编译原理:python编译器--从AST到字节码
首先了解下从AST到生成字节码的整个过程:
编译过程
Python编译器把词法分析和语法分析叫做 "解析(Parse)", 并且放在Parser目录下。
从AST到生成 字节码的过程,才叫做 "编译(Compile)"
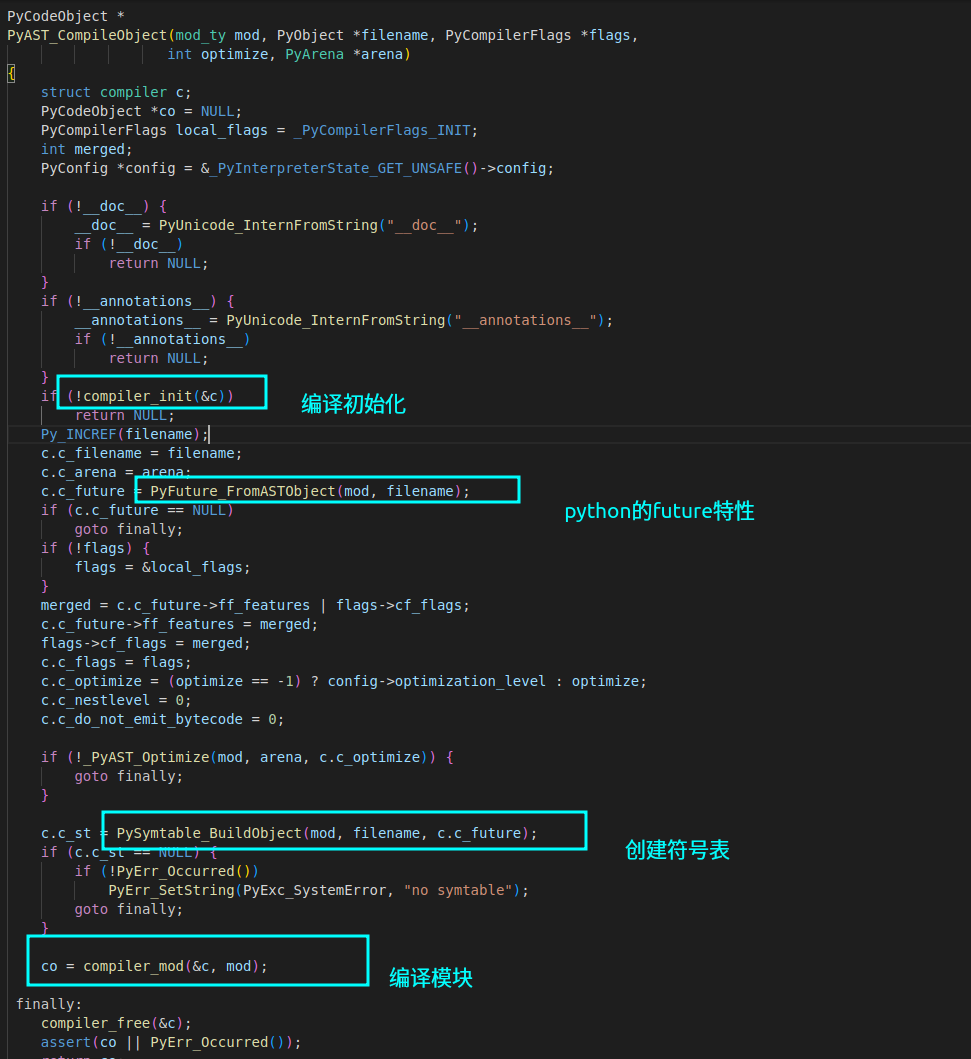
Python编译工作的主干代码是在**Python/compile.c **, 它主要完成5项工作:
第一步,检查future语句。future 语句是 Python 的一个特性,让你可以提前使用未来版本的特性,提前适应语法和语义上的改变。
第二步,建立符号表
第三步,为基本块产生指令
第四步,汇编过程:把所有基本块的代码组装在一起
第五步,对字节码做窥孔优化
语义分析:建立符号表和引用消解
通常来说,在语义分析阶段首先是建立符号表,然后在此基础上做引用消解和类型检查。
Python为动态类型的语言,类型检查应该是不需要的,但引用消解还是要做的
python的符号表定义在 Include/symtable.h中,其中定义了两个结构,分别是符号表和符号表的条目:
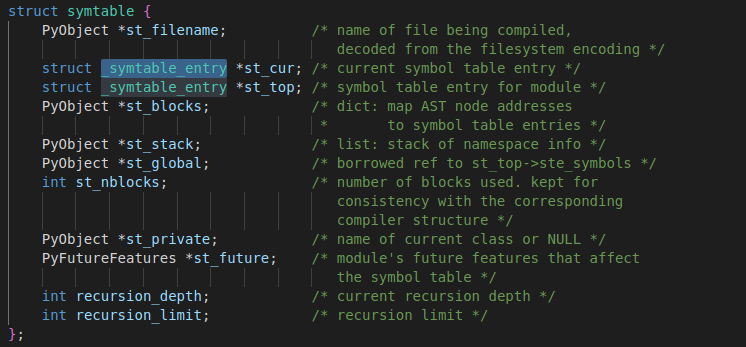
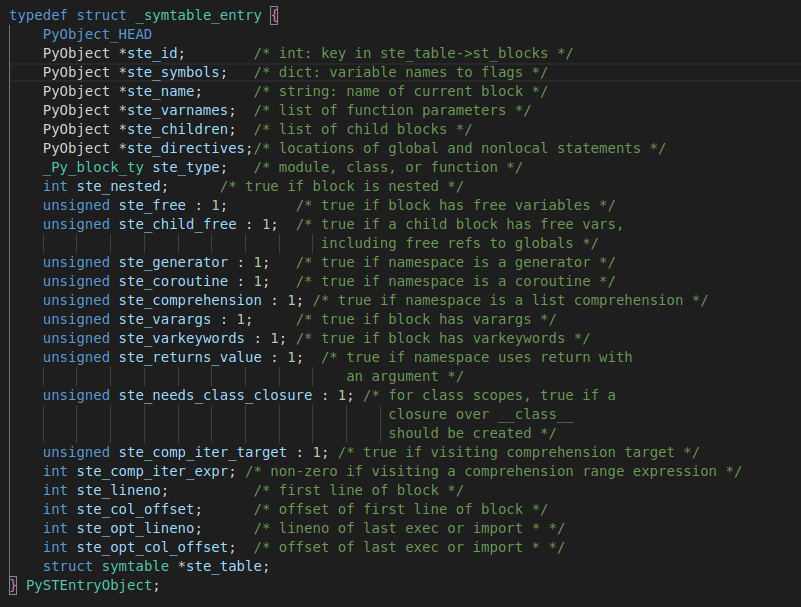
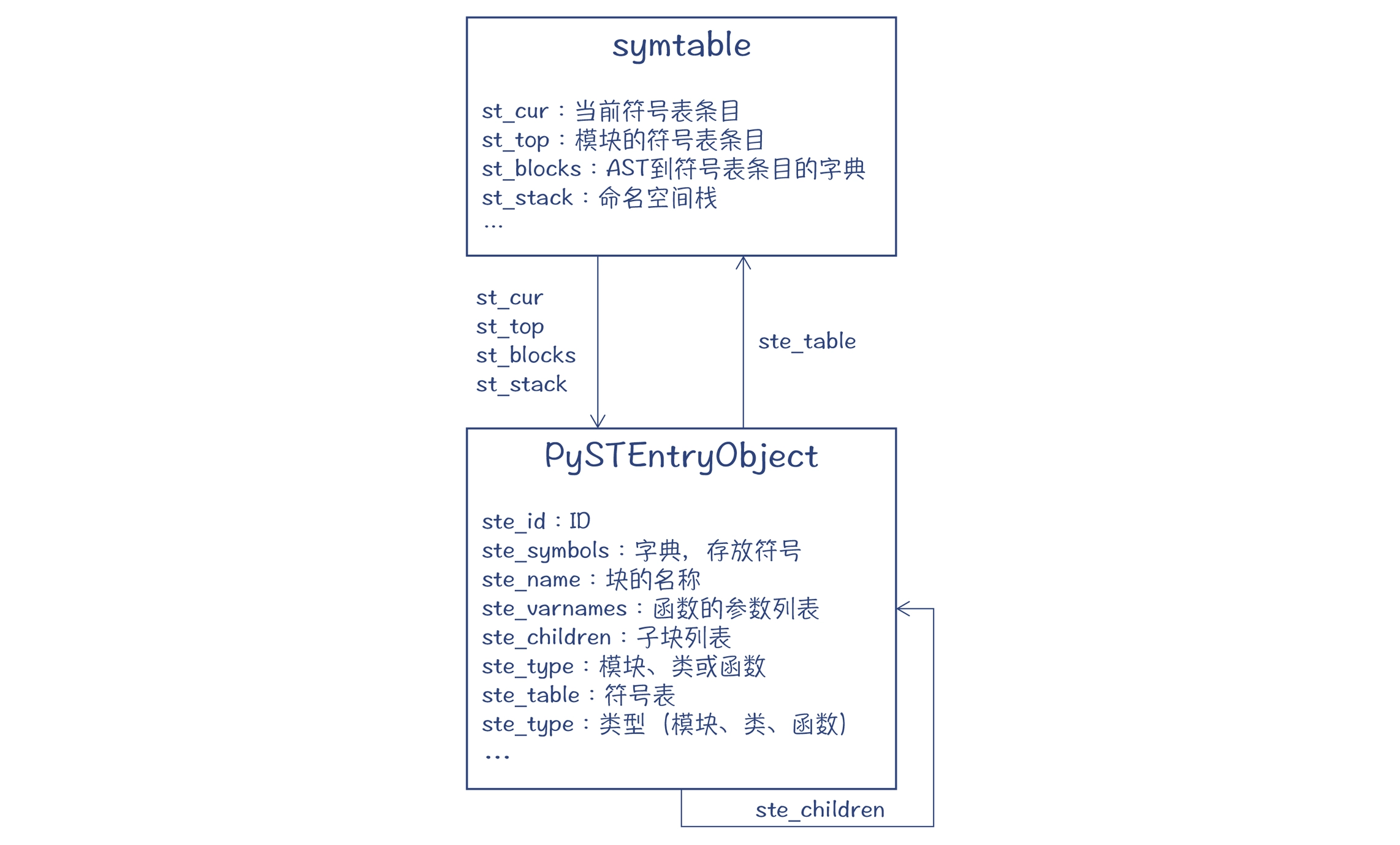
在编译过程中,针对每个模块(也就是一个python文件)会产生一个符号表(symtable)
Python程序被划分为"块(block)",块分为三种:模块,类和函数。每种块就是一种作用域,而在Python里面还叫命名空间。每个块对应一个符号表条目(PySTEntryObject),每个符号表条目里存有该块里的所有符号(ste_symbols)。 每个块还可以有多个子块(ste_children),形成树状结构
在符号表里,有一个 st_blocks 字段,这是个字典,它能通过模块、类和函数的 AST 节点,查找到 Python 程序的符号表条目,通过这种方式,就把 AST 和符号表关联在了一起。
示例:下面的程序 对应的符号表长什么样子
a = 2 #模块级变量
class myclass:
def __init__(self, x):
self.x = x
def foo(self, b):
c = a + self.x + b #引用了外部变量a
return c
这个示例程序有模块,类和函数三个级别的块,他们分别 对应一个符号表条目:
示例程序对应的符号表:
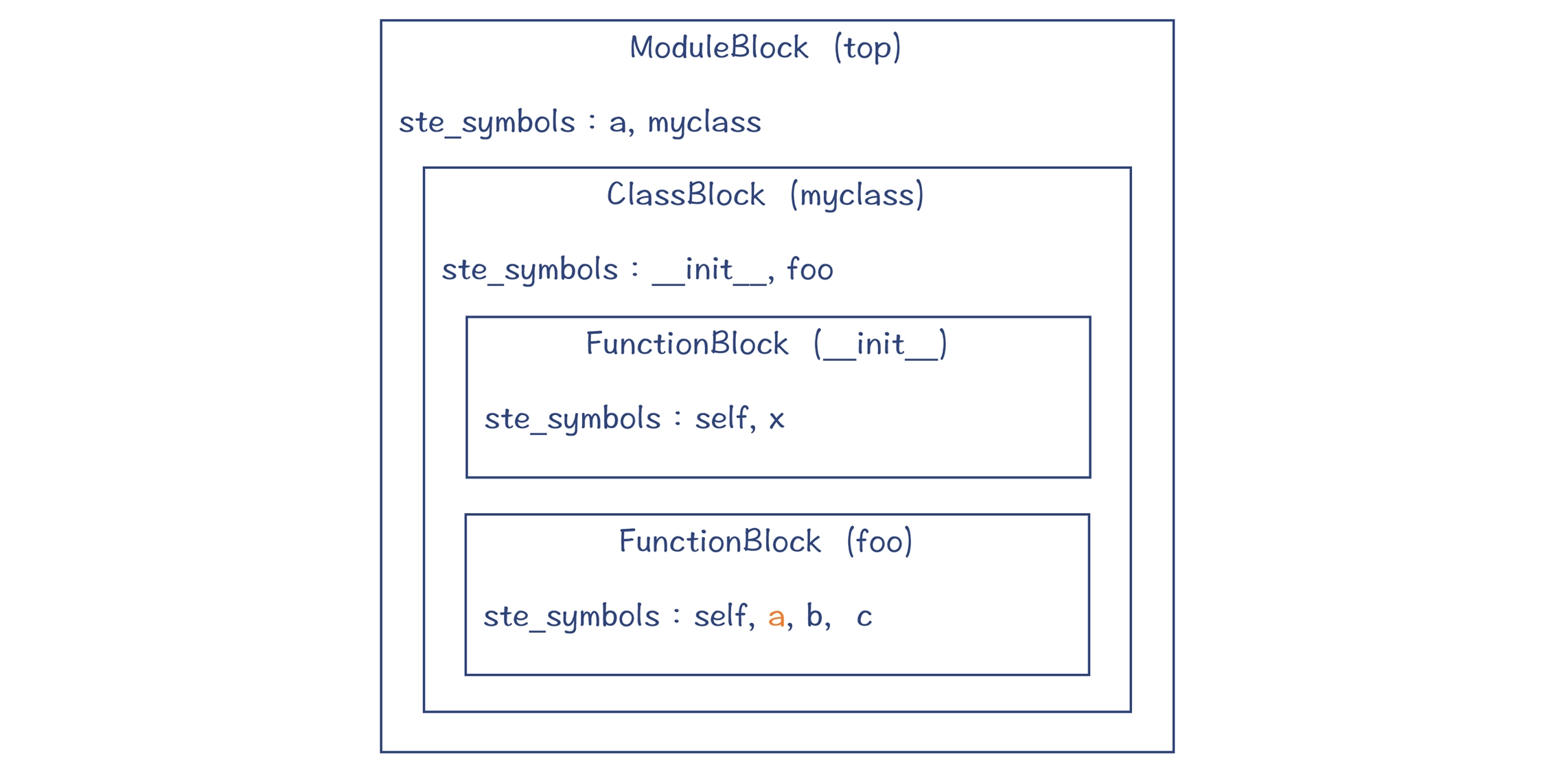
可看到,每个块中都有ste_sybol字段,它是一个字典,里面保存了本命名空间涉及的符号,以及每个符号的各种标志位(flags)
然后,针对这个示例程序,看看符号表的主要字段的取值:
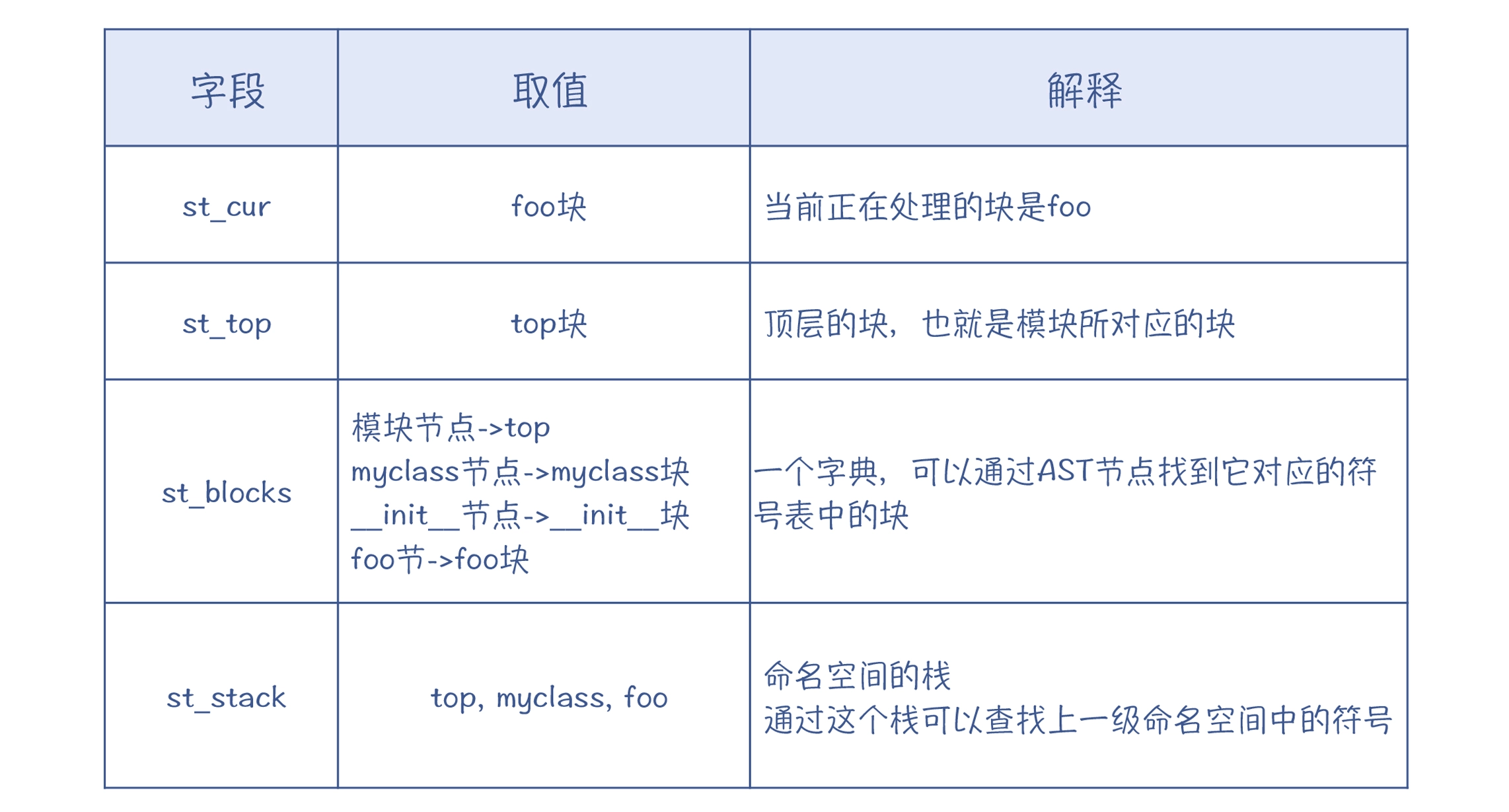
符号表的建立过程
建立符号表的主程序是Python/symtable.c中的 PySymtable_BuildObject() 函数。
Python建立符号表的过程,需要做两遍处理,如下图所示:
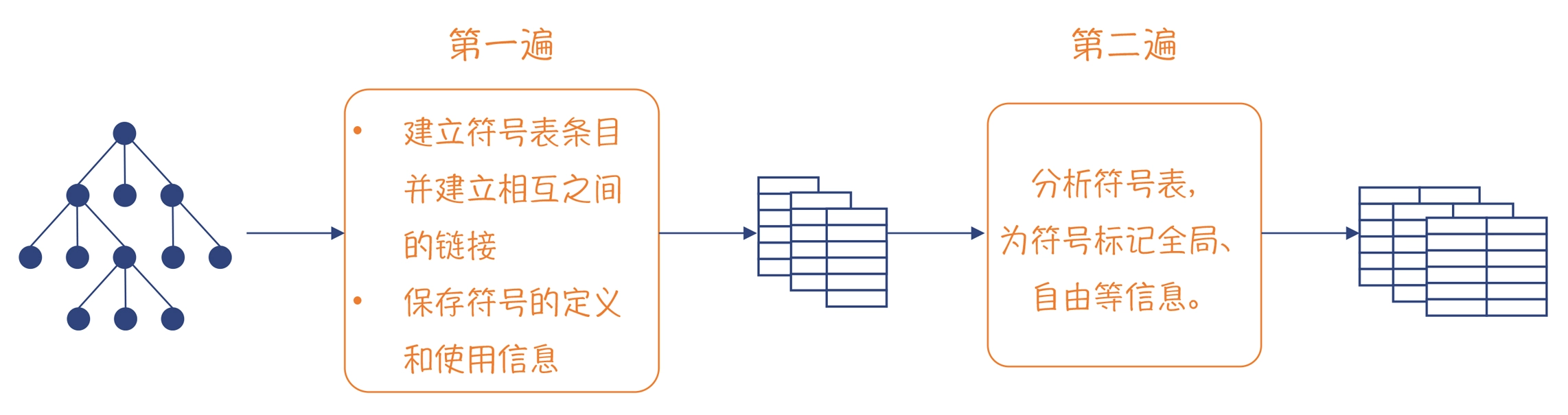
- 第一遍,主要做了两件事情。第一件事情是建立一个个的块(也就是符号表条目),并形成树状结构,就像示例程序那样;第二件事情,就是给块中的符号打上一定的标记(flag)。
用 GDB 跟踪一下第一遍处理后生成的结果
可以参考下图,看一下 Python 的 REPL 中的输入信息:

在 symtable_add_def_helper() 函数中设置了断点,便于调试。当编译器处理到 foo 函数的时候,我在 GDB 中打印输出了一些信息:
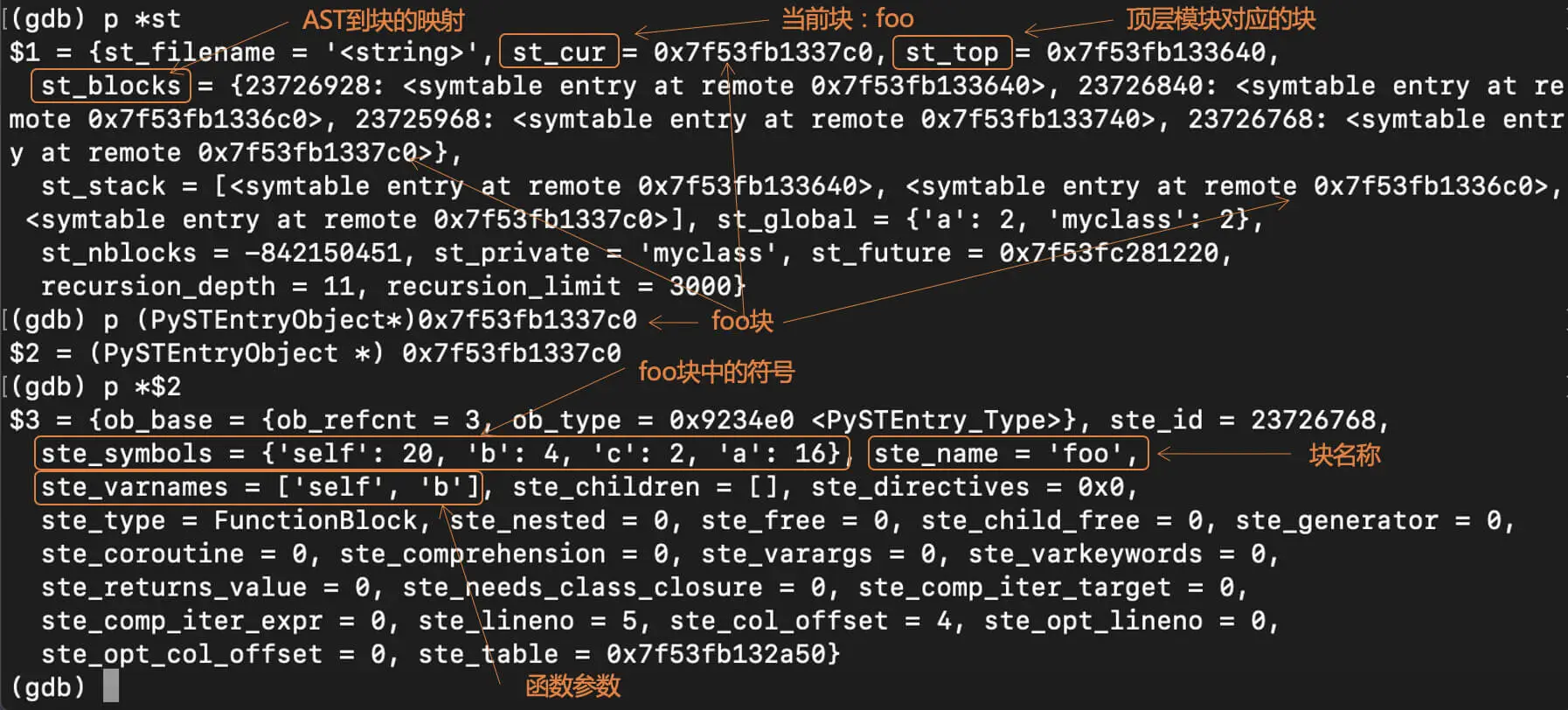
重点想让看的,是 foo 块中各个符号的标志信息:self 和 b 是 20,c 是 2,a 是 16。这是什么意思呢?
ste_symbols = {'self': 20, 'b': 20, 'c': 2, 'a': 16}
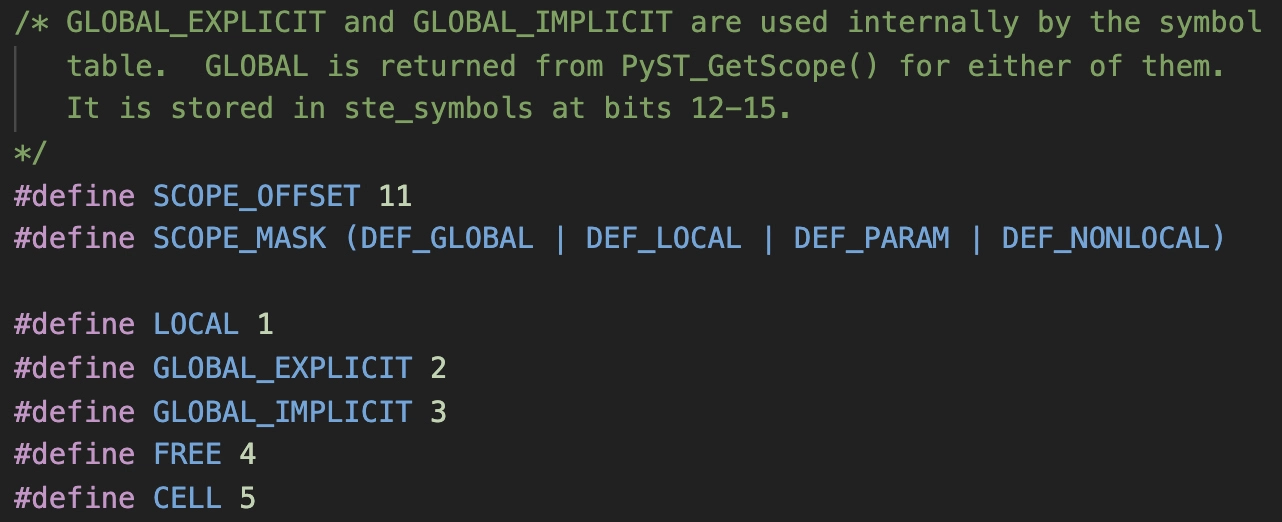
这就需要看一下 symtable.h 中,对这些标志位的定义:
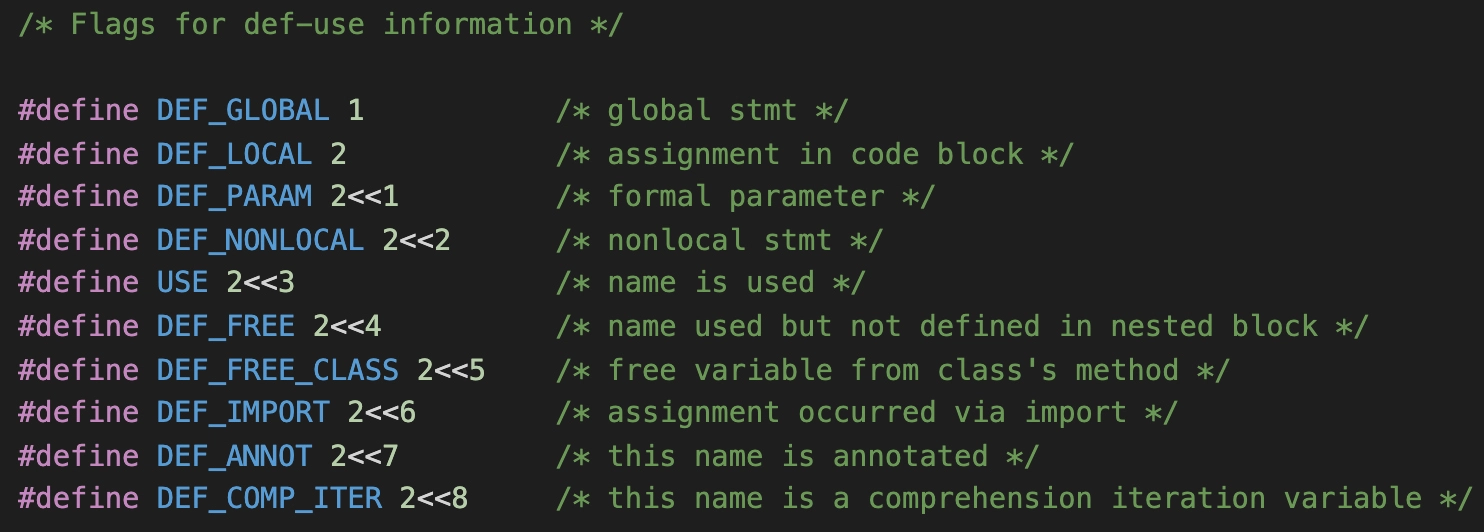
整理成了一张更容易理解的图,你参考一下:
符号标志信息中每个位的含义:
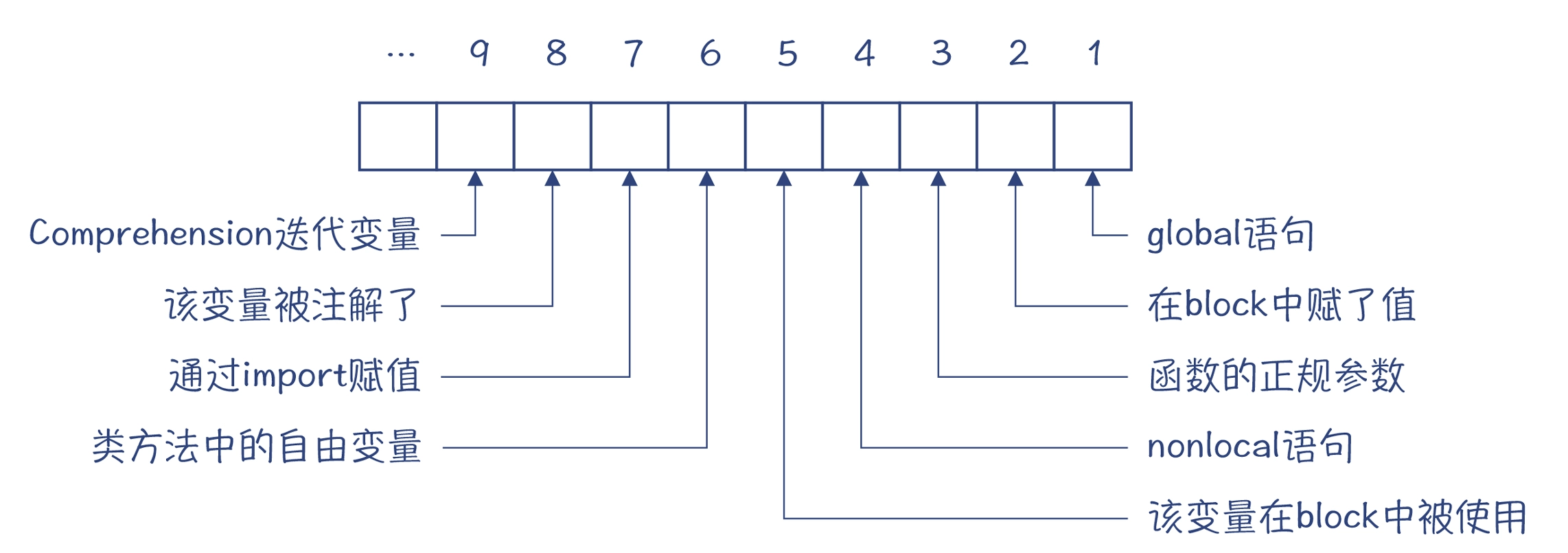
根据上述信息,你会发现 self 和 b,其实是被标记了 3 号位和 5 号位,意思是这两个变量是函数参数,并且在 foo 中被使用。而 a 只标记了 5 号位,意思是 a 这个变量在 foo 中被使用,但这个变量又不是参数,所以肯定是来自外部作用域的。我们再看看 c,c 只在 2 号位被标记,表示这个变量在 foo 里被赋值了。
通过第一遍处理,我们会知道哪些变量是本地声明的变量、哪些变量在本块中被使用、哪几个变量是函数参数等几方面的信息。
- 编译器会做第二遍的分析(见 symtable_analyze() 函数)。在这遍分析里,编译器会根据我们刚才说的 Python 关于变量引用的语义规则,分析出哪些是全局变量、哪些是自由变量,等等。这些信息也会被放到符号的标志位的第 12~15 位。
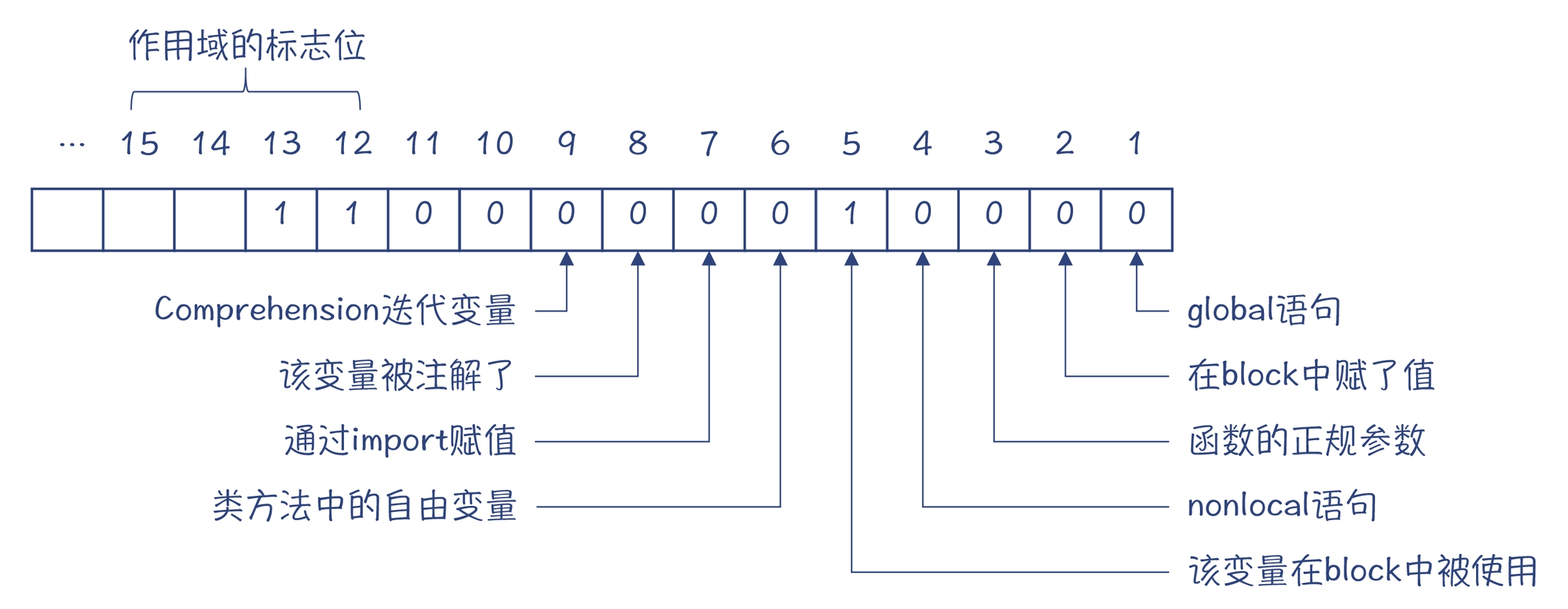
ste_symbols = {'self': 2068, 'b': 2068, 'c': 2050, 'a': 6160}
symtable.h中对作用域的标志位:
以变量 a 为例,它的标志值是 6160,也就是二进制的 1100000010000。其标记位设置如下,其作用域的标志位是 3,也就是说,a 是个隐式的全局变量。而 self、b 和 c 的作用域标志位都是 1,它们的意思是本地变量。
作用域的标志位:
在第二遍的分析过程中,Python 也做了一些语义检查。
可以搜索一下 Python/symtable.c 的代码,里面有很多地方会产生错误信息,比如“nonlocal declaration not allowed at module level(在模块级不允许非本地声明)”。
另外,Python 语言提供了访问符号表的 API,方便你直接在 REPL 中,来查看编译过程中生成的符号表。你可以参考我的屏幕截图:
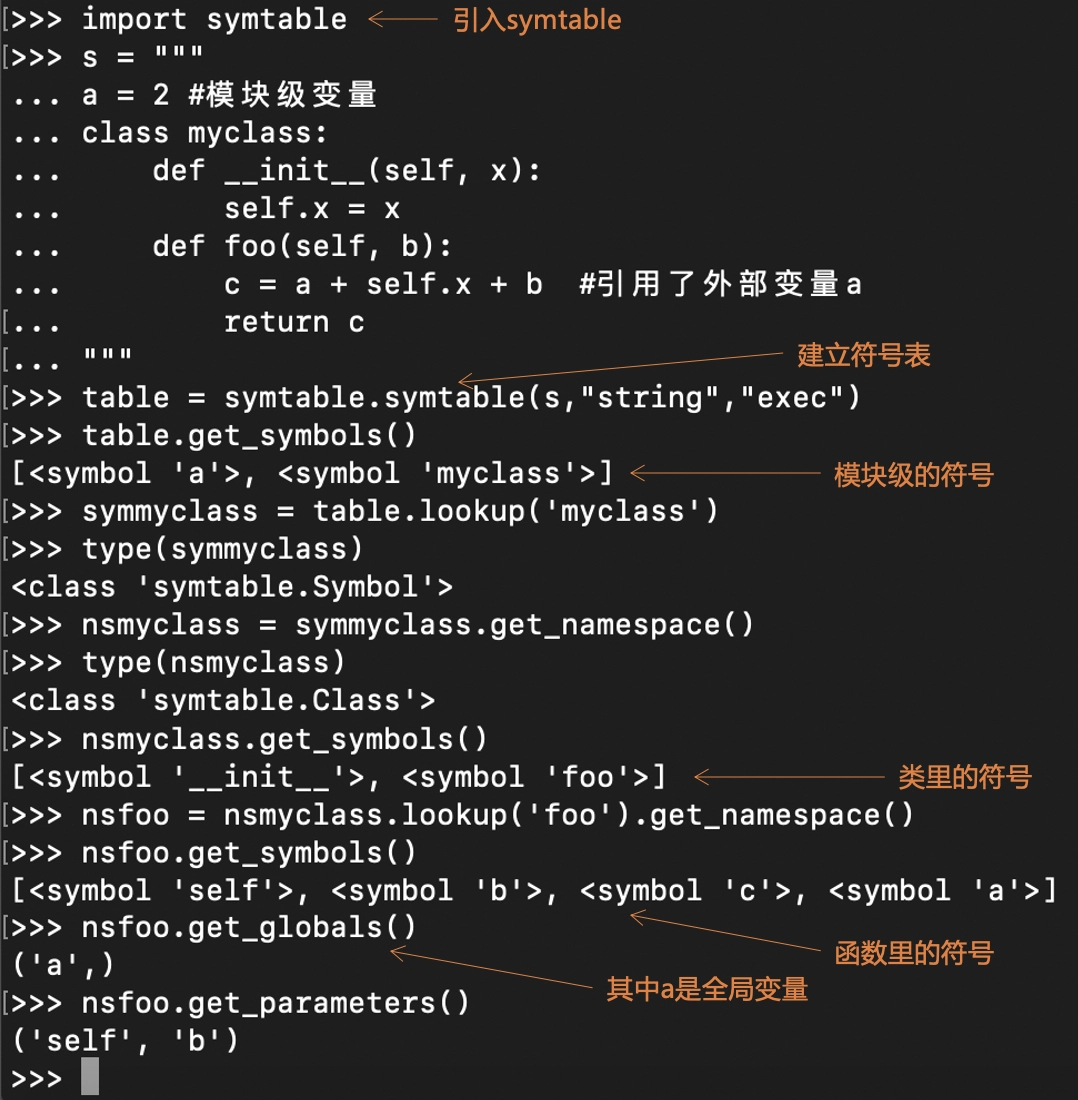
现在符号表已经生成了。基于 AST 和符号表,Python 编译器就可以生成字节码。
生成 CFG 和指令
可以用Python调用编译器的API,来 观察字节码生成的情况:
>>> co = compile("a+2", "test.py", "eval") //编译表达式"a+2"
>>> dis.dis(co.co_code) //反编译字节码
0 LOAD_NAME 0 (0) //装载变量a
2 LOAD_CONST 0 (0) //装载常数2
4 BINARY_ADD //执行加法
6 RETURN_VALUE //返回值
其中的 LOAD_NAME、LOAD_CONST、BINARY_ADD 和 RETURN_VALUE 都是字节码的指令。
Python 和 Java 的虚拟机一样,都是基于栈的虚拟机。所以,它们的指令也很相似。比如,加法操作的指令是不需要带操作数的,因为只需要取出栈顶的两个元素相加,把结果再放回栈顶就行了。
对比下python指令和Java指令的异同点:
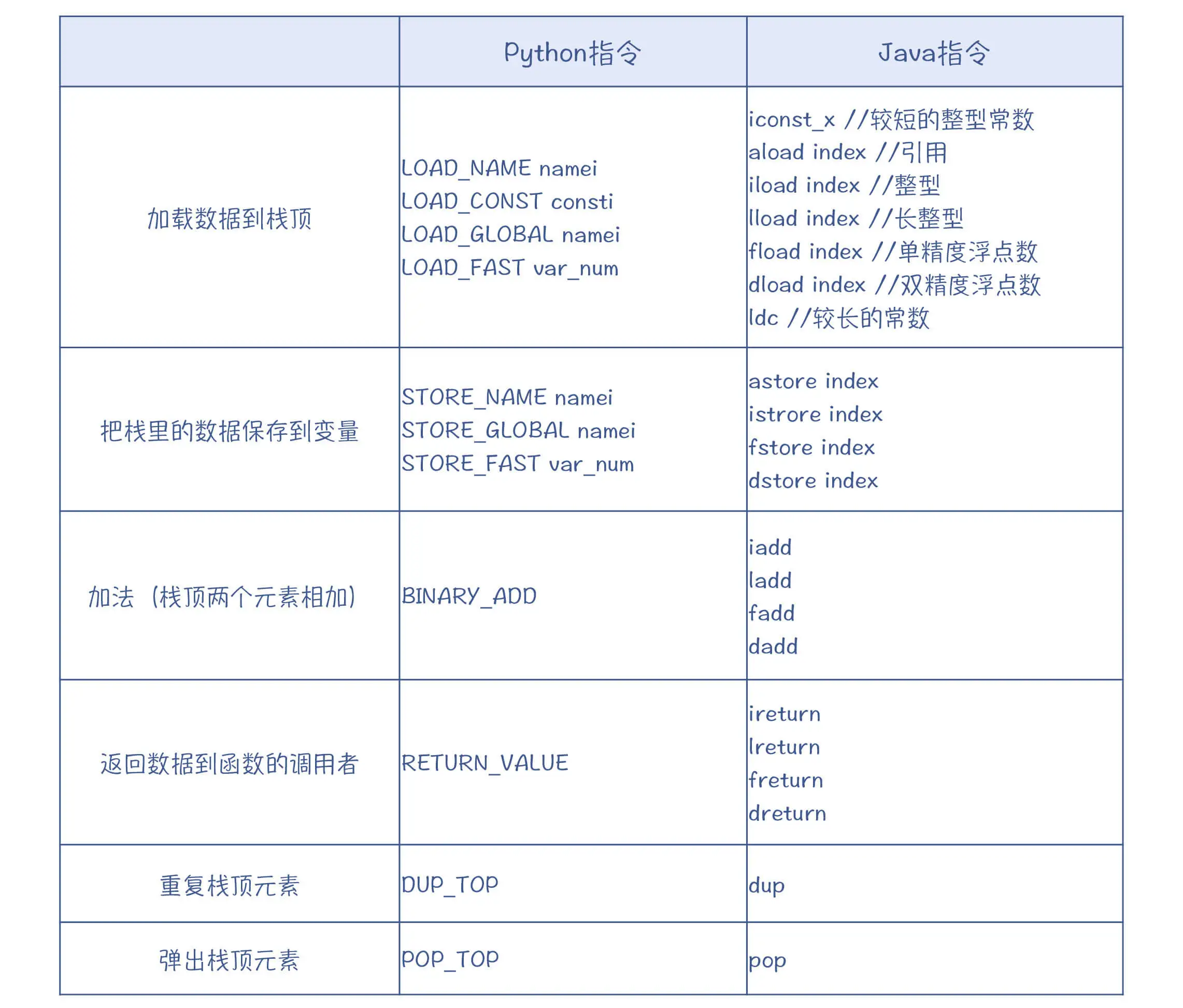
它们主要的区别就在于,Java 的字节码对不同的数据类型会提供不同的指令,而 Python 则不加区分。因为 Python 对所有的数值,都会提供统一的计算方式。
所以一门语言的 IR,是跟这门语言的设计密切相关的。
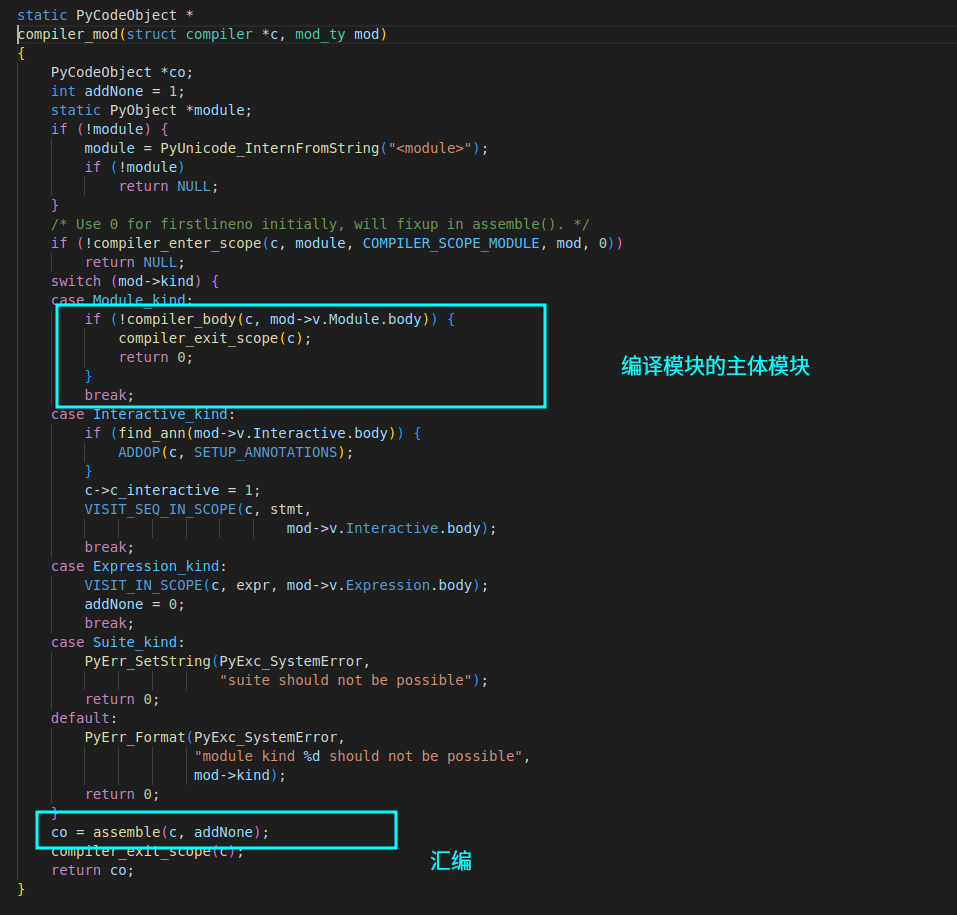
生成 CFG 和字节码的代码在 **Python/compile.c **中。调用顺序如下:
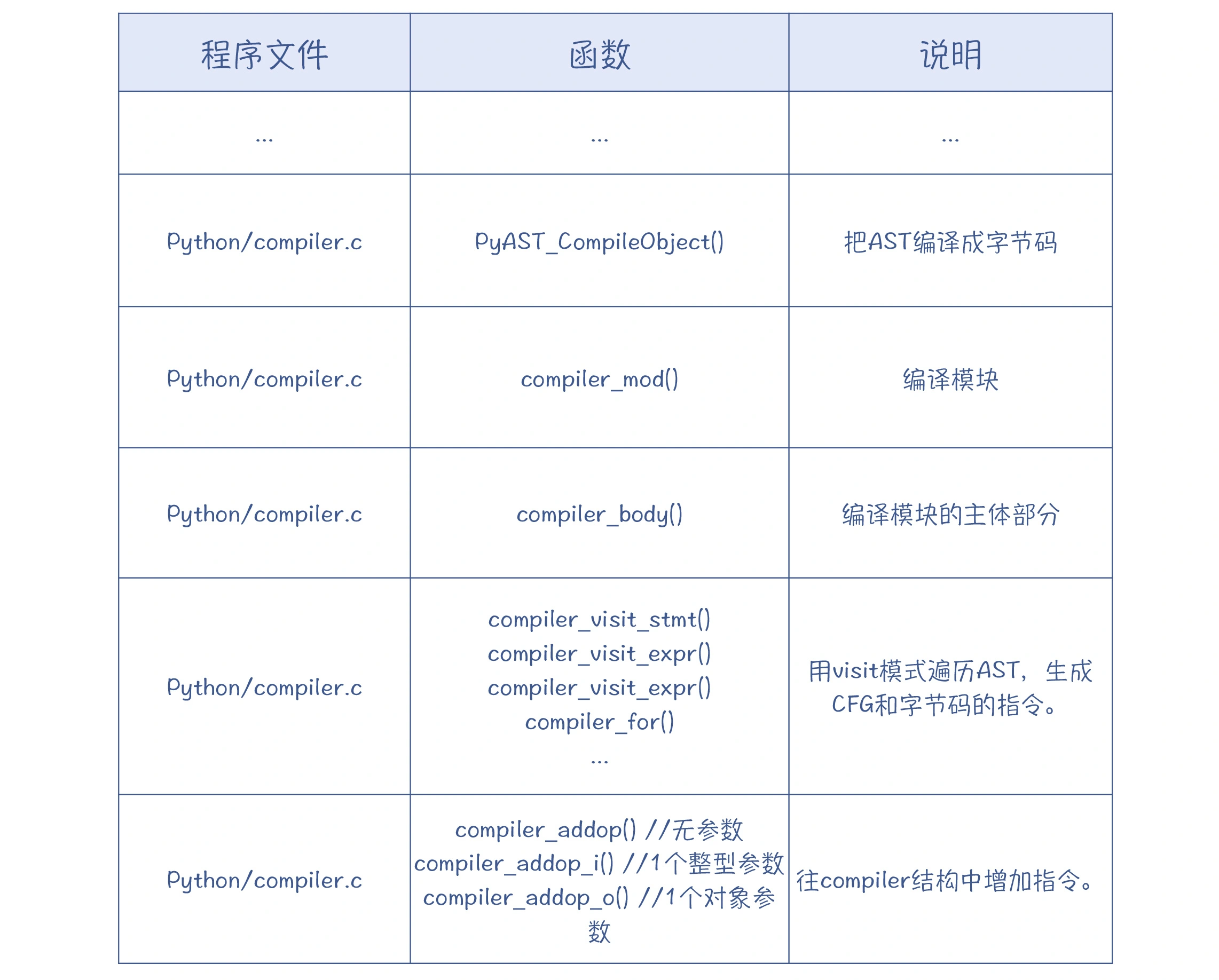
总的逻辑是:以 visit 模式遍历整个 AST,并建立基本块和指令。对于每种 AST 节点,都由相应的函数来处理。
以 compiler_visit_expr1() 为例,对于二元操作,编译器首先会递归地遍历左侧子树和右侧子树,然后根据结果添加字节码的指令。
compiler_visit_expr1(struct compiler *c, expr_ty e)
{
switch (e->kind) {
...
.
case BinOp_kind:
VISIT(c, expr, e->v.BinOp.left); //遍历左侧子树
VISIT(c, expr, e->v.BinOp.right); //遍历右侧子树
ADDOP(c, binop(c, e->v.BinOp.op)); //添加二元操作的指令
break;
...
}
那么基本块是如何生成的呢?
编译器在进入一个作用域的时候(比如函数),至少要生成一个基本块。而像循环语句、if 语句,还会产生额外的基本块。
所以,编译的结果,会在 compiler 结构中保存一系列的基本块,这些基本块相互连接,构成 CFG;基本块中又包含一个指令数组,每个指令又包含操作码、参数等信息。
基本块和指令:
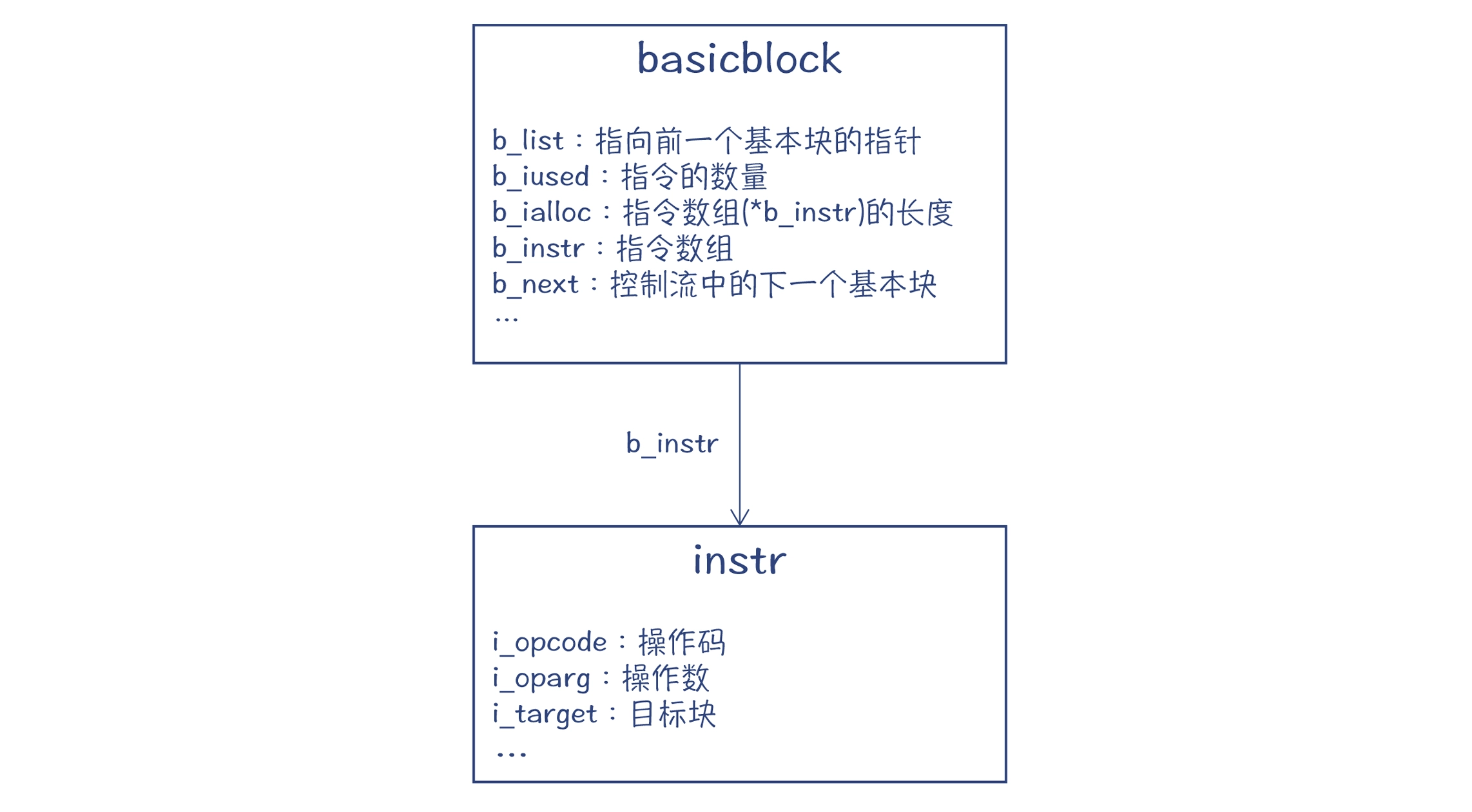
为了直观理解,我设计了一个简单的示例程序。foo 函数里面有一个 if 语句,这样会产生多个基本块。
def foo(a):
if a > 10 :
b = a
else:
b = 10
return b
通过 GDB 跟踪编译过程,我们发现,它生成的 CFG 如下图所示:
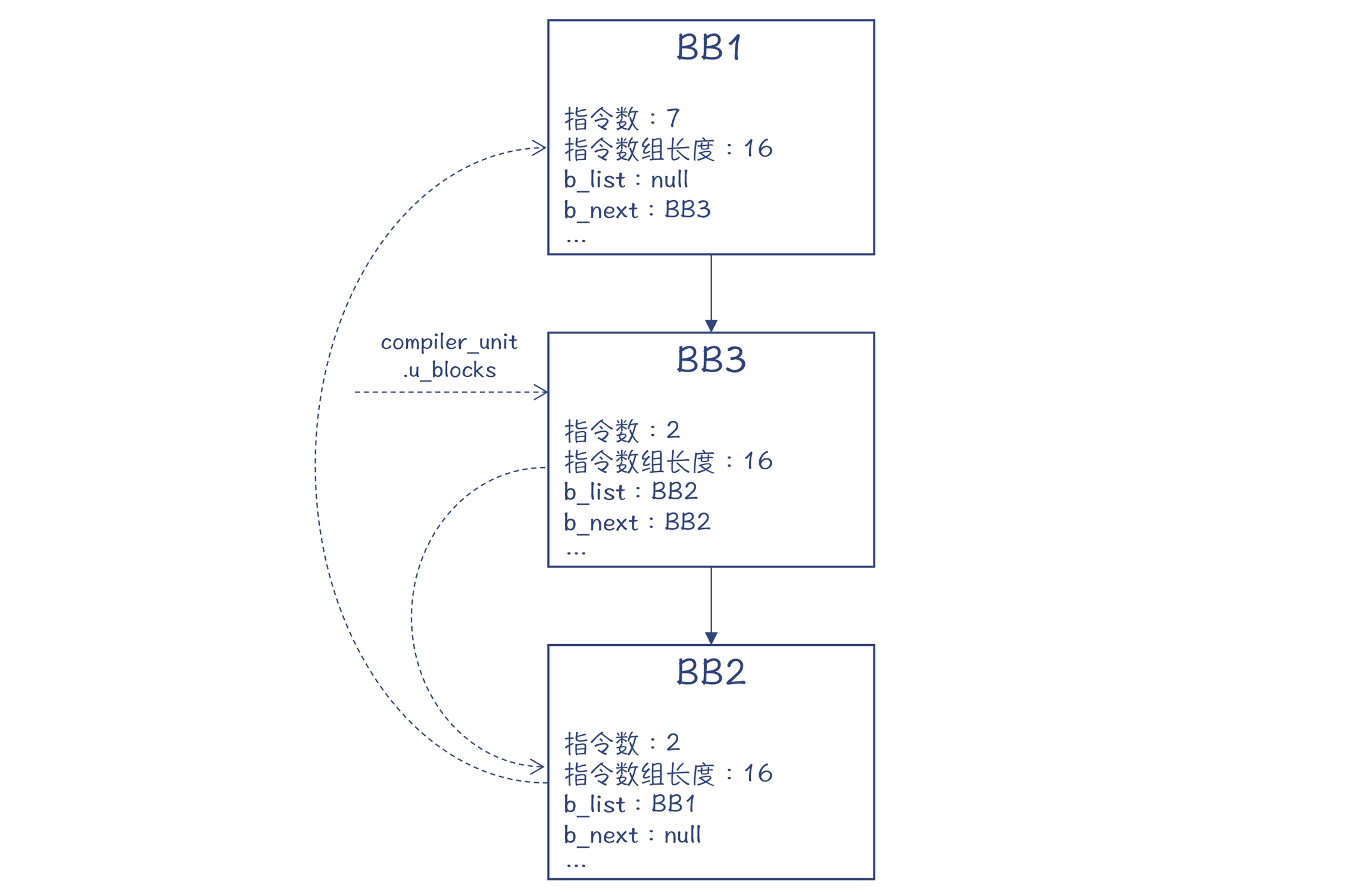
在 CFG 里,你要注意两组箭头
实线箭头是基本块之间的跳转关系,用 b_next 字段来标记。
虚线箭头能够基于 b_list 字段把所有的基本块串起来,形成一个链表,每一个新生成的基本块指向前一个基本块。只要有一个指针指向最后一个基本块,就能访问所有的基本块。
汇编(Assembly)
汇编过程是在 **Python/compiler.c ** 中的assemble() 函数中完成的。
Python 的汇编阶段,是生成字节码,它们都是生成目标代码。
具体来说,汇编阶段主要会完成以下任务:
- 把每个基本块的指令对象转化成字节码。
- 把所有基本块的字节码拼成一个整体。
- 对于从一个基本块跳转到另一个基本块的 jump 指令,它们有些采用的是相对定位方式,比如往前跳几个字的距离。这个时候,编译器要计算出正确的偏移值。
- 生成 PyCodeObject 对象,这个对象里保存着最后生成的字节码和其他辅助信息,用于 Python 的解释器执行。
通过示例程序,来直观地看一下汇编阶段的工作成果。你可以参照下图,使用 instaviz 工具看一下 foo 函数的编译结果。

在 PyCodeObject 对象中,co_code 字段是生成的字节码(用 16 进制显示)。你还能看到常量表和变量表,这些都是在解释器中运行所需要的信息。
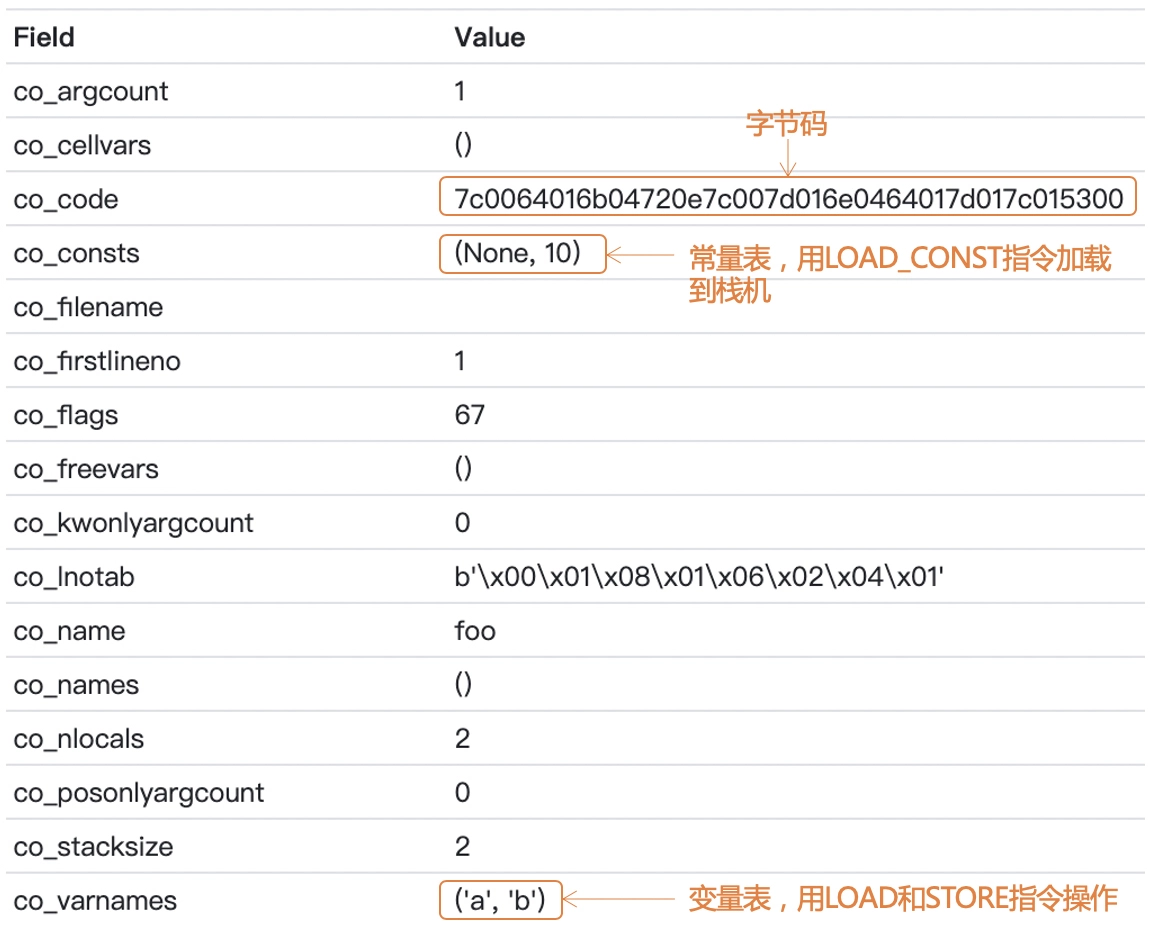
如果把 co_code 字段的那一串字节码反编译一下,你会得到下面的信息:
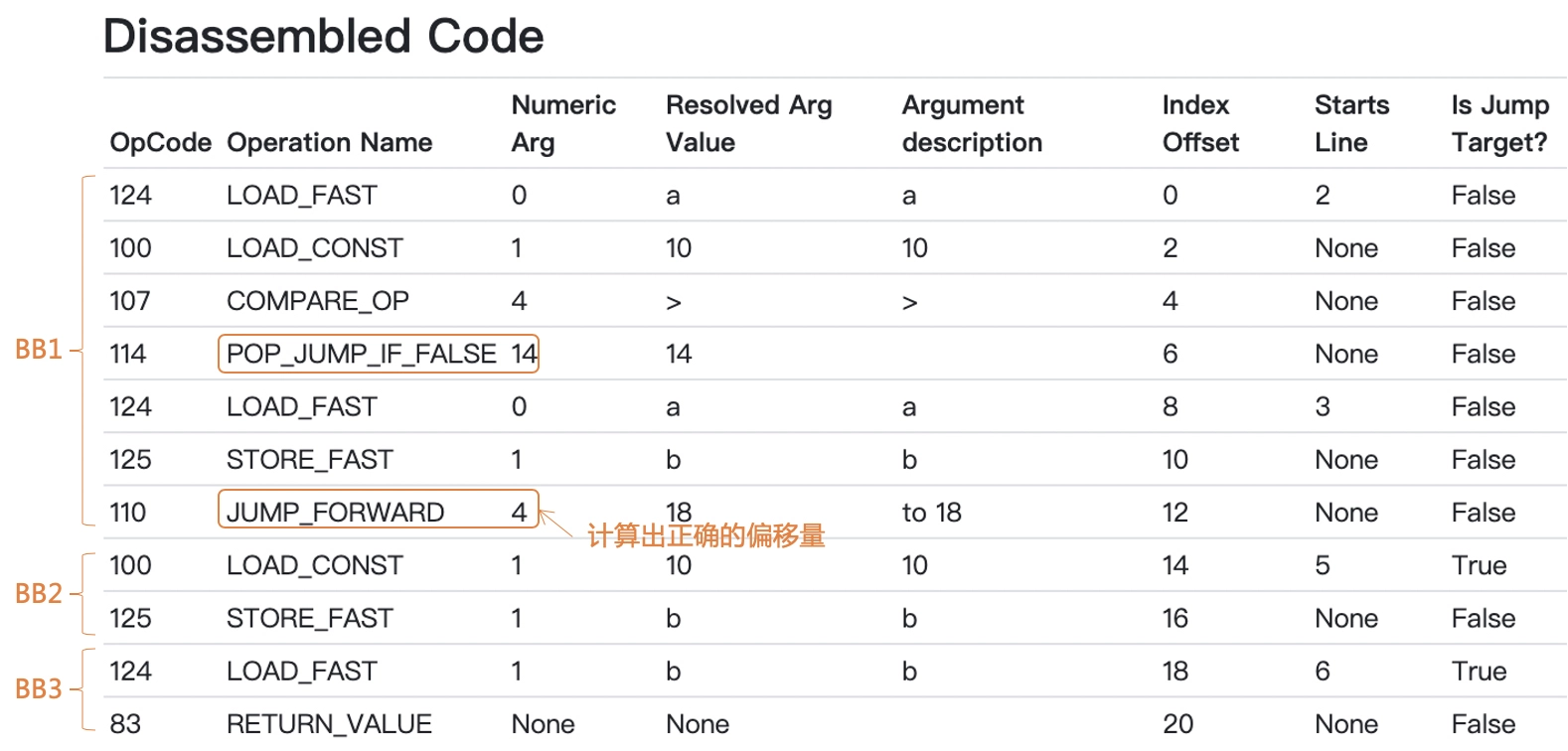
一共 11 条指令,其中 BB1 是 7 条,BB2 和 BB3 各 2 条。BB1 里面是 If 条件和 if 块中的内容,BB2 对应的是 else 块的内容,BB3 则对应 return 语句。
窥孔优化
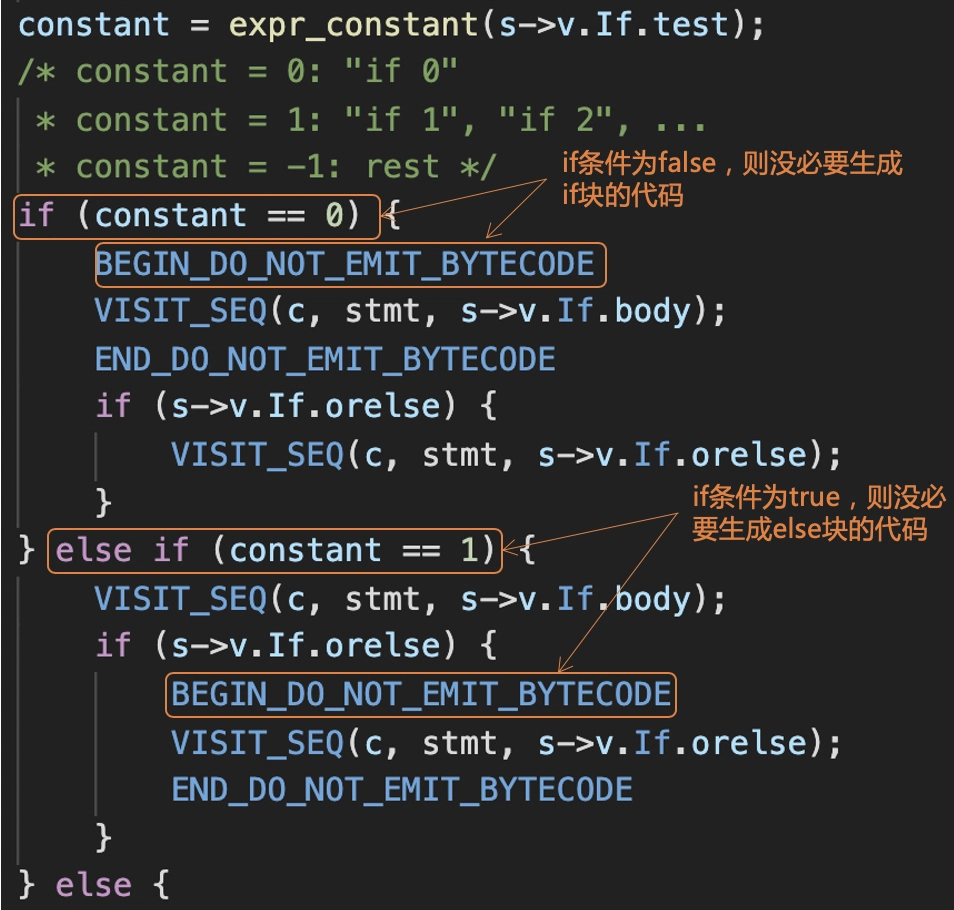
总体来说,在编译的过程中,Python 编译器的优化功能是很有限的。在 compiler.c 的代码中,你会看到一点优化逻辑。比如,在为 if 语句生成指令的时候,编译器就会看看 if 条件是否是个常数,从而不必生成 if 块或者 else 块的代码。
另一个优化机会,就是在字节码的基础上优化,这就是窥孔优化,其实现是在 Python/peephole.c 中。它能完成的优化包括:
- 多个 LOAD_CONST 指令替换为一条加载常数元组的指令。
- 如果一个跳转指令,跳到 return 指令,那么可以把跳转指令直接替换成 return 指令。
- 如果一个条件跳转指令,跳到另一个条件跳转指令,则可以基于逻辑运算的规则做优化。比如,“x:JUMP_IF_FALSE_OR_POP y”和“y:JUMP_IF_FALSE_OR_POP z”可以直接简化为“x:JUMP_IF_FALSE_OR_POP z”。这是什么意思呢?第一句是依据栈顶的值做判断,如果为 false 就跳转到 y。而第二句,继续依据栈顶的值做判断,如果为 false 就跳转到 z。那么,简化后,可以直接从第一句跳转到 z。
- 去掉 return 指令后面的代码。
- ......
在做优化的时候,窥孔优化器会去掉原来的指令,替换成新的指令。如果有多余出来的位置,则会先填充 NOP 指令,也就是不做任何操作。最后,才扫描一遍整个字节码,把 NOP 指令去掉,并且调整受影响的 jump 指令的参数。
小结
Python 通过一个建立符号表的过程来做相关的语义分析,包括做引用消解和其他语义检查。由于 Python 可以不声明变量就直接使用,所以编译器要能识别出正确的“定义 - 使用”关系。
生成字节码的工作实际上包含了生成 CFG、为每个基本块生成指令,以及把指令汇编成字节码,并生成 PyCodeObject 对象的过程。
窥孔优化器在字节码的基础上做了一些优化,研究这个程序,会让你对窥孔优化的认识变得具象起来。
编译原理:python编译器--从AST到字节码的更多相关文章
- [Vue源码]一起来学Vue模板编译原理(一)-Template生成AST
本文我们一起通过学习Vue模板编译原理(一)-Template生成AST来分析Vue源码.预计接下来会围绕Vue源码来整理一些文章,如下. 一起来学Vue双向绑定原理-数据劫持和发布订阅 一起来学Vu ...
- [Vue源码]一起来学Vue模板编译原理(二)-AST生成Render字符串
本文我们一起通过学习Vue模板编译原理(二)-AST生成Render字符串来分析Vue源码.预计接下来会围绕Vue源码来整理一些文章,如下. 一起来学Vue双向绑定原理-数据劫持和发布订阅 一起来学V ...
- Compiler Theory(编译原理)、词法/语法/AST/中间代码优化在Webshell检测上的应用
catalog . 引论 . 构建一个编译器的相关科学 . 程序设计语言基础 . 一个简单的语法制导翻译器 . 简单表达式的翻译器(源代码示例) . 词法分析 . 生成中间代码 . 词法分析器的实现 ...
- 浅谈C++编译原理 ------ C++编译器与链接器工作原理
原文:https://blog.csdn.net/zyh821351004/article/details/46425823 第一篇: 首先是预编译,这一步可以粗略的认为只做了一件事情,那就 ...
- 必要的软件架构师——编译原理·语法
最近软测试.我观看进程的视频! 发现里面有很多内容已经在自我不错的接触过程.而占80%比例! 但其中的一部分.我很奇怪的一部分.研究,在这里,将我研究的内容整理分享给大家! 编译原理: 首先,我第一眼 ...
- 学了编译原理能否用 Java 写一个编译器或解释器?
16 个回答 默认排序 RednaxelaFX JavaScript.编译原理.编程 等 7 个话题的优秀回答者 282 人赞同了该回答 能.我一开始学编译原理的时候就是用Java写了好多小编译器和 ...
- Knowledge Point 20180303 对比编译器、解释器与Javac编译原理
编译器与Javac编译原理 在前文我们知道了Java是一种编译语言和解释语言,它的源代码经过编译器Javac编译为能够被JVM识别的二进制语言,然后JVM将其解释为能够被平台识别的机器语言.那么什么是 ...
- gcc/g++等编译器 编译原理: 预处理,编译,汇编,链接各步骤详解
摘自http://blog.csdn.net/elfprincexu/article/details/45043971 gcc/g++等编译器 编译原理: 预处理,编译,汇编,链接各步骤详解 C和C+ ...
- python实现算术表达式的词法语法语义分析(编译原理应用)
本学期编译原理的一个大作业,我的选题是算术表达式的词法语法语义分析,当时由于学得比较渣,只用了递归下降的方法进行了分析. 首先,用户输入算术表达式,其中算术表达式可以包含基本运算符,括号,数字,以及用 ...
- php中foreach源码分析(编译原理)
php中foreach源码分析(编译原理) 一.总结 编译原理(lex and yacc)的知识 二.php中foreach源码分析 foreach是PHP中很常用的一个用作数组循环的控制语句.因为它 ...
随机推荐
- 用 solon-ai 写个简单的 deepseek 程序(构建全国产 ai 智能体应用)
用国产应用开发框架(及生态),对接国产 ai.构建全国产 ai 智能体应用. 1.先要申请个 apiKey 打开 https://www.deepseek.com 官网,申请个 apiKey .(一万 ...
- Manus爆火,是硬核还是营销?
相信这两天小伙伴们应该被Manus刷屏了,铺天盖地的体验解读文章接踵而来,比如「数字生命卡兹克」凌晨爆肝的热文:「一手体验首款通用Agent产品Manus」.从公众号.朋友圈.抖音.央媒,都能看到Ma ...
- Ubuntu22.04双网卡调试
最近捡起正点原子的linux开发板,又开始了linux的学习,这条路走走停停的,隔了一年时间很多积累的东西都忘了.打开VMware虚拟机发现网络也连接不上了,我的印象中去年是把虚拟机的双网卡配置好了, ...
- Vulnhub-venom
对于该靶机,注意利用了信息收集来的21端口和80端口,网站源码发现账户,ftp匿名登录密码猜测,维吉尼亚解密,后台管理员登录,CVE文件上传RCE漏洞利用反弹shell,提权有两中,利用版本内核提权和 ...
- 解决 Mac(M1/M2)芯片,使用node 14版本
前言 nvm 在安装 Node.js v14.21.3 时,报错: nvm install 14 Downloading and installing node v14.21.3... Downloa ...
- gorm stdErr = sql: Scan error on column index 0, name "total": converting NULL to float64 is unsupported
前言 使用 gorm 查询时,报错:stdErr = sql: Scan error on column index 0, name "total": converting NUL ...
- mongodb查询某个字段数据
如下 db.集合名.find( {}, {需要查询的字段:1, _id:0} ) 例如 db.userInfo.find({}, {'created_at':1, _id: 0}) 默认会显示 _id ...
- 深入理解CPU的调度原理
前言 软件工程师们总习惯把OS(Operating System,操作系统)当成是一个非常值得信赖的管家,我们只管把程序托管到OS上运行,却很少深入了解操作系统的运行原理.确实,OS作为一个通用的软件 ...
- pandas数据统一绘图风格配置
在使用pandas的时候,经常会用到Dataframe或者Series的plot方法,该方法底层实际上调的还是matplotlib.pyplot的plot方法.因此,通过对pyplot模块的绘图全局参 ...
- ARM开发板——实时获取用户点击触摸屏的LCD坐标信息(阻塞式读取)
ARM开发板--实时获取用户点击触摸屏的LCD坐标信息(阻塞式读取) 目录 ARM开发板--实时获取用户点击触摸屏的LCD坐标信息(阻塞式读取) 1.硬件信息 2.代码需求 3.代码实现 1.硬件信息 ...