mysql-elasticsearch 同步mysql的数据
一.首先在Centos6.5上安装 go 语言环境 下载Golang语言包:https://studygolang.com/dl [hoojjack@localhost src]$ ls apache ...
- canal同步异常:当表结构变化时,同步失败
场景 canal 同步Mysql一段时间后突然失败,报如如下错误: 2021-08-06 16:16:51.732 [MultiStageCoprocessor-Parser-Twt_instance ...
- Canal——增量同步MySQL数据到ElasticSearch
1.准备 1.1.组件 JDK:1.8版本及以上: ElasticSearch:6.x版本,目前貌似不支持7.x版本: Kibana:6.x版本: Canal.deployer:1 ...
- 几篇关于MySQL数据同步到Elasticsearch的文章---第二篇:canal 实现Mysql到Elasticsearch实时增量同步
文章转载自: https://mp.weixin.qq.com/s?__biz=MzI2NDY1MTA3OQ==&mid=2247484377&idx=1&sn=199bc88 ...
随机推荐
- 黑客工具:Amass – 寻找子域
安装 所有信息都可以在 OWASP Amass 项目的 Github 页面上找到:https://github.com/OWASP/Amass.我们将一起完成安装过程,以便更快地部署. 转到发布页面并 ...
- idea项目提交到码云
第一步:创建一个项目 第二步:在码云上新建一个项目.[注意把使用Readme复选框取消掉] 第三步:复制gitee地址 第四步:创建本地git仓库 第五步:选择自己需要上传到码云的项目名 第六步:提交 ...
- ROS入门21讲(5)
九.服务数据的定义与使用 1.服务模型 2.自定义服务数据 Person.srv string name uint8 sex uint8 age uint8 unknown = 0 uint8 mal ...
- CSS动画(动态导航栏)
1.项目简介 一个具有创意的导航菜单不仅能为你的大作业增色,还能展示你的技术实力.本文将分享一系列常用于期末大作业的CSS动画导航效果,这些效果不仅外观酷炫,而且易于实现.我们提供了一键复制的代码,让 ...
- 一些很好用的SVN功能
1.checkout 1.1 只checkout部分目录和文件 目的:有时候项目的文件很多,但是只会关心其中的某几个文件,就可以只checkout这几个文件,可以缩短checkout时间且减少其他文件 ...
- Maxima 使用教程
说起数学软件,我们很多人脑子里浮现出的第一个就是 matlab,不可否认,matlab 确实是一个优秀的数学软件,但是它需要付费啊(这里不讨论盗版问题).那么有没有一个同样强大但免费的数学软件呢?答案 ...
- 使用 vscode 简单配置 ESP32 连接 Wi-Fi 每日定时发送 HTTP 和 HTTPS 请求
最新博客文章链接 文字更新时间:2024/11/07 由于学校校园网,如果长时间不重新登陆的话,网速会下降,所以想弄个能定时发送 HTTP 请求的东西.由于不想给路由器刷系统,也麻烦.就开始考虑使用局 ...
- quartz集群增强版🎉
quartz集群增强版 转载请著名出处https://www.cnblogs.com/funnyzpc/p/18534034 这是除了mee_admin之外,投入时间精力最多的一次开源了,quartz ...
- 使用switch语句的注意事项
目录 case后需要手动break switch内的变量定义 变量没有定义在语句块内 变量定义在语句块内 表述多情况时不能用逗号 case后需要手动break switch(i){ case 1: 语 ...
- win10本地客户端配置SSL并使用MQTTX
1. 本地下载Openssl(默认安装即可,最后一个将打赏取消勾选) Win32/Win64 OpenSSL Installer for Windows - Shining Light Pro ...