[转载]Oracle之xml的增删改查操作
tip: xmltype函数是将clob字段转成xmltype类型的函数,若字段本身为xmltype类型则不需要引用xmltype()函数
同名标签用数组取值的方式获取,但起始值从1开始
一.查询(Query)
1. extract函数,查询节点值,带节点名
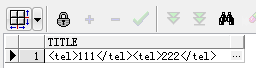
1 -- 获取带节点的值,例如:<tel>222</tel>
2 select extract(xmltype(e.prj_xml),'/data/project/persons/person[1]/tel').getStringVal() as title from project e where e.zh_title='白夜追逐繁星';
3 -- 备注如果节点表达式查询一个节点的父节点,则会将该父节点下的所有节点包含该父节点查出
Query Result:
tip: extract函数中路径引用text(),查询的节点若重复则自动拼接
select extractvalue(xmltype('<a><b>1</b><b>2</b></a>'),'/a/b') from dual; -- 报错,报只返回一个节点值,因为在a标签下存在两个同名标签b
select extract(xmltype('<a><b>1</b><b>2</b></a>'),'/a/b/text()') from dual; -- extract+text() 解决同名节点问题,若存在重复节点会自动拼接在一起,但不使用任何拼接符号
2. extractvalue函数,查询节点值,不带节点名
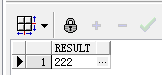
-- 获取不带节点的值,例如:222
1 select extractvalue(xmltype(e.prj_xml),'/data/project/persons/person[1]/tel') as result from project e where e.zh_title='白夜追逐繁星';
Query Result:
Tip: 节点不存在时,查询结果均为空
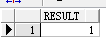
3. existsnode函数,判断节点是否存在,表示存在,0表示不存在
1 select existsnode(xmltype(e.prj_xml),'/data/project/persons/person[1]/tel') as result from project e where e.zh_title='白夜追逐繁星';
Query Result:
4. sys_dburigen,将指定列通过函数生成一个该列的URI值,例如:/PUBLIC/PROJECT/ROW[ZH_TITLE='邹成咁180117']/ZH_TITLE
1 select sys_dburigen(e.zh_title) as result from project e where e.zh_title='白夜追逐繁星';
Query Result:

5. sys_xmlAgg,合并查询,将多个xml合并,类似于set集合
-- sys_xmlGen 将xml转成xmltype实例,方便xml合并,sys_xmlAgg用于xml合并
1 select sys_xmlAgg(sys_xmlgen(e.prj_xml)) as result from project e where e.zh_title='白夜追逐繁星' or e.zh_title='白夜追逐繁星2' ;
Query Result:
6. xmlforest,将指定列以xml格式查询出来,可指定生成的xml节点名称
1 select xmlforest(e.zh_title as zhTitle,e.prj_no as prjNo,e.psn_code as psnCode).getStringVal() as xml from project e where e.zh_title='白夜追逐繁星';
Query Result:

7. xmlelement,为查询出来的xml添加挂载的父节点,并将xml字符串格式化成xml ,与xmlforest函数配套使用
1 select xmlelement(data,xmlforest(e.zh_title,e.prj_no,e.psn_code)).getStringVal() as xml from project e where e.zh_title='白夜追逐繁星';
Query Result:

延伸:为data节点添加属性,使用xmlattributes函数
1 select xmlelement(data,xmlattributes(e.prj_code as code),xmlforest(e.zh_title,e.prj_no,e.psn_code)).getStringVal() as xml from project e where e.zh_title='白夜追逐繁星';
Query Result:

延伸: XMLCOLATTVAL效果等同于xmlforest函数,但默认会为每个标签添加一个属性name,属性值为列明,若未指定列别名,默认该列列明
1 select XMLCOLATTVAL(e.zh_title as zhTitle,e.prj_no as prjNo,e.psn_code as psnCode).getStringVal() as xml from project e where e.zh_title='白夜追逐繁星'
Query Result:

8. xmlConcat,xmlType实例之间联结
1 select xmlelement(data,xmlConcat(xmltype('<a>1</a>'),xmltype('<b>1</b>'))).getStringVal() as result from dual;
Query Result:
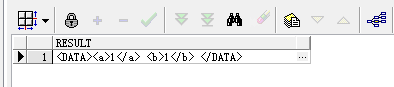
9. xmlsequence将一个xml以标签为单位,转换成数组,也就是一行行记录
1 select e.getStringVal() as result
2 from table(xmlsequence(extract(xmltype('<a><b>233</b><c>666</c><d>88</d></a>'),'/a/*'))) e;
Query Result:

二.添加(Insert)
-- 添加xml节点,insertchildxml添加xml节点,参数3默认指定插在该节点后,若该节点不存在,则追加到子节点集合的末尾
-- 添加xml节点,insertchildxmlbefore,和insertchildxmlafter添加xml节点,参数3指定插在该节点前或者后,若该节点不存在,则追加到子节点集合的末尾

1 update project e set e.prj_xml=insertchildxml(xmltype(e.prj_xml),'/data/project/persons/person[1]','tel',xmltype('<tel>222</tel>')).getClobVal() where e.zh_title='白夜追逐繁星';
2 update project e set e.prj_xml=insertchildxmlbefore(xmltype(e.prj_xml),'/data/project/persons/person[1]','psn_code',xmltype('<tel>111</tel>')).getClobVal() where e.zh_title='白夜追逐繁星';
三.修改(Update)
-- updatexml用于更新节点值
1 -- updatexml用于更新节点值,参数1:需要修改节点的xml字段;参数2:节点路径;参数3:值
2 update project e set e.prj_xml=updatexml(xmltype(e.prj_xml),'/data/project/persons/person[1]/tel','<tel>111</tel>').getClobVal() where e.zh_title='白夜追逐繁星';
3 update project e set e.prj_xml=updatexml(xmltype(e.prj_xml),'/data/project/persons/person[1]/tel/text()','222').getClobVal() where e.zh_title='白夜追逐繁星';
tip: getClobVal()是将xmltype类型转成clob类型方法
四.删除(Delete)
1 -- 删除xml节点,参数1:需要删除节点的xml字段;参数2:节点路径;
2 update project e set e.prj_xml=deletexml(xmltype(e.prj_xml),'/data/project/persons/person[1]/tel').getClobVal() where e.zh_title='白夜追逐繁星';
[转载]Oracle之xml的增删改查操作的更多相关文章
- Oracle之xml的增删改查操作
工作之余,总结一下xml操作的一些方法和心得! tip: xmltype函数是将clob字段转成xmltype类型的函数,若字段本身为xmltype类型则不需要引用xmltype()函数 同名标签用数 ...
- c# xml的增删改查操作 xmlDocument 的用法
1.将xml转换为DataTable string path = "";//xml的位置StringReader sr = null;XmlTextReader xmlReader ...
- 使用C#对XML进行增删改查操作
xml文件格式 <?xml version="1.0" encoding="utf-8"?> <messageList> <mes ...
- 对oracle里面clob字段里面xml的增删改查学习
这段时间,我使用系统表里面有clob字段里面存放的xml信息,我们如何对xml进行增删改查操作呢,自己参考了很多也学到很多,给大家分享一下 首先我们先建测试表 CREATE TABLE EFGP_23 ...
- C# - VS2019 通过DataGridView实现对Oracle数据表的增删改查
前言 通过VS2019建立WinFrm应用程序,搭建桌面程序后,通过封装数据库操作OracleHelper类和业务逻辑操作OracleSQL类,进而通过DataGridView实现对Oracle数据表 ...
- oracle 临时表空间的增删改查
oracle 临时表空间的增删改查 oracle 临时表空间的增删改查 1.查看临时表空间 (dba_temp_files视图)(v_$tempfile视图)select tablespace_nam ...
- java实现xml文件增删改查
java一次删除xml多个节点: 方案1.你直接改动了nodeList,这一般在做循环时是不同意直接这么做的. 你能够尝试在遍历一个list时,在循环体同一时候删除list里的内容,你会得到一个异常. ...
- Oracle使用JDBC进行增删改查 表是否存在
Oracle使用JDBC进行增删改查 数据库和表 table USERS ( USERNAME VARCHAR2(20) not null, PASSWORD VARCHAR2(20) ) a ...
- 用dom4j解析xml文件并执行增删改查操作
转自:https://www.aliyun.com/jiaocheng/1339446.html xml文件: <?xml version="1.0" encoding=&q ...
随机推荐
- 在页面上获取web项目信息
获取协议名称:request.getScheme() 获取域名:request.getServerName() 获取项目名称:request.getContextPath() 使用EL表达式获取项目名 ...
- STL--set_difference
set_difference(),作用是求两个集合的差.即求A-B(属于A但不属于B的元素) set_difference()算法计算两个集合[start1, end1)和[start2, end2) ...
- Docker 安装以及运用
Docker 运行在 CentOS 7 上,要求系统为64位.系统内核版本为 3.10 以上.Docker 运行在 CentOS-6.5 或更高的版本的 CentOS 上,要求系统为64位.系统内核版 ...
- php正则表达式 剔除字符串中 ,除了汉字的字符(只保留汉字) php 正则 只保留汉字,剔除所有符号
<?php //提取字符串中的汉字其余信息剔除 $str='f龙,真 .,.,.?!::·…~&@#,.?!:;.……-&@#“”‘’〝 "〞'´'>< ...
- 下面findmax函数将计算数组中的最大元素及其下标值,请编写该函数。
#include <stdio.h> void findmax ( int s[ ], int t, int *k ) { int i; *k = ; ; i < t; i++) { ...
- nodejs----安装配置
Node.js 安装配置 Node.js 安装包及源码下载地址为:https://nodejs.org/en/download/. 你可以根据不同平台系统选择你需要的 Node.js 安装包. Nod ...
- Lambda查询
使用EF查询数据库,之前使用Linq表达式,现在改成另一个种方法查询:Lambda表达式 TestEntities db=new TestEntities(); ).FirstOrDefault(); ...
- [strongswan] strongswan METHOD宏
使用METHOD宏的函数定义: METHOD(message_t, get_message_id, uint32_t, private_message_t *this) { return this-& ...
- flask读书笔记
学习flask的一个很好的网站:http://www.pythondoc.com/flask-mega-tutorial/helloworld.html ======================= ...
- SQL SERVER 基本操作语句
Sql 是一种结构化的查询语言:Sql是一种数据库查询和程序设计语言,用于存取数据以及查询.更新和管理‘关系型数据库’系统:Sql对大小写不敏感:Sql不是数据库,是行业标准,是结构化的查询语言 In ...