读论文-基于序列模式的电子商务推荐系统综述(A Survey of Sequential Pattern Based E-Commerce Recommendation Systems)
前言
今天读的论文为一篇于2023年10月3日发表在《算法》(Algorithms)的论文,这篇文章综述了基于序列模式的电子商务推荐系统,强调了通过整合用户购买和点击行为的序列模式来提高推荐准确性、减少数据稀疏性、增加推荐新颖性,并改善推荐系统的可扩展性。文章详细分析了现有推荐系统的方法、性能和潜在问题,并提出了未来研究的方向,包括更精确地评估序列模式的购买概率、整合点击流数据以及开发跨域推荐系统。
Algorithms 是一本开放获取的国际期刊,专注于算法领域的研究。它由MDPI出版,这是一个总部位于瑞士巴塞尔的开放获取出版商。该期刊涵盖了算法设计、分析、实现和应用的各个方面,包括但不限于计算理论、数据结构、优化算法、机器学习算法、生物信息学算法、图像处理算法、网络算法等。
Algorithms鼓励研究人员提交高质量的原创研究论文、综述文章以及对现有算法的改进。它的目标是为算法研究者提供一个分享最新研究成果、促进学术交流的平台。由于是开放获取期刊,它允许读者免费在线阅读和下载文章,从而提高了研究成果的可见性和影响力。
要引用这篇论文,请使用以下格式:
[1]Ezeife, Christie I., and Hemni Karlapalepu. "A Survey of Sequential Pattern Based E-Commerce Recommendation Systems." Algorithms 16.10 (2023): 467.
摘要
电子商务推荐系统通常处理大量的客户序列数据库,例如历史购买或点击流序列。如果能够通过将客户点击和/或购买的序列模式整合到协同过滤的用户-项目评分矩阵输入中,可以提高推荐系统的准确性。本综述专注于现有的基于序列模式的电子商务推荐系统算法,提供了这些系统的全面和比较性能分析,揭示了它们的方法论、成就、局限性以及解决该领域更重要问题的潜力。综述表明,将历史购买和/或点击序列的序列模式挖掘整合到用户-项目矩阵中,可以(i)提高推荐准确性,(ii)减少用户-项目评分数据的稀疏性,(iii)增加推荐的新性率,以及(iv)提高推荐系统的可扩展性。
要点总结:
- 电子商务推荐系统处理大量客户序列数据,如历史购买和点击流序列。
- 通过整合用户行为的序列模式到推荐系统中,可以提升推荐质量。
- 本文综述了基于序列模式的推荐系统算法,并进行了性能比较分析。
- 整合序列模式可以改善推荐准确性、数据稀疏性、推荐新性率和系统可扩展性。
- 综述揭示了现有方法的优缺点,并探讨了解决领域内重要问题的潜力。
本文综述了基于序列模式的电子商务推荐系统,强调了将用户购买和点击行为的序列模式整合到推荐系统中的重要性,这不仅提高了推荐准确性,还减少了数据稀疏性,增加了推荐内容的新颖性,并提升了系统的可扩展性。同时,文章对现有算法进行了深入分析,展示了它们的方法论、成就和局限性,并探讨了如何通过这些算法解决电子商务推荐领域的关键问题。
引言
推荐系统已经成为互联网基础公司的核心,例如Google、YouTube、Facebook、Netflix、LinkedIn和Amazon。推荐系统为用户提供可能对他们有用的项目建议。这些建议旨在支持用户在各种决策过程中,比如购买什么商品、听什么音乐或阅读什么新闻。模式挖掘包括通过关联规则挖掘、频繁模式挖掘和序列模式挖掘等任务,在数据库中发现有趣、有用和意外的模式。这些数据挖掘任务通常被推荐系统用来生成历史用户购买数据的有意义表示和学习。本文专注于挖掘客户购买历史的序列模式,以便在电子商务应用领域进行推荐。不同类型的推荐系统接受不同的输入数据,包括通过显式评分反馈(例如,表1)和隐式派生反馈。显式反馈可以是收集用户通过注册表单/明确询问兴趣和偏好对产品的评分或文本评论的形式,用户从特定的评估系统(例如,五星评分系统)中选择数字值来指定他们对不同项目的喜好和厌恶。隐式反馈包括购买历史、浏览历史、搜索模式、用户在特定页面上花费的时间、用户跟随的链接、按钮点击以及来自社交网络平台的用户数据。例如,用户购买或浏览商品的简单行为可以被视为对该商品的认可。这种形式的反馈通常被像Amazon.com这样的在线商家使用。一个电影推荐网站的数据实例(表1)是显式反馈信息的一个例子。表1中的每个单元格都是用户对电影的评分值(偏好),用问号“?”标记的偏好是需要预测的缺失或未知值。
表1. 用户的点击和购买行为数据示例。

考虑用户的点击和购买行为数据,如表2所示;这个电影网站用户的点击和购买行为示例表明,客户最终从点击项目列表中购买了少数商品。
表2. 电影网站用户-项目评分矩阵示例。

表3. 隐式用户-项目购买矩阵。

序列模式挖掘(SPM)在序列数据库中发现有趣的子序列作为模式(序列模式),这些模式可以稍后被最终用户或管理层用来在他们的数据中找到不同项目或事件之间的关联,以便进行营销活动、业务重组、预测和规划等电子商务领域的工作。序列数据库存储了一系列记录,其中所有记录都是按时间顺序排列的序列{s1, s2, ..., sn}。序列数据库可以表示为元组<SID, sequence–item sets>,其中SID代表序列标识符,sequence–item sets指定了在括号()中按时间顺序(例如每天、每周、每月)购买的物品集。一个零售客户交易或杂货店的购买序列的示例序列数据库,显示了每个客户一个月内每周购买的商店物品的集合。
表4. 历史购买数据。

可以从这样的历史购买数据中构建序列数据库,考虑一段时间(天、周、月)。在这种情况下,从历史购买数据(表4)构建的购买序列数据库在表5中呈现,其中SID(01)包含序列<(面包,牛奶), (面包,牛奶,糖), (牛奶), (茶,糖)>。这意味着客户(01)首先购买了面包和牛奶,然后在第二次购买中购买了面包、牛奶和糖,第三次购买了牛奶,最后在最后一次购买中购买了茶和糖。
表5. 从历史购买数据构建的序列数据库。

序列模式是随时间发生的项目(事件)的有序集合。序列模式用尖括号< >表示,每个itemset包含一组项目,其中每个itemset用括号()分隔的逗号表示在同一市场访问中同时购买的一组项目。例如,从表5中,<(面包), (糖,茶)>是一个频繁序列模式,如果在这个数据库中使用最小支持度75%来挖掘频繁序列模式,那么这个模式就出现了。这意味着大多数客户会在一次访问中首先购买面包,然后在随后的购买中一起购买糖和茶。序列模式在数据库表中的支持度定义为模式出现的记录数除以数据库中总记录数。在HSPRec系统中使用的Sequential Historical Database (SHOD)算法用于从历史购买数据库(类似于表4)生成序列数据库。SPM问题现在可以正式描述如下。对于
(i) 一组序列记录(称为序列),代表序列数据库SDB = {s1, s2, ..., sn},序列标识符为1, 2, 3, ..., n,
(ii) 一个最小支持阈值,称为min sup ξ,
(iii) 一组k个独特的候选项或事件I = {i1, i2, ..., ik},
SPM算法发现在给定序列数据库SDB中的物品I的所有频繁子序列S,其支持度(序列在数据库记录中出现的百分比)大于或等于最小支持(min sup ξ)[7]。电子商务推荐系统基于协同过滤方法的输入通常是二进制用户-项目评分矩阵(表6),仅显示用户之前是否购买或喜欢过一个项目。因此,用户-项目评分矩阵可能非常稀疏,且输入数据质量低,即不反映(1)用户购买项目时的喜好程度,(2)用户购买项目的时间间隔,或(3)购买的产品数量。改进输入数据的一种方法是将显式评分与从历史购买或点击流数据中提取的隐式评分相结合,或者使用学习算法,如历史购买和点击流数据的序列模式挖掘(SPM),以提取更具信息性的客户购买和点击流数据行为。这可以整合到用户-项目评分矩阵中,有助于减少数据稀疏性,提高推荐质量和准确性。SPM可以捕获客户随时间的购买行为,使用挖掘的序列模式;这是至关重要的,因为项目之间的时间间隔对于学习用户可能在何时购买下一个项目是有用的。用户的下一个购买决策通常受到他们最近行为的影响,这种方法考虑了用户的时间偏好,将购买项目作为一系列购买。从相关的电子商务购买历史序列数据库中挖掘的一个频繁序列模式(FSP)的例子是<(牛奶,面包), (牛奶,奶油)>。这表明,通常从历史购买数据库中学到的是,当客户在一周内一起购买牛奶和面包时,他们会在接下来的一周回来一起购买牛奶和奶油。
表6. 电子商务用户-项目评分矩阵。
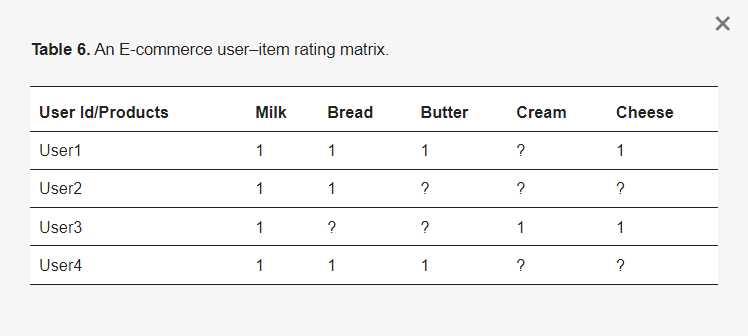
这个序列规则可以写成(milk, bread) → (milk, cream)。有了这样的序列规则,表6中的输入用户-项目评分矩阵中的许多未知评分可以被填充,使得所有购买前件项目(牛奶,面包)的用户有更高的概率(比如说0.5或更具体的确定概率值)在下一次购买奶油。通过这种方式,用户1、2和4对奶油的评分可以从未知更改为0.5。这样,序列模式可以用来通过为缺失/未评分的项目提供可能的值来提高评分值的数量。然后可以构建一个用户-项目购买频率矩阵,其中每个值代表用户购买的产品数量。这个购买频率然后被标准化到一个缩放值(0到1),代表用户对一个项目的兴趣程度与对其他项目的兴趣程度相比。如果这些历史序列购买模式被分析并整合到用户-项目矩阵输入中,那么评分质量(指定已评分项目的喜好程度或价值)和数量(为之前未知的评分找到可能的评分)可以通过挖掘的序列模式得到增强和改善。因此,推荐质量可以在准确性、可扩展性和新颖性方面得到提升。电子商务网站的一个重要任务是基于用户购物历史来预测用户未来可能购买的商品。这个问题可以使用文献中最成功的技术之一——协同过滤(CF)技术来建模,该技术利用用户显式的评分-项目矩阵数据进行推荐。CF的一般技术[1]接受一个不完整的用户-项目评分矩阵作为输入,目标是预测目标用户或项目的未知评分。对于基于用户的CF,使用目标用户u的类似用户的评分来为用户u做出推荐。这组邻居的加权评分被用作目标用户u的预测评分。同样,可以在项目-用户评分矩阵的行之间计算函数,以发现可能购买相同类型产品的相似用户。这种模型的一个主要优点是其能够捕捉到推荐的整体口味。然而,这种算法有两个明显的不足。首先,当用户的显式评分行为数据稀疏时,这类算法的有效性大大降低;其次,这些方法忽略了用户行为的时间背景,即客户的购买行为可能随时间变化,因此无法捕捉到用户的序列行为。最近,SPM技术[7,8]被单独用来通过提取用户购买行为的序列模式来使推荐更有效,因为用户的下一次购买受到他们之前购买和行为的影响。这种推荐通常利用用户的隐式反馈数据;这种模型的主要优点是其能够捕捉到用户的序列购买行为以进行推荐。然而,单独的SPM推荐模型无法捕捉到用户的一般口味。可以看出,这两种方法(CF和SPM)都有不足之处。实际上,用户的序列行为和一般口味都是影响用户购买行为的重要因素,如[9-11]所示。这激发了对将SPM与CF整合到推荐系统中以提高推荐质量的重要性进行系统性回顾,通过更多样化的推荐来解决高稀疏矩阵问题,从而使推荐更好地考虑到用户的一般口味和序列行为。对这些基于序列模式的协同电子商务推荐系统进行回顾,涉及比较它们的特征,如推荐准确性、用户评分矩阵输入数据稀疏比率和功能(例如,推荐新颖和多样化产品的能力,适应频繁变化的产品和用户可扩展性的能力),推荐方法,通过清晰的例子理解系统的算法,并强调它们在推荐过程中的优势、弱点和未来前景。本文调查研究的重点是对协同过滤系统基于RS的算法方法的深入理解,这些方法通过历史购买和点击流数据的序列模式挖掘来提高推荐质量。早期关于基于协同过滤技术的评估推荐系统的方法的工作和调查包括[12-18]。这项工作与现有的评估推荐系统方法的调查或评论不同,例如[19,20],它们提供了一个框架,但没有讨论任何算法。这种更传统和技术可理解的基于挖掘的方法与其他相关调查或研究复杂基于深度学习的序列推荐系统[11,21-25]不同,后者没有利用历史和点击流购买数据来跟踪客户的时间购买行为。
现有的基于序列模式的电子商务推荐系统 Existing Sequential Pattern-Based E-Commerce Recommendation Systems
电子商务网站的主要目标是将访问者转变为客户。由于交易数据提供了一组首选项目,并且可以用来预测未来的客户偏好,研究人员已经应用关联规则挖掘技术来提取序列,以提高推荐系统的性能[30,31]。然而,这样的系统只结合了单一时间周期的客户交易数据,忽略了客户访问序列的动态性质。与关联规则不同,序列模式[8]可能表明,当前时间周期内访问新项目的用户体验可能在下一个时间周期内访问另一个项目。因此,SPM技术已被用于提取用户购买行为的复杂序列模式,如果这些模式被学习和包含在用户-项目矩阵输入中,推荐系统的准确性就会提高,因为输入在输入到CF之前变得更加信息丰富。因此,将CF和历史购买数据的SPM整合起来可以提高推荐质量,减少数据稀疏性,并增加推荐的新颖性。虽然序列模式挖掘算法(如GSP[5]、SPADE[32]和PrefixSpan[33])使用类似a priori的逻辑[34]从序列数据库(例如历史购买或点击)中挖掘频繁模式,但协同过滤算法[1]遵循一般的四步逻辑,以预测输入用户-项目评分矩阵中的缺失评分。首先,为每个用户u计算平均评分。其次,使用相似性函数(如皮尔逊相关系数)计算目标用户v与所有其他用户u之间的相似性。第三,为v的每个未评分项目计算v的同行群体(即v的最相似用户)。最后,用户v的预测评分被计算为v的最相似K个用户对未评分项目的评分的加权平均值。在文献中可以找到的结合了CF和历史购买序列(SPM)以向用户推荐项目的现有电子商务推荐系统包括以下十个系统:(1)基于模型的方法,ChoRec05[35],(2)模式分割框架,ChoRec09[36],(3)基于序列模式的协同推荐系统,HuaRec09[37],(4)基于分割的方法,LiuRec09[38],(5)混合在线产品推荐,ChoiRec12[39],(6)混合模型(HM),RecSys16[40],(7)产品推荐系统(PRS),RecSys16[41],(8)基于序列模式的推荐系统,SainiRec17[42],(9)基于历史购买和点击流的推荐,HPCRec18[43],以及(10)基于历史序列模式推荐,HSPCRec19[6]。接下来将提供这些系统的简要概述。每个回顾的系统首先介绍了其算法和方法,然后是一个系统算法的应用示例,以帮助澄清技术,对于大多数系统来说,这是适用的。
2.1. 基于模型的方法:ChoRec05 [35]
ChoRec05 [35] 概述:提出了一种混合推荐系统,结合了自组织映射(SOM)聚类技术和基于关联规则的序列聚类规则,用于挖掘客户购买行为随时间的变化。自组织映射(SOM)允许将客户历史购买交易按购买时间排列,并分配一个编号的聚类。每次交易导致客户聚类编号的变化,用于创建客户购买序列。此外,使用关联规则挖掘从构建的客户序列中挖掘序列模式。[35]解决的问题可以表述如下:对于目标客户c的给定购买序列,基于时间周期l(例如,l为每个月或三个月的周期),在时间T之前的l-1个周期内,找出目标客户最有可能在时间T购买的产品p。推荐过程分为两个部分,模型构建阶段和推荐阶段。
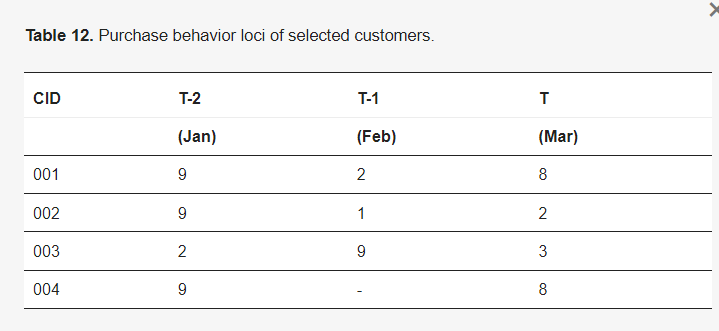
ChoRec05系统[35]的示例应用:解决的问题陈述为:给定输入数据集为:输入:电子商务数据集中的历史购买数据,包括客户ID、购买项目和交易持续时间。预期的输出数据集为:输出:向每个用户推荐产品。应用ChoRec05算法解决此推荐任务。ChoRec05[35]算法首先进行模型构建阶段。模型构建阶段:这个阶段只执行一次,以从客户交易数据库创建一个可靠的模型,包括交易聚类,其中交易被转换为由位向量组成的输入矩阵。这些为给定客户的时间有序向量代表了该客户的购买历史;输入矩阵可以被视为客户的动态档案。识别聚类序列:通过识别客户在每个时间段(例如一月、二月、三月)的聚类,学习客户的聚类序列。使用客户交易变化聚类数据库(例如,表12,称为loci[35]),关联规则挖掘用于预测客户移动。在表12中,第一行意味着CID为001的客户在一月(时间T-2)的购买模式位于聚类9,然后在二月(时间T-1)移动到聚类2,然后在时间T(三月)移动到聚类8。
表12. 选定客户的购买行为loci。
提取序列聚类规则:为了根据购买时间挖掘客户行为,采用关联规则Ri[44]来确定最频繁的规则模式,这些模式等于或超过给定的最小支持和最小置信度,如表13中所示的样本规则。
在关联规则挖掘中,第一阶段,从输入数据库中挖掘频繁模式。然后,从这些频繁模式中推导出关联规则,并仅保留置信度等于或超过设定最小置信度级别的规则作为显著的。规则的置信度是数据库记录中规则的左右两边(前件 → 结果)同时出现的次数除以仅规则左边出现的次数。从客户交易loci(移动)中挖掘的样本规则如表13所示。
表13. 样本推导出的关联规则。

然后ChoRec05[35]算法将继续进行模型构建阶段,并在接下来的推荐阶段进行讨论。推荐阶段:在这个阶段,找到与目标客户动态行为最匹配的产品,并将相关交易转换为行为loci,使用SOM聚类模型,如前一阶段。最后,从关联规则库中提取最佳匹配的loci,并提取前N项推荐给目标客户,即聚类中最常购买的产品(见表14)。在这张表中,选定的聚类有四种产品按购买数量降序排列,购买最多的是品牌23,购买了5次,品牌21购买了4次,品牌28购买了3次,品牌27购买了2次。
表14. 其他目标客户在选定聚类中购买的产品列表。

2.2. 模式分割框架:ChenRec09 [36]
ChenRec09系统[36]概述:Chen等人[36]提出了一种基于序列模式的推荐系统,该系统结合了RFM(最近一次购买时间、购买频率和货币价值)概念。“最近一次购买时间”表示自上次购买以来的时间长度,较低的值对应于客户重复购买的更高概率。“购买频率”表示在指定时间段内购买的次数,频率越高表示客户忠诚度越强。“货币价值”指的是在指定时间段内花费的金额;因此,如果客户具有较高的货币价值,公司应更多地集中资源来保留该客户。然后定义了RFM序列模式,并使用一种名为RFM-Apriori的新算法从客户购买数据中生成所有RFM序列模式。该算法通过对著名的a priori GSP序列模式挖掘算法[5]进行修改而开发,包括迭代阶段。RFM-Apriori算法经历了候选项生成阶段:首先,算法将所有itemsets放入候选项集C1中,即长度为1的候选项模式集,然后扫描数据库以从候选项itemsets C1中找到频繁(大)1-模式(L1)。itemset被用作扩展模式的单位,而不仅仅是一个项目,因为它可以减少完成算法所需的阶段数,从而提高效率。其次,假设已知频繁(k-1)-模式Lk-1,它通过a priori-gen join方式与自身结合以生成长度为k的候选项模式,其中k ≥ 2,如果它们具有相同的(k-2)后缀。算法扫描数据库以确定Ck中模式的支持度,然后通过从Ck中移除支持度低于最小支持阈值的模式来找到Lk。通过增加k的值,重复此迭代,直到无法生成更多模式。为了计算支持度,使用逆候选项树来存储CIk中的所有候选项模式,其中叶节点对应于候选项模式。可以通过每个数据序列遍历树来在每个叶节点中累积支持值。这是一种有效的方法,用于确定候选项模式是否满足最近一次购买时间约束。这种遍历过程是一个递归程序,其中所有子序列在T中可以与CIk中的所有候选项模式匹配。如果找到一个匹配的子序列,可以满足模式的最近一次购买时间和货币约束(叶节点),则增加该模式的rfm-support和rfsupport。如果它只满足最近一次购买时间约束,则只增加rf-support。使用RFM-Apriori算法,提出了一个模式分割框架,允许将RFM模式分割成与RFM标准相关的段,以便为管理决策制定生成有关客户购买行为的有价值信息。通过根据RFM指数对模式进行分组,零售商可以进一步比较、对比和聚合这些模式组,以发现购买模式随时间的可能变化。
2.3. 基于序列模式的协同推荐系统:HuaRec09 [37]
HuaRec09系统[37]概述:Huang等人(2009)提出了一种混合推荐系统,使用基于序列模式的协同推荐系统来预测电子商务环境中客户逐渐变化的购买模式。开发了一个两阶段推荐过程,以预测客户购买行为的产品类别以及产品项目。引入了时间窗口权重,以提供对当前时间段内具有较大影响的序列模式的更高重视,而不是对相对较远时间段的模式。考虑到当前时间段T和前r个时间段T-1、T-2、...、T-r的所有目标客户的交易序列,确定最有可能在下一个时间段T+1(目标预测期)购买项目的活跃客户。所提出的系统包括目标客户的模型训练和活跃客户的模型使用(实施)。在模型使用期间,从目标客户中选择活跃客户以接收推荐。下面讨论了这两个模块中的每个步骤。目标客户的模型训练经历了以下四个步骤:
确定目标客户:可以根据客户行为变量(如最近一次购买时间、购买频率和货币支出)确定目标客户[45]。
构建动态客户档案:可以通过分析客户的周期性交易数据来模拟动态客户购买行为。
客户聚类:基于动态客户档案,使用基于遗传算法的聚类方法对客户进行聚类。
每个聚类的序列模式挖掘:一个聚类的序列模式代表了该聚类中客户的购买行为。使用SPM算法(如GSP[5]或PrefixSpan[33])为每个聚类生成客户购买序列,并发现每个聚类的序列模式。
对于活跃客户的模型使用,遵循两阶段推荐过程,包括为活跃客户选择聚类,其中包括预测前M个产品类别和推荐前N个产品项目。基于产品类别推荐分数(CRS)预测前M个产品类别。预测类别i的CRS计算如下:
CRScategory = ∑period(CATEGORY − SUPPORcategory periodt × WEIGHTperiod) for T = T0, T1, ..., Tr
其中,WEIGHTperiodt是时间段t的时间窗口权重。前N个产品项目的推荐:通过计算前M个产品类别中每个项目的推荐分数来生成活跃客户可能在目标期间购买的前N个项目。项目推荐分数(IRS)对于前M个产品类别中的一个项目itemj计算如下:
IRSitemj = ∑periodt(Purchase − Frequency itemj periodt × Weightperiodt) for T = T0, T1, ..., Tr
其中,Weightperiodt是时间段t的时间窗口权重,Purchase − Frequency itemj periodt是同一聚类中所有客户在时间段t购买itemj的频率。购买频率定义为在特定期间购买次数,而不是数量。然后,向活跃客户推荐具有较大推荐分数的前N个项目,不包括活跃客户之前购买过的项目。
2.4. 基于分割的方法:LiuRec09 [26]
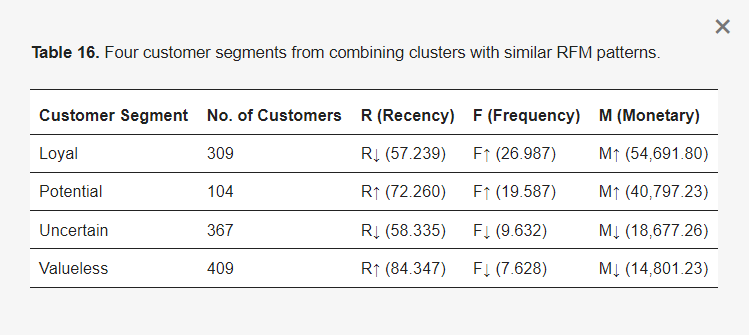
LiuRec09系统[26]概述:提出了一种混合推荐系统,该系统结合了基于分割的序列规则方法和基于分割的KNN-CF方法[26]。假设电子商务历史购买数据包含购买项目、购买频率、价格和交易时间作为输入。基于分割的序列规则(SSR)方法将经历以下步骤。步骤1:客户聚类。根据RFM值(最近一次购买时间、购买频率和货币)将客户聚类成不同的组。通过根据聚类RFM值是否大于或小于整体平均RFM值来分配↑或↓,确定每个聚类的RFM模式。具有相同模式的聚类合并为一个聚类。例如,表15中的聚类3、4和5具有相同的模式;同样,聚类2、7和8可以合并。因此,八个客户聚类可以减少到四个客户细分:忠诚、潜力、不确定和无价值,基于他们的RFM模式,如表16所示。
表15. 基于标准化RFM值的K-means聚类。

表16. 根据相似RFM模式合并聚类得到的四个客户细分。
步骤2:交易聚类。根据相似的产品项目和购买模式,将交易分为不同的组(交易聚类)。一个客户的交易聚类用于识别随时间变化的交易聚类序列。表17显示了三个时期的客户购买行为的变化。
表17. 客户购买行为的变化。

步骤3:从交易聚类中挖掘客户行为。为了根据购买时间挖掘客户行为,采用关联规则[44]来确定最频繁的模式和置信度。从表17中,提取了序列规则Ap2 → Ep3 (0.4,1),支持度为40%,置信度为100%。根据这个规则,如果客户在时期P2的购买行为在交易聚类A中,那么他们在P3的行为将在交易聚类E中。其他序列规则Bp2 → Ep3 (0.2,1)和Bp1 → Dp3 (0.2,1)可以类似地获得。
步骤4:确定目标客户的聚类序列并匹配。通过适应度度量计算目标客户购买行为与序列规则之间的匹配程度。
步骤5:推荐。最后,计算每个项目在预测的交易聚类中的频率计数,并返回频率计数最高的前N个项目。基于分割的KNN-CF方法(SKCF)。在这一步中,使用皮尔逊相关系数来衡量目标客户与其他同一分段中的客户的相似性,然后选择与目标客户最相似的k个(排名最高的)客户作为目标客户的k个最近邻居。选择目标客户在时期T尚未购买的N个最频繁的产品作为前N个推荐。
混合推荐方法。SSR和SKCF通过加权组合线性结合,如下所示,其中α和(1 − α)分别是SKCF和SSR方法的权重。在两种方法的线性组合中具有最高N值的产品项目被选为推荐。
产品评分 = (1 − α) * 序列规则 + α * 协同过滤
2.5. 混合在线产品推荐:ChoiRec12 [39]
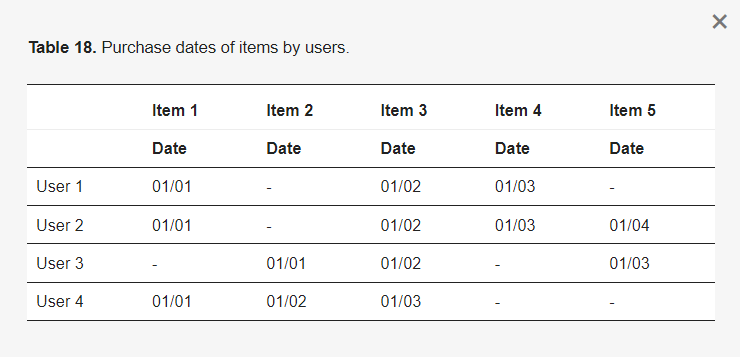
ChoiRec12系统[39]概述:Choi、Yoo、Kim和Suh(2012)提出了一种混合推荐系统,结合了CF和SPM。该系统基于购买历史使用用户u购买项目i的次数来提取隐式评分,即使在没有显式评分的情况下,也可以在CF中使用。ChoiRec12系统的示例应用[39]:给定一个历史购买数据的片段,如表18所示,其中只提供了用户购买项目的日期作为可用信息,目标是向用户T推荐合适的项目。
表18. 用户购买项目的日期。
ChoiRec12系统[39]的一般算法遵循七个步骤来向用户T推荐项目。步骤1:从用户交易中派生隐式评分。隐式评分可以根据购买历史使用用户u购买项目i的次数相对于总交易次数来计算。例如,用户1在三次交易中购买了项目1一次。同样,可以从历史数据创建一个用户-项目隐式评分矩阵,如表19所示。
表19. 从用户交易中派生的隐式评分。
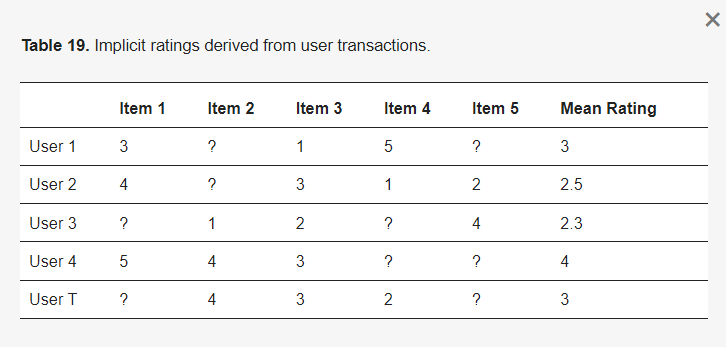
步骤2:计算平均评分和基于隐式评分的用户相似性。平均评分是通过将用户对所有项目的评分相加并除以总评分数来计算的。因此,用户1的平均评分=(3 + 1 + 5)/3 = 3,用户2 = 2.5,用户3 = 2.3,用户4 = 4,用户T = 3。然后使用余弦相似度计算用户之间的相似性,如下所示:
余弦相似度(T, b) = ∑ m i=1(RT,i).(Rb,i) / √∑ m i=1(RT,i)2. √∑ m i=1(Rbi)2
其中(RT,i)表示用户T对项目i的评分;同样,Rb,i表示用户b对项目i的评分。例如,计算出的目标用户T与其他每个用户的相似性将是CS(T,1) = 0.7071,CS(T,2) = 0.9648,CS(T,3) = 0.8944,CS(T,4) = 1,其中CS(T,1)表示目标用户T和用户1之间的余弦相似度,等等。
步骤3:找到目标用户T的前k个最近邻居。这是通过按降序排序用户相似性,然后选择前k(其中k = 2)个邻居来完成的。因此,按降序排列的相似性是CS(T,4) = 1,CS(T,2) = 0.9648,CS(T,3) = 0.8944,CS(T,1) = 0.7071。在这种情况下,目标用户T的前2个邻居是用户4和用户2。
步骤4:计算基于CF的预测偏好(CFPP)。然后使用前k个邻居的评分信息来预测用户a对项目i的基于CF的预测偏好。例如,目标用户T对所有其他项目的CFPP现在是:
CFPP(T, item1) = 4.7455, CFPP(T, item2) = 3.5, CFPP(T, item3) = 3.2365, CFPP(T, item4) = 2, 和 CFPP(T,5) = 3。
步骤5:派生序列模式并计算基于购买项目的评分(SPAPP)。通过按交易日期对每个用户的交易数据进行排序来生成每个用户的序列数据。然后,使用候选项生成(Ck)和修剪(Lk)过程找到频繁项,直到候选项集为空。接下来,通过枚举目标用户购买项目来匹配目标用户购买的子序列。最后,基于用户T对项目i的预测偏好(SPAPP)进行模式分析。例如,目标用户对项目1的SPAPP是SPAPP (T,1) = 0;同样,SPAPP (T,2) = 0,SPAPP (T,3) = 0.75 + 0.5 + 0.5 = 1.25,SPAPP (T,4) = 0.5 + 0.5 + 0.5 = 1.5,和 SPAPP (T,5) = 0.5。
步骤6:整合CFPP和SPAPP。将CFPP和SPAPP标准化以获得N_CFPP和N_SPAPP。目标用户T对项目i的最终预测偏好,FPP (T,i),计算为α乘以CFPP加上1 − α乘以SPAPP,其中α和1 − α分别是分配给CF和SPA的权重,并设置为0.1和0.9。FPP值显示在表20中。
表20. 整合CFPP和SPAPP。

步骤7:推荐排名最高的项目。在获得目标用户邻居购买项目的FPP值后,推荐具有最高FPP值的项目给目标用户T。在表20的情况下,项目3和4将被推荐,因为它们具有最高的FPP值。
2.6. 混合模型:HM RecSys16 [40]
HM RecSys16系统[40]概述:提出了一种混合推荐系统,结合了前缀跨度算法与传统的矩阵分解。SPM旨在在序列数据库中找到频繁的序列模式,并在此混合模型中应用于预测客户支付行为,从而提高模型的准确性。系统的workflow包括三个阶段:行为预测、CF和推荐。
购买模式提取
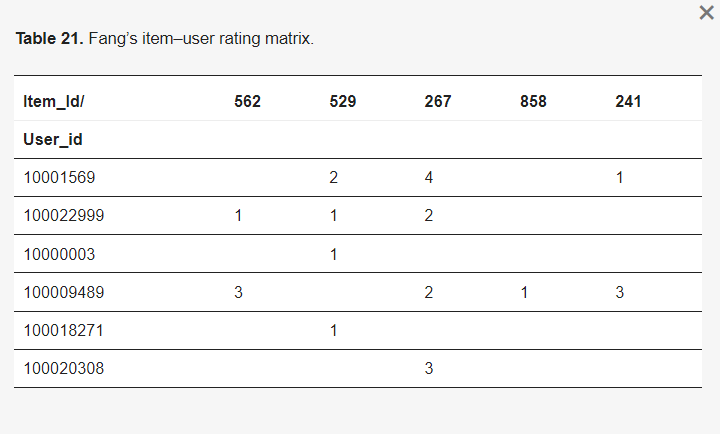
BPM(行为模式模型)利用前缀-跨度算法实时从仓库中提取最普遍的购买序列,并将序列与客户浏览或将商品添加到购物车时的客户行为模式进行匹配。当推荐系统的行为监控部分检测到用户的潜在购买倾向时,系统会从序列数据库中获取用户的历史行为记录,并构建一个类似于表21的项目-用户评分矩阵,其中每个条目包含第I个用户对第J个产品的Ith用户的历史行为。
表21. 方的项目-用户评分矩阵。
基于矩阵分解的协同过滤
CF方法用于找到一组客户,他们的购买和评分项目与用户的购买和评分项目重叠。该算法基于与用户最相似的少数客户生成推荐,并根据他们的历史购买记录生成用户的偏好倾向。使用基本的矩阵分解模型,将用户-项目矩阵分解为两个矩阵,一个代表产品特征,另一个代表用户偏好。通过乘以这两个矩阵,可以预测用户对所有产品的偏好。rui = qT i * pu
rui代表用户u对项目i的评分;然后使用潜在因子模型通过最小化已知评分集上的正则化平方误差来学习因子向量pu和qi。∑(u,i)∈k(rui − qT i .pu)^2 + λ(||qi||^2 + ||pu||^2)
推荐阶段:从行为预测阶段提取的支付行为模式和使用CF方法收集的偏好结合起来,选择目标项目作为建议。在第一步中,生成并存储客户实时行为序列的候选数据库。定期扫描候选数据库,并将包含支付模式的序列发送到推荐系统作为潜在购买序列。其次,对于潜在买家,生成CF阶段的偏好信息,该信息代表了对每个产品的偏好程度。因为序列挖掘阶段生成了支付序列和目标项目类别,所以在偏好向量中匹配类别的项目被推荐。
2.7. 产品推荐系统:PRS RecSys16 [41]
Jamali和Navaei(2016)提出了一个两级产品混合推荐系统,结合了C-Means聚类算法和Freespan算法。首先,使用C-Means算法对可用产品进行聚类,以创建具有相似特征的产品组。然后,第二级考虑客户的行为和购买历史,以便使用序列模式分析(SPA)在产品之间建立关系。这些关系最终导致为客户提供适当的推荐,并增加在电子交易中销售相关产品的可能性。PRS(产品推荐系统)包括两级产品推荐;第一级是在购买前推荐,第二级是在购买后推荐。PRS最初从电子商店收集产品数据,根据其类型分离产品,然后使用C-Means算法将它们基于数值属性聚类成三个独立的质量群组:高、中和低。这里,C-Means聚类算法用于按类型分离产品,并创建具有相似特征的群组,以对产品进行分类。该算法基于模糊逻辑生成群组,并且不考虑群组之间的尖锐边界,允许每个特征向量以一定程度属于不同的群组。特征向量与群组之间的成员资格度通常被认为是其与群组中心点距离的函数,基于以下目标函数的最小化:
Jm = ∑ N i=1 ∑ C i=1 um ij ∥Xi − cj∥2, 1 ≤ m ≤ ∞,
其中m是大于1的任何实数,uij是xi在群组j中的成员资格度,xi代表第i个d维测量数据,cj是群组的d维中心,∥ ∗ ∥表示任何表示任何测量数据与中心之间的相似性的范数。
接下来,PRS尝试使用在线表单收集有关产品的信息,如类型、质量、价格、品牌等,以确定客户的需求和标准。这些信息用于为客户分配适当的群组。在第二级,收集有关客户购物行为历史的信息。这些信息用于使用SPA方法的Freespan算法探索产品之间的关系。Freespan通过递归地基于投影的项目集对序列子数据库进行分区和投影,从而挖掘序列模式[46]。最终,这些关系和模式被提供为产品推荐,推荐与购买产品相关的产品,使客户意识到可能相关的产品,因为产品之间的关系增加了客户购买这些产品的可能性。
总结
总结来说,文章综述了基于序列模式的电子商务推荐系统,强调了通过整合用户购买和点击行为的序列模式来提高推荐准确性、减少数据稀疏性、增加推荐新颖性,并改善推荐系统的可扩展性。文章详细分析了现有推荐系统的方法、性能和潜在问题,并提出了未来研究的方向,包括更精确地评估序列模式的购买概率、整合点击流数据以及开发跨域推荐系统。
写在结尾
这篇文章实在太长了,能力和时间有限,以后有机会再读剩下的文章吧。
好了,今天的论文就读到这了,明天见!
读论文-基于序列模式的电子商务推荐系统综述(A Survey of Sequential Pattern Based E-Commerce Recommendation Systems)的更多相关文章
- 【新鲜出炉的个人项目】基于 Flink 的商品推荐系统
FlinkCommodityRecommendationSystem Recs FlinkCommodityRecommendationSystem(基于 Flink 的商品推荐系统) 1. 前言 系 ...
- 【论文笔记】基于图机构的推荐系统:Billion-scale Commodity Embedding for E-commerce Recommendation in Alibaba
论文:https://arxiv.org/abs/1803.02349 题外话: 阿里和香港理工联合发布的这篇文章,整体来说,还挺有意思的. 刚开始随便翻翻看看结构图的时候,会觉得:这也能发文章 ...
- (读论文)推荐系统之ctr预估-NFM模型解析
本系列的第六篇,一起读论文~ 本人才疏学浅,不足之处欢迎大家指出和交流. 今天要分享的是另一个Deep模型NFM(串行结构).NFM也是用FM+DNN来对问题建模的,相比于之前提到的Wide& ...
- 【RS】Collaborative Memory Network for Recommendation Systems - 基于协同记忆网络的推荐系统
[论文标题]Collaborative Memory Network for Recommendation Systems (SIGIR'18) [论文作者]—Travis Ebesu (San ...
- 基于Spark的电影推荐系统(推荐系统~4)
第四部分-推荐系统-模型训练 本模块基于第3节 数据加工得到的训练集和测试集数据 做模型训练,最后得到一系列的模型,进而做 预测. 训练多个模型,取其中最好,即取RMSE(均方根误差)值最小的模型 说 ...
- 基于Mahout的电影推荐系统
基于Mahout的电影推荐系统 1.Mahout 简介 Apache Mahout 是 Apache Software Foundation(ASF) 旗下的一个开源项目,提供一些可扩展的机器学习领域 ...
- 读论文系列:Deep transfer learning person re-identification
读论文系列:Deep transfer learning person re-identification arxiv 2016 by Mengyue Geng, Yaowei Wang, Tao X ...
- 实现基于lnmp的电子商务网站
今天带给大家的是一个实战项目,主要是让大家了解在我们接到一个项目时,我们该怎样做好这个项目,下面看具体内容: 技术说明 LNMP代表的就是:Linux系统下Nginx+MySQL+PHP这种网站服务器 ...
- 基于pytorch的电影推荐系统
本文介绍一个基于pytorch的电影推荐系统. 代码移植自https://github.com/chengstone/movie_recommender. 原作者用了tf1.0实现了这个基于movie ...
- 基于Spark的电影推荐系统(电影网站)
第一部分-电影网站: 软件架构: SpringBoot+Mybatis+JSP 项目描述:主要实现电影网站的展现 和 用户的所有动作的地方 技术选型: 技术 名称 官网 Spring Boot 容器 ...
随机推荐
- OpenTelemetry.NET API
OpenTelemetry.NET API Status and Releases Tracing Metrics Logging 1.0 Alpha Beta 安装 dotnet add packa ...
- JavaScript 的 Mixin 问题
JavaScript 从 ES6 开始支持 class 了, 如何在现在的 class 上实现 mixin 呢? 很多人推荐这种搞法 Object.assign(MyClass.prototype, ...
- K8S deployment 重启的三种方法
一般重启deployment,常规操作是删掉对应的pod, 但如果有多个副本集的话,一个个删很麻烦.除了删除pod,还可以: 方案一: 加上环境变量kubectl patch deploy <d ...
- iaas,saas,paas,daas区别:
iaas,saas,paas,daas区别: Iaas(Infrastructure as a server):基础设施即服务,是基础层.PaaS(Platform as a Server):平台即服 ...
- Qt音视频开发43-采集屏幕桌面并推流(支持分辨率/矩形区域/帧率等设置/实时性极高)
一.前言 采集电脑屏幕桌面并推流一般是用来做共享桌面.远程协助.投屏之类的应用,最简单入门的做法可能会采用开个定时器或者线程抓图,将整个屏幕截图下来,然后将图片传出去,这种方式很简单但是性能要低不少, ...
- Qt编写物联网管理平台45-采集数据转发
一.前言 本系统严格意义上说是一个直连硬件的客户端软件,下面接的modbus协议的设备直接通过网络或者串口和软件通信,软件负责解析数据和存储记录.有时候客户想要领导办公室或者分管这一块的部门经理办公室 ...
- Qt数据库应用16-通用数据库采集
一.前言 数据库采集对应的就是上一篇文章的数据库同步,数据库同步到云端数据库以后,app.网页.小程序啥的要数据的话,可以通过执行http请求拿到数据,http接收应答这边程序一般最简单可以用php写 ...
- Pelco-D控制协议
1. 通令参数: 标准速率为4800bps,无校验, 8位数据位,1位停止位 2.命令串格式: 一个PTZ控制命令为7字节的十六进制代码,格式如下: Word 1 Word2 Word 3 Wor ...
- [转]xmanager和xshell什么关系 xmanager怎么使用
xmanager是一款小巧实用且运行于Windows系统上的X服务器软件,可以帮助用户快速连接并访问Unix/Linux服务器.那xmanager和xshell什么关系,xmanager怎么使用,本文 ...
- 基于Netty,从零开发IM(四):编码实践篇(系统优化)
本文由作者"大白菜"分享,有较多修订和改动.注意:本系列是给IM初学者的文章,IM老油条们还望海涵,勿喷! 1.引言 前两篇<编码实践篇(单聊功能)>.<编码实践 ...