zipkin链路追踪
zipkin架构说明
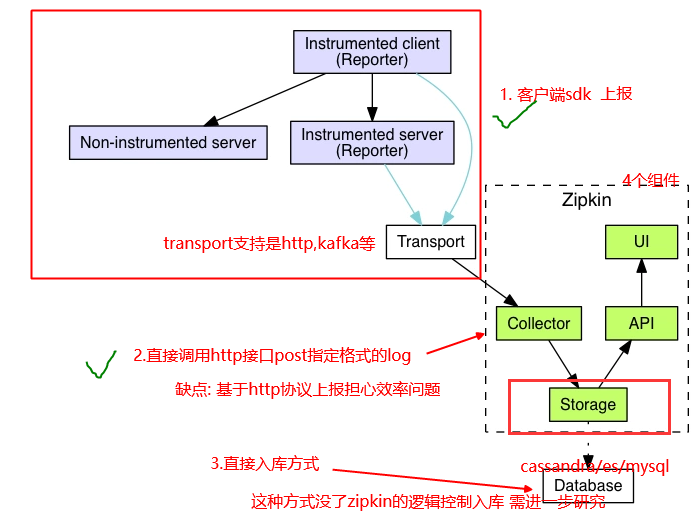
zipkin api
我想自己搞一些满足zipkin格式的日志,入库es,然后让zipkin仅做展示
1.需要了解zipkin组件
2,学习zipkin设计原理,何时何地产生日志 日志如何聚合存储
3.zipkin的自身api
3个主要概念 各个字段的用途
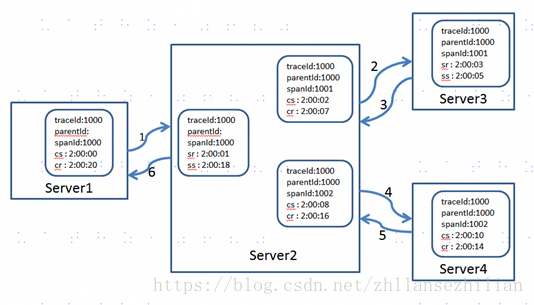
(1)Trace:它是由一组有相同Trace ID的Span串联形成一个树状结构。为了实现请求跟踪,当请求请求到分布式系统的入口端点时,只需要服务跟踪框架为该请求创建一个唯一的跟踪标识(即前文提到的Trace ID),同时在分布式系统内部流转的时候,框架始终保持传递该唯一标识,直到返回请求为止,我们通过它将所有请求过程中的日志关联起来;
(2)Span:它代表了一个基础的工作单元,例如服务调用。为了统计各处理单元的时间延迟,当前请求到达各个服务组件时,也通过一个唯一标识(即前文提到的Span ID)来标记它的开始、具体过程以及结束。通过span的开始和结束的时间戳,就能统计该span的时间延迟,除此之外,我们还可以获取如事件名称、请求信息等元数据。
(3)Annotation:它用于记录一段时间内的事件。内部使用的最重要的注释是:
cs - Client Sent - 客户端发送一个请求,这个注解描述了这个Span的开始。
sr - Server Received - 服务端获得请求并准备开始处理它,其中(sr – cs) 时间戳便可得到网络传输的时间。
ss - Server Sent (服务端发送响应)– 该注解表明请求处理的完成(当请求返回客户端), (ss – sr)时间戳就可以得到服务器请求的时间。
cr - Client Received (客户端接收响应)- 表明此时Span的结束,(cr – cs)时间戳便可以得到整个请求所消耗的时间。
通过http header方式传输traceid spanid等
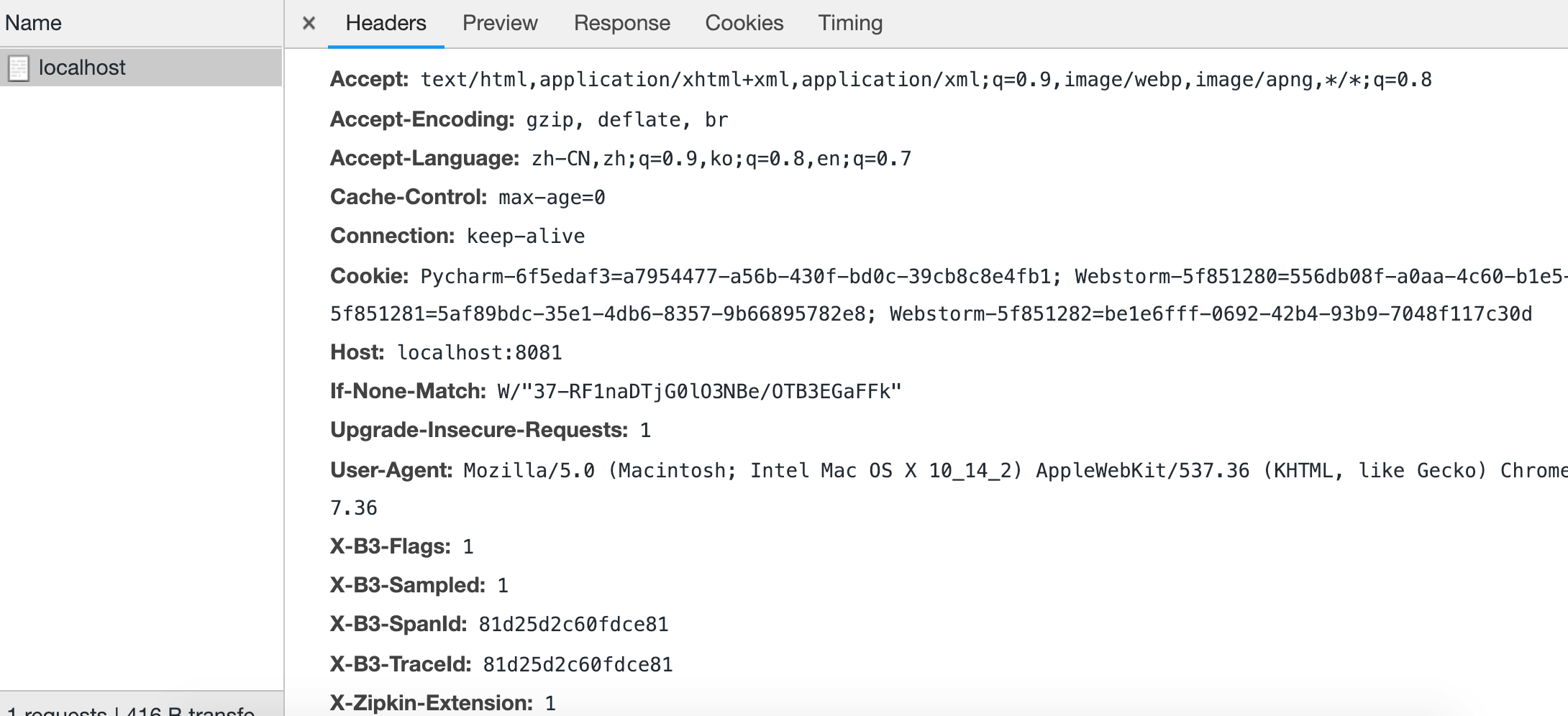
注意:时间点计算
sr-cs:网络延迟
ss-sr:逻辑处理时间
cr-cs:整个流程时间
一个例子
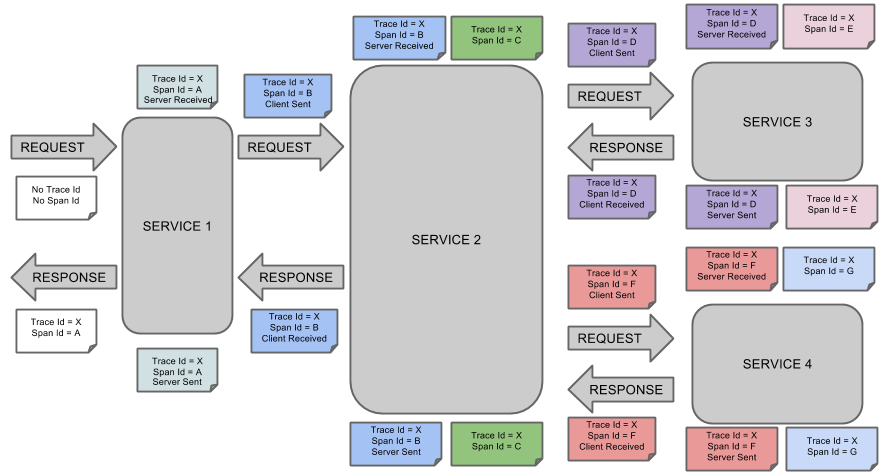
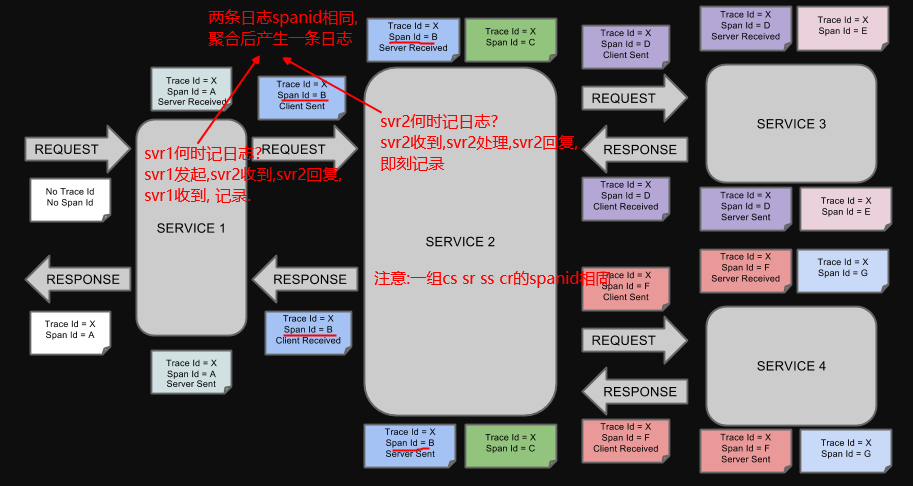
上图表示一请求链路,一条链路通过Trace Id唯一标识,Span标识发起的请求信息,各span通过parent id 关联起来,如图
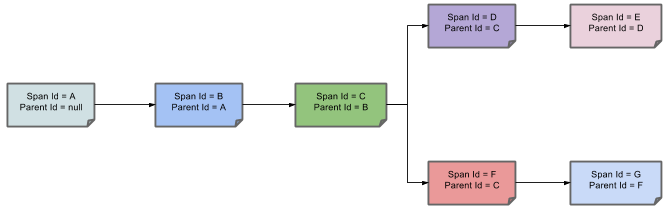
整个链路的依赖关系如下:


sr-cs 得到请求发出延迟
ss-sr 得到服务端处理延迟
cr-cs 得到真个链路完成延迟
注意:时间点计算
sr-cs:网络延迟
ss-sr:逻辑处理时间
cr-cs:整个流程时间
日志格式

zipkin官网的一个流程图
Instrumented client:被装配的客户端
Non-Instrumented server:没被装配的服务端
Instrumented server:被装配的服务端
┌─────────────┐ ┌───────────────────────┐ ┌─────────────┐ ┌──────────────────┐
│ User Code │ │ Trace Instrumentation │ │ Http Client │ │ Zipkin Collector │
└─────────────┘ └───────────────────────┘ └─────────────┘ └──────────────────┘
│ │ │ │
┌─────────┐
│ ──┤GET /foo ├─▶ │ ────┐ │ │
└─────────┘ │ record tags
│ │ ◀───┘ │ │
────┐
│ │ │ add trace headers │ │
◀───┘
│ │ ────┐ │ │
│ record timestamp
│ │ ◀───┘ │ │
┌─────────────────┐
│ │ ──┤GET /foo ├─▶ │ │
│X-B3-TraceId: aa │ ────┐
│ │ │X-B3-SpanId: 6b │ │ │ │
└─────────────────┘ │ invoke
│ │ │ │ request │
│
│ │ │ │ │
┌────────┐ ◀───┘
│ │ ◀─────┤200 OK ├─────── │ │
────┐ └────────┘
│ │ │ record duration │ │
┌────────┐ ◀───┘
│ ◀──┤200 OK ├── │ │ │
└────────┘ ┌────────────────────────────────┐
│ │ ──┤ asynchronously report span ├────▶ │
│ │
│{ │
│ "traceId": "aa", │
│ "id": "6b", │
│ "name": "get", │
│ "timestamp": 1483945573944000,│
│ "duration": 386000, │
│ "annotations": [ │
│--snip-- │
└────────────────────────────────┘
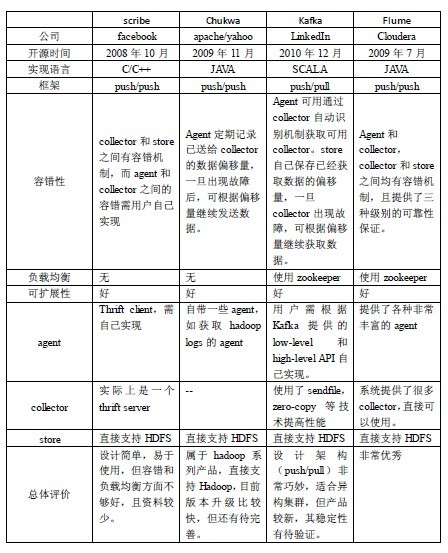
facebook已放弃的scribe日志采集器
zipkin链路追踪的更多相关文章
- 微服务 Zipkin 链路追踪原理(图文详解)
一个看起来很简单的应用,可能需要数十或数百个服务来支撑,一个请求就要多次服务调用. 当请求变慢.或者不能使用时,我们是不知道是哪个后台服务引起的. 这时,我们使用 Zipkin 就能解决这个问题. 由 ...
- 微服务SpringCloud之zipkin链路追踪
随着业务发展,系统拆分导致系统调用链路愈发复杂一个前端请求可能最终需要调用很多次后端服务才能完成,当整个请求变慢或不可用时,我们是无法得知该请求是由某个或某些后端服务引起的,这时就需要解决如何快读定位 ...
- SpringCloud:Zipkin链路追踪,并将数据写入mysql
1.zipkin server 1.1.新建Springboot项目,zinkin 1.2.添加依赖 <dependency> <groupId>io.zipkin.java& ...
- 原理分析dubbo分布式应用中使用zipkin做链路追踪
zipkin是什么 Zipkin是一款开源的分布式实时数据追踪系统(Distributed Tracking System),基于 Google Dapper的论文设计而来,由 Twitter 公司开 ...
- 原理分析dubbo分布式应用中使用zipkin做链路追踪(转)
作者:@nele本文为作者原创,转载请注明出处:https://www.cnblogs.com/nele/p/10171794.html 目录 zipkin是什么为什么使用Zipkinzipkin架构 ...
- 基于zipkin分布式链路追踪系统预研第一篇
本文为博主原创文章,未经博主允许不得转载. 分布式服务追踪系统起源于Google的论文“Dapper, a Large-Scale Distributed Systems Tracing Infras ...
- zipkin分布式链路追踪系统
基于zipkin分布式链路追踪系统预研第一篇 分布式服务追踪系统起源于Google的论文“Dapper, a Large-Scale Distributed Systems Tracing Inf ...
- Spring Cloud Sleuth服务链路追踪(zipkin)(转)
这篇文章主要讲述服务追踪组件zipkin,Spring Cloud Sleuth集成了zipkin组件. 一.简介 Spring Cloud Sleuth 主要功能就是在分布式系统中提供追踪解决方案, ...
- 链路追踪工具之Zipkin学习小记
(接触了Zipkin,权将所了解或理解的记于此,以备忘) 分布式追踪系统 随着业务发展,系统拆分多个微服务.此时对于一个前端请求可能需要调用多个后端端服务才能完成,当整个请求变慢或不可用时,我们是无法 ...
随机推荐
- Shell入门(一)
一.Shell参数变量相关知识: $@: 所有参数,每个参数带双引号.以"$1" "$2" "$3"的形式出现, $*: 所有参数,所有参 ...
- Allegro PCB Design GXL (legacy) 设置自动保存brd文件
Allegro PCB Design GXL (legacy) version 16.6-2015 菜单Setup > User Preferences... 在User Preferences ...
- Hdu 1022 Train Problem I 栈
Train Problem I Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) ...
- java开发学生信息管理系统的实现(简洁易懂),适合计算机专业学生参考,课程设计、毕业论文设计参考等
编写一个简单的学生管理信息系统. 在oracle中设计一张学生表,以学号作为关键字. 其他学生信息有:姓名.手机号. 在进入系统时,显示如下菜单: ************************** ...
- Javascript我学之三函数的参数
本文是金旭亮老师网易云课堂的课程笔记,记录下来,以供备忘 函数的参数 对于参数值,JavaScript不会进行类型检查,任何类型的值都可以被传递给参数. ...
- Python——文件读取
我们经常需要从文件中读取数据,因此学会文件的读取很重要,下面来介绍一下文件的读取工作: 1.读取整个文件 pi_digits.text 3.1415926535 8979323846 ...
- python全栈开发day110-Flask基础语法
1.Flask 初识: 短小精悍,三方支持的组件多 稳定性较差 2.三行 :启动flask服务 from flask import Flask app = Flask(__name__) app.ru ...
- Android+openCV人脸检测2(静态图片)
前几篇文章中有提到对openCV环境配置,这里再重新梳理导入和使用openCV进行简单的人脸检测(包括使用级联分类器) 一 首先导入openCVLibrary320 二 设置gradle的sdk版本号 ...
- Fiddler工具使用介绍
Fiddler基础知识 Fiddler是强大的抓包工具,它的原理是以web代理服务器的形式进行工作的,使用的代理地址是:127.0.0.1,端口默认为8888,我们也可以通过设置进行修改. 代理就是在 ...
- [linux]主机访问虚拟机web服务(CentOS)
目的为了实现主机和虚拟机的通信,访问虚拟机中架设的web服务.按理说通过虚拟机ip + web服务端口,即可在浏览器访问虚拟机的web服务.但是由于CentOS的防火墙问题,对应web端口无法访问.通 ...