【MIT-6.824】Lab 1: MapReduce
Lab 1链接:https://pdos.csail.mit.edu/6.824/labs/lab-1.html
Part I: Map/Reduce input and output
Part I需要补充两个关键功能:为map函数分解输出的功能和为reduce函数收集输入的功能,这两个功能对应的函数分别在common_map.go的doMap()函数和common_reduce.go的doRedce()函数。
本人首先梳理程序运行流程,其次补充代码,最后测试结果。
程序运行流程简述如下:
- Sequential首先获取Master对象的指针,然后利用函数闭包运行Master.run()。
- Master.run()会依次运行mapPhase和reducePhase。
- 在mapPhase中,doMap会依次处理每一个输入文件;在reducePhase中,doReduce会依次处理nReduce(论文中为R)个区域。
为实现doMap函数,需要实现以下功能:
- 读取inFile。
- 通过mapF函数,将inFile转换成key/value的切片形式。
- 将上一步得到的结果切割为nReduce个切片,并使用hash函数将结果分配到对应的切片中。
- 将上一步得到的结果转换为Json格式,并存储于文件中。
func doMap(
jobName string, // the name of the MapReduce job
mapTask int, // which map task this is
inFile string,
nReduce int, // the number of reduce task that will be run ("R" in the paper)
mapF func(filename string, contents string) []KeyValue,
) {
// Your code here (Part I).
// read file
data, err := ioutil.ReadFile(inFile)
if err != nil{
log.Fatal("common_map.doMap: fail to read the file. The error is ", err)
} // transfer file
slice := mapF(inFile, string(data)) // initialize reduceKv
var reduceKv [][]KeyValue
for i := ; i < nReduce; i++{
temp := make([]KeyValue, )
reduceKv = append(reduceKv, temp)
} // get reduceKv
for _, s := range slice{
index := ihash(s.Key) % nReduce
reduceKv[index] = append(reduceKv[index], s)
} // get intermediate files
for i:= ; i < nReduce; i++{
file, err := os.Create(reduceName(jobName, mapTask, i))
if err != nil{
log.Fatal("common_map.doMap: fail to create the file. The error is ", err)
}
enc := json.NewEncoder(file)
for _, kv := range(reduceKv[i]){
err := enc.Encode(&kv)
if err != nil{
log.Fatal("common_map.doMap: fail to encode. The error is ", err)
}
}
file.Close()
}
}
为实现doReduce函数,需要实现如下功能:
- 读取文件中存储的key/value对,并对其进行排序。
- 将key值相同的value发送至用户定义的reduceF()中,reduceF()会返回一个新的value值。
- 将新的key/value对写入文件。
func doReduce(
jobName string, // the name of the whole MapReduce job
reduceTask int, // which reduce task this is
outFile string, // write the output here
nMap int, // the number of map tasks that were run ("M" in the paper)
reduceF func(key string, values []string) string,
) {
// Your code here (Part I). // get and decode file
var slices []KeyValue
for i := ; i < nMap; i++{
fileName := reduceName(jobName, i, reduceTask)
file, err := os.Open(fileName)
if err != nil{
log.Fatal("common_reduce.doReduce: fail to open the file. The error is ", err)
}
dec := json.NewDecoder(file)
var kv KeyValue
for{
err := dec.Decode(&kv)
if err != nil{
break
}
slices = append(slices, kv)
}
file.Close()
} sort.Sort(ByKey(slices)) //return the reduced value for the key
var reducedValue []string
var outputValue []KeyValue
preKey := slices[].Key
for i, kv := range slices{
if kv.Key != preKey{
outputValue = append(outputValue, KeyValue{preKey, reduceF(preKey, reducedValue)})
reducedValue = make([]string,)
}
reducedValue = append(reducedValue, kv.Value)
preKey = kv.Key if i == (len(slices) - ){
outputValue = append(outputValue, KeyValue{preKey, reduceF(preKey, reducedValue)})
}
} //write and encode file
file, err := os.Create(outFile)
if err != nil{
log.Fatal("common_reduce.doReduce: fail to create the file. The error is ", err)
}
defer file.Close() enc := json.NewEncoder(file)
for _, kv := range outputValue{
err := enc.Encode(&kv)
if err != nil{
log.Fatal("common_reduce.doReduce: fail to encode. The error is ", err)
}
}
}
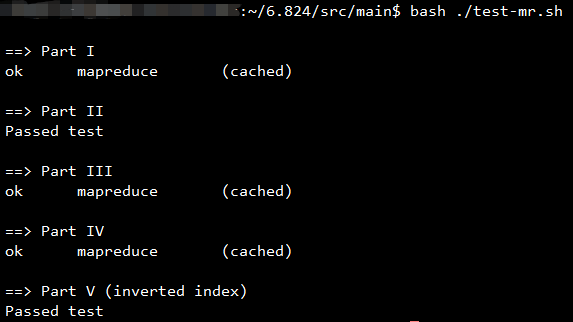
实验结果如下图所示:

Part II: Single-worker word count
Part II需要统计文档中每个单词出现的数目,需要实现的函数为wc.go中的mapF()和reduceF()函数。
mapF()函数需要将文件拆分为单词,并返回mapreduce.KeyValue的形式。reduceF()函数需要统计每一个Key对应的Value出现的数目,并以string的形式返回。
func mapF(filename string, contents string) []mapreduce.KeyValue {
// Your code here (Part II).
f := func(c rune) bool{
return !unicode.IsLetter(c)
}
words := strings.FieldsFunc(contents, f)
var result []mapreduce.KeyValue
for _, word := range words{
result = append(result, mapreduce.KeyValue{word,""})
}
return result
}
func reduceF(key string, values []string) string {
// Your code here (Part II).
sum :=
for _, value := range values{
i, err := strconv.Atoi(value)
if err != nil{
log.Fatal("wc.reduceF: fail to convert. The error is ", err)
}
sum += i
}
return strconv.Itoa(sum)
}
实验结果如下图所示:

Part III: Distributing MapReduce tasks&&Part IV: Handling worker failures
Part III和Part IV需要将顺序执行的MapReduce框架并行化并处理worker异常。
本人分别介绍worker和master的执行流程。
worker:RunWorker()首先被调用,该函数创建新Worker并通过call()函数向Master.Register()发送RPC。
master:
- 在master.go的Distributed()函数中,master通过startRPCServer()启动RPC服务器,然后利用函数闭包运行run()函数。
- 在run()函数中,master会依次运行schedule(mapPhase)和schedule(reducePhase)。
- 在schedule(phase)函数中,master会开启新协程运行forwardRegistrations()函数,然后运行Part III和Part IV需要实现的schedule.go中的schedule()函数。
- 在介绍worker的执行流程时,本人提到worker会向Master.Register()发送RPC。在Register()函数中,master会将新的worker添加至mr.workers中并告知forwardRegistrations()出现了新的worker。
- 在forwardRegistrations()函数中,master通过mr.workers的数目判断是否有新的worker。若有新的worker,master通过channel通知schedule.go的schedule()函数。
- 在schedule()函数中,master负责为worker分配task。
为实现master对worker的调度,需要在schedule()函数中实现如下功能。
- 通过sync.WaitGroup判断全部任务是否完成。
- 通过registerChan判断是否有新的worker。若有,开启新协程为此worker分配任务。
- 通过带有缓冲的channel输入任务序号,从channel中取出任务序号并分配给worker。若worker异常,则重新输入任务序号。
- 通过call()函数向worker发送RPC。
func schedule(jobName string, mapFiles []string, nReduce int, phase jobPhase, registerChan chan string) {
var ntasks int
var n_other int // number of inputs (for reduce) or outputs (for map)
switch phase {
case mapPhase:
ntasks = len(mapFiles)
n_other = nReduce
case reducePhase:
ntasks = nReduce
n_other = len(mapFiles)
}
fmt.Printf("Schedule: %v %v tasks (%d I/Os)\n", ntasks, phase, n_other)
// All ntasks tasks have to be scheduled on workers. Once all tasks
// have completed successfully, schedule() should return.
//
// Your code here (Part III, Part IV).
//
var wg sync.WaitGroup
wg.Add(ntasks)
taskChan := make(chan int, ntasks)
for i := ; i < ntasks; i++{
taskChan <- i
}
go func(){
for{
ch := <- registerChan
go func(address string){
for{
index := <- taskChan
result := call(address, "Worker.DoTask", &DoTaskArgs{jobName, mapFiles[index], phase, index, n_other},new(struct{}))
if result{
wg.Done()
fmt.Printf("Task %v has done\n", index)
}else{
taskChan <- index
}
}
}(ch)
}
}()
wg.Wait()
fmt.Printf("Schedule: %v done\n", phase)
}
Part V: Inverted index generation (optional, does not count in grade)
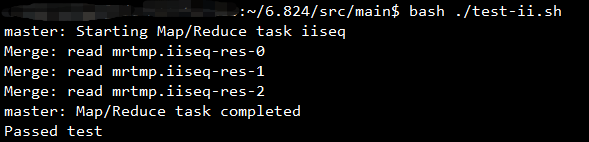
Part V需要实现倒排索引,需要补充的函数为ii.go中的mapF()和reduceF()函数。
mapF()函数需要对输入文件中的单词进行分割,返回以单词为Key,以文件题目为Value的切片。
reduceF()函数需要对相同Key对应的全部Value去重并排序,统计Value的个数。
func mapF(document string, value string) (res []mapreduce.KeyValue) {
// Your code here (Part V).
f := func(c rune) bool{
return !unicode.IsLetter(c)
}
words := strings.FieldsFunc(value, f)
var result []mapreduce.KeyValue
for _, word := range words{
result = append(result, mapreduce.KeyValue{word, document})
}
return result
}
func reduceF(key string, values []string) string {
// Your code here (Part V).
fileName := make(map[string]bool)
for _, value := range values{
fileName[value] = true
}
num :=
var documents []string
for key := range fileName{
num +=
documents = append(documents, key)
}
sort.Strings(documents)
var result string
for i, file := range documents{
if i >= {
result += ","
}
result += file
}
return strconv.Itoa(num) + " " + result
}
实验结果如下图所示:
Running all tests
【MIT-6.824】Lab 1: MapReduce的更多相关文章
- 【MIT 6.824 】分布式系统 课程笔记(一)
Lecture 02 Infrastructure: RPC & threads 一.多线程挑战 共享数据: 使用互斥信号量.或者避免共享 线程间协作: 使用channels 或者 waitg ...
- 【MIT 6.824 】分布式系统 课程笔记(二)Lecture 03 : GFS
Lecture 03 : GFS 一.一致性 1, 弱一致性 可能会读到旧数据 2, 强一致性 读到的数据都是最新的 3, 一致性比较 强一致性对于app的写方便, 但是性能差 弱一致性有良好的性能, ...
- MIT 6.824(Spring 2020) Lab1: MapReduce 文档翻译
首发于公众号:努力学习的阿新 前言 大家好,这里是阿新. MIT 6.824 是麻省理工大学开设的一门关于分布式系统的明星课程,共包含四个配套实验,实验的含金量很高,十分适合作为校招生的项目经历,在文 ...
- 【甘道夫】官方网站MapReduce代码注释具体实例
引言 1.本文不描写叙述MapReduce入门知识,这类知识网上非常多.请自行查阅 2.本文的实例代码来自官网 http://hadoop.apache.org/docs/current/hadoop ...
- 【大数据系列】hadoop核心组件-MapReduce
一.引入 hadoop的分布式计算框架(MapReduce是离线计算框架) 二.MapReduce设计理念 移动计算,而不是移动数据. Input HDFS先进行处理切成数据块(split) ma ...
- MIT 6.824学习笔记1 MapReduce
本节内容:Lect 1 MapReduce框架的执行过程: master分发任务,把map任务和reduce任务分发下去 map worker读取输入,进行map计算写入本地临时文件 map任务完成通 ...
- 【hadoop2.6.0】一句话形容mapreduce
网上看到的: We want to count all the books in the library. You count up shelf #1, I count up shelf #2. Th ...
- MIT 6.824 lab1:mapreduce
这是 MIT 6.824 课程 lab1 的学习总结,记录我在学习过程中的收获和踩的坑. 我的实验环境是 windows 10,所以对lab的code 做了一些环境上的修改,如果你仅仅对code 感兴 ...
- 【hadoop代码笔记】Mapreduce shuffle过程之Map输出过程
一.概要描述 shuffle是MapReduce的一个核心过程,因此没有在前面的MapReduce作业提交的过程中描述,而是单独拿出来比较详细的描述. 根据官方的流程图示如下: 本篇文章中只是想尝试从 ...
随机推荐
- 接口自动化测试持续集成--SoapUI安装
实际使用: 接口自动化测试持续集成框架:maven+SoapUI+jenkins 1.SoapUI安装文件下载5.1.2 http://pan.baidu.com/s/1c17dJLu安装步骤非常简单 ...
- Ajax不执行回调函数的原因(转)
今天用ajax的post请求后台,但是始终不执行回调函数,经查得知,ajax不执行回调函数的原因如下: jquery中规定返回的JSON字符串的KEY要用引号括起来,如{“result”: 1}这样才 ...
- Git 教程(三):仓库与分支
远程仓库 到目前为止,我们已经掌握了如何在Git仓库里对一个文件进行时光穿梭,你再也不用担心文件备份或者丢失的问题了. 可是有用过集中式版本控制系统SVN的童鞋会站出来说,这些功能在SVN里早就有了, ...
- c#进阶之泛型
好久没用写博了,感觉工作的越久就越发的懒了,啦啦啦!德玛西亚! 感觉最近食欲不正,便想写写组织下自己的学习路程: 泛型,可能很多朋友在学习这个东西的时候都源于面向对象,当然我也不例外:从一个实体继承另 ...
- 最简单的 react-router4 的安装和使用
React-Router 的安装 npm install react-router React-Router提供了两个组件:Router和Route.下面看最简单的例子: src/Routes.js ...
- Java 数据返回接口封装
enum StatusCode package com.lee.utils; public enum StatusCode { SUCCESS(20000, "成功"), FALL ...
- IDEA日常遇到问题汇总
1. IDEA .gitignore文件不显示在项目栏中 解决方法,setting >> Editor >> Code Style >> File Type &g ...
- MacOS修改用户名后变为普通用户,无法创建管理员账号
摘要:有的时候用户修改原电脑用户名,会把该用户降为普通用户,点击下方的锁会弹出下方图示,导致无法修改任何设置 解决方案: 重启电脑Restart按Command+S进入终端terminal输入以下命令 ...
- bash 基础命令
bash的基础特性(): () 命令历史 history 环境变量: HISTSIZE:命令历史记录的条数: HISTFILE:~/.bash_history: HISTFILESIZE:命令历史文件 ...
- 尝试解决IDea 启动项目后,后台疯狂输出日志。
今天启动项目的时候,昨天下班前还好好,然后今天就炸了.后台疯狂输出日志.. 就类似这种,大批量的刷.其实项目已经正常启动了,就是疯狂的刷日志. 2019-03-29 08:42:53 [DEBUG] ...