ASP.NET的SEO:使用.ashx文件——排除重复内容
不同的链接指向的页面如果具有大量相同的内容,这种现象就会被称为“重复内容”,如果一个网站的重复内容很多,搜索引擎就会认为这个网站的价值不高。所以我们应尽量避免各种重复内容。
动态网站的重复内容常常是由URL参数引起的,而URL重写会恶化这一现象(比较耐人寻味哟,呵呵)。因为如果使用的是原始的URL参数的话,搜索引擎可能会进行适当的判断,而得知重复内容是由URL参数引起的,自动的进行相应的处理;而URL重写会掩盖URL参数,反而使得搜索引擎无法识别URL参数。比如:

http://www.freeflying.com/articles.aspx?id=231&catelog=blog
http://www.freeflying.com/articles.aspx?id=231&catelog=news
经过URL重写过后的URL:
http://www.freeflying.com/blog/231.html
http://www.freeflying.com/news/231.html
这些URL所指向的页面内容其实是一样的,都是id=231的那篇文章,但这篇文章被blog和news两个栏目所引用,出于各种原因的考虑,我们最终的URL还是如上所示。
处理的办法有两种,一种是利用机器人(robot)协议“排除”其中一个,另一种是通过301将其中一个URL永久重定向另一个URL。
今天我们先讲robot协议。简单的讲,robot指的就是搜索引擎,针对Google,我们又将其称之为“蜘蛛(spider)”。蜘蛛是很有礼貌的,在抓取你的网页内容的之前,会首先征求你的意见。而你和robot之前就基于robot协议进行沟通。具体到实现,有两种方式:
1. 将一个的robots.txt文本添加到网站根目录下,如:
#static content, forbid all the pages under the "Admin" folderUser-agent: *Disallow: /Admin
#行表示注释;
User-agent指搜索引擎,*表示针对所有搜索引擎,也可以指定具体的搜索引擎,如User-agent: googlebot;
Disallow指定不允许访问的目录或页面,注意:1. 此文本是大小写敏感的;2.必须以“\”开头,表示网站根目录;
和本系列的宗旨一样,我们着重谈ASP.NET技术。所以更多的robots.txt文本的注意事项,请查看http://www.googlechinawebmaster.com/2008/03/robotstxt.html
但我们怎么动态的生成这个文件呢(这种需求其实蛮多的)?可能我们马上想到的就是I/O操作,在根目录下写一个txt文件……,但其实还可以有一种方法:使用一般处理程序(.ashx文件),代码如下:
 代码
代码
using System;
using System.Web;
public class Handler : IHttpHandler {
public void ProcessRequest (HttpContext context) {
HttpResponse response = context.Response;
response.Clear();
//response.ContentType = "text/plain"; 如果要用IE6查看页面的话,不能这一条声明,原因不详
//下面这两句在实际使用中应该数据库等动态生成
response.Write("User-agent: * \n");
response.Write("Disallow: /news/231.html \n");
//引用一个静态的robots文件内容,里面存储不会改变的屏蔽内容
response.WriteFile("~/static-robots.txt");
response.Flush();
}
public bool IsReusable {
get {
return false;
}
}
}
一般处理程序实现了IHttpHandler,在前面UrlRewrite部分中,我们讲到了HttpModule,其实在ASP.NET的应用程序生命周期中,有一个称之为“管道(pipeline)”的概念:一个HTTP请求,经过一个有一个的HttpModule的“过滤/处理”,最终到达一个HttpHandle的“处理器”部分,HttpModule和HttpHandle就组成了一个“管道”,非常形象哟,呵呵。贴张图吧:
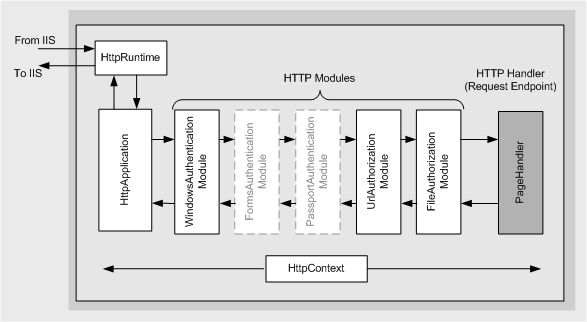
如果你对它还比较陌生的话,查看Page的源代码,你会发现,Page也实现了IHttpHandler,所以*.aspx文件是最常用的HttpHandle。但Page不仅仅是一个HttpHandler,它还嵌入了复杂的页面生命周期事件,所以从节约资源的角度考虑,很多时候我也可以使用自定义的、更轻量级的*.ashx文件(),来完成一些简单的工作。和生成一个txt文件类似,我们还可以生成验证码(jpg文件),xml文件等。
然后还要做的一件事就是进行URLRewrite:
代码
{
// Code that runs on application startup
HttpContext context = HttpContext.Current;
string currentLocation = context.Request.Url.LocalPath;
if (currentLocation.ToLower() == "/website1/robots.txt")
{
context.RewritePath("~/Handler.ashx");
}
}
这样,蜘蛛就会以为在网站的根目录下的确存在一个robots.txt文件。
2. 在需要屏蔽的页面META标签里加上
<meta id="meta" name="robots" content="noindex,nofollow" />
noindex 意味着该页面不能被索引
nofollow 意味着该页面不能被“跟随”(将在SEO Hack中详细讲解)
这是静态页面的效果,如果需要动态生成,也相当简单:
代码
{
HtmlMeta meta = new HtmlMeta();
meta.Name = "robots";
meta.Content = "noindex,nofollow";
this.Header.Controls.Add(meta);
}
meta中还可以指定description、keyword等,其技术实现是相同的。
那么,两种方式我们如何选择呢?我的一些建议:
1. 尽量使用robots.txt,这既能降低网站的负载(虽然很小,呵呵),因为蜘蛛查看了robots.txt文件之后,就不会再请求被屏蔽的相关页面了;而如果使用meta方式,蜘蛛必须先请求该页面,再做出不检索的判断,这时Http请求已经发出了,服务器端的资源就已经浪费了;另外,如果过多的meta屏蔽,也会使蜘蛛对网站产生不佳的印象,减少或放弃该网站的检索收录;
2. robots.txt文本的匹配时从左到右的,这里就没什么正则匹配了!所以有的时候,我们不得不使用meta方式了。如我们文章开始的URL:
http://www.freeflying.com/blog/231.html
http://www.freeflying.com/news/231.html
最后,再讲一些注意事项:
1. 不要在所有页面使用相同的Keyword和Discription,这是我们很容易犯的一个错误,虽然articles.aspx是一个页面,但加上url参数后,就变成了成千上万个页面,如果你在页面上写死了Keyword和Discription,那将使这成千上万个页面都是一样的Keyword和Discription!
2. 尽量避免使用基于URL的SessionID。ASP.NET在客户端禁用cookie的情况下,可以设置使用基于URL的SessionID,效果类似:
http://www.freeflying.com/(S(c3hvob55wirrndfd564))/articles.aspx
ASP.NET的SEO:使用.ashx文件——排除重复内容的更多相关文章
- ASP.NET的SEO:HTTP报头状态码---内容重定向
本系列目录 我们经常说"404错误",你知道他指的是什么意思么? 404其实是Http报头所包含的一个"状态码",表明该Http请求失败.那么除此之外,还有哪些 ...
- ASP.NET大闲话:ashx文件有啥用
在VS中右击项目,添加新项,我们找到.ashx文件在新建项模板中叫做“一般处理程序”,那么这个一般处理程序用来干吗的呢? 我们可以这样地简单理解,嗯,不需搞得太复杂,它就类似.aspx文件,用于处理传 ...
- 算法初级面试题05——哈希函数/表、生成多个哈希函数、哈希扩容、利用哈希分流找出大文件的重复内容、设计RandomPool结构、布隆过滤器、一致性哈希、并查集、岛问题
今天主要讨论:哈希函数.哈希表.布隆过滤器.一致性哈希.并查集的介绍和应用. 题目一 认识哈希函数和哈希表 1.输入无限大 2.输出有限的S集合 3.输入什么就输出什么 4.会发生哈希碰撞 5.会均匀 ...
- ASP.NET的SEO:目录
ASP.NET的SEO:基础知识 ASP.NET的SEO:Global.asax和HttpModule中的RewritePath()方法--友好的URL ASP.NET的SEO:正则表达式 ASP.N ...
- asp.net中.ashx文件接参
如果是在解决方案中的Web项目中创建.ashx文件,没有文件头,不能直接读取到html页面传来的参数值. 用context.Request["参数名"]来获取参数值. 用conte ...
- Ajax跨域请求ashx文件与Webservice文件
前台页面: <%@ Page Language="C#" AutoEventWireup="true" CodeBehind="WebForm1 ...
- ASP.NET跨服务器上传文件的相关解决方案
第一种:通过FTP来上传文件 首先,在另外一台服务器上设置好FTP服务,并创建好允许上传的用户和密码,然后,在ASP.NET里就可以直接将文件上传到这台 FTP 服务器上了.代码如下: <%@ ...
- ASP.NET的SEO:Linq to XML---网站地图和RSS Feed
本系列目录网站地图的作用是让搜索引擎尽快的,更多的收录网站的各个网页. 这里我们首先要明白一个基本的原理,搜索引擎的爬行方式.整个互联网就像一张纵横交错的"网":网的各个节点 ...
- Linq to XML---网站地图和RSS Feed(ASP.NET的SEO)
本系列目录网站地图的作用是让搜索引擎尽快的,更多的收录网站的各个网页. 这里我们首先要明白一个基本的原理,搜索引擎的爬行方式.整个互联网就像一张纵横交错的"网":网的各个节点 ...
随机推荐
- linux命令(7)killall
killall命令: Linux系统中的killall命令用于杀死指定名字的进程(kill processes by name).我们可以使用kill命令杀死指定进程PID的进程,如果要找到我们需要杀 ...
- FileSystemWatcher
转:http://www.cnblogs.com/zhaojingjing/archive/2011/01/21/1941586.html 注意:用FileWatcher的Created监控文件时,是 ...
- 图片_ _优化Bitmap加载图片1
=========== 1 视图显示大量图片时的内存问题 setBackgroundResource 回去res 资源文件里面找适配手机当前屏幕的文件,所以消耗高,etBackgroundDra ...
- JAVA实例,判断是否是瑞年
题目:用户输入一个年份,返回是否是瑞年. 瑞年规则:能被4整除,并且不能能被100整除,或者能被400整除的年份称之为瑞年. 实例: import java.util.Scanner; public ...
- 基本 linux命令
rm rf * 递归删除 ln -s 源 目标 |管道命令 把上一个命令的结果交给 | 的后面的命令处理 文件内容查阅 cat 由第一行开始显示文件内容 tac 从最后一行开始显示 nl 显示的时候输 ...
- 计算webView的 高度 和自适应屏幕大小
- (void)webViewDidFinishLoad:(UIWebView *)webView{ [webView stringByEvaluatingJavaScriptFromString: ...
- 真正的轻量级WebService框架——使用JAX-WS(JWS)发布WebService
WebService历来都很受重视,特别是Java阵营,WebService框架和技术层出不穷.知名的XFile(新的如CXF).Axis1.Axis2等. 而Sun公司也不甘落后,从早期的JAX-R ...
- 基于Maven的Springboot+Mybatis+Druid+Swagger2+mybatis-generator框架环境搭建
基于Maven的Springboot+Mybatis+Druid+Swagger2+mybatis-generator框架环境搭建 前言 最近做回后台开发,重新抓起以前学过的SSM(Spring+Sp ...
- CyclicBarrier
用于多线程计算数据,最后合并计算结果的应用场景 CyclicBarrier 的字面意思是可循环使用(Cyclic)的屏障(Barrier) 它要做的事情是,让一组线程到达一个屏障(也可以叫同步点)时被 ...
- freemarker中使用shiro标签
地址:https://github.com/jagregory/shiro-freemarker-tags下载该jar包 或者源代码文件复制到自己工程的lib下或者package中 如果使用spri ...