没有Happens-Before?你的多线程代码就是‘一锅粥’!
内存模型与happens-before:开发者与硬件的和平条约
在前文中,提到处理器通过一些特殊指令(如 LOCK、CMPXCHG、内存屏障等)来保障多线程环境下程序的正确性。然而,这种做法仍然存在几个显著问题。
1)底层指令实现复杂且晦涩:处理器指令的细节往往难以理解,开发者需要付出大量的时间和精力来掌握这些低级实现。
2)不同平台间的兼容性问题:不同硬件架构和操作系统对这些指令的支持和实现方式各不相同,这要求程序在设计时考虑到跨平台的兼容性和一致性。
3)多线程数据操作的复杂性:随着程序业务逻辑的多变,处理器与线程之间的内存访问依赖关系变得更加复杂,从而增加了程序出错的风险。
为了简化并发编程,解决这些问题,现代编程语言通常提供了抽象的内存模型,用以规范多线程环境下的内存访问行为。这种抽象使开发者无需关注底层硬件与操作系统实现细节,即可编写高效且可移植的并发程序。
以 Java 为例,Java语言采用了Java 内存模型(Java Memory Model,JMM)来提供这种抽象。 Java 内存模型的核心目的是通过支持诸如 volatile、synchronized、final 等同步原语,来确保在多线程环境下程序的原子性、可见性和有序性。这些原语确保了不同线程间的操作能够按照特定的规则正确协作。
此外,JMM 还引入了一个重要概念:happens-before 关系,旨在描述并发编程中操作之间的偏序关系。具体来说,偏序关系主要用于确保线程间操作的顺序性,避免因执行顺序不明确而导致的并发问题。
偏序关系在并发编程中的应用主要体现在以下两种情况。
1)程序顺序(Program Order):指单线程中,由程序控制流决定的操作顺序。例如,如果操作 A 在操作 B 之前执行,那么我们可以认为 A <= B。
2)同步顺序(Synchronization Order):指由并发控制机制(如锁、信号量等)所控制的操作顺序。例如,如果操作 A 释放了锁,而操作 B 随后获取了该锁,那么我们可以认为 A <= B。
除了 Java 之外,其他现代编程语言,如 Go、C++、Rust 等,也都实现了各自的 happens-before 关系机制,以确保并发程序的正确性和一致性。

Java内存模型的happens-before关系是用来描述两个线程操作的内存可见性。需注意这里的可见性,并不代表A线程的执行顺序一定早于B线程, 而是A线程对某个共享变量的操作对B线程可见。即A线程对变量a进行写操作,B线程读取到是变量a的变更值。
Java内存模型定义了主内存(Main memory),本地内存(Local memory),共享变量等抽象关系,来决定共享变量在多线程之间通信同步方式,即前面所说两个线程操作的内存可见性。其中本地内存,涵盖了缓存,写缓冲区,寄存器以及其他硬件和编译器优化等概念。
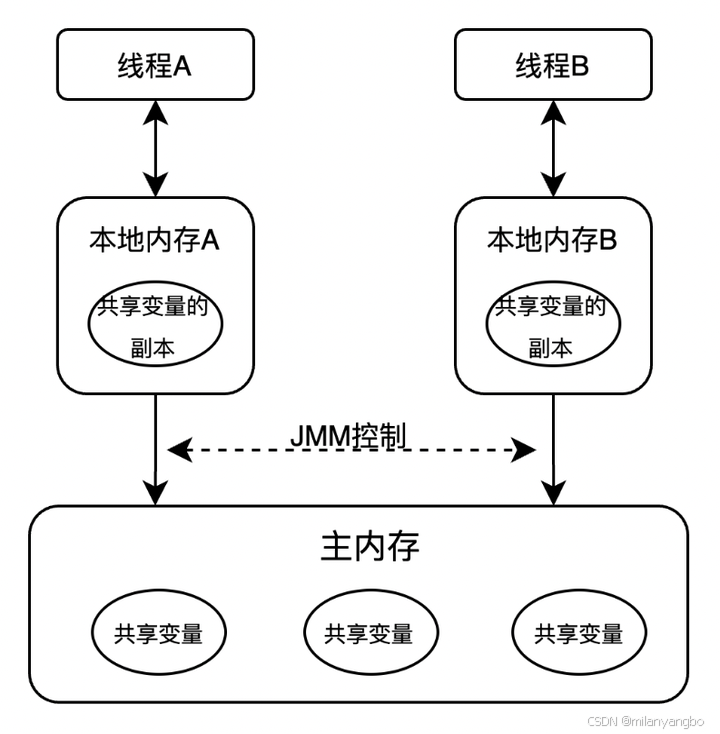
如图所示,如果线程A与线程B之间要通信的话,必须要经历下面2个步骤:
1)线程A把本地内存A中更新过的共享变量刷新到主内存中;
2)线程B到主内存中去读取线程A之前已更新过的共享变量。
为了进一步抽象这种线程间的数据同步方式,Java内存模型定义了下述线程间的happens-before关系。
1)程序顺序规则:单线程内,每个操作happens-before于该线程中的任意后续操作。
// Thread1内, A happens-before B,B happens-before C。
// 这意味着A一定会在B之前完成,B一定会在C之前完成。因此,可以确信y包含x+5的结果。
Thread1 {
x = 10; // A
y = x + 5; // B
print(y); // C
}
2)监视器锁规则:释放锁的操作happens-before之后对同一把锁的获取的锁操作。
// Thread1释放锁(B)happens-before Thread2获取锁(C)。
// 这意味着当Thread2打印x时,它看到的一定是"Thread1 data",因为Thread1的修改操作和释放锁操作,都在Thread2获取锁之前完成。
lock = Lock()
Thread1 {
lock.acquire()
x = "Thread1 data" // A
lock.release() // B
}
Thread2 {
lock.acquire() // C
print(x) // D
lock.release()
}
3)volatile变量规则:volatile字段的写操作happens-before之后对同一字段的读操作。
// 对volatile字段的写操作(A)happens-before之后对同一字段的读操作(B)。
// 这意味着当Thread2读取x时,它看到的一定是100,因为Thread1的写操作在Thread2的读操作之前完成。
volatile int sharedData; // 声明一个volatile变量
Thread1 {
x = 100; // A
}
Thread2 {
int localData = x; // B
print(localData);
}
4)传递性规则:如果A happens-before B,且B happens-before C,那么A happens-before C。
// 如果Thread1 A happens-before Thread2 B,且Thread2 B happens-before Thread2 C,那么Thread1 A happens-before Thread2 C。
// 这意味着A一定会在C之前完成。因此,可以确信z包含(x+5)*2的结果,因为赋值给x的操作和计算x+5的操作都在计算y*2的操作之前完成。
Thread1 {
x = 10; // A
}
Thread2 {
y = x + 5; // B
z = y * 2; // C
print(z);
}
5)start()规则:如果线程A执行操作ThreadB.start(),那么A线程的ThreadB.start()操作happens-before于线程B中的任意操作。
// 如果Thread1执行操作ThreadB.start(),那么Thread1 A happens-before Thread2 C。
// 这意味着A一定会在C之前完成。因此,可以确信Thread1 x值为10,因为赋值给x的操作在打印x的操作之前完成。
Thread1 {
ThreadB.start(); // A
x = 10; // B
}
Thread2 {
print(x); // C
}
6)join()规则:如果线程A执行操作ThreadB.join()并成功返回,那么线程B中的任意操作 happens-before 线程A从ThreadB.join()操作成功返回。
// 如果线Thread1执行操作Thread2.join(),那么Thread2 D happens-before Thread1 C。
// 这意味着D一定会在C之前完成。因此,可以确信Thread1 x值为10,因为赋值给x的操作在打印x的操作之前完成。
Thread1 {
Thread2.start(); // A
Thread2.join(); // B
print(x); // C
}
Thread2 {
x = 10; // D
}
如上的happens-before关系中,与日常开发密切相关的是1、2、3、4四个规则。其中规则1满足了as-if-serial语义,即Java内存模型允许代码和指令重排序,只要不影响程序执行结果。规则2和3是通过synchronized、volatile关键字实现。结合规则1、2、3来看看规则4的具体使用,可以看到如下的代码,程序最终执行且得到正确结果。
// x, y, z被volatile关键字修饰
private volatile int x, y, z;
public void test() {
Thread a = new Thread(() -> {
// 基于程序顺序规则
// 没有数据依赖关系,可以重排序下面代码
int i = 0;
x = 2;
// 基于volatile变量规则
// 编译器插入storeload内存屏障指令
// 1)禁止代码和指令重排序
// 2)强制刷新变量x的最新值到内存
});
Thread b = new Thread(() -> {
int i = 0;
// 存在数据依赖关系,无法重排序下面代码
// 强制从主内存中读取变量x的最新值
y = x;
// 基于volatile变量规则
// 编译器插入storeload内存屏障指令
// 1)禁止代码和指令重排序
// 2)强制刷新变量y的最新值到内存
// 3)y = x;可能会被编译优化去除
y = 3;
// 编译器插入storeload内存屏障指令
// 1)禁止代码和指令重排序
// 2)强制刷新变量y的最新值到内存
});
Thread c = new Thread(() -> {
// 基于程序顺序规则
// 没有数据依赖关系,可以重排序下面代码
int i = 0;
// 基于volatile变量规则
// 强制从主内存中读取变量x和y的最新值
z = x * y;
// 编译器插入storeload内存屏障指令
// 1)禁止代码和指令重排序
// 2)强制刷新变量z的最新值到内存
});
// ...start启动线程,join等待线程
assert z == 6;
// 可以看到a线程对变量x变更,b线程对变量y变更,最终对线程c可见
// 即满足传递性规则
}
private int x, y, z;
public void test() {
Thread a = new Thread(() -> {
// synchronized,同步原语,程序逻辑将顺序串行执行
synchronized (this){
// 基于程序顺序规则
// 没有数据依赖关系,可以重排序下面代码
int i = 0;
x = 2;
// 基于监视器锁规则
// 强制刷新变量x的最新值到内存
}
});
Thread b = new Thread(() -> {
// synchronized,同步原语,程序逻辑将顺序串行执行
synchronized (this) {
int i = 0;
// 存在数据依赖关系,无法重排序下面代码
// 强制从主内存中读取变量x的最新值
y = x;
// 基于监视器锁规则
// 1)强制刷新变量y的最新值到内存
// 2)y = x;可能会被编译优化去除
y = 3;
// 强制刷新变量y的最新值到内存
}
});
Thread c = new Thread(() -> {
// synchronized,同步原语,程序逻辑将顺序串行执行
synchronized (this) {
// 基于程序顺序规则
// 没有数据依赖关系,可以重排序下面代码
int i = 0;
// 基于监视器锁规则
// 强制从主内存中读取变量x和y的最新值
z = x * y;
// 强制刷新变量z的最新值到内存
}
});
// ...start启动线程,join等待线程
assert z == 6;
// 可以看到a线程对变量x变更,b线程对变量y变更,最终对线程c可见
// 即满足传递性规则
}
总结:在混沌与秩序间搭建桥梁
Java内存模型是并发编程中连接开发者与硬件系统的关键桥梁。它依托可见性、有序性和原子性这三大核心原则,将复杂的并发问题转化为清晰的编程规范。当多个线程操作共享变量时,Java内存模型利用volatile、synchronized等机制,有效抑制了处理器优化带来的不确定性,同时兼顾了性能优化需求。其定义的happens-before关系,如同线程间的通信准则,以顺序性规则替代了对缓存刷新、指令重排等底层操作的直接操控。这种设计让开发者能够专注于业务逻辑,仅凭有限的同步手段就能构建出稳健的多线程程序。
Java内存模型的价值在于达成了三个重要平衡:它确保程序正确性不依赖于硬件实现细节;维持同步规则的简洁性以控制复杂度;让开发者能以较低的认知成本构建并发系统。这无疑是工程解耦的典范:用简洁的抽象来掌控复杂的世界。
很高兴与你相遇!
如果你喜欢本文内容,记得关注哦!!!
没有Happens-Before?你的多线程代码就是‘一锅粥’!的更多相关文章
- 使用匿名委托,Lambda简化多线程代码
使用匿名委托,Lambda简化多线程代码 .net中的线程也接触不少了.在多线程中最常见的应用莫过于有一个耗时的操作需要放到线程中去操作,而在这个线程中我们需要更新UI,这个时候就要创建一个委托了 ...
- Eclipse调试多线程代码
Eclipse调试多线程代码 标签: eclipse 调试 多线程 | 发表时间:2013-02-16 05:51 | 作者:czjuttsw 分享到: 出处:http://blog.csdn.net ...
- 第六周测试补交 多线程代码和sumN
1.多线程代码 要求:编译运行多线程程序,提交编译和运行命令截图 2.sumN 要求:1-N求和的截图
- 干货最实用的 Python 多线程代码框架
前言 很多地方都要用到多线程,这是我经常用的多线程代码,放在博客园记录下. 代码 from multiprocessing.pool import ThreadPool thread = 10 ite ...
- JavaScript 编写多线程代码引用Concurrent.Thread.js(转)
这是一个很简单的功能实现: <script type="text/javascript" src="Concurrent.Thread.js">&l ...
- 用gdb调试python多线程代码-记一次死锁的发现
| 版权:本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接.如有问题,可以邮件:wangxu198709@gmail.com 前言 相信很多人都有 ...
- C#多线程代码示例
using System; using System.Threading; namespace MultiThreadDemo { class Program { public static void ...
- 基础才是重中之重~ConcurrentDictionary让你的多线程代码更优美
回到目录 ConcurrentDictionary是.net4.0推出的一套线程安全集合里的其中一个,和它一起被发行的还有ConcurrentStack,ConcurrentQueue等类型,它们的单 ...
- php多线程代码
<?php$thNum = 20; //20个进程$total = 20000;//总数$pageNum=100;//每个页面显示100条数据 $pageCount = ceil($total/ ...
- ConcurrentDictionary让你的多线程代码更优美
ConcurrentDictionary是.net4.0推出的一套线程安全集合里的其中一个,和它一起被发行的还有ConcurrentStack,ConcurrentQueue等类型,它们的单线程版本( ...
随机推荐
- Opencv与Pillow图片操作差异对深度学习的影响
目前在使用Pytorch训练的深度学习模型算法,大部分由于pillow与torchvision中transforms的优异兼容都会采用Image.open from pillow的方式进行图像数据的读 ...
- 编译原理:python编译器--运行时机制
python的运行时机制的核心 -- python对象机制的设计 理解字节码的执行过程 用 GDB 跟踪执行一个简单的示例程序,它只有一行:"a=1". 对应的字节码如下.其中,前 ...
- BD202404 110串
百度之星一场,t4 题目链接: 对于这种连续状态限制的字符串方案数,首先考虑dp, 首先定义好每个状态方便转移,0状态是结尾为0,1状态是结尾1个连续1,2状态是结尾两个连续1,有以下关系 if(s[ ...
- React Native开发鸿蒙Next---RN键盘问题
.markdown-body { line-height: 1.75; font-weight: 400; font-size: 16px; overflow-x: hidden; color: rg ...
- git reset回滚未提交的更改和覆盖分支
摘要:介绍git reset使用技巧:回滚本地所有未提交的更改,用一个分支覆盖另一个分支. git回滚本地所有未提交的更改可以使用命令 git reset,它的功能是强制覆盖本地文件到指定分支.切 ...
- J积分
J积分是断裂力学中表征裂纹尖端能量场的路径无关积分,具有两个核心功能: 积分路径为从裂纹下表面上任意一点出发,沿任一路径绕过裂纹尖端,最后终止于裂纹上表面的任意一点. J积分具有守恒性(与路径无关). ...
- 深入剖析开源AI阅读器项目Saga Reader基于大模型的文本转换与富文本渲染优化方案
引言 AI阅读器作为一种新型的内容消费工具,正在改变人们获取和处理信息的方式.本文将介绍Saga Reader项目中如何利用大型语言模型(LLM)进行网页内容抓取.智能优化和富文本渲染,特别是如何通过 ...
- ET框架运行(Mac环境)--服务端
1:环境 Mac电脑,安装.net cor2 2.2 ,JetBrains Rider编辑器,Unity环境(2018.4.28f1) 终端运行: dotnet --version 查看是否安装n ...
- Java 开发者无痛迁移到 Cursor 开启AI编程新生涯
习惯了IntelliJ IDEA的Java开发者,想尝试Cursor.Windsurf或Trae这类新兴的AI IDE,却担心迁移成本? 本文分享我的实战经验,帮助你高效切换开发环境,保留核心效率.效 ...
- JavaScript中如何遍历对象?
JavaScript中如何遍历对象? 今天来点稍微轻松的话题,如何在JavaScript中遍历对象,在平常的工作中,遍历对象是很常见的操作,javascript提供了多种方法来遍历对象的属性.这些方法 ...