hbase 概念
在hbase里面有几个通俗的名称会经常出现
1)Hregion = region
2)Hregionserver = regionserver
3)Hmaster = master
4)Hmamstore = memstore
5)Hfile = storeFile
1、什么是hbase?
1)它是基于稀疏的、分布式的、持久化的、多维有序映射,它基于行健、列簇、时间戳建立索引
2)构建在hdfs之上的分布式列式键值存储系统,hbase内部管理的文件存储在hdfs中。
2、有什么特点?
1)不介意数据类型,允许动态的、灵活的数据模型,并不限制存储数据的种类。因此他可以自如的存储结构化和半结构化的数据。
2)它不要sql语音,不强调数据之间的关系
3)它不允许跨行的事物,可以在一行的某一列存储一个整数,而在另一行的同一列存储一个字符串
4)它被设计在一个服务器集群上运行,而不是单台服务器。这就意味着是一种强大的、可扩展的数据使用方式。
3、列式存储
列式存储的基础:对于特定的查询,不是所有的值都是必须的。
1)以列为单位聚合数据,然后将列值顺序的存入磁盘
2)数据类型一致,数据特征相似,更利于压缩
3)大量降低系统I/O
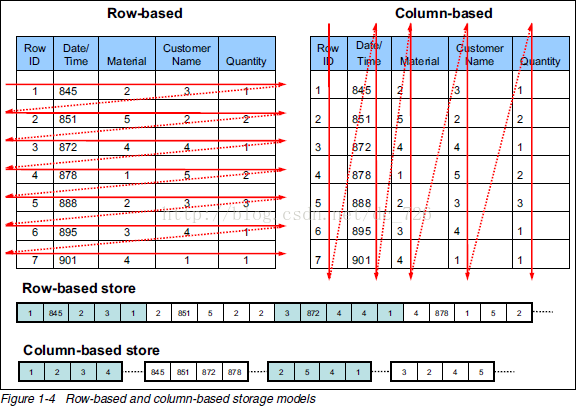
4、HBASE特性
1)容量巨大:单表可以有百亿行,百万列
2)面向列
3)稀疏性:空值不占用存储空间
4)扩展性:由hdfs决定,热扩展
5)高可用性:WAL和Replication机制;hdfs;zookeeper
6)共性能:LSM数据结构;Rowkey有序排列
7)无模式
8)数据多版本
9)数据类型单一
10)TTL
5、client
1)包含访问hbase的接口,并维护cache来加快对hbase的访问
2)通过rpc机制和master,region server通信
6、zookeeper
1)保证任何时候,集群中只有一个master
2)存储所有region的寻址入口
3)实时监控region server的上下线信息。并通知给master
4)存储hbase元数据信息
5)hbase中可以启动多个Hmaster,通过zookeeper的master election机制保证总有一个master运行
7、HMaster主要负责:table、region管理工作
1)管理用户对table的增删改查
2)管理regionserver的负载均衡,跳转region分布
3)在region分裂后,负责新region的分配
4)在regionserver死机后,负责失效regionserver上的region迁移
(由于master只维护表和region的元数据,而不参与表数据IO的过程,master下线仅导致所有元数据的修改被冻结(无法创建删除表,无法修改表的schema,无法进行region的负载均衡,无法处理region上下线,无法进行region的合并,唯一例外的是region的split可以正常进行,因为只有region server参与),表的数据读写还可以正常进行。
因此master下线短时间内对整个hbase集群没有影响。)
8、regionserver:主要负责响应用户I/O请求,向hdfs文件系统中读写数据
1)管理了一系列Hregion对象,每个Hregion对应了table中的region
2)Hregion由多个Hstore组成,每个Hstore对应了table中的一个column Family的存储
每个column Family其实就是一个集中的存储单位,简称Hstore
3)regionserver维护region,处理对这些region的IO请求
4)regionserver负责切分在运行过程中变得过大的region
5)regionserver提供行级锁
注:
1)Hregionserver:Hregion:Hstore = Column Family
2)Hstore:
- memStore:用户首先先写入MemStore。(flush操作)
- StoreFile:Hfile(compact合并,split操作)
3)hbase只有增加数据,所有更新和删除都是在compact过程中进行的。
4)用户写操作只要写入内存就可以立即返回,保证I/O高性能
5)同一台rs上的所有region共享相同的Hlog Files
6)每个update(或者说edit)都会被写到log,当通知客户端成功后,rs把数据再加载到内存中。
9、region是什么?
1)region按大小分割的,每个表开始只有一个region,随着数据增多,region不断增大,当增大到一个阀值的时候,region就会等分两个新的region,只会就会越来越多。
2)本质上是以行键排序的连续存储的区间
3)region最佳大小:1GB~2GB
4)regionserver:10~1000个region
5)不同的region分布到不同regionserver上
6)每个Hregion保存某段连续的数据,从开始主键(startRow)到结束主键(endRow),通过Hregion从Hadoop的分布式文件系统上数据
region虽然是分布存储的最小单位,但并不是存储的最小单位
1)一个region由一个或者多个store组成,每个store保存一个 columns family
2)每个store又由一个memstore和0个至多个storeFile组成
3)memstore存储在内存中,storeFile存储在hdfs上
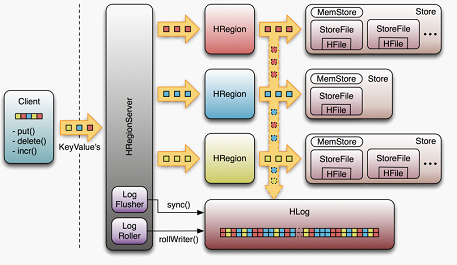
10、Hstore是什么?
Hstore:Hstore存储是Hbase存储的核心,由memstore和storeFile组成。
1)Hmemcache:内存中的缓存,保存着最近更新的数据,如果Hmemcache没有数据,将从hstores获取磁盘上的数据,每个列簇会有一个hstore集合,每个集合包含多个Hstorefiles文件(b+数结构)
2)Hregion定期调用flushcache()缓存里的内容写入到文件中,每次调用产生一个新的文件Hstorefile文件,从一个hstore或数据会访问所有的Hstotefile,很耗时,hstore.compact可以完成小文件到达文件的合并
11、Hlog是什么?
磁盘上的操作记录文件,记录这所有的更新操作,数据写入Hlog后,commit()调用才会返回给客户端。
数据的更新操作最先被记录在Hmemcache和Hlog中
12、Row key
行键,table的主键,Table中的记录按照Row key排序。类型为Byte array
1)不宜过长
2)分布均匀
13、Column Family
列族,table水平方向有一个或者多个Column Family组成,一个Column Family中可以由任意多个Column组成
14、Cloumn
列 格式为:familyName:columnName
列名称是编码在cell中的
不同的cell可以拥有不同的列
15、Version Number
版本号。默认值是时间戳。类型为long
16、Value(Cell)
具体的值。类型为Byte array
hbase 概念的更多相关文章
- HBase概念及表格设计
HBase概念及表格设计 1. 概述(扯淡~) HBase是一帮家伙看了Google发布的一片名为“BigTable”的论文以后,犹如醍醐灌顶,进而“山寨”出来的一套系统. 由此可见: 1. 几乎所有 ...
- HBASE概念补充
HBASE概念补充 HBase的工作方式: hbase中的表在行的方向上分隔为多个HRegion,分散在不同的RegionServer中 这样做的目的是在查询时可以将工作量分布到多个RegionSer ...
- hbase概念
1. 概述(扯淡~) HBase是一帮家伙看了Google发布的一片名为“BigTable”的论文以后,犹如醍醐灌顶,进而“山寨”出来的一套系统. 由此可见: 1. 几乎所有的HBase中的理念,都可 ...
- Hbase概念原理扫盲
一.Hbase简介 1.什么是Hbase Hbase的原型是google的BigTable论文,收到了该论文思想的启发,目前作为hadoop的子项目来开发维护,用于支持结构化的数据存储. Hbase是 ...
- HBase概念入门
HBase简介 HBase基于Google的BigTable论文而来,是一个分布式海量列式非关系型数据库系统,可以提供大规模数据集的实时随机读写. 下面通过一个小场景认识HBase存储.同样的一个数据 ...
- hbase概念解析
hbase是一种nosql数据库.是一个高可靠,高性能,面向列,可伸缩,实时读取的分布式数据库. hbase一般由行键,时间戳,列族,列,表格单元,行组成. 行一般由一个行键和一个或多个具有关联关系值 ...
- HBase 概念视图
- HBASE学习笔记-初步印象
HBASE概念: HBASE是一个分布式架构的数据库,通过对数据进行多层的分块打散储存.从而改写传统数据库的储存能力和读取速度. HBASE的集群服务器: HBASE的集群主要分为Zookeeper集 ...
- 分布式数据库 HBase
原文地址:http://www.oschina.net/p/hbase/ HBase 概念 HBase – Hadoop Database,是一个高可靠性.高性能.面向列.可伸缩的分布式存储系统,利用 ...
随机推荐
- 5、Docker容器网络
使用Linux进行IP层网络管理的指 http://linux-ip.net/html/ # yum install iproute http://linux-ip.net/html/tool ...
- yaf框架在windows上的环境配置和安装
1.首先检测你的php版本 如图:Architecture:×86和thread Safety:disabled 这个有什么用呢? 2.进入这个网站 tgz是linux下的扩展包,windows下点D ...
- 肿瘤数据库除了TCGA,还有TCIA--转载
TCIA就是基于TCGA数据开发的,不同的是TCIA只提供了20个癌种的免疫数据分析. 看网站首页的介绍就知道,这个数据库主要是根据TCGA的二代测序数据开发出来的.这里的20个癌种,点击每个柱子进去 ...
- Centos 6.6 安装
说明:使用VMware进行安装.安装VMware软件及创建虚拟机步骤省略,从正式安装开始. 1.开启虚拟机后稍等,直到出现如下界面: 2.选择第一项,进入光盘介质检查界面. 一般直接跳过点击skip, ...
- VirtualBox中CentOS7.2 网络配置(固定IP+联网)
一.前言 用虚拟机装Linux系统时,经常会出现一些问题.比如:从主机到虚拟机之间网络不通:虚拟机中无法联网:虚拟机中的IP地址不固定.为了解决这些问题,我曾花了不少时间.在此,记下填坑方法. 二.环 ...
- Android从启动到程序运行整个过程的整理
1Android是基于Linux的一个操作系统,它可以分为五层,下面是它的层次架构图,可以记一下,因为后面应该会总结到SystemServer这些Application Framework层的东西 A ...
- caffe win添加新层
1.编写.h和.cpp .cu文件 将.hpp文件放到路径caffe-windows\caffe-master\include\caffe\layers下 将.cpp文件和.cu放到路径caffe-w ...
- nodemanager 无法启动报错“doesn't satisfy minimum allocations”
在启动nodemanager节点nodemanager时候报错 2019-03-29 14:15:44,648 INFO org.apache.hadoop.yarn.server.nodemanag ...
- [luogu P2633] Count on a tree
[luogu P2633] Count on a tree 题目描述 给定一棵N个节点的树,每个点有一个权值,对于M个询问(u,v,k),你需要回答u xor lastans和v这两个节点间第K小的点 ...
- spoj1026Favorite Dice
题意翻译 一个n面的骰子,求期望掷几次能使得每一面都被掷到. 题目描述 BuggyD loves to carry his favorite die around. Perhaps you wonde ...