python全栈开发中级班全程笔记(第二模块、第三章)(员工信息增删改查作业讲解)
python全栈开发中级班全程笔记
第三章:员工信息增删改查作业代码
作业要求:
员工增删改查表
用代码实现一个简单的员工信息增删改查表
需求: 1、支持模糊查询,
(1、find name ,age form staff_table where age > 22
(查找 staff_fable (文件)内所有 age > 22 的name 和 age全部打印)
(2、find * from staff_table where dept = "IT"
(查找所有部门是 IT的所有列打印出来*代表所有)
(3、find * from staff_table where enroll_date like "2013"
(查找所有 enroll_date (登记日期)为 2013的序列并打印) 2、可创建员工信息记录,以 phone 做唯一键(既不允许表内有手机号重复的情况),staff_id 需自增
语法格式为:add staff Alex Li,25,134435344,IT,2015-10-29 3、可删除指定员工信息记录,输入员工id 即可删除
语法格式:del staff 3 4、可修改员工信息 语法如下:
UPDATE staff_table SET dept = "Market" WHERE dept = "IT"(把部门是 IT 的全部更改成 Market)
UPDATE staff_table SET age = 25 WHERE name = "Alex Li" (把 name = Alex Li 的年龄改成 25 )
以上每条语句执行完毕后,要显示影响了多少条记录,(比如查询,要显示查询出多少条、修改要显示修改多少条
整体思路图:
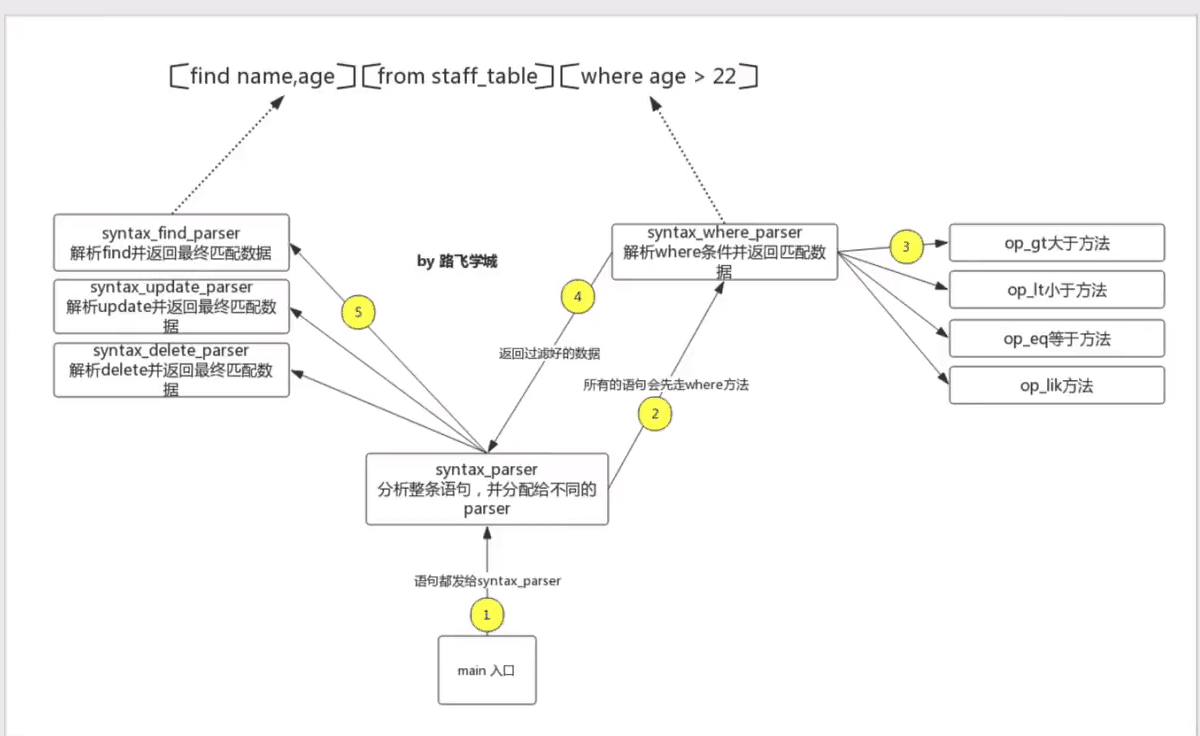
代码奉上:
# -*- coding:utf-8 -*-
from tabulate import tabulate
import os FILE_NAME = "staff_table"
OPTION = ["id", "name", "age", "phone", "dept", "enroll_date"] # 加载员工信息表并转成指定格式
def info(file_name):
data = {}
for i in OPTION:
data[i] = []
with open(file_name, "r", encoding="utf-8") as f:
for line in f:
staff_id, name, age, phone, dept, enroll_date = line.strip().split(",")
data["id"].append(staff_id)
data["name"].append(name)
data["age"].append(age)
data["phone"].append(phone)
data["dept"].append(dept)
data["enroll_date"].append(enroll_date)
return data INFO_DATA = info(FILE_NAME) # 程序启动后就执行 # 把修改的数据写入硬盘
def write_info():
f = open("%s" % FILE_NAME, "w", encoding="utf-8")
for index, staff_tb in enumerate(INFO_DATA["id"]):
res = []
for col in OPTION:
res.append(INFO_DATA[col][index])
f.write(",".join(res)+"\n") # 报错字体颜色
def print_log(calc, log_type = "info"):
if log_type == "info":
print("\033[33;1m%s\033[0m" % calc)
elif log_type == "error":
print("\033[31;1m%s\033[0m" % calc) # 自动删除函数
def del_info(del_name, del_term):
for index, del_loop in enumerate(INFO_DATA[del_name]):
if del_loop == del_term:
for del_key in OPTION:
del INFO_DATA[del_key][index]
write_info()
return
else:
print_log("没有此序号或未检测到关键字[id=NO.]", "error") # 解析条件并返回值
def less(field, term):
result = []
for index, cont in enumerate(INFO_DATA[field]):
if float(cont) > float(term):
whole_article = []
for cont_name in OPTION:
whole_article.append(INFO_DATA[cont_name][index])
result.append(whole_article)
return result def greater(field, term):
result = []
for index, cont in enumerate(INFO_DATA[field]):
if float(cont) < float(term):
whole_article = []
for cont_name in OPTION:
whole_article.append(INFO_DATA[cont_name][index])
result.append(whole_article)
return result def equal(field, term):
result = []
for index, cont in enumerate(INFO_DATA[field]):
if cont == term:
whole_article = []
for cont_name in OPTION:
whole_article.append(INFO_DATA[cont_name][index])
result.append(whole_article)
return result def like(field, term):
result = []
for index, cont in enumerate(INFO_DATA[field]):
if term in cont:
whole_article = []
for cont_name in OPTION:
whole_article.append(INFO_DATA[cont_name][index])
result.append(whole_article)
return result # 解析 where 条件并过滤数据
def syntax_where(offside):
handle = {">": less,
"<": greater,
"=": equal,
"like": like
}
for _key, func in handle.items():
if _key in offside:
field, term = offside.split(_key)
match_result = func(field.strip(), term.strip())
return match_result
else:
print_log("语法错误:where条件只支持[>,<,=,where]", "error") # 解析 find 语句并返回结果
def syntax_find(content, condition):
find_name = condition.split("from")[0].split("find")[1].split(",")
find_name = [i.strip() for i in find_name]
if "*" in find_name[0]:
print(tabulate(content, headers=INFO_DATA, tablefmt="grid"))
else:
title_list = []
for title in content:
item_list = []
for item in find_name:
item_index = OPTION.index(item)
item_list.append(title[item_index])
title_list.append(item_list)
print(tabulate(title_list, headers=find_name, tablefmt="grid"))
print_log("成功查询到%s条数据" % len(content), "info") # 增加条目函数
def syntax_add(content, codition):
codition = codition.split("staff_table")[1].split(",")
if codition[2] in INFO_DATA["phone"]:
print_log("手机号码重复", "error")
else:
id_id = []
for add_id in INFO_DATA["id"]:
id_id.append(int(add_id))
codition.insert(0, (id_id[-1] + 1))
for last_name, last_info in zip(OPTION, codition):
INFO_DATA[last_name].append(str(last_info))
write_info()
print_log("成功增加第%s条数据" % int(len(content)+1), "info") # 删除条目函数
def syntax_del(content, codition):
codition = [i.strip() for i in codition.split(" ")]
if "id" in codition[3]:
if "id" in codition[-1]:
del_name, del_term = codition[-1].split("=")
del_info(del_name, del_term)
elif "id" in codition[3]:
del_name = codition[-3]
del_term = codition[-1]
del_info(del_name, del_term)
print_log("成功删除第%s条数据" % del_term, "info")
else:
print_log("没有此序号或未检测到关键字[id=NO.]", "error")
elif "id"not in codition and len(content) > 0:
del_info(del_name="id", del_term=content[0][0])
print_log("成功删除第%s条数据" % content[0][0], "info")
else:
print_log("没有此序号或未检测到关键字[id=NO.]", "error") # 修改的函数
def syntax_update(content, codition):
codition = codition.split("set")
if len(codition) > 1:
index_own, number = codition[1].strip().split("=")
for index_value in content:
ind_index = index_value[0]
ind_index_id = INFO_DATA['id'].index(ind_index)
INFO_DATA[index_own.strip()][ind_index_id] = number.strip()
write_info() # 修改后的数据写进文件
print_log("成功修改%s条数据" % len(content), "info")
else:
print_log("语法格式错误,不存在 set 关键词", "error") # 解析语句并执行
def syntax_parser(order):
syntax_dict = {
"find": syntax_find,
"add": syntax_add,
"del": syntax_del,
"update": syntax_update
}
if order.split(" ")[0] in ("find", "add", "del", "update"):
if "where" in order:
left_side, offside = order.split("where")
final_result = syntax_where(offside)
else:
final_result = []
for index, info_id in enumerate(INFO_DATA["id"]):
info_set = []
for i in OPTION:
info_set.append(INFO_DATA[i][index])
final_result.append(info_set)
left_side = order
order_start = order.split()[0]
if order_start in syntax_dict:
syntax_dict[order_start](final_result, left_side)
else:
print_log("语法错误!\n[find/ add/ del/ update [size] from [staff_table] where [term][>,<,=,like][parameter]\n", "error") # 让用户输入语句并执行!
def main():
while True:
order = input("staff_db:"). strip()
if not order: continue
syntax_parser(order)
main()
python全栈开发中级班全程笔记(第二模块、第三章)(员工信息增删改查作业讲解)的更多相关文章
- python全栈开发中级班全程笔记(第二模块、第四章)(常用模块导入)
python全栈开发笔记第二模块 第四章 :常用模块(第二部分) 一.os 模块的 详解 1.os.getcwd() :得到当前工作目录,即当前python解释器所在目录路径 impor ...
- python全栈开发中级班全程笔记(第二模块、第四章(三、re 正则表达式))
python全栈开发笔记第二模块 第四章 :常用模块(第三部分) 一.正则表达式的作用与方法 正则表达式是什么呢?一个问题带来正则表达式的重要性和作用 有一个需求 : 从文件中读取所有联 ...
- python全栈开发中级班全程笔记(第二模块)第 二 部分:函数基础(重点)
python学习笔记第二模块 第二部分 : 函数(重点) 一.函数的作用.定义 以及语法 1.函数的作用 2.函数的语法和定义 函数:来源于数学,但是在编程中,函数这个概念 ...
- python全栈开发中级班全程笔记(第二模块)第一部分:文件处理
第二模块 第一部分:文件处理与函数 #插曲之人丑就要多读书:读书能够提高个人素质与内涵,提升个人修养与能力,以及层次的提升. 推荐书籍:追风筝的人.白鹿原 电影:阿甘正传.辛德勒的名单 第一节:三 ...
- python全栈开发从入门到放弃之模块和包
一 模块 1 什么是模块? 常见的场景:一个模块就是一个包含了python定义和声明的文件,文件名就是模块名字加上.py的后缀. 但其实import加载的模块分为四个通用类别: 1 使用python编 ...
- python全栈开发day16-正则表达式和re模块
1.昨日内容回顾 2.正则表达式(re模块是python中和正则表达式相关的模块) 1.作用 1).输入字符串是否符合匹配条件 2).从大段文字中匹配出符合条件的内容 2.字符组 [0-9a-zA-Z ...
- python全栈开发 * 进程池,线程理论 ,threading模块 * 180727
一.进程池 (同步 异步 返回值) 缺点: 开启进程慢 几个CPU就能同时运行几个程序 进程的个数不是无线开启的 应用: 100个任务 进程池 如果必须用多个进程 且是高计算型 没有IO型的程序 希望 ...
- Python:员工信息增删改查
一:需求 homework.txt文件中有如下格式的人员信息: 1,Jack Wang,28,13451024608,HR,2015‐01‐072,Rain Wang,21,13451054608,I ...
- 老男孩Python全栈第2期+课件笔记【高清完整92天整套视频教程】
点击了解更多Python课程>>> 老男孩Python全栈第2期+课件笔记[高清完整92天整套视频教程] 课程目录 ├─day01-python 全栈开发-基础篇 │ 01 pyth ...
随机推荐
- CODING 如何使用 CODING 研发管理系统来敏捷开发
之前我们分享过<CODING 如何使用 CODING 开发 CODING>的文章,时过境迁,现在 CODING 研发管理系统已经上线了如持续集成.缺陷管理.测试管理等 DevOps 中的重 ...
- cesium 之三维漫游飞行效果实现篇(附源码下载)
前言 cesium 官网的api文档介绍地址cesium官网api,里面详细的介绍 cesium 各个类的介绍,还有就是在线例子:cesium 官网在线例子,这个也是学习 cesium 的好素材. 内 ...
- Android远程桌面助手之功能简介
外国友人录制的ARDC的使用简介,非常不错,介绍得很详尽.
- 经度和纬度在SQL中的数据类型
冬天太冷,等坐公司班车也很冷,就萌生了给班车做一个到站查询功能. 在某宝上买了汽车在线的GPS设备, 终生免费的服务的. 这里不得不提下这个设备的优点, 它提供API接口,还是免费的. 所以在班车上装 ...
- [idea] SpringBoot整合swagger2实现CRUD
一:创建SpringBoot ,在pom.xml文件中加入jar包 <dependency> <groupId>io.springfox</groupId> < ...
- Docker + Sonarqube 环境搭建
Sonar概述 Sonar 是一个用于代码质量管理的开放平台.通过插件机制,Sonar 可以集成不同的测试工具,代码分析工具,以及持续集成工具. 一,postgres 数据库下载 docker pul ...
- JavaScript中编码函数escape,encodeURI,encodeURIComponent
第一:escape():对字符串进行编码,escape()不编码的字符:@*/+ 第二:encodeURI() 函数可把字符串作为 URI 进行编码.不会进行转义的:;/?:@&=+$,# 第 ...
- eclipse中使用Lombok(转)
原文链接:https://www.cnblogs.com/justuntil/p/7120534.html windows环境 1.下载lombok.jar包https://projectlombok ...
- C++11のlambd表达式
在其他语言中,我们常见lambda表达式,c++11中也引入了. 利用Lambda表达式,可以方便的定义和创建匿名函数.今天,我们就来简单介绍一下C++中Lambda表达式的简单使用. 一.lambd ...
- MYSQL内置MYSQL数据库中你可以得到的信息
1:help_topic 可以查看函数帮助,例如:SELECT * from help_topic WHERE name='concat' 可以查看concat函数. 2:SLOW_LOG 慢查询日 ...