Elasticsearch单机双节点集群部署实战
一、安装第一个ElasticSearch(主节点)
1、创建es用户,启动es不能使用root用户
useradd es
passwd es12
root用户进入/home/es目录下
2、获取ElasticSearch安装包
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.1.2.tar.gz
3、解压、改名(方便集群时区别另一个ES)
tar xf elasticsearch-6.1.2.tar.gz
mv elasticsearch-6.1.2.tar.gz elasticsearch-node212
4、修改配置文件
vi elasticsearch-node2/config/elasticsearch.yml1
修改内容如下:
cluster.name: my-application 各节点此名称必须一致
node.name: node-2 节点名称,不能与其他节点相同
network.host: ***.***.***.*** 自己的服务器IP
http.port: **** 访问端口
transport.tcp.port: **** 集群各节点间的通讯端口
discovery.zen.ping.unicast.hosts: ["主节点IP:通讯端口","辅节点IP:通讯端口"] 123456
文件最后追加以下内容,以便连接head显示健康值(注意每行代码前面不要有空格)
http.cors.enabled: true
http.cors.allow-origin: "*"12
5、启动
sh elasticsearch-node2/bin/elasticsearch1
[2018-01-24T15:36:41,990][INFO ][o.e.n.Node ] [KMyyO-3] started
[2018-01-24T15:36:41,997][INFO ][o.e.g.GatewayService ] [KMyyO-3] recovered [0] indices into cluster_state12
启动成功,浏览器中输入 IP:访问端口
网页显示以下内容,说明部署成功
{
"name" : "node-2",
"cluster_name" : "my-application",
"cluster_uuid" : "j2aJ7CsRSuSo0G8Bgky2Ww",
"version" : {
"number" : "6.1.2",
"build_hash" : "5b1fea5",
"build_date" : "2018-01-10T02:35:59.208Z",
"build_snapshot" : false,
"lucene_version" : "7.1.0",
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}123456789101112131415
6、报错及其处理
【类型一】
Caused by: java.lang.RuntimeException: can not run elasticsearch as root1
该问题是因为运行es不能使用root用户,因此要切换es用户再次启动
chown -R es:es elasticsearch-node2/
su - es
sh elasticsearch-node2/bin/elasticsearch123
【类型二】
max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]1
解决方法,换回root用户,修改配置文件
vi /etc/security/limits.conf
#在最后面追加下面内容
es hard nofile 65536
es soft nofile 655361234
【类型三】
max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]1
解决方法,换回root用户,修改配置文件
vi /etc/sysctl.conf
#在最后面追加下面内容
vm.max_map_count=655360
#执行命令:
sysctl -p12345
二、安装第二个ElasticSearch(辅节点)
安装方法与第一个一致,注意修改配置文件
root用户进入/home/es目录下
1、解压、改名
tar xf elasticsearch-6.1.2.tar.gz
mv elasticsearch-6.1.2.tar.gz elasticsearch-node312
2、修改配置文件
vi elasticsearch-node3/config/elasticsearch.yml1
修改内容如下:
cluster.name: my-application 各节点此名称必须一致
node.name: node-3 节点名称,不能与其他节点相同
network.host: ***.***.***.*** 自己的服务器IP
http.port: **** 访问端口(注意不要与第一个端口重复)
transport.tcp.port: **** 集群各节点间的通讯端口(注意不要与第一个端口重复)
discovery.zen.ping.unicast.hosts: ["主节点IP:通讯端口","辅节点IP:通讯端口"]123456
文件最后同样追加下面代码
http.cors.enabled: true
http.cors.allow-origin: "*"12
3.启动
sh elasticsearch-node3/bin/elasticsearch1
浏览器,浏览器中输入 IP:访问端口
网页显示以下内容,说明第二个部署成功
{
"name" : "node-3",
"cluster_name" : "my-application",
"cluster_uuid" : "j2aJ7CsRSuSo0G8Bgky2Ww",
"version" : {
"number" : "6.1.2",
"build_hash" : "5b1fea5",
"build_date" : "2018-01-10T02:35:59.208Z",
"build_snapshot" : false,
"lucene_version" : "7.1.0",
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}123456789101112131415
三、安装Elasticsearch-head插件
1、安装head插件之前需要安装node.js
curl -sL https://rpm.nodesource.com/setup_8.x | bash -
yum install -y nodejs12
安装完成后执行命令查看node与npm版本
[root@host]# node -v
v8.12.0
[root@host]# npm -v
6.4.1
12345
2、从git获取head插件
wget https://github.com/mobz/elasticsearch-head/archive/master.zip1
3、解压安装包(可以改名,方便操作)
unzip master.zip
mv elasticsearch-head-master/ head12
4、修改配置文件
vi head/Gruntfile.js1
更改head端口号
connect: {
server: {
options: {
port: ****, 改为head访问端口
base: '.',
keepalive: true
}
}
}
12345678910
vi head/_site/app.js 1
更改head链接地址
init: function(parent) {
this._super();
this.prefs = services.Preferences.instance();
this.base_uri = this.config.base_uri || this.prefs.get("app-base_uri") || "http://主节点IP:访问端口";
12345
5、启动head
nohup npm run start > ../head.log 2>&1 &1
6、浏览器登录head
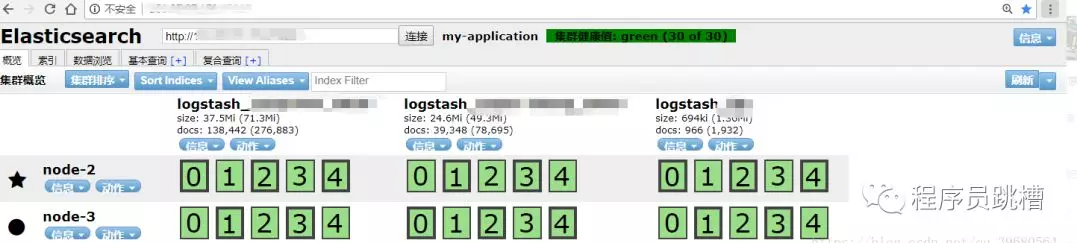
URL输入服务器IP:head访问端口
链接地址输如主节点的访问地址
7、安装head常见错误
【类型一】启动成功,但是网页不能访问
解决方法
关闭服务器防火墙
service iptables stop【类型二】集群健康值未连接
在elasticsearch.yml里追加下列代码(注意代码前面不要有空格)
http.cors.enabled: truehttp.cors.allow-origin: "*"问:为什么es节点用node2、node3?
答:因为之前用node1搭建了一套未集群的ES,所以后面集群就用2和3了。
---------------------------------------------
推荐阅读:
Elasticsearch单机双节点集群部署实战的更多相关文章
- Windows下ELK环境搭建(单机多节点集群部署)
1.背景 日志主要包括系统日志.应用程序日志和安全日志.系统运维和开发人员可以通过日志了解服务器软硬件信息.检查配置过程中的错误及错误发生的原因.经常分析日志可以了解服务器的负荷,性能安全性,从而及时 ...
- (十)RabbitMQ消息队列-高可用集群部署实战
原文:(十)RabbitMQ消息队列-高可用集群部署实战 前几章讲到RabbitMQ单主机模式的搭建和使用,我们在实际生产环境中出于对性能还有可用性的考虑会采用集群的模式来部署RabbitMQ. Ra ...
- elasticSearch数据库、skywalking集群部署
Centos6上面安装elasticsearc数据库的集群 安装的是6.3.2版本,安装之前首先要先安装jdk1.8版本 安装之前首先需要关闭防火墙 Centos6 sudo service ipta ...
- RabbitMQ消息队列(十)-高可用集群部署实战
前几章讲到RabbitMQ单主机模式的搭建和使用,我们在实际生产环境中出于对性能还有可用性的考虑会采用集群的模式来部署RabbitMQ. RabbitMQ集群基本概念 Rabbit模式大概分为以下三种 ...
- RabbitMQ-rabbitmqctl多机多节点和单机多节点集群搭建(五)
准备 1.准备3台物理机 我这里通过本地机和2台虚拟模拟我是mac通过(Parallel Desktop 实现) 2.按照签名的liux安装步骤在3台机器都安装rabiitMq 3.将任意一节点的co ...
- elasticsearch + kibana + x-pack + logstash_集群部署安装
elasticsearch 部分总体描述: 1.elasticsearch 的概念及特点.概念:elasticsearch 是一个基于 lucene 的搜索服务器.lucene 是全文搜索的一个框架. ...
- k8s, etcd 多节点集群部署问题排查记录
目录 文章目录 目录 部署环境 1. etcd 集群启动失败 解决 2. etcd 健康状态检查失败 解决 3. kube-apiserver 启动失败 解决 4. kubelet 启动失败 解决 5 ...
- Docker | redis集群部署实战
前面已经简单熟悉过redis的下载安装使用,今天接着部署redis集群(cluster),简单体会一下redis集群的高可用特性. 环境准备 Redis是C语言开发,安装Redis需要先将Redis的 ...
- ElasticSearch 在3节点集群的启动
ElasticSearch的启动分前台和后台启动 先介绍前台启动: 先在master节点上启动 可以看到已经启动了 同时在slave1.slave2节点上也启动 可以看到都已经启动了! 在浏览器分别打 ...
随机推荐
- ES5 常用 语法(object Arrary 函数绑定this指向)
ES object 扩展 ES object 扩展1. <!DOCTYPE html> <html> <head> <link rel="short ...
- ora-01033 oracle initialization or
这次出现这个问题是源于错删了 DBF文件. 解决方案如下: 1.打开SQL Plus 最后把你删掉的那个文件的表空间删掉就好了
- muse-ui底部导航自定义图标和字体颜色
最近在鼓捣用vue.js进行混合APP开发,遍寻许久终于找到muse-ui这款支持vue的轻量级UI框架,竟还支持按需引入,甚合萝卜意! 底部导航的点击波纹特效也是让我无比惊喜,然而自定义图标和字体颜 ...
- [Swift]LeetCode1 .两数之和 | Two Sum
Given an array of integers, return indices of the two numbers such that they add up to a specific ta ...
- [Swift]LeetCode151. 翻转字符串里的单词 | Reverse Words in a String
Given an input string, reverse the string word by word. Example: Input: "the sky is blue", ...
- [Swift]LeetCode496. 下一个更大元素 I | Next Greater Element I
You are given two arrays (without duplicates) nums1 and nums2 where nums1’s elements are subset of n ...
- 基于IPV6的数据包分析(更新拓扑加入了linux主机和抓取133icmp包)(第十三组)
1.拓扑图 2.配置ipv6地址,在拓扑图上对应位置标有对应网段,所在网段的端口按照网段配置,下图以r4为例 3.配置路由表,由于静态路由还要敲ip很麻烦所以使用ospf协议,下图为ospf配置以r5 ...
- 如何实现登录、URL和页面按钮的访问控制?
用户权限管理一般是对用户页面.按钮的访问权限管理.Shiro框架是一个强大且易用的Java安全框架,执行身份验证.授权.密码和会话管理,对于Shiro的介绍这里就不多说.本篇博客主要是了解Shiro的 ...
- nginx系列 2 概述
一. nginx功能概述 nginx 提供的基本功能服务归纳为:基本HTTP服务.高级HTTTP服务.邮件代理服务.TCP/UDP 代理服务等四大类. (1) Nginx提供基本HTTP服务,可以作为 ...
- C#版[击败100.00%的提交] - Leetcode 6. Z字形变换 - 题解
版权声明: 本文为博主Bravo Yeung(知乎UserName同名)的原创文章,欲转载请先私信获博主允许,转载时请附上网址 http://blog.csdn.net/lzuacm. C#版 - L ...