wordCount剖析Spark模型
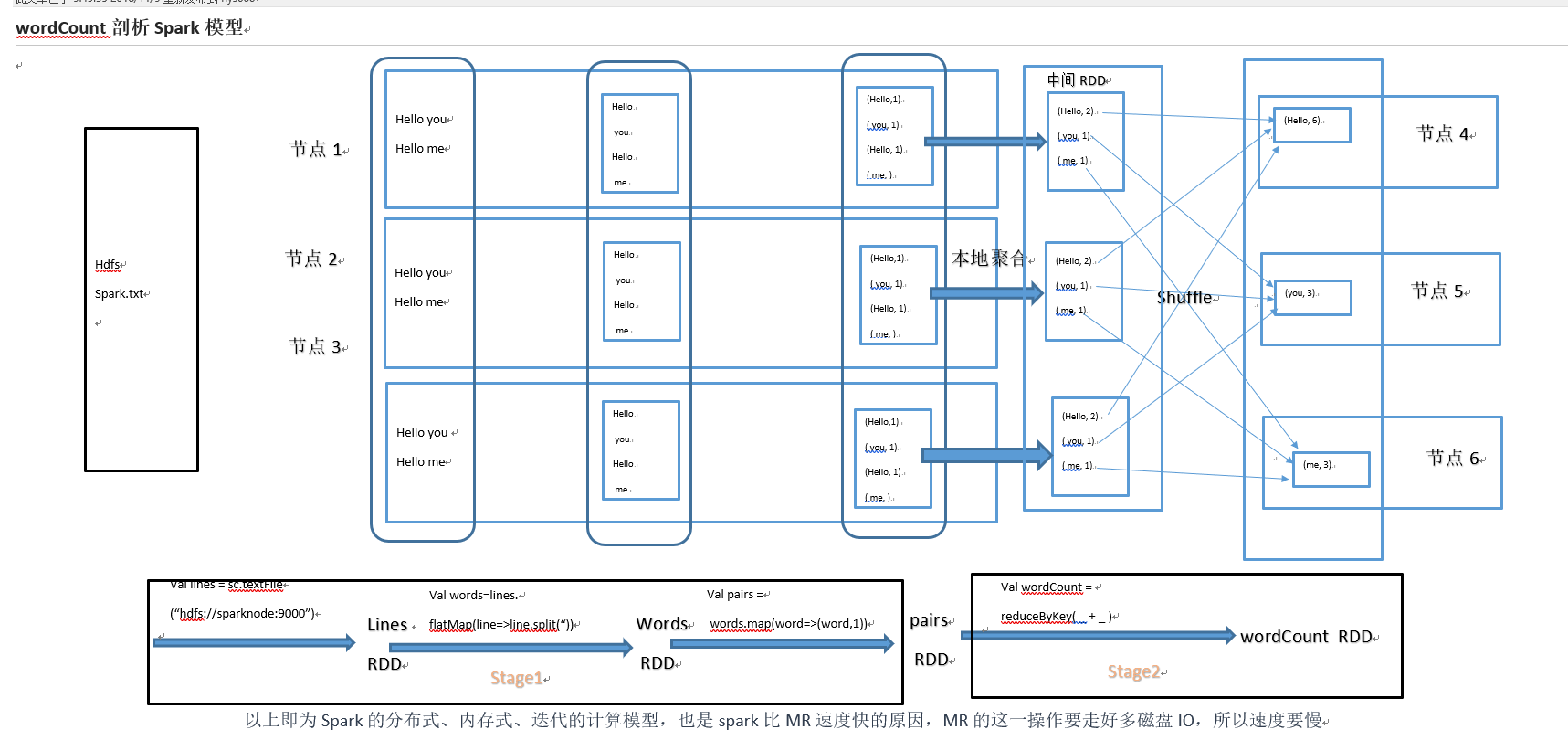
wordCount剖析Spark模型的更多相关文章
- Spark大数据处理 之 从WordCount看Spark大数据处理的核心机制(2)
在上一篇文章中,我们讲了Spark大数据处理的可扩展性和负载均衡,今天要讲的是更为重点的容错处理,这涉及到Spark的应用场景和RDD的设计来源. Spark的应用场景 Spark主要针对两种场景: ...
- Spark大数据处理 之 从WordCount看Spark大数据处理的核心机制(1)
大数据处理肯定是分布式的了,那就面临着几个核心问题:可扩展性,负载均衡,容错处理.Spark是如何处理这些问题的呢?接着上一篇的"动手写WordCount",今天要做的就是透过这个 ...
- 通过WordCount解析Spark RDD内部源码机制
一.Spark WordCount动手实践 我们通过Spark WordCount动手实践,编写单词计数代码:在wordcount.scala的基础上,从数据流动的视角深入分析Spark RDD的数据 ...
- Spark 模型选择和调参
Spark - ML Tuning 官方文档:https://spark.apache.org/docs/2.2.0/ml-tuning.html 这一章节主要讲述如何通过使用MLlib的工具来调试模 ...
- petite-vue源码剖析-沙箱模型
在解析v-if和v-for等指令时我们会看到通过evaluate执行指令值中的JavaScript表达式,而且能够读取当前作用域上的属性.而evaluate的实现如下: const evalCache ...
- 深度剖析Spark分布式执行原理
让代码分布式运行是所有分布式计算框架需要解决的最基本的问题. Spark是大数据领域中相当火热的计算框架,在大数据分析领域有一统江湖的趋势,网上对于Spark源码分析的文章有很多,但是介绍Spark如 ...
- spark模型运行时无法连接摸个excutors异常org.apache.spark.shuffle.FetchFailedException: Failed to connect to xxxx/xx.xx.xx.xx:xxxx
error:org.apache.spark.shuffle.FetchFailedException: Failed to connect to xxxx/xx.xx.xx.xx:xxxx 定位来定 ...
- spark模型error java.lang.IllegalArgumentException: Row length is 0
failure: Lost task 18.3 in stage 17.0 (TID 59784,XXXXX, executor 19): java.lang.IllegalArgumentExcep ...
- (升级版)Spark从入门到精通(Scala编程、案例实战、高级特性、Spark内核源码剖析、Hadoop高端)
本课程主要讲解目前大数据领域最热门.最火爆.最有前景的技术——Spark.在本课程中,会从浅入深,基于大量案例实战,深度剖析和讲解Spark,并且会包含完全从企业真实复杂业务需求中抽取出的案例实战.课 ...
随机推荐
- 基于BootStrap的initupload()实现Excel上传和获取excel中的数据
简单说明:后边要做exl解析(还没做呢),所以先有一个excel的的上传以及获取excel中的数据,展示出来. 代码: //html代码 <div class="btn-group&q ...
- Django-ORM多表操作(进阶)
一.创建模型 下面我们通过图书管理系统,来设计出每张表之间的对应关系. 通过上图关系,来定义一下我们的模型类. from django.db import models class Book(mode ...
- java----JDOM解析XML
JDOM: 与DOM类似,基于树形结构 效率比DOM快 下载: http://www.jdom.org/dist/binary/jdom-2.0.6.zip 导包导java中的工程目录 jdom-2. ...
- URL.createObjectURL() 实现本地上传图片 并预览功能
URL.createObjectURL() 静态方法会创建一个 DOMString,其中包含一个表示参数中给出的对象的URL.这个 URL 的生命周期和创建它的窗口中的 document 绑定.这个新 ...
- Java集合实现
set: public class BSTSet<E extends Comparable<E>> implements Set<E> { private BST& ...
- [慢更]Sublime Text 快捷键及使用过的插件
整理自己常用的sublime text命令和插件 1.pretty json Json 快速格式化,免去url访问json站点的烦恼. 摘自:https://segmentfault.com/a/11 ...
- SQL反模式学习笔记9 元数据分裂
目标:支持可扩展性.优化数据库的结构来提升查询的性能以及支持表的平滑扩展. 反模式:克隆表与克隆列 1.将一张很长的表拆分成多张较小的表,使用表中某一个特定的数据字段来给这些拆分出来的表命名. 2.将 ...
- Android+openCV人脸检测2(静态图片)
前几篇文章中有提到对openCV环境配置,这里再重新梳理导入和使用openCV进行简单的人脸检测(包括使用级联分类器) 一 首先导入openCVLibrary320 二 设置gradle的sdk版本号 ...
- linux安装git方法
用git --version命令检查是否已经安装 在CentOS5的版本,由于yum源中没有git,所以需要预先安装一系列的依赖包.在CentOS6的yum源中已经有git的版本了,可以直接使用yum ...
- hdu5706-GirlCat
Problem Description As a cute girl, Kotori likes playing ``Hide and Seek'' with cats particularly.Un ...