SQL语句调优 - 索引上的数据检索方法
如果一张表上没有聚集索引,数据将会随机的顺序存放在表里。以dbo.SalesOrderDetail_TEST为例子。它的上面没有聚集索引,只有一个在SalesOrderID上的非聚集索引。所以表格的每一行记录,不会按照任何顺序,而是随意地存放在Hash里。这个时候如果用户想要找所有单价大于200的销售详细记录,要运行的语句会是:
SET STATISTICS PROFILE ON SELECT SalesOrderDetailID , Unitprice
FROM SalesOrderDetail_test
WHERE UnitPrice > 200
由于表在UnitPrice上没有索引,所以SQL SERVER不得不对这个表从头到尾扫描一遍,把所有UnitPrice的值大于200的记录一个一个挑出来。

从执行计划里可以清楚地看出来SQL SERVER 这里做了一个表扫描(下图),后面会详细介绍如何得到和分析执行计划

如果这个表上有聚集索引,事情会怎么样呢?还是刚才那张表做例子,先给它的值是唯一的字段 Unitprice上建立一个聚集索引。这样所有的数据都会按照聚集索引的顺序存储。
CREATE CLUSTERED INDEX SalesOrderDetail_TEST_CL ON dbo.SalesOrderDetail_test (SalesOrderDetailID)
可惜的是,查询条件Unitprice上没有索引,所以SQL SERVER还是要把所有记录都扫描一遍。如下图

与之前不同的是,执行计划里的表扫描变成了聚集索引扫描。因为在有聚集索引的表上,数据是直接存放在索引的最底层的,所以要扫描整个表格的数据,就是把整个聚集索引扫描一遍。在这里,聚集索引扫描就相当于一个表扫描。所要用的时间和资源与表扫描没有什么差别。并不是说这里有了”Index”这个字样,就说明执行计划比表扫描的有多大进步。当然反过来讲,如果看到”Table Scan”的字样,就说明这个表格上没有聚集索引。
现在在 UnitPrice 上面建一个非聚集索引,看看情况会有什么变化
CREATE NONCLUSTERED INDEX SalesOrderDetail_TEST_NCL_Price ON dbo.SalesOrderDetail_test (UnitPrice)
再次查询
SET STATISTICS PROFILE ON SELECT SalesOrderDetailID , Unitprice
FROM SalesOrderDetail_test
WHERE UnitPrice > 200
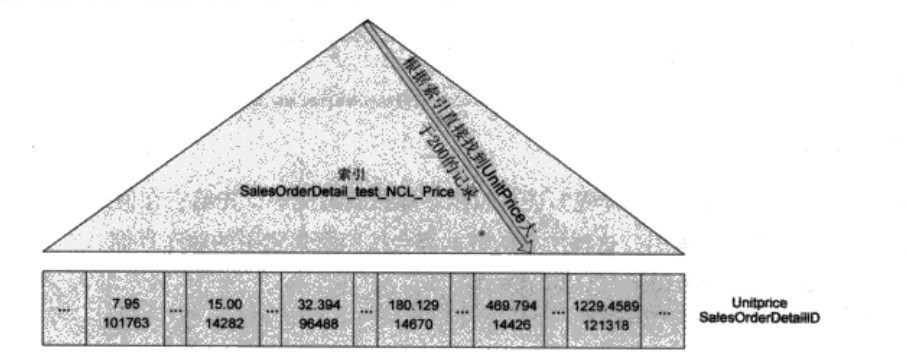

在非聚集索引里,会为每条记录存储一份非聚集索引索引键的值和一份聚集索引索引键的值(在没有聚集索引的表格里,是RID值)。所以在这里,每条记录都会有一份 SalesOrderDetailID和UnitPrice记录,按照UnitPrice的顺序存放。再查询,就会看到这次的SQL SERVER不是扫描整个表,会根据新建的索引直接找到符合的记录的值。
但是光用UnitPrice建立在上的索引不能告诉我们其它字段的值。如果在刚才那个查询里再增加几个字段返回,SQL SERVER 就要先在非聚集索引上找到所有UnitPrice大于200的记录,然后再根据SalesOrderDetailID的值找到存储在聚集索引上的详细数据。这个过程可以称为 “Bookmark Loopup”
SET STATISTICS PROFILE ON SELECT SalesOrderId,SalesOrderDetailID , Unitprice
FROM SalesOrderDetail_test with(index = SalesOrderDetail_TEST_NCL_Price)
WHERE UnitPrice > 200
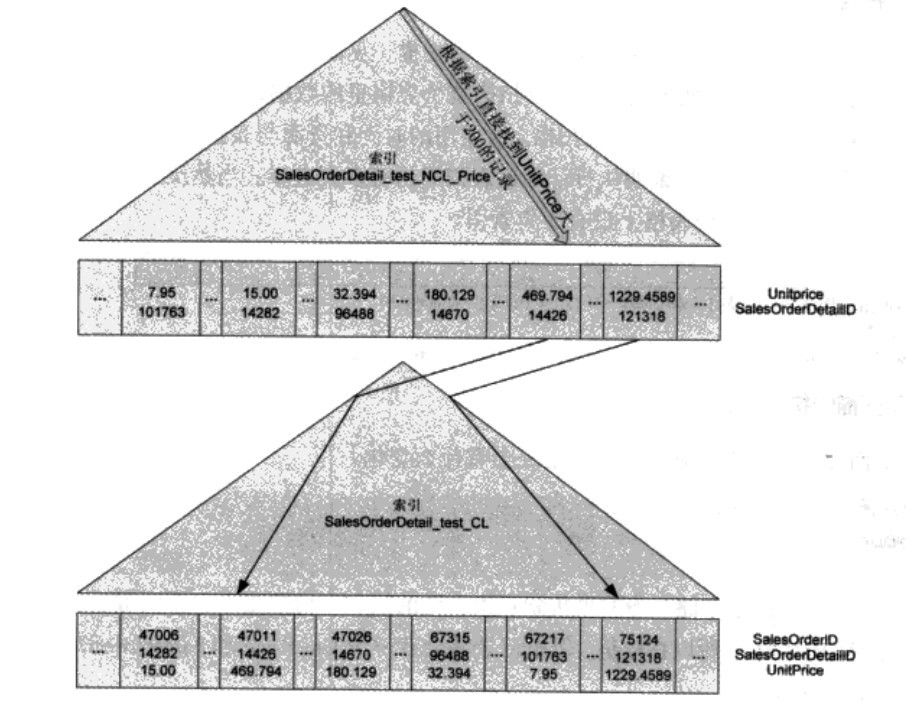
在SQL SERVER 2005以后,Bookmark Loopup 的动作用一个嵌套循环来完成。所以在执行计划里,可以看到SQL SERVR是先SEEK了非聚集索引,然后再用Clustered Index Seek 把需要的行找出来。这里的嵌套循环其实就是 Bookmark Loopup 如下图。

注:Bookmark Loopup就是聚集索引
在SQL SERVER里根据数据找寻目标的不同和方法不同。有下面几种情况。
|
结构 |
Scan |
Seek |
|
堆(没有聚集索引的表) |
Tablescan |
无 |
|
聚集索引 |
Clustered Index Scan |
Clustered Index Seek |
|
非聚集索引 |
Index Scan |
Index Seek |
如果在执行计划里看到这些动作,就应该能够知道SQL SERVER正在对哪种对象在做什么样的操作。表扫描表明正在处理的表没有聚集索引,SQL SERVER正在扫描整张表。聚集索引扫描表明SQL SERVER正在扫描一张有聚集索引的表,但是也会是整表扫描。Index Scan表明SQL SERVER正在扫描一个非聚集索引。由于非聚集索引上一般只会有一小部分字段,所以这些虽然也是扫描,但是代价会比整表扫描要小很多。Clustered Index Seek 和Index Seek会比Scan 说明SQL SERVER正在利用索引结果检索目标数据。如果结果集只占表格总数据量的一小部分,Seek 会比Scan便宜很多,索引就起到了提高性能的作用。
了解这些是为以后读懂执行计划做基础。水平有限,暂时为这些吧。大家可以多多交流。
下一次会写统计信息的东西,可能会稍多一些。上述一语句均为上一次发博客的脚本为例。
SQL语句调优 - 索引上的数据检索方法的更多相关文章
- SQL语句调优-基础知识准备
当确定了应用性能问题可以归结到某一个,或者几个耗时资源的语句后,对这些语句进行调优,就是数据库管理员或者数据库应用程序开发者当仁不让的职责了.语句调优是和数据库打交道的必备基本功之一. 当你面对一个“ ...
- MySQL千万级多表关联SQL语句调优
本文不涉及复杂的底层数据结构,通过explain解释SQL,并根据可能出现的情况,来做具体的优化. 需要优化的查询:使用explain 出现了Using temporary: ...
- MySQL百万级、千万级数据多表关联SQL语句调优
本文不涉及复杂的底层数据结构,通过explain解释SQL,并根据可能出现的情况,来做具体的优化,使百万级.千万级数据表关联查询第一页结果能在2秒内完成(真实业务告警系统优化结果).希望读者能够理解S ...
- SQL语句调优三板斧
改装有顺序------常开的爱车下手 你的系统中有成千上万的语句,那么优化语句从何入手呢 ? 当然是系统中运行最频繁,最核心的语句了.废话不多说,上例子: 这是一天的语句执行情况,里面柱状图表示的是对 ...
- SQL语句调优相关方法
SQL语句慢的原因:1,数据库表的统计信息不完整2,like查询估计不准确调优方法:1,查看表中数据的条数:2, explain analyze target_SQL;查看SQL执行计划:比较SQL总 ...
- SQL语句调优 - 统计信息的含义与作用及维护计算
统计信息的含义与作用 ...
- SQL语句调优汇总
1.插入数据的表或临时表,预先创建好表结构,能够加快执行速度 2.where 条件判断的字段以及连接查询的条件字段 都添加上索引 能够加快执行速度 3.尽量避免使用 like ,类似 like ...
- 【初学Java学习笔记】SQL语句调优
1, 对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 2,应尽量避免在 where 子句中对字段进行 null 值判断,创建表时NULL是默认 ...
- SQL 语句调优 where 条件 数据类型 临时表 索引
基本原则 避免全表扫描 建立索引 尽量避免向客户端返回大数据量,若数据量过大,应该考虑相应需求是否合理 尽量避免大事务操作,提高系统并发能力 使用基于游标的方法或临时表方法之前,应先寻找基于集的解决方 ...
随机推荐
- as的一些常见问题
assets文件的存放目录在”src/main/”目录下,和java.res文件夹平级: aidl文件需要单独在”src/main/”目录下新建一个文件夹,然后创建对应的包名,将aidl文件放在包名对 ...
- Dynamic CRM 2013学习笔记(十一)利用Javascript实现子表合计(汇总,求和)功能
我们经常有这样一种需求,子表里新加或修改一数值后,要马上在主表里把它们的和显示在主表上.如果用插件来实现,可以实现求和,但页面上还要刷新一下才能显示正确.这时就考虑到用JS来实现这一功能,并自动刷新页 ...
- SSH Secure Shell Client的windows客户端样式设置
SSH Secure Shell Client下载:http://pan.baidu.com/s/1dF2lDdf 其他工具(putty-0.67)下载:http://pan.baidu.com/s/ ...
- Swift 笔记
苹果官方文档 https://developer.apple.com CocoaChina帮助文档 http://www.cocoachina.com/special/swift/ 74个Swift标 ...
- 冲刺阶段day3
day3 项目进展 今天周三,我们五个人难得的一整个下午都能聚在一起.首先我们对昨天的成果一一地查看了一遍,并且坐出了修改.后面的时间则是做出 登录界面的窗体,完善了登录界面的代码,并且实现了其与数据 ...
- 多网卡的7种bond模式原理
多网卡的7种bond模式原理 Linux 多网卡绑定 网卡绑定mode共有七种(0~6) bond0.bond1.bond2.bond3.bond4.bond5.bond6 常用的有三种 mode=0 ...
- p4 是否能自动merge
总结: 1)如果在copy merge(-at)/auto merge(-am)后修改source branch,则可以自动被copy merge: 2)如果在manual merge后修改sou ...
- Spring - 初始化spring容器
2016.01.12 学习linux内核的过程中发现变相的提升了自己的工程能力.以前觉得spring这些东西很复杂麻烦.然而,学了linux内核再看这些东西,发现好简单. 学习spring首先就要学习 ...
- atitit.泛型编程总结最佳实践 vO99 java c++ c#.net php
atitit.泛型编程总结最佳实践 vO99 java c++ c#.net php \ 1. 泛型历史 1 由来 1 2. 泛型的机制编辑 1 机制 1 编译机制 2 3. 泛型方法定义1::前定义 ...
- atitit.获取北京时间CST 功能api总结 O7
atitit.获取北京时间CST 功能api总结 O7 1. 获取cst时间(北京时间)两布:1.抓取url timtstamp >>format 到cst 1 2. 设置本机时间 se ...