mybatis与数据库访问相关的配置以及设计
mybatis与数据库访问相关的配置以及设计
mybatis不管如何NB,总是要与数据库进行打交道。通过提问的方式,逐步深入
- 我们常用的MyBatis配置中哪些是与数据库相关?
- 数据源配置:
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
</environment>
看到这个配置文件,第一个直觉会想到由谁读取配置文件,谁有读取了配置信息?先忽略这个疑问,跳过。直接看下面的问题
1.配置数据源信息后,由谁来创建、管理数据源?
根据JDBC驱动中约束的接口,Connection需要DataSource中获取
如果自己设计,是否直接可以由工厂返回Connection?有什么好处,有什么坏处? //TODO
没看代码前:
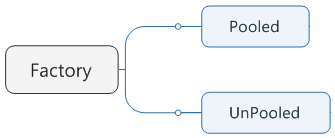
实际Mybatis设计,没有直接返回Connection,而返回了dataSource
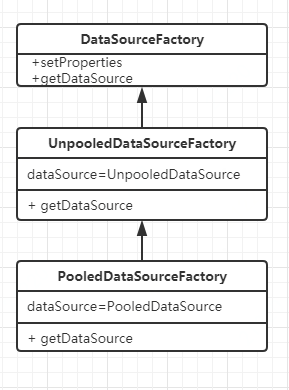
2.对于有连接池的数据源,和无连接池的数据源,我们自己会如何设计?
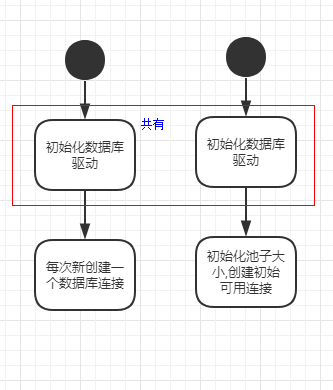
流程上的区别
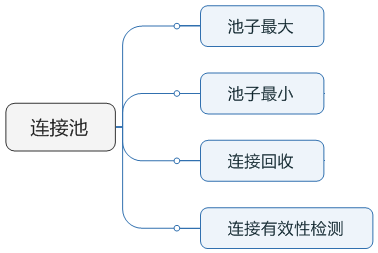
职责上区别
现在解开谜底:看实际Mybatis设计如何?
非池化类:
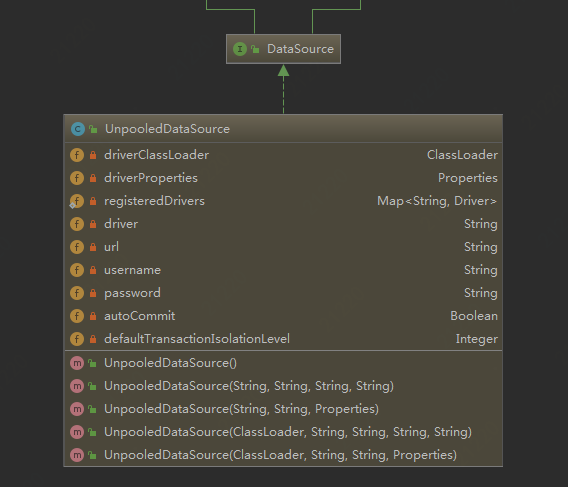
看下最关键的,获得数据库连接,和我们自己写的没啥区别。简单粗暴
private Connection doGetConnection(Properties properties) throws SQLException {
initializeDriver();
Connection connection = DriverManager.getConnection(url, properties);
configureConnection(connection);
return connection;
}
池化类:
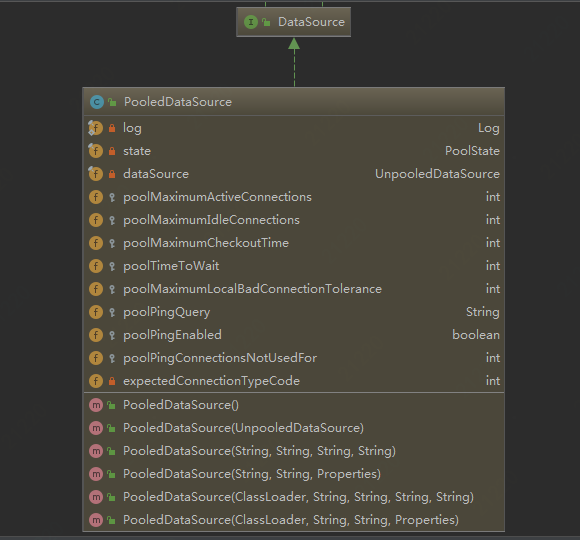
池化工作分配 :
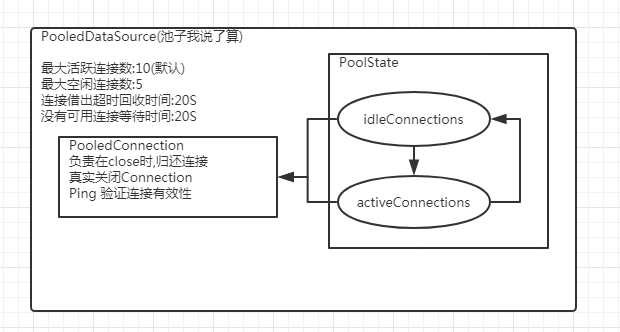
至此,MYBABTIS对于数据源的创建以及管理结束!看下代码,池化获得连接的代码
@Override
public Connection getConnection() throws SQLException {
return popConnection(dataSource.getUsername(), dataSource.getPassword()).getProxyConnection();
}
while (conn == null) { //够用就行,拿到一个就返回
synchronized (state) {
//只有有连接还回来,再走这里
if (!state.idleConnections.isEmpty()) {
// Pool has available connection
conn = state.idleConnections.remove(0);
if (log.isDebugEnabled()) {
log.debug("Checked out connection " + conn.getRealHashCode() + " from pool.");
}
} else {
//有两种可能:1种,都在使用中,池子没满,再新建
// Pool does not have available connection
if (state.activeConnections.size() < poolMaximumActiveConnections) {
// Can create new connection
//新建连接
conn = new PooledConnection(dataSource.getConnection(), this);
if (log.isDebugEnabled()) {
log.debug("Created connection " + conn.getRealHashCode() + ".");
}
} else {
// Cannot create new connection
//找一个最老的,用的ArrayList,老的在ArrayList数组的前面
PooledConnection oldestActiveConnection = state.activeConnections.get(0);
long longestCheckoutTime = oldestActiveConnection.getCheckoutTime();
//借出超时,不让他做了,直接rollback。。。暴力
if (longestCheckoutTime > poolMaximumCheckoutTime) {
// Can claim overdue connection
state.claimedOverdueConnectionCount++;
state.accumulatedCheckoutTimeOfOverdueConnections += longestCheckoutTime;
state.accumulatedCheckoutTime += longestCheckoutTime;
state.activeConnections.remove(oldestActiveConnection);
if (!oldestActiveConnection.getRealConnection().getAutoCommit()) {
try {
oldestActiveConnection.getRealConnection().rollback();
} catch (SQLException e) {
/*
Just log a message for debug and continue to execute the following
statement like nothing happend.
Wrap the bad connection with a new PooledConnection, this will help
to not intterupt current executing thread and give current thread a
chance to join the next competion for another valid/good database
connection. At the end of this loop, bad {@link @conn} will be set as null.
*/
log.debug("Bad connection. Could not roll back");
}
}
//拿回来后,不再放到原有的PooledConnection,新建立一个。从新开始.老的REAL connection还被oldestActiveConnection引用,不会内存溢出?
conn = new PooledConnection(oldestActiveConnection.getRealConnection(), this);
conn.setCreatedTimestamp(oldestActiveConnection.getCreatedTimestamp());
conn.setLastUsedTimestamp(oldestActiveConnection.getLastUsedTimestamp());
oldestActiveConnection.invalidate();
if (log.isDebugEnabled()) {
log.debug("Claimed overdue connection " + conn.getRealHashCode() + ".");
}
} else {
// Must wait
//大家都在用着,你只能等着了。
try {
if (!countedWait) {
state.hadToWaitCount++;
countedWait = true;
}
if (log.isDebugEnabled()) {
log.debug("Waiting as long as " + poolTimeToWait + " milliseconds for connection.");
}
long wt = System.currentTimeMillis();
state.wait(poolTimeToWait);
state.accumulatedWaitTime += System.currentTimeMillis() - wt;
} catch (InterruptedException e) {
break;
}
}
}
}
if (conn != null) {
// ping to server and check the connection is valid or not
if (conn.isValid()) {
if (!conn.getRealConnection().getAutoCommit()) {
conn.getRealConnection().rollback();
}
conn.setConnectionTypeCode(assembleConnectionTypeCode(dataSource.getUrl(), username, password));
conn.setCheckoutTimestamp(System.currentTimeMillis());
conn.setLastUsedTimestamp(System.currentTimeMillis());
state.activeConnections.add(conn);
state.requestCount++;
state.accumulatedRequestTime += System.currentTimeMillis() - t;
} else {
if (log.isDebugEnabled()) {
log.debug("A bad connection (" + conn.getRealHashCode() + ") was returned from the pool, getting another connection.");
}
state.badConnectionCount++;
localBadConnectionCount++;
conn = null;
//如果累计有这些个链接失效了,则报个异常.
if (localBadConnectionCount > (poolMaximumIdleConnections + poolMaximumLocalBadConnectionTolerance)) {
if (log.isDebugEnabled()) {
log.debug("PooledDataSource: Could not get a good connection to the database.");
}
throw new SQLException("PooledDataSource: Could not get a good connection to the database.");
}
}
}
}
}
mybatis与数据库访问相关的配置以及设计的更多相关文章
- SpringBoot:4.SpringBoot整合Mybatis实现数据库访问
在公司项目开发中,使用Mybatis居多.在 SpringBoot:3.SpringBoot使用Spring-data-jpa实现数据库访问 中,这种jpa风格的把sql语句和java代码放到一起,总 ...
- mysql+spring+mybatis实现数据库读写分离[代码配置] .
场景:一个读数据源一个读写数据源. 原理:借助spring的[org.springframework.jdbc.datasource.lookup.AbstractRoutingDataSource] ...
- Spring Mvc和Mybatis的多数据库访问配置过程
Spring Mvc 加Mybatis的多数据库访问源配置访问过程如下: 在applicationContext.xml进行配置 <?xml version="1.0" en ...
- Spring+MyBatis实践—MyBatis数据库访问
关于spring整合mybatis的工程配置,已经在Spring+MyBatis实践—工程配置中全部详细列出.在此,记录一下几种通过MyBatis访问数据库的方式. 通过sqlSessionTempl ...
- 使用MyBatis搭建一个访问mysql数据库的简单示例
MyBatis是一个支持普通SQL查询,存储过程和高级映射的优秀持久层框架.MyBatis消除了几乎所有的JDBC代码和参数的手工设置以及对结果集的检索封装.MyBatis可以使用简单的XML或注解用 ...
- Spring+MyBatis双数据库配置
Spring+MyBatis双数据库配置 近期项目中遇到要调用其它数据库的情况.本来仅仅使用一个MySQL数据库.但随着项目内容越来越多,逻辑越来越复杂. 原来一个数据库已经不够用了,须要分库分表.所 ...
- Spring+Mybatis+Mysql搭建分布式数据库访问框架
一.前言 用Java开发企业应用软件, 经常会采用Spring+MyBatis+Mysql搭建数据库框架.如果数据量很大,一个MYSQL库存储数据访问效率很低,往往会采用分库存储管理的方式.本文讲述如 ...
- spring配置druid连接池和监控数据库访问性能
Druid连接池及监控在spring配置如下: <bean id="dataSource" class="com.alibaba.druid.pool.DruidD ...
- SpringBoot入门 (四) 数据库访问之JdbcTemplate
本文记录在SpringBoot中使用JdbcTemplate访问数据库. 一 JDBC回顾 最早是在上学时接触的使用JDBC访问数据库,主要有以下几个步骤: 1 加载驱动 Class.forName( ...
随机推荐
- 使用VMware Workstation 14 Player或者Oracle VM VirtualBox安装Fedora-Workstation-netinst-x86_64-27-1.6操作系统的相关记录
无论是在使用哪个(VMware或者Oracle VM)都遇到了一个问题:即使在安装完Fedoras操作系统之后,进行Reboot还是会进入之前一摸一样的安装界面,相当于再次安装.然而最最有效的解决办法 ...
- 【转】干货 | 【虚拟货币钱包】从 BIP32、BIP39、BIP44 到 Ethereum HD Wallet
虚拟货币钱包 钱包顾名思义是存放$$$.但在虚拟货币世界有点不一样,我的帐户资讯(像是我有多少钱)是储存在区块链上,实际存在钱包中的是我的帐户对应的 key.有了这把 key 我就可以在虚拟货币世界证 ...
- C语言权威指南和书单 - 专家级别
注: 点击标题即可下载 1. Advanced Programming in the UNIX Environment, 3rd Edition 2. Essential C 3. Computer ...
- STL——string
C++之string类型详解 之所以抛弃char*的字符串而选用C++标准程序库中的string类,是因为他和前者比较起来,不必担心内存是否足够.字符串长度等等,而且作为一个泛型类出现,他集成的操作函 ...
- 20155219 付颖卓《基于ARM试验箱的接口应用于测试》课程设计个人报告
一.个人贡献 参与课设题目讨论及完成全过程: 资料收集: 负责代码调试: 修改小组结题报告: 负责试验箱的管理: 二.设计中遇到的问题及解决方法 1.makefile无法完成编译.如下图: 答:重新下 ...
- python基础(九)
一.私有 class DB: port = 3306 #类变量 def __init__(self): self.host = '127.0.0.1' self.__user = 'root' #实例 ...
- memcached命令行、Memcached数据导出和导入、php连接memcache、php的session存储到memcached
1.memcached命令行 telnet 127.0.0.1 11211set key2 0 30 2abSTOREDget key2VALUE key2 0 2abEND 如: set key3 ...
- .NET第一章
1.介绍了.NET的作用和软件前景趋势 2.Visual studio .net 编程 3.介绍.net可以多种编程语言,通过公共语言类库存放 2.介绍C# 数据类型和变量设置,以及函数的使用 3.继 ...
- BOM模型中常用对象 定义计数器 网页跳转 网页前进后退
今天上午学了的BOM模型中常用对象,了解了一部分的属性 For循环的规律 外层循环控制行 内层循环控制列 <!doctype html> <html> <head> ...
- spring4注解配置datasource方式
package com.boot.config; import org.springframework.context.annotation.AnnotationConfigApplicationCo ...