Fast RCNN 中的 Hard Negative Mining
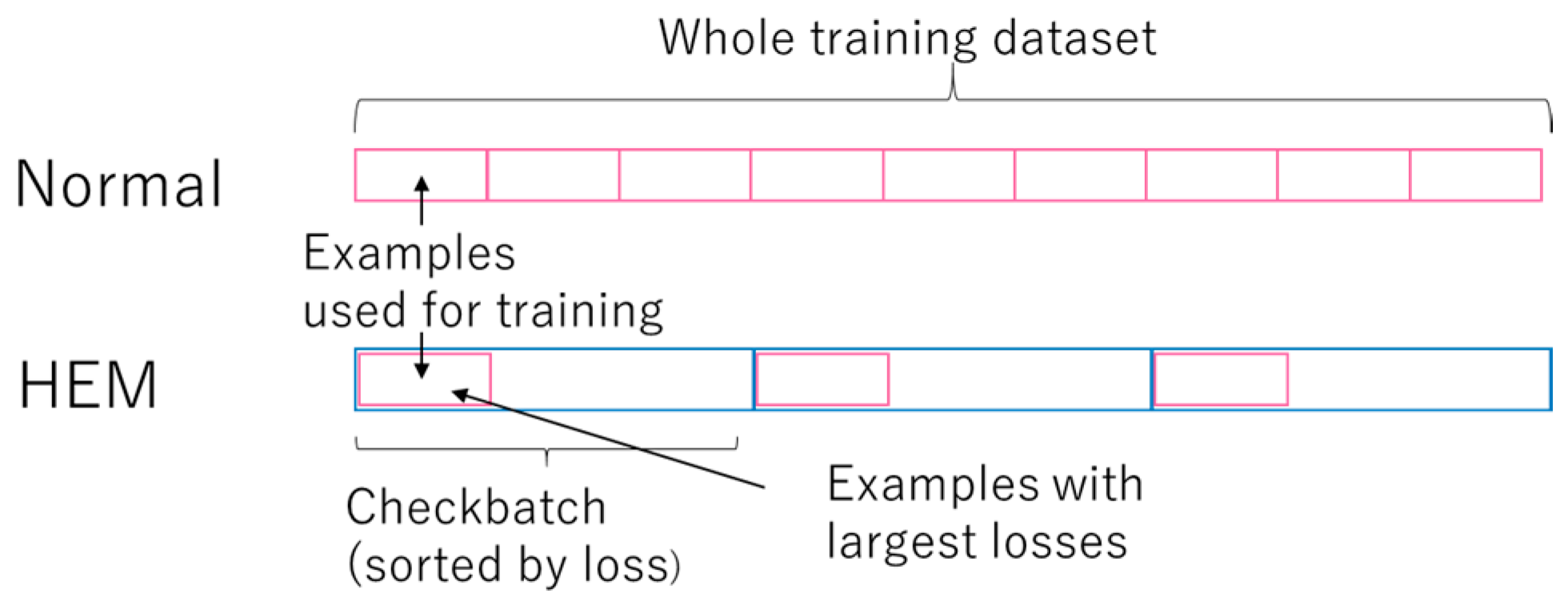 

Fast RCNN 中将与 groud truth 的 IoU 在 [0.1, 0.5) 之间标记为负例, [0, 0.1) 的 example 用于 hard negative mining. 在训练时一般输入为N=2张图片, 选择 128 个 RoI, 即每张图片 64 个 RoI. 每张图片, 按照1:3的比例来抽取的 RoI 的话, 要在负例中抽取 48 个, Fast RCNN 采用 random sampling 策略.
hard negative example
首先我们看看 hard negative example 是怎么定义?
negative,即负样本,hard 说明是难以正确分类的样本,也就是说在对负样本分类时候,loss比较大(label与prediction相差较大)的那些样本,也可以说是容易将负样本看成正样本的那些样本;
然后我们看看Fast RCNN 中的一些概念
对于目标检测, 我们会事先标记 ground truth,然后再算法中会生成一系列 proposal,这些 proposal有跟 ground truth重合的也有没重合的,那么 IoU 超过一定阈值(通常0.5)的则认定为是正样本,以下的则是负样本, 然后扔进网络中训练。 然而,这也许会出现一个问题那就是正样本的数量远远小于负样本,这样训练出来的分类器的效果总是有限的,会出现许多 false negative, 即预测为负例的正样本
一般来说, 负样本远多于正样本, 如 99% 的负样本, 那么算法不需要训练直接输出为负例, 准确率也会有 99%, 那么正负样本不均衡时, 预测偏向于样本多的一方, 对于目标检测而言, 负例多, 所以被预测为 false negative(即预测为负例的正样本) 可能性比较大.
我们为了避免这样一种情况, 需要使用策略使得正负样本尽量的均衡一点, Fast RCNN 采用的是随机抽样, 使得正负样本的比例为 1:3, 为何是1:3, 而不是1:1呢? 可能是正样本太少了, 如果 1:1 的话, 一张图片处理的 ROI 就太少了, 不能充分的利用 Roi Pooling 前一层的共享计算, 训练的效率就太低了, 但是负例比例也不能太高了, 否则算法会出现上面所说的 false negative 太多的现象, 选择 1:3 这个比例是算法在性能和效率上的一个折中考虑, 同时 OHEM(online hard example mining)一文中也提到负例比例设的太大, Fast RCNN 的 mAP将有很大的下降.
一些思考
Fast RCNN中选用 IoU < 0.1 作为hard negative的话,这样的 IoU 值对应的负样本一般不会被误判。我的理解下,不是应该把那些IoU值较高但是标记为负样本的样本更容易被误判吗?所以 hard negative mining 应该从这些样本里面(比如在Fast Rcnn中 IoU 在 [0.1, 0.5) 定义的负样本) 挑选不是更加合理吗?
我们可以先验的认为, 如果 Roi 里没有物体,全是背景,这时候分类器很容易正确分类成背景,这个就叫 easy negative, 如果roi里有二分之一个物体,标签仍是负样本,这时候分类器就容易把他看成正样本,这时候就是 hard negative。
确实, 不是一个框中背景和物体越混杂, 越难区分吗? 框中都基本没有物体特征, 不是很容易区分吗?
那么我认为 Fast RCNN 也正是这样做的, 为了解决正负样本不均衡的问题(负例太多了), 我们应该剔除掉一些容易分类负例, 那么与 ground truth 的 IOU 在 [0, 0.1)之间的由于包含物体的特征很少, 应该是很容易分类的, 也就是说是 easy negitive, 为了让算法能够更加有效, 也就是说让算法更加专注于 hard negitive examples, 我们认为 hard negitive examples 包含在[0.1, 0.5) 的可能性很大, 所以训练时, 我们就在[0.1, 0.5)区间做 random sampling, 选择负例.
我们先验的认为 IoU 在[0, 0.1)之内的是 easy example, 但是, [0, 0.1) 中包含 hard negitive examples 的可能性并非没有, 所以我们需要对其做 hard negitive mining, 找到其中的 hard negitive examples 用于训练网络.
按照常理来说 IOU 在[0, 0.1)之内 会被判定为真例的概率很小, 如果这种现象发生了, 可能对于我们训练网络有很大的帮助, 所以 Fast RCNN 会对与 ground truth 的 IoU 在 [0, 0.1)之内的是 example 做 hard negitive examples.
传统 hard example mining 流程
R-CNN 关于 hard negative mining 的部分引用了两篇论文, 下面两句话是摘自这两篇论文中
先要理解什么是 hard negative example?
1. Bootstrapping methods train a model with an initial subset of negative examples, and then collect negative examples that are incorrectly classified by this initial model to form a set of hard negatives. A new model is trained with the hard negative examples, and the process may be repeated a few times.
2. We use the following “bootstrap” strategy that incrementally selects only those “nonface” patterns with high utility value:
- Start with a small set of “nonface” examples in the training database.
- Train the MLP classifier with the current database of examples.
- Run the face detector on a sequence of random images. Collect all the “nonface” patterns that the current system wrongly classifies as “faces” (see Fig. 5b). Add these “nonface” patterns to the training database as new negative examples.
- Return to Step2
[17] P. Felzenszwalb, R. Girshick, D. McAllester, and D. Ramanan. Object detection with discriminatively trained part based models. TPAMI, 2010.
[37] K. Sung and T. Poggio. Example-based learning for viewbased human face detection. Technical Report A.I. Memo No. 1521, Massachussets Institute of Technology, 1994.
什么是 hard negative mining?
在 bootstrapping 方法中, 我们先用初始的正负样本(一般是正样本+与正样本同规模的负样本的一个子集)训练分类器, 然后再用训练出的分类器对样本进行分类, 把其中负样本中错误分类的那些样本(hard negative)放入负样本集合, 再继续训练分类器, 如此反复, 直到达到停止条件(比如分类器性能不再提升).
we expect these new examples to help steer the classifier away from its current mistakes.
hard negative 就是每次把那些顽固的棘手的错误, 再送回去继续练, 练到你的成绩不再提升为止. 这一个过程就叫做'hard negative mining'.
R-CNN的实现直接看代码:rcnn/rcnn_train.m at master · rbgirshick/rcnn Line:214开始的函数定义
作者:R2D2
链接:https://www.zhihu.com/question/46292829/answer235112564
来源:知乎, 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Fast RCNN 中的 Hard Negative Mining的更多相关文章
- Fast RCNN中RoI的映射关系
写在前面:下面讨论中Kernel Size为奇数,因为这样才能方便一致的确认Kernel中心. 在Fast RCNN中,为了大大减少计算量,没有进行2k次运算前向运算,而是进行了1次运算,然后在从po ...
- Fast R-CNN中的边框回归
前面对R-CNN系的目标检测方法进行了个总结,其中对目标的定位使用了边框回归,当时对这部分内容不是很理解,这里单独学习下. R-CNN中最后的边框回归层,以候选区域(Region proposal)为 ...
- Fast RCNN论文学习
Fast RCNN建立在以前使用深度卷积网络有效分类目标proposals的工作的基础上.使用了几个创新点来改善训练和测试的速度,同时还能增加检测的精确度.Fast RCNN训练VGG16网络的速度是 ...
- Fast RCNN 训练自己数据集 (1编译配置)
FastRCNN 训练自己数据集 (1编译配置) 转载请注明出处,楼燚(yì)航的blog,http://www.cnblogs.com/louyihang-loves-baiyan/ https:/ ...
- 目标检测算法之Fast R-CNN算法详解
在介绍Fast R-CNN之前我们先介绍一下SPP Net 一.SPP Net SPP:Spatial Pyramid Pooling(空间金字塔池化) 众所周知,CNN一般都含有卷积部分和全连接部分 ...
- 目标检测(三)Fast R-CNN
作者:Ross Girshick 该论文提出的目标检测算法Fast Region-based Convolutional Network(Fast R-CNN)能够single-stage训练,并且可 ...
- Fast R-CNN论文理解
论文地址:https://arxiv.org/pdf/1504.08083.pdf 翻译请移步:https://blog.csdn.net/ghw15221836342/article/details ...
- Fast R-CNN论文详解 - CSDN博客
废话不多说,上车吧,少年 paper链接:Fast R-CNN &创新点 规避R-CNN中冗余的特征提取操作,只对整张图像全区域进行一次特征提取: 用RoI pooling层取代最后一层max ...
- 读论文系列:Object Detection ICCV2015 Fast RCNN
Fast RCNN是对RCNN的性能优化版本,在VGG16上,Fast R-CNN训练速度是RCNN的9倍, 测试速度是RCNN213倍:训练速度是SPP-net的3倍,测试速度是SPP-net的3倍 ...
随机推荐
- CF452F Permutations/Luogu2757 等差子序列 树状数组、Hash
传送门--Luogu 传送门--Codeforces 如果存在长度\(>3\)的等差子序列,那么一定存在长度\(=3\)的等差子序列,所以我们只需要找长度为\(3\)的等差子序列.可以枚举等差子 ...
- 如何在Jupyter里以不同的运行模式使用Pyspark
假设你的环境已经安装好了以下东西,如何详细的安装它们不在本文的讨论范围之内 具体的可疑参考三分钟搞定jupyter和pyspark整合 anaconda2 findspark pyspark 这里多说 ...
- Linux配置外网访问mysql
stream{ upstream abc{ server 192.168.8.249:3306; } server{ listen 9211 ; prox ...
- PS制作黑暗墙面上的漂亮霓虹文字
一.用ps软件打开砖墙背景素材. 二.复制一层,混合模式改为“正片叠底”,不透明度50%. 三.新建色相/饱和度调整图层,设置如下.打造夜间的气氛. 四.新建一个空白图层,设置前景色黑色.背景色白色, ...
- 解决Jenkins邮件配置问题
最近要配置Jenkins邮箱,由于一直报如下错误,又没办法解决,所以想到了另外的办法发邮件. 我采用shell脚本执行python命令的方式来发邮件: #!/bin/bash cd /software ...
- linux rzsz(lrzsz)安装
lrzsz 官网入口:https://ohse.de/uwe/software/lrzsz.html lrzsz是一个unix通信套件提供的X,Y,和ZModem文件传输协议,可以用在windows与 ...
- Python学习之路——函数对象作用域名称空间
一.函数对象 # 函数名就是存放了函数的内存地址,存放了内存地址的变量都是对象,即 函数名 就是 函数对象 # 函数对象的应用 # 1 可以直接被引用 fn = cp_fn # 2 可以当作函数参数传 ...
- SpringMVC DispatcherServlet在配置Rest url-pattern的一点技巧
SpringMVC的Controller中已经有了@RequestMapping(value = "detail.do", method = RequestMethod.GET)的 ...
- Microsoft Visual Studio Tools for AI
https://www.visualstudio.com/zh-hans/downloads/ai-tools-vs/ 开发.调试和部署深度学习和 AI 解决方案 Visual Studio Tool ...
- [转载:Q1mi]Bootstrap和基于Bootstrap的登录验证示例
转载自:Q1mi Bootstrap介绍 Bootstrap是Twitter开源的基于HTML.CSS.JavaScript的前端框架. 它是为实现快速开发Web应用程序而设计的一套前端工具包. 它支 ...