4.BN推导
参考博客:https://www.cnblogs.com/guoyaohua/p/8724433.html
参考知乎:https://www.zhihu.com/question/38102762/answer/85238569
1.BN的原理
我们知道,神经网络在训练的时候,如果对图像做白化(即通过变换将数据变成均值为0,方差为1)的话,训练效果就会好。那么BN其实就是做了一个推广,它对隐层的输出也做了归一化的操作。那么为什么归一化操作能够使得训练效果好那么多呢?机器学习领域有个很重要的假设:IID独立同分布假设,就是假设训练数据和测试数据是满足相同分布的,这是通过训练数据获得的模型能够在测试集获得好的效果的一个基本保障。假设我们用批量梯度下降法来训练,在没有BN层之前,你对输入做了白化,对于每一个batch在喂到神经网络之前分布是一致的,但是通过每一个隐层的激活函数后,每一个batch的隐层输出分布可能就有很大差异了,而且随着层数的加深,这种差异也会越来越大。
2.BN的公式表达

下面具体解释一下上述公式的意思:前三步的作用就是把输入数据分布归一化成一个正态分布,这样一来,每一个隐藏层未经激活的输出值经过激活函数之后大部分都落在了激活函数的线性区域(参考sigmoid函数),但是由于神经网络强大的表达能力就是基于它的高度非线性化,如果这种特性失去了,网络在再深也没有用了。原作者采取了一个办法,就是第四步,这个步骤其实就是将正太分布进行一个偏移(scale and shift),从某种意义上来说,就是在线性和非线性之间做一个权衡,而这个偏移的参数gamma和bata是神经网络在训练时学出来的。另外提一下,公式3中的eplison应该是一个很小的正数,为了防止分母为0,tensorflow的源码是这样解释的。
3.BN的参数推导
现在我们看下,如何通过链式法则更新BN中的参数(其中 就相当于之前的传播误差
就相当于之前的传播误差 ):
):

4.BN在实际运用中需要注意的问题 (此处参考博客:https://blog.csdn.net/xys430381_1/article/details/85141702)
当我们的测试样本前向传导的时候,上面的均值u、标准差σ要哪里来?其实网络一旦训练完毕,参数都是固定的,这个时候即使是每批训练样本进入网络,那么BN层计算的均值u、和标准差σ都是固定不变的。我们可以采用这些训练阶段的均值u、标准差σ来作为测试样本所需要的均值、标准差,于是最后测试阶段的u和σ计算公式如下:
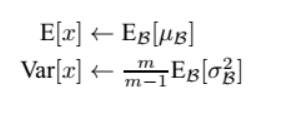
上面简单理解就是:对于均值来说直接计算所有batch u值的平均值;然后对于标准偏差采用每个batch σB的无偏估计。最后测试阶段,BN的使用公式就是:
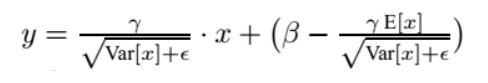
也就是说, 在test的时候,BN用的是固定的mean和var, 而这个固定的mean和var是通过训练过程中对mean和var进行滑动平均得到的,被称之为moving_mean和moving_var。在实际操作中,每次训练时应当更新一下moving_mean和moving_var,然后把BN层的这些参数保存下来,留作测试和预测时使用。(如果不太了解滑动平均可以参考博文:https://blog.csdn.net/qq_18888869/article/details/83009504)
5.BN的好处(此处参考知乎:https://www.zhihu.com/question/38102762中龙鹏-言有三的回答)
(1) 减轻了对参数初始化的依赖,这是利于调参的朋友们的。
(2) 训练更快,可以使用更高的学习率。
(3) BN一定程度上增加了泛化能力,dropout等技术可以去掉。
6.BN的缺陷
batch normalization依赖于batch的大小,当batch值很小时,计算的均值和方差不稳定。研究表明对于ResNet类模型在ImageNet数据集上,batch从16降低到8时开始有非常明显的性能下降,在训练过程中计算的均值和方差不准确,而在测试的时候使用的就是训练过程中保持下来的均值和方差。
由于这一个特性,导致batch normalization不适合以下的几种场景。
(1)batch非常小,比如训练资源有限无法应用较大的batch,也比如在线学习等使用单例进行模型参数更新的场景。
(2)rnn,因为它是一个动态的网络结构,同一个batch中训练实例有长有短,导致每一个时间步长必须维持各自的统计量,这使得BN并不能正确的使用。在rnn中,对bn进行改进也非常的困难。不过,困难并不意味着没人做,事实上现在仍然可以使用的,不过这超出了咱们初识境的学习范围。
4.BN推导的更多相关文章
- HDU 5734 Acperience (推导)
Acperience 题目链接: http://acm.hdu.edu.cn/showproblem.php?pid=5734 Description Deep neural networks (DN ...
- 卷积层和BN层融合
常规的神经网络连接结构如下  当网络训练完成, 在推导的时候为了加速运算, 通常将卷积层和 batch-norm 层融合, 原理如下 \[ \begin{align*} y_{conv} & ...
- BN讲解(转载)
本文转载自:http://blog.csdn.net/shuzfan/article/details/50723877 本次所讲的内容为Batch Normalization,简称BN,来源于< ...
- ch5-处理数据,抽取-整理-推导
场景:教练kelly有4个选手James\Sarah\Julie\Mikey,他们每跑600米,教练就会计时并把时间记录在计算机的一个文件中,总共4个文件:James.txt\Sarah.txt\Ju ...
- AES128加密-S盒和逆S盒构造推导及代码实现
文档引用了<密码编码学与网络安全--原理和实践>里边的推导过程,如有不妥,请与我联系修改. 文档<FIPS 197>高级加密标准AES,里边有个S盒构造,涉及到了数论和有限域的 ...
- Caffe Batch Normalization推导
Caffe BatchNormalization 推导 总所周知,BatchNormalization通过对数据分布进行归一化处理,从而使得网络的训练能够快速并简单,在一定程度上还能防止网络的过拟合, ...
- zz详解深度学习中的Normalization,BN/LN/WN
详解深度学习中的Normalization,BN/LN/WN 讲得是相当之透彻清晰了 深度神经网络模型训练之难众所周知,其中一个重要的现象就是 Internal Covariate Shift. Ba ...
- python实现贝叶斯网络的概率推导(Probabilistic Inference)
写在前面 这是HIT2019人工智能实验三,由于时间紧张,代码没有进行任何优化,实验算法仅供参考. 实验要求 实现贝叶斯网络的概率推导(Probabilistic Inference) 具体实验指导书 ...
- opencv——PCA(主要成分分析)数学原理推导
引言: 最近一直在学习主成分分析(PCA),所以想把最近学的一点知识整理一下,如果有不对的还请大家帮忙指正,共同学习. 首先我们知道当数据维度太大时,我们通常需要进行降维处理,降维处理的方式有很多种, ...
随机推荐
- vs2005设置打开文件和保存文件编码
一般vs2005打开文件时会自动侦测文件编码,自动以相应的编码格式打开.但是如果不认识的编码,就会出现乱码. Set VS2005 to use without BOM UTF-8 encoding ...
- jupyter nootbook本地使用指南
本地文件读入jupyter notebook 在文件夹内,shift+鼠标右键,出现菜单中选择“”在此处打开命令窗口“”,输入jupyter notebook, 可以把本地文件读入jupyter.
- react项目后台及上线步骤
应同学要求,本人将react项目创建后台及上线流程书写如下: 前端部分 略…… 后台部分 (注:这里的后台是用的nodejs搭建的,使用的是express框架+ejs模板) 首先通过express快速 ...
- Apicloud学习第四天
apicloud存储机制,添加和获取存储的数据 $api.setStorage('currentCity', cityList[i_]); $api.getStorage('currentCity') ...
- Python——使用高德API获取指定城指定类别POI并实现XLSX文件合并
# 以下内容为原创,转载请注明出处 1 import xlrd # 读xlsx import xlsxwriter # 写xlsx import urllib.request # url请求,Pyth ...
- ES2015 中的函数式Mixin
原文链接:http://raganwald.com/2015/06/17/functional-mixins.html 在“原型即对象”中,我们看到可以对原型使用 Object.assign 来模拟 ...
- java使用redis数据库
1.安装 Redis 支持 32 位和 64 位,根据实际情况选择不同的安装版本. 安装完成后打开命令提示窗口,切换到redis安装目录,启动redis客户端, redis-cli命令启动redis客 ...
- iOS 图片9切
UIImageView *svRect; UIImage *backgroundImage = [UIImage imageNamed:@"bg.png"]; background ...
- 读spring源码(三)-ClassPathXmlApplicationContext-getBean
这次主要看了下bean的生成过程,发现个画时序图很好用的软件plantuml,充分发挥程序员的能力,能用代码解决的别叨叨别的
- 利用C# 窗体设计 写一个抽奖游戏
老师布置了一个任务,要求我们做一个抽奖游戏,以下是我个人制作的一个作品与写项目的过程. 我们用到了8个pictureBox控件和一个button,设置好大小,并且编排成一个九宫个形状 添加窗体的背景图 ...