<关于数据仓库>基于docker的Mysql与Hadoop/Hive之间的数据转移 (使用Apache Sqoop™)
原创博客,转载请联系博主!
摘要:本文介绍了如何使用docker快速搭建一个可以从外部访问的mysql服务容器,和由docker搭建的分布式Hadoop文件系统,并且使用ApacheSqoop完成将mysql中的关系型数据库转移到导入到hadoop文件系统之中,以及过程中遇到的一些问题及解决办法,一些为了避免错误要注意的细节!一转眼又是半个学期了,顺便感慨下时间过的好快呀..
再阅读之前你需要先 安装docker,我使用的是centos7,安装docker可以直接通过
yum -y install docker-io
fedora/RHEL及其它使用yum作为包管理工具的都可以这样一步到位,其他distribu的linux安装过程可以通过下面的链接学习:
一. 用Docker搭建Mysql服务,并通过远程访问
参考Github Repository:https://github.com/docker-library/docs
这是docker官方的docker-library其中有对各种数据库系统包括spark,redis,mongo等官方镜像的使用方法介绍。
首先需要拉取官方的DockerHub镜像
docker pull mysql:latest
或者你可以直接下载下来Dockerfile和entrypoint.sh脚本来构建一个 mysql镜像(5.6)

这里个人不推荐直接git clone下来整个庞大的docker-library,不如直接在浏览器上复制粘贴下来Dockerfile和entrypoint.sh的内容,之后进入Dockerfile所在的目录使用下面docker命令:
docker build .
关于Docker各种命令及参数的用法细节个人,个人推荐一个链接,请见 这里。
之后使用 docker images 来检查镜像之中是否存在mysql的镜像,如果存在,那么恭喜你离搭建一个完整的mysql服务只差一步之遥了。
最后创建docker容器完成mysql服务的搭建:
$ docker run --name mysql_serv -e MYSQL_ROOT_PASSWORD=mysqlpassword -d mysql:latest 或者你想要这个容器搭建的mysql服务可以从外部访问,就使用-p选项添加一个端口映射的规则,如将容器的mysql远程登陆端口3306映射为30000:
$ docker run -p 30000:3306--name mysql_serv -e MYSQL_ROOT_PASSWORD=mysqlpassword -d mysql:latest # 这里注意-p选项一定不能放在mysql:latest后面,不然不会有什么端口映射'-p 30000:3306'会直接作为cmd参数给容器启动!
(其中-e选项代表export 代表运行时使用-e后定义的环境变量 -d选项代表deamon指这个容器会在后台运行,和shell中的'&'很类似)
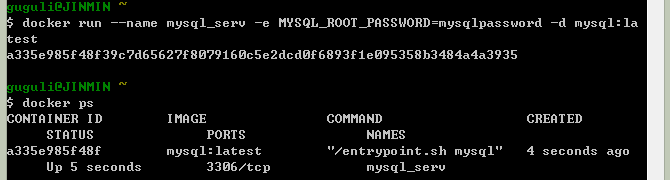
再使用: $ docker exec -t -i mysql_serv /bin/bash (其中-t和-i选项代表我们执行的进程创建了一个新的TTY并捕捉STDIN,即‘新建一个TTY并登入到这个容器之中’这和docker attach.. 有很大的区别)
之后我们就可以从外部登录我们的mysql服务了,容器通过端口映射实现了一个类似反向代理的服务!
二. 用docker搭建hadoop分布式文件系统
下面关于搭建Hadoop-docker的过程参考 原作者的文章。想了解具体原理的同学请参考作者原文,这里就给出“傻瓜式”完成搭建的过程:
首先拉取下面几个DockerHub镜像,这些镜像已经是成型的Hadoop节点:
(1) 拉取DockerHub中成型的Hadoop镜像
sudo docker pull index.alauda.cn/kiwenlau/hadoop-master:0.1.0 sudo docker pull index.alauda.cn/kiwenlau/hadoop-slave:0.1.0 sudo docker pull index.alauda.cn/kiwenlau/hadoop-base:0.1.0 sudo docker pull index.alauda.cn/kiwenlau/serf-dnsmasq:0.1.0
(2) 修改镜像的tag
sudo docker tag d63869855c03 kiwenlau/hadoop-slave:0.1.0 sudo docker tag 7c9d32ede450 kiwenlau/hadoop-master:0.1.0 sudo docker tag 5571bd5de58e kiwenlau/hadoop-base:0.1.0 sudo docker tag 09ed89c24ee8 kiwenlau/serf-dnsmasq:0.1.0
(3) 下载启动hadoop镜像的shell脚本
git clone https://github.com/kiwenlau/hadoop-cluster-docker
(4) 运行容器脚本
./hadoop-cluster-docker/start-container.sh
正常运行后的结果如下:

(5) 附加:搭建N节点的Hadoop集群(可选)
#重新配置容器参数,N为hadoop集群大小,下面默认N=5
./resize-cluster.sh 5
#启动容器
./start-container 5
(6) 启动Hadoop(相当于编译后的hadoop的start-all.sh脚本)
# 进入master的交互界面后(ssh和docker exec..均可)
./start-hadoop.sh
运行一次wordcount测试脚本(run-wordcount.sh)后正常的结果如下所示:

到这里hadoop集群就搭建完成了!
三. 构建Hive数据库
首先我们要登录hadoop的master节点:
docker exec -i -t master /bin/bash
配置Hive数据库
(到这里docker的hadoop节点都是可以访问外网的,我们直接下载并配置hive到master上)
#选择一个合适的目录并下载hive-binary包,注意要下载bin包而非src包
wget http://www.eu.apache.org/dist/hive/hive-1.2.1/apache-hive-1.2.1-bin.tar.gz
下载完成进行解压:
#这里注意下载到的格式后缀最好为.tar.gz
tar xzvf xxxx.tar.gz
然后将hive的环境变量配置好:
#进入hive的主目录下
echo "export HIVE_HOME=$(pwd)" >> /etc/profile
echo "export PATH=\$PATH:\$HIVE_HOME/bin">>/etc/profile
echo "export HIVE_CONF_DIR=\$HIVE_HOME/conf">>/etc/profile
source /etc/profile
(重要)因为$HADOOP_HOME/share/hadoop/yarn/lib中的jline-x.x.x.jar版本太低用$HIVE_HOME/lib中的jline-x.x.x.jar进行代替:
#替代hadoop中的低版本jline.x.x.x.jar
#需要环境变量 $HADOOP_HOME 和 $HIVE_HOME
jline_hadoop_path=$HADOOP_HOME/share/hadoop/yarn/lib/$(ls $HADOOP_HOME/share/hadoop/yarn/lib|grep jline)
jline_hive_path=$HIVE_HOME/lib/$(ls $HIVE_HOME/lib|grep jline)
cp $jline_hive_path $HADOOP_HOME/share/hadoop/yarn/lib/
rm $jline_hadoop_path
然后直接输入'hive'启动hive,结果如下图所示:
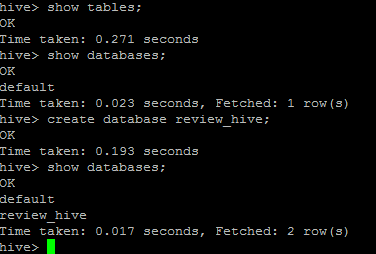
到这里hive的安装配置就完成了!
四. Apache Sqoop的安装及配置
(1)首先下载Apache Sqoop
官网FTP站为:http://www.us.apache.org/dist/sqoop/1.4.6/
这里还要注意由于Docker镜像中的Hadoop节点中版本为:

这里Hadoop2以上的版本必须使用Sqoop2以上的版本才可以正常运行,千万不要弄错了,不然后面会很麻烦。
注意要下载1.4.6版本,不要下载官网推荐最新的1.9.x版本,这里使用的是:http://www.us.apache.org/dist/sqoop/1.4.6/sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz
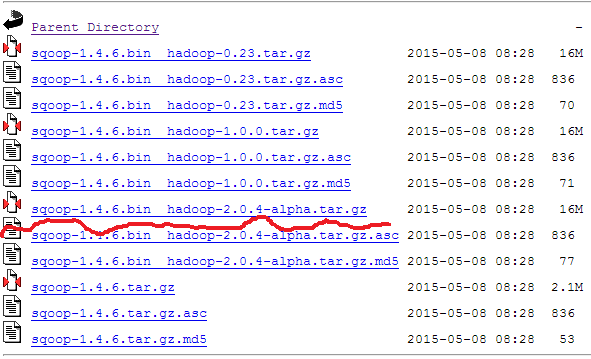
#下载sqoop脚本
#以下文件的名字请根据实际修改
mkdir ~/sqoop
cd ~/sqoop
wget http://www.us.apache.org/dist/sqoop/1.4.6/sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz
tar zxvf sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz
进入sqoop的主目录进行一些修改:
#配置环境变量
echo "export SQOOP_HOME=$(pwd)" >>/etc/profile
echo "export PATH=\$PATH:\$SQOOP_HOME/bin">>/etc/profile
source /etc/profile #将sqoop-1.4.6.jar放入$SQOOP_HOME/lib不然接下来会报错(不信你试试= =)
cp sqoop-1.4.6.jar $SQOOP_HOME/lib/
之后进入$SQOOP_HOME/conf进行一些配置:
#重命名文件
mv sqoop-env-template.sh sqoop-env.sh
之后修改sqoop-env.sh中的内容,将里面被注释掉的HADOOP_COMMON_HOME,HADOOP_MAPRED_HOME改为和HADOOP_HOME一致,再写好HIVE_HOME,如下所示:
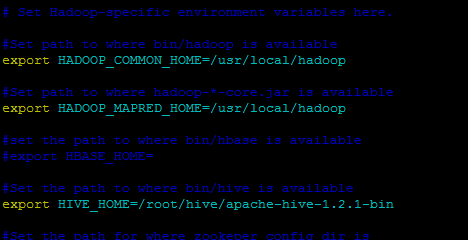
最后直接运行'sqoop‘,会出现一些WARNING,但是没有关系忽略掉他们,你的sqoop已经配置完成了!
五. 使用Apache Sqoop进行Mysql的表->Hive的表的转移
到这里就可以自由发挥了,比如我们在mysql中创建一个testdb,再创建一张testtable:
drop database testdb;
create database testdb;
use testdb;
create table testtable(
id char(10) primary key,
name char(10) not null
); insert into testtable(id,name) values('00000','kimmin');
insert into testtable(id,name) values('00001','kimmin1');
insert into testtable(id,name) values('00002','kimmin2');
insert into testtable(id,name) values('00003','kimmin3');
因为这里我们要和mysql之间沟通数据,所以要在$SQOOP_HOME/lib下面添加mysql的jdbc桥接包:
我这里上传了一份mysql的jdbc-connector包,由于格式限制,请大家wget到master容器后手动在后缀名从.rar改成.jar!
然后在master容器中使用命令:(执行之前请确认使用hive创建了数据库hivedb:create database hivedb)
sqoop import --connect jdbc:mysql://172.17.0.3:3306/testdb --username root --password dbpassword --table testtable --fields-terminated-by "\t" --lines-terminated-by "\n" --hive-import --hive-overwrite --create-hive-table --hive-table hivedb.testtable --delete-target-dir
关于sqoop的其它用法个人推荐这篇博客:http://segmentfault.com/a/1190000002532293#articleHeader8
这里得用mysql容器的虚拟私有ip来进行连接,所以端口自然也用容器的虚拟端口3306,而非外部映射的端口,转移成功结果如下:
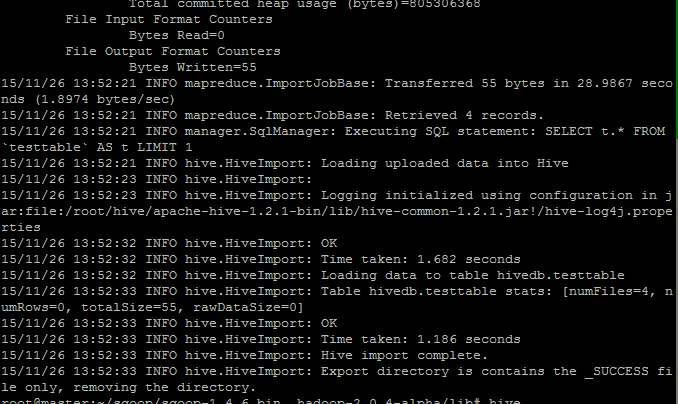
进入hive检查结果:
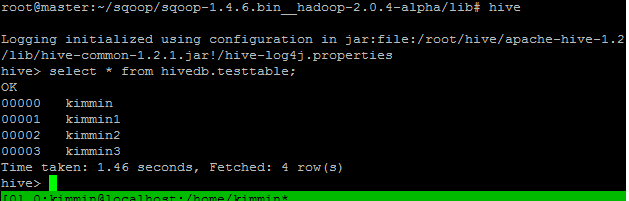
到此为止,使用sqoop将数据从mysql转移到hive已经完成了!
如果有疑问欢迎留言,博主会尽快回答!
<关于数据仓库>基于docker的Mysql与Hadoop/Hive之间的数据转移 (使用Apache Sqoop™)的更多相关文章
- 基于Docker的Mysql主从复制
基于Docker的Mysql主从复制搭建 为什么基于Docker搭建? 资源有限 虚拟机搭建对机器配置有要求,并且安装mysql步骤繁琐 一台机器上可以运行多个Docker容器 Docker容器之间相 ...
- 基于docker的php调用基于docker的mysql数据库的方法
1:建立基于docker的mysql,参考 Mac上将brew安装的MySql改用Docker执行 2:建立基于docker�php image 在当前目录,建立Dockerfile,内容如下 FRO ...
- 基于Docker的MySql
MySQL Server安装教程 考虑到实际情况需要经常使用MySQL,为了方便大家能够快速基于Docker搭建MySQL这里以Linux下为例 进行说明,对于Windows用户来说直接通过查看官网H ...
- docker初识-docker安装、基于docker安装mysql及tomcat、基本命令
一.docker是什么 用go语言开发,开源的应用容器引擎,容器性能开销极低 二.整体架构图 Docker 包括三个基本概念: 镜像(Image):Docker 镜像(Image),就相当于是一个 r ...
- Hadoop+Hive 操作mongodb数据
Hadoop+Hive 操作mongodb数据 1.版本概述 hadoop-2.7.3.hive-2.2 下载响应的jar包:http://mvnrepository.com/,直接搜索想要的jar包 ...
- 基于Docker的Mysql主从复制搭建
来源:https://www.cnblogs.com/songwenjie/p/9371422.html?tdsourcetag=s_pctim_aiomsg 为什么基于Docker搭建? 资源有 ...
- 基于Docker一键部署大规模Hadoop集群及设计思路
一.背景: 随着互联网的发展.互联网用户的增加,互联网中的数据也急剧膨胀.每天产生的数据量数以万计,本地文件系统和单机CPU已无法满足存储和计算要求.Hadoop分布式文件系统(HDFS)是海量数据存 ...
- Linux系统环境基于Docker搭建Mysql数据库服务实战
开放端口规划: mysql-develop:3407 mysql-test: 3408 mysql-release: 3409 ps: 1.不推荐使用默认端口-3306,建议自定义端口 2.如果采用阿 ...
- 基于Docker搭建MySQL主从复制
摘要: 本篇博文相对简单,因为是初次使用Docker,MySQL的主从复制之前也在Centos环境下搭建过,但是也忘的也差不多了,因此本次尝试在Docker中搭建. 本篇博文相对简单,因为是初次使用D ...
随机推荐
- 关于Action<T> 、Func<T>、EventHandler<T>、event、delegate
c# 最初的时候 只有 delegate,之后的版本封装了Action<T> .Func<T>.EventHandler<T> 关于Action<T> ...
- (转) 在Eclipse中进行C/C++开发的配置方法(20140721最新版)
本文转载自:http://blog.csdn.net/baimafujinji/article/details/38026421 Eclipse 是一个开放源代码的.基于Java的可扩展开发平台.就其 ...
- Python之re模块 —— 正则表达式操作
这个模块提供了与 Perl 相似l的正则表达式匹配操作.Unicode字符串也同样适用. 正则表达式使用反斜杠" \ "来代表特殊形式或用作转义字符,这里跟Python的语法冲突, ...
- Firmware综述
软件的层次关系(从底层到高层)如下: 1. PSP (Processor Support Package). A group of file that are specific to a CPU ty ...
- 两分钟彻底让你明白Android Activity生命周期(图文)!
大家好,今天给大家详解一下Android中Activity的生命周期,我在前面也曾经讲过这方面的内容,但是像网上大多数文章一样,基本都是翻译Android API,过于笼统,相信大家看了,会有一点点的 ...
- SpringJDBC
<!-- JdbcTemplate:最基础的springJDBC模板,这个模板支持最简单的jdbc数据库访问功能以及简单的索引参数查询 NamedParameterJdbcTemplate:使用 ...
- socket 发送发送HTTP请求
socket方式: $socket = socket_create(AF_INET, SOCK_STREAM, SOL_TCP); //socket_set_option($socket, SOL_S ...
- c#unity
using UnityEngine;using System.Collections; public class PacmanMove : MonoBehaviour { public float s ...
- PDF出力相关资料
http://itext.2136553.n4.nabble.com/iText-SetFieldProperty-method-not-working-for-some-parameters-set ...
- JS实例
JS实例 1.跑马灯 <!DOCTYPE html> <html lang="en"> <head> <meta charset=&quo ...