Spring AI 增加混元 embedding 向量功能
上次我们讨论了如何将自己的开源项目发布到 Maven 中央仓库,确保其能够方便地被其他开发者使用和集成。而我们的项目 spring-ai-hunyuan 已经具备了正常的聊天对话功能,包括文本聊天和图片理解等基础功能。今天,我们进一步优化和扩展了该项目,新增了一个向量化功能。如图所示:
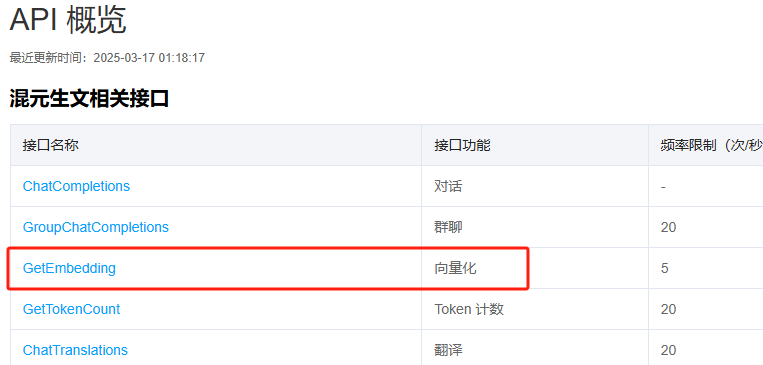
好的,首先就是对接API接口。我们开始。
向量功能
接口调用
腾讯的所有接口共享同一个域名,并且接口之间并没有按照请求路径进行细分。主要依赖请求头中的action字段来区分不同的接口调用。通过这种方式,接口能够在同一个域名下通过不同的请求头信息进行区分和处理,如下图所示:

所以,我们以前写的HunYuanAPI类就需要改一下,否则他默认走的全是聊天接口。修改如下:
ResponseEntity<EmbeddingResponse> embeddingResponseResponseEntity = this.restClient.post().uri("/")
.header("X-TC-Action", HunYuanConstants.DEFAULT_EMBED_ACTION).body(embeddingRequest).retrieve().toEntity(EmbeddingResponse.class);
在正常调用过程中,header字段用于区分不同的接口请求。这是因为在我使用的restClient加密方式中,采用了拦截器的形式。通过这种方式,每次请求发起时,拦截器都会被触发,从而使我能够轻松地读取到请求头中的相关信息。
这样一来,我可以在请求的整个生命周期内获取和处理这些信息。具体实现细节如下所示:
@Override
public ClientHttpResponse intercept(HttpRequest request, byte[] body, ClientHttpRequestExecution execution) throws IOException {
String action = request.getHeaders().getFirst("X-TC-Action");
MultiValueMap<String, String> httpHeadersConsumer = hunYuanAuthApi.getHttpHeadersConsumer(action, body);
.......
}
通过这种方式,我们不再依赖于写死的固定值来传递参数,而是能够动态地处理每次请求时的不同值。完成接口调用的处理后,接下来需要关注的是输入参数的管理与传递。
输入参数
这里的输入参数有两个可选值,如图所示:

为了简化对接过程,我们选择直接使用数组类型的输入形式。这种方式不仅使得数据传递更加直观和高效,而且与Spring AI的内部处理机制高度契合。Spring AI在处理数据时,本身也会将输入数据自动转化为数组形式进行处理,具体的实现方式如下所示:
default float[] embed(String text) {
Assert.notNull(text, "Text must not be null");
List<float[]> response = this.embed(List.of(text));
return response.iterator().next();
}
输出参数
处理完了输入参数,那么紧接着就是输出参数了。如图所示:
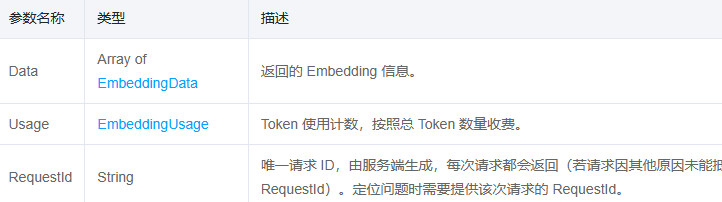
但是,腾讯接口有一个共同特点,就是所有输出参数都被Response字段包围着。所以我们还需要单独处理一下,如下所示:
ResponseEntity<EmbeddingResponse> embeddingResponseResponseEntity = this.restClient.post().uri("/")
.header("X-TC-Action", HunYuanConstants.DEFAULT_EMBED_ACTION).body(embeddingRequest).retrieve().toEntity(EmbeddingResponse.class);
return embeddingResponseResponseEntity.getBody().response();
EmbeddingResponse的结构如下:
@JsonInclude(Include.NON_NULL)
public record EmbeddingResponse(
// @formatter:off
@JsonProperty("Response") EmbeddingList response
) {
// @formatter:on
}
@JsonInclude(Include.NON_NULL)
public record EmbeddingList(// @formatter:off
@JsonProperty("RequestId") String object,
@JsonProperty("Data") List<Embedding> data,
@JsonProperty("Usage") Usage usage) { // @formatter:on
}
自动配置
在正常完成接口调用的编写之后,接下来我们需要着手进行Spring Boot的自动配置编写。
HunYuanEmbeddingProperties
首先一个配置类解析,将配置文件中的配置信息读取到类中,如下所示:
@ConfigurationProperties(HunYuanEmbeddingProperties.CONFIG_PREFIX)
public class HunYuanEmbeddingProperties extends HunYuanParentProperties {
public static final String CONFIG_PREFIX = "spring.ai.hunyuan.embedding";
public static final String DEFAULT_EMBEDDING_MODEL = "hunyuan-embedding";
.......
}
HunYuanAutoConfiguration
这里就是单独配置一下我们需要的embedding模型的接口配置了。如图所示,先将配置类添加到注解中。

然后我们需要注入一下HunYuanEmbeddingModel模型。代码如下:
@Bean
@ConditionalOnMissingBean
@ConditionalOnProperty(prefix = HunYuanEmbeddingProperties.CONFIG_PREFIX, name = "enabled", havingValue = "true",
matchIfMissing = true)
public HunYuanEmbeddingModel hunYuanEmbeddingModel(HunYuanCommonProperties commonProperties,
HunYuanEmbeddingProperties embeddingProperties, ObjectProvider<RestClient.Builder> restClientBuilderProvider,
ObjectProvider<WebClient.Builder> webClientBuilderProvider, RetryTemplate retryTemplate,
ResponseErrorHandler responseErrorHandler, ObjectProvider<ObservationRegistry> observationRegistry,
ObjectProvider<EmbeddingModelObservationConvention> observationConvention) {
var hunyuanApi = hunyuanApi(embeddingProperties.getSecretId(), commonProperties.getSecretId(),
embeddingProperties.getSecretKey(), commonProperties.getSecretKey(), embeddingProperties.getBaseUrl(),
commonProperties.getBaseUrl(),
restClientBuilderProvider.getIfAvailable(RestClient::builder),responseErrorHandler);
var embeddingModel = new HunYuanEmbeddingModel(embeddingProperties.getOptions(), retryTemplate,hunyuanApi, embeddingProperties.getMetadataMode(),
observationRegistry.getIfUnique(() -> ObservationRegistry.NOOP));
observationConvention.ifAvailable(embeddingModel::setObservationConvention);
return embeddingModel;
}
这样一来,我们基本上已经完成了Spring-AI-Hunyuan中向量化功能的集成和配置工作,确保了系统能够顺利进行向量化处理,并与其他模块良好协作。接下来的步骤便是编写单元测试,由于单元测试的编写较为标准且常见,这部分内容就不再详细赘述。
小结
在本次更新中,我们进一步优化了spring-ai-hunyuan项目,新增了向量化功能。首先,我们对接了腾讯API,通过修改HunYuanAPI类来支持不同接口的调用,确保请求头能够正确区分接口类型。接着,我们处理了输入输出参数的管理,将数据以数组形式传递,并适应Spring AI的处理机制。同时,完成了Spring Boot自动配置,确保向量化功能能够顺利运行并与其他模块协同工作。
我是努力的小雨,一个正经的 Java 东北服务端开发,整天琢磨着 AI 技术这块儿的奥秘。特爱跟人交流技术,喜欢把自己的心得和大家分享。还当上了腾讯云创作之星,阿里云专家博主,华为云云享专家,掘金优秀作者。各种征文、开源比赛的牌子也拿了。
想把我在技术路上走过的弯路和经验全都分享出来,给你们的学习和成长带来点启发,帮一把。
欢迎关注努力的小雨,咱一块儿进步!
Spring AI 增加混元 embedding 向量功能的更多相关文章
- Spring Boot 2.2 增加了一个新功能,启动飞起~
前几天栈长分享了一个好玩的框架:一个比Spring Boot快44倍的Java框架!,是不是感觉 Spring Boot 略慢?今天讲一下 Spring Boot 添加的这个新特性,可以大大提升 Sp ...
- Spring 系列教程之容器的功能
Spring 系列教程之容器的功能 经过前面几章的分析,相信大家已经对 Spring 中的容器功能有了简单的了解,在前面的章节中我们一直以 BeanFacotry 接口以及它的默认实现类 XmlBea ...
- Spring Boot开启Druid数据库监控功能
Druid是一个关系型数据库连接池,它是阿里巴巴的一个开源项目.Druid支持所有JDBC兼容的数据库,包括Oracle.MySQL.Derby.PostgreSQL.SQL Server.H2等.D ...
- Spring Cloud Gateway的断路器(CircuitBreaker)功能
欢迎访问我的GitHub https://github.com/zq2599/blog_demos 内容:所有原创文章分类汇总及配套源码,涉及Java.Docker.Kubernetes.DevOPS ...
- Spring +SpringMVC 实现文件上传功能。。。
要实现Spring +SpringMVC 实现文件上传功能. 第一步:下载 第二步: 新建一个web项目导入Spring 和SpringMVC的jar包(在MyEclipse里有自动生成spring ...
- Win8增加了快速启动功能......
(从已经死了一次又一次终于挂掉的百度空间人工抢救出来的,发表日期 2014-05-11) Win8增加了快速启动功能,能让计算机尽快的启动进入Windows界面.win8的这种快速启动功能只会在“关机 ...
- android wear开发之:增加可穿戴设备功能到通知中 - Adding Wearable Features to Notifications
注:本文内容来自:https://developer.android.com/training/wearables/notifications/index.html 翻译水平有限,如有疏漏,欢迎批评指 ...
- Android高级控件(一)——ListView绑定CheckBox实现全选,增加和删除等功能
Android高级控件(一)--ListView绑定CheckBox实现全选,增加和删除等功能 这个控件还是挺复杂的,也是项目中应该算是比较常用的了,所以写了一个小Demo来讲讲,主要是自定义adap ...
- 织梦CMS增加复制文档功能
打开后台目录(/dede)下archives_do.php约430行下添加: /*----------------------------- //复制文档 ---------------------- ...
- Spring mvc 增加静态资源配置后访问不了注解配置的controller
spring mvc 增加静态资源访问配置. 例如: <!-- 静态资源映射 --> <mvc:resources location="/static/" map ...
随机推荐
- cpa-税法
1.税法总论 2.增值税法 3.消费税法 4.企业所得税法 5.个人所得税法 6.城市维护建设税法和烟叶税法 7.关税法和船舶吨税法 8.资源税法和环境保护税法 9.城镇土地使用税法和耕地占用税法 1 ...
- 使用Python的一维卷积
学习&转载文章:使用Python的一维卷积 背景 在开发机器学习算法时,最重要的事情之一(如果不是最重要的话)是提取最相关的特征,这是在项目的特征工程部分中完成的. 在CNNs中,此过程由网络 ...
- 【译】我们最喜欢的2024年的 Visual Studio 新功能
去年,Visual Studio 团队发布了许多新的面向开发人员的改进和 AI 集成,其中许多直接来自您在开发者社区的反馈.在这篇文章中,我们将重点介绍2024年团队最喜欢的功能,这些功能可以提高生产 ...
- TCP/IP协议栈封装解封装过程
发送方将用户数据提交给应用程序把数据送达目的地,整个数据封装流程如下: 用户数据首先传送至应用层,添加应用层信息: 完成应用层处理后,数据将往下层传输层继续传送,添加传输层信息(如TCP或UDP,应用 ...
- 央国企“严选”!天翼云夺得IaaS+PaaS市场桂冠!
10月17日,赛迪顾问发布的<2024中国央国企云市场研究报告>显示,2023年,在中国央国企云"IaaS+PaaS"市场中,中国电信天翼云凭借行业云和全栈服务能力.渠 ...
- 配置计算节点之间的SSH
本文分享自天翼云开发者社区<配置计算节点之间的SSH>,作者:y****n 如果在管理程序之间调整或迁移实例,可能会遇到SSH(拒绝权限)错误.请确保每个节点都配置了SSH密钥验证,以便C ...
- Q:LISTAGG()函数用法笔记(oracle)
.LISTAGG()函数作为普通函数使用时就是查询出来的结果列转为行 ☆LISTAGG 函数既是分析函数,也是聚合函数有两种用法:1.分析函数,如: row_number().rank().dense ...
- 管理虚拟机(virsh)
[root@kvm1 qemu]# virsh --help 开启和关闭 [root@kvm1 qemu]# virsh virsh # help list virsh # list virsh # ...
- 百万架构师第四十课:RabbitMq:RabbitMq-工作模型与JAVA编程|JavaGuide
来源:https://javaguide.net RabbitMQ 1-工作模型与Java编程 课前准备 预习资料 Windows安装步骤 Linux安装步骤 官网文章中文翻译系列 环境说明 操作系统 ...
- 别再为文本提取抓狂!一站式文本提取神器Kreuzberg 助你解决PDF、图片、文档等多格式文件的文本提取难题
大家好,我是六哥,相信很多朋友肯定都有过从各种文档里提取文本的经历,那过程可太让人头疼了!今天就给大家分享一款超实用的现代Python库--Kreuzberg,帮你轻松解决文本提取的难题. 一.Kre ...