[算法]KD树
KD树,你看着他好几个维度不明白,但实际上非常简单
\(K\)指维度 因此他可以在二维(多维)平面内进行搜索!!!
1.二维
1.1 建树
对于每一层,我们使用轮转法进行建树 什么意思呢?比如二维,如果\(x\)层为一维(横坐标),则\((x+1)\)层为二维(纵坐标)
确定好维数,接下来就是构建了。
此处用一张平面直角坐标系图来进行举例说明
已知二维平面点集\({(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)}\)
首先进行排序,排完后如下:
\({(2,3),(4,7),(5,4),(7,2),(8,1),(9,6)}\)
将其作图,得:
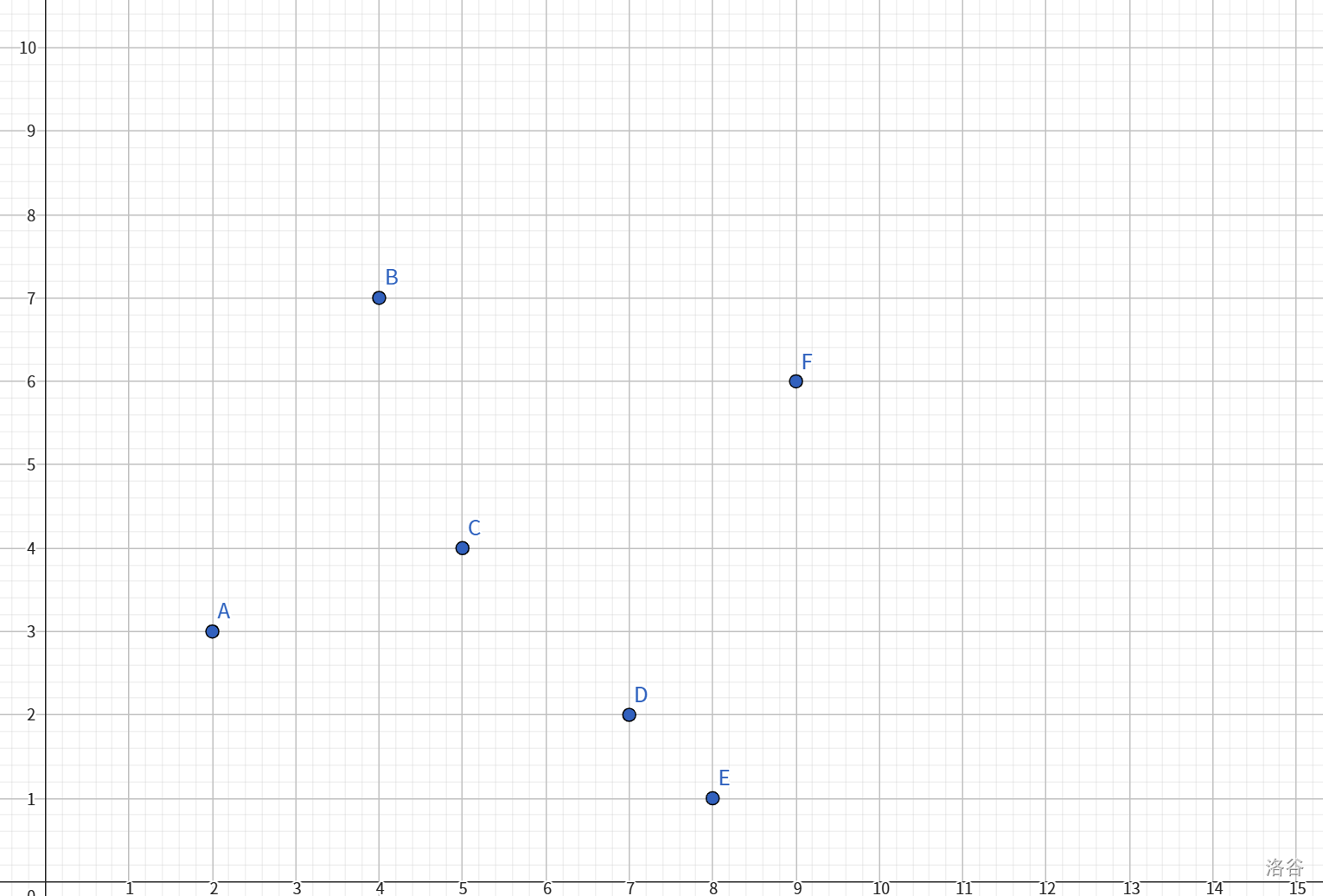
第一轮在\(x\)轴上进行划分(竖着切),找中点,得\((7,2)\)
则有图:

然后就有问题了
没法确定左右子树的根节点啊
于是递归
因为是第二轮,所以横着在\(y\)轴上划分
首先划分相对的左子树,找中点,得图:
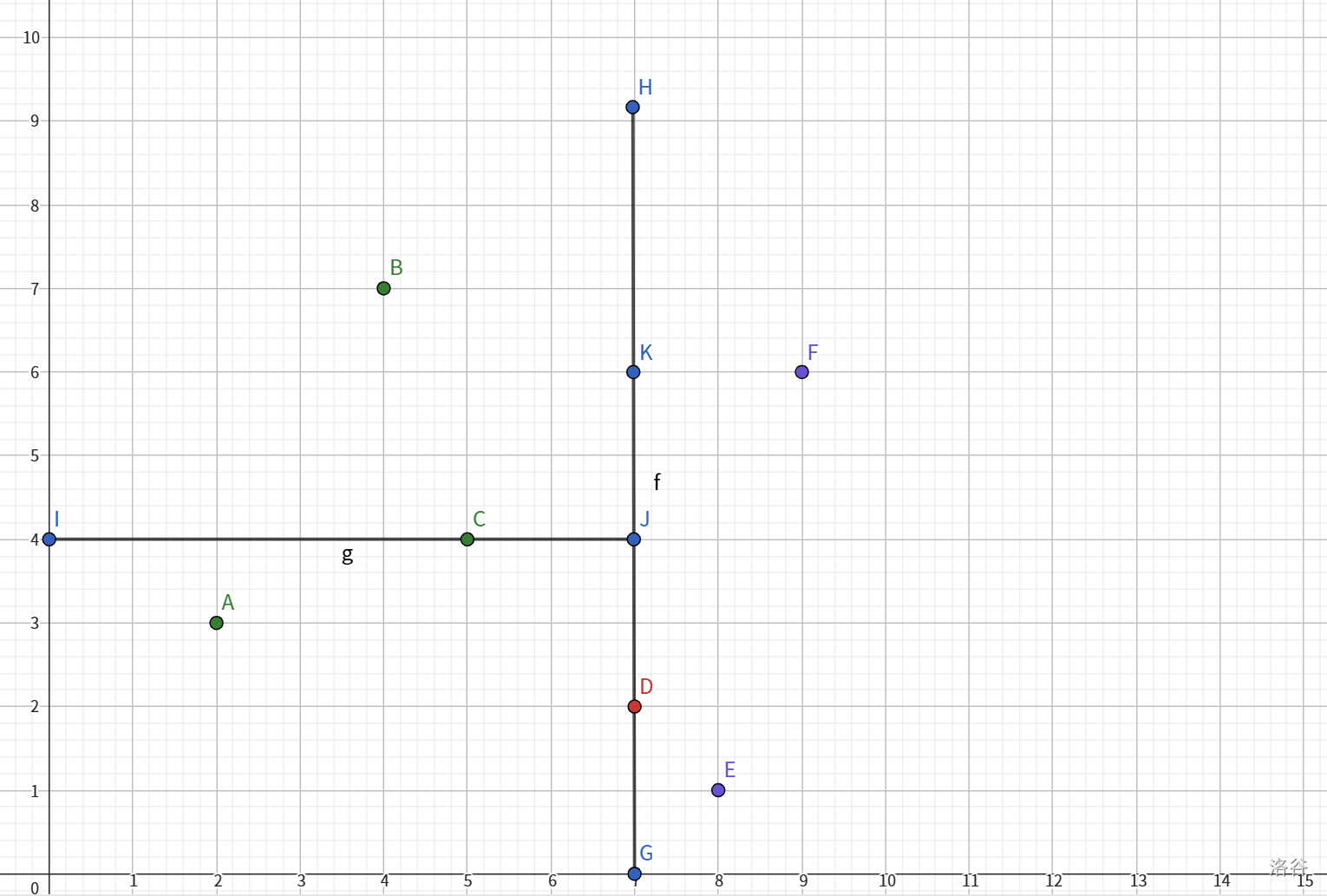
因此完整构建左子树
然后构建右子树(\(y\)轴)
两个点,我习惯性将在上的设为中点,则得图:
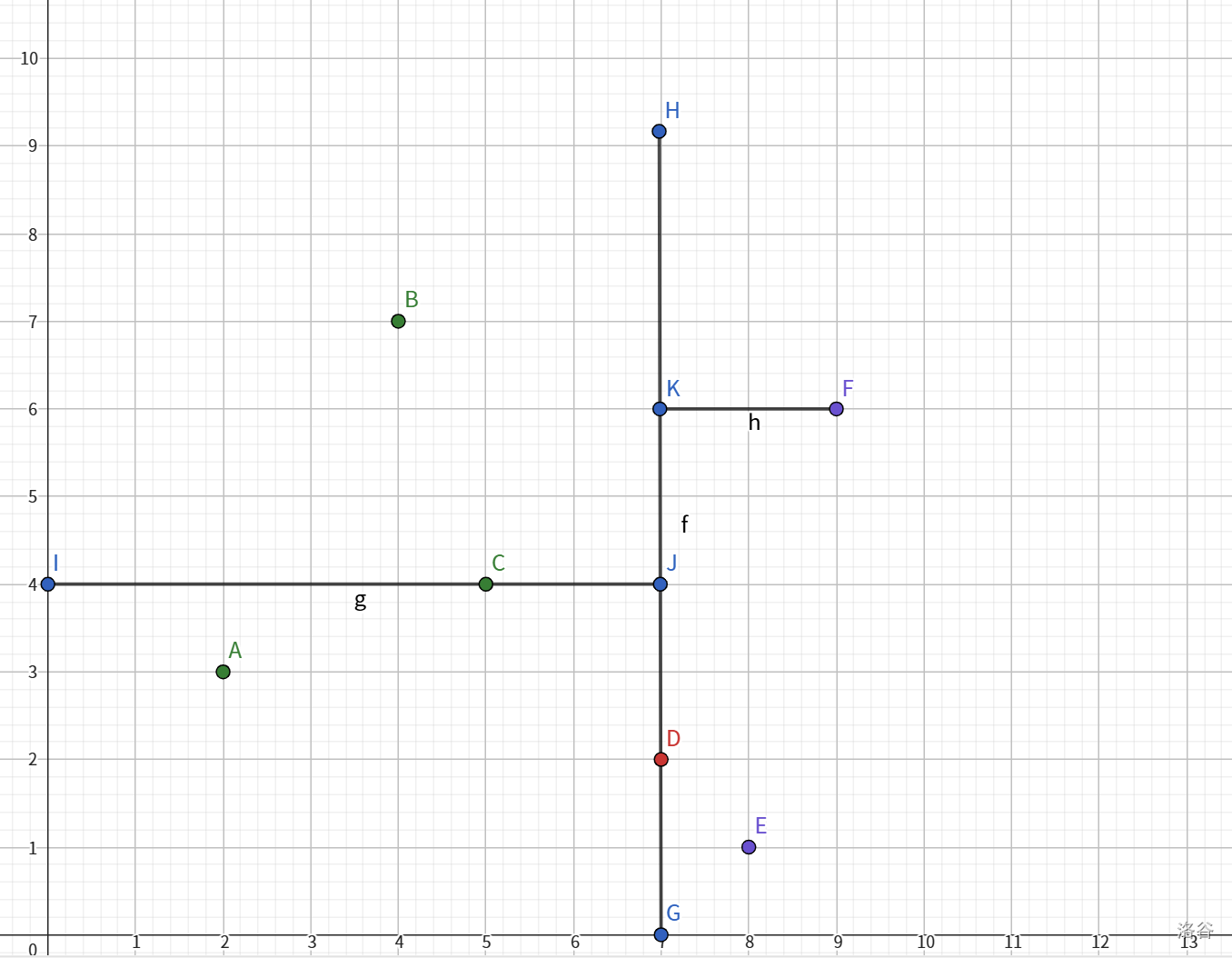
因此构建出树:
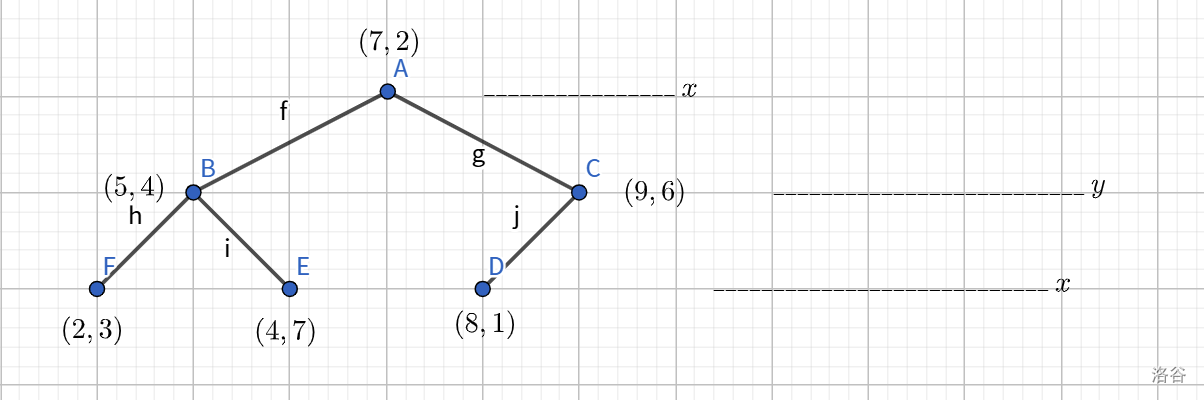
可以看到,每一次划分都用一条水平线或垂直线将平面分成相等的两部分(二分思想),得到的两个子空间单座左右节点,即二分过程
1.2 计算中位数
nth_element(ps+l,ps+mid,ps+r)解决的问题不必多讲 但是不会排序数组!!!
1.3 代码
struct kdTree {
point p; // 直接存储对象
kdTree ls, rs; // 对象实例
};
/kdtree-build
void build(int l, int r, int rt = 1, int dep = 0)
{
if (l > r)
return;
son[rt] = r - l; // 当前节点子树元素数量
son[rt * 2] = son[rt * 2 + 1] = -1; // 初始化子节点为无效值
idx = dep % k; // 根据深度决定当前分割维度
int mid = (l + r) / 2; // 计算当前区间中点
// 快速选择算法,将中位数元素放到mid位置
nth_element(po + l, po + mid, po + r + 1);
pt[rt] = po[mid]; // 当前节点存储中位数点
// 递归构建左右子树
build(l, mid - 1, rt * 2, dep + 1); // 左子树区间[l,mid-1]
build(mid + 1, r, rt * 2 + 1, dep + 1); // 右子树区间[mid+1,r]
}
2.插入
2.1 思路
与二叉查找树类似,假设现在要将新增点插入到节点\(x\)的子树中,那么通过比较新增点的大小,来确定是左/右子树
(小左大右)
2.2 代码
void insert(kdTree* &o,const point &p)
{
if(o==nullptr) // 当前节点为空时创建新节点
{
o=new kdTree(p); // 初始化新节点存储目标点
return;
}
int d=cmp(p,o->p)^1; // 比较当前维度坐标(异或1实现维度交替)
dimension ^=1; // 切换分割维度
insert(o->ch[d],p); // 递归插入对应子树
o->maintain(); // 更新节点统计信息(如子树大小等)
}
3.查询
3.1 思路
对于每个节点,判断其对应的k维超矩形是否与查询超矩形有交集。
1.如果当前超矩形与查询超矩形不相交,则跳过该节点。
2.如果当前超矩形完全包含在查询超矩形内,则将该节点及其子树中的所有点添加到结果集。
3.如果当前超矩形与查询超矩形部分相交,则递归查询左右子树。
ps.超矩形你可以理解为一大块空间,放到二维上比
3.2 代码
可惜啦 这里没有代码
这就是\(manacher\)的思路,回去好好想想,看看自己是否学会!
4.查找最近/远点
4.1 思路
这里以查找远点为例,就是由远及近的一个思想,看着代码理解
4.2代码
void query(kdTree* o,const point &p)
{
if(o==nullptr) return;
ans=min(ans,dis(o.p,p)); // 更新最近距离
int d=o.ls.dis(p)>o.rs.dis(p); // 比较左右子树到目标点的距离,选择更远的分支
query(o.ch[d],p); // 优先搜索更远的分支(剪枝优化)
if(o.ch[d^1].dis(p)<ans) // 检查另一分支是否可能有更近点
query(o.ch[d^1],p); // 递归搜索另一分支
}
5.例题
1.摆棋子
2.查找k远点
都是模板题,只不过一个是远,一个是近,这里就不解析了(反正也是模板题
完结撒花!!!
[算法]KD树的更多相关文章
- KNN算法与Kd树
最近邻法和k-近邻法 下面图片中只有三种豆,有三个豆是未知的种类,如何判定他们的种类? 提供一种思路,即:未知的豆离哪种豆最近就认为未知豆和该豆是同一种类.由此,我们引出最近邻算法的定义:为了判定未知 ...
- kd树的构建以及搜索
构建算法 k-d树是一个二叉树,每个节点表示一个空间范围.表1给出的是k-d树每个节点中主要包含的数据结构. 表1 k-d树中每个节点的数据类型 域名 数据类型 描述 Node-data 数据矢量 数 ...
- 从K近邻算法谈到KD树、SIFT+BBF算法
转自 http://blog.csdn.net/v_july_v/article/details/8203674 ,感谢july的辛勤劳动 前言 前两日,在微博上说:“到今天为止,我至少亏欠了3篇文章 ...
- <转>从K近邻算法、距离度量谈到KD树、SIFT+BBF算法
转自 http://blog.csdn.net/likika2012/article/details/39619687 前两日,在微博上说:“到今天为止,我至少亏欠了3篇文章待写:1.KD树:2.神经 ...
- 算法5-6:Kd树
问题 给定一系列的点.和一个矩形.求矩形中包括的点的数量. 解答 这个问题能够通过建立矩阵来进行求解.首先将一个空间切割成矩阵,将点放置在相应的格子中.再计算矩形覆盖的格子.再推断格子中的点是否包括在 ...
- 从K近邻算法、距离度量谈到KD树、SIFT+BBF算法
转载自:http://blog.csdn.net/v_july_v/article/details/8203674/ 从K近邻算法.距离度量谈到KD树.SIFT+BBF算法 前言 前两日,在微博上说: ...
- 【特征匹配】SIFT原理之KD树+BBF算法解析
转载请注明出处:http://blog.csdn.net/luoshixian099/article/details/47606159 继上一篇中已经介绍了SIFT原理与C源代码剖析,最后得到了一系列 ...
- 一看就懂的K近邻算法(KNN),K-D树,并实现手写数字识别!
1. 什么是KNN 1.1 KNN的通俗解释 何谓K近邻算法,即K-Nearest Neighbor algorithm,简称KNN算法,单从名字来猜想,可以简单粗暴的认为是:K个最近的邻居,当K=1 ...
- 【分类算法】K近邻(KNN) ——kd树(转载)
K近邻(KNN)的核心算法是kd树,转载如下几个链接: [量化课堂]一只兔子帮你理解 kNN [量化课堂]kd 树算法之思路篇 [量化课堂]kd 树算法之详细篇
- kd树和knn算法的c语言实现
基于kd树的knn的实现原理可以参考文末的链接,都是一些好文章. 这里参考了别人的代码.用c语言写的包括kd树的构建与查找k近邻的程序. code: #include<stdio.h> # ...
随机推荐
- K8s进阶之MetalLB实现LoadBalancer
概述 LoadBalancer官网文档:https://kubernetes.io/zh-cn/docs/concepts/services-networking/service/#loadbalan ...
- 深入理解微服务架构:银弹 or 焦油坑?
极客时间:<从 0 开始学架构>:深入理解微服务架构:银弹 or 焦油坑? 微服务与 SOA 的关系 SOA和微服务的关系和区别,可分为以下几种典型的观点: 微服务是 SOA 的实现方式 ...
- C# unsafe 快速复制数组
(1) /// <summary> /// 复制内存 /// </summary> /// <param name="dest">目标指针位置& ...
- Mimikatz 常用命令
以肉去蚁蚁愈多,以鱼驱蝇蝇愈至. 导航 1 工具介绍 2 基本用法 2.1 执行方式 2.2 帮助命令 3 模块用法 3.1 Standard 模块 3.2 Privilege 模块 3.3 Toke ...
- Odoo14前端框架常用操作
单页Web应用(single page web application,SPA): SPA 是一种特殊的 Web 应用,是加载单个 HTML 页面并在用户与应用程序交互时动态更新该页面的. 它将所有的 ...
- Mysql索引为什么要采用B+Tree而非B-Tree
B+树非叶子节点不存储数据只存储索引,B树非叶子节点存储数据. B+树查询效率更高.B+树使用双向链表串连所有叶子节点,区间查询效率更高(因为所有数据都在B+树的叶子节点,扫描数据库 只需 ...
- 解决Navicat导出Excel数字为科学计数法问题
问题分析 需求是使用Navicat导出数据到Excel中,但是,发现导出的数据中,数字长度如果超过12位,自动的按照科学计数法显示数字.我们需要全部显示输入的内容,而不能使用科学计数法,如输入的身份证 ...
- ElasticSearch介绍及单机版安装
概述 ElasticSearch官网:https://www.elastic.co/cn/elasticsearch GitHub地址:https://github.com/elastic/elast ...
- Istio流量控制
Istio 是现在最热门的 Service Mesh 工具,istio 是由 Google.IBM.Lyft 等共同开源的 Service Mesh(服务网格)框架,于2017年初开始进入大众视野.K ...
- ChatMoney智能体高情商接话神器
本文由 ChatMoney团队出品 会说话是一个人的优势,而会接话才是一个人的本事.现实中很多人有这样的困扰:朋友聚会.上门拜访以及和人聊天.是不是完全不知道如何回应,只会说"嗯" ...